twemproxy源码分析
twemproxy是twitter开源的redis/memcached 代理,数据分片提供取模,一致性哈希等手段,维护和后端server的长连接,自动踢除server,恢复server,提供专门的状态监控端口供外部工具获取状态监控信息。代码写的比较漂亮,学习了一些Nginx的东西,比如每个请求的处理分为多个阶段,IO模型方面,采用单线程收发包,基于epoll事件驱动模型。文档中提到的Zero Copy技术,通过将消息指针在3个队列之间流转实现比较巧妙。本文主要分析twemproxy的核心部分,即一个请求的从接收到最后发送响应给客户端的流程。
一、大体流程
twemproxy后端支持多个server pool,为每个server pool分配一个监听端口用于接收客户端的连接。客户端和proxy建立连接记作client_conn,发起请求,proxy读取数据,放入req_msg中,设置msg的owner为client_conn,proxy根据策略从server pool中选取一个server并且建立连接记作server_conn,然后转发req_forward,将req_msg指针放入client_conn的output队列中,同时放入server_conn的input队列,然后触发server_conn的写事件,server_conn的写回调函数会从input队列中取出req_msg发送给对应的后端server,发送完成后将req_msg放入server_conn的output队列,当req_msg的响应rsp_msg回来后,调用rsp_filter(用于判断消息是否为空,是否消息可以不用回复等)和rsp_forward,将req_msg从server_conn的output队列中取出,建立req_msg和rsp_msg的对应关系(通过msg的peer字段),通过req_msg的owner找到client_conn,然后启动client_conn的写事件,client_conn的写回调函数从client_conn的output队列中取出req_msg,然后通过peer字段拿到对应的rsp_msg,将其发出去。至此,一次请求从被proxy接收到最后响应给client结束。
可以看出,整个流程,req_msg内容只有一份,req_msg指针在三个队列中的顺序是:
1. req_msg => client_conn.outputq
2. req_msg => server_conn.inputq
3. server_conn.inputq => req_msg
4. req_msg => server_conn.outputq
5. server_conn.outputq => req_msg
6. client_conn.outputq => req_msg
总体来说,proxy既需要接收客户端的连接,也需要维护和后端server的长连接,根据从客户端收到的req根据特定策略选择后端一台server进行转发,同一个客户端的连接上的不同的请求可能会转发到后端不同的server。

二、基础数据结构:
后端的每个redis server对应一个server结构:
struct server {
uint32_t idx; /* server index */
struct server_pool *owner; /* owner pool */ // 每个server属于一个server pool
struct string pname; /* name:port:weight (ref in conf_server) */
struct string name; /* name (ref in conf_server) */
uint16_t port; /* port */
uint32_t weight; /* weight */
int family; /* socket family */
socklen_t addrlen; /* socket length */
struct sockaddr *addr; /* socket address (ref in conf_server) */
uint32_t ns_conn_q; /* # server connection */ // 下面队列中conn的个数
struct conn_tqh s_conn_q; /* server connection q */ // proxy和这个redis server之间维护的连接队列
int64_t next_retry; /* next retry time in usec */ // proxy有踢除后端server机制,当proxy给某台server转发请求出错次数达到server_failure_limit次,则next_retry微妙内不会请求该server。可配。
uint32_t failure_count; /* # consecutive failures */
};
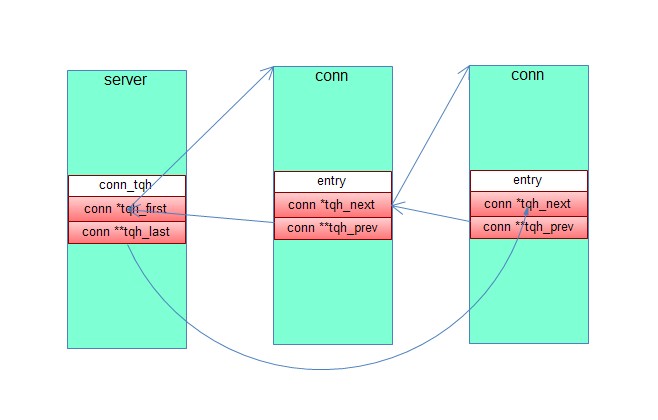
twemproxy中使用一堆宏来定义队列等数据结构,如上面struct conn_tqh,nc_connection.h中有定义TAILQ_HEAD(conn_tqh, conn),TAILQ_HEAD宏定义如下:
/*
* Tail queue declarations.
*/
#define TAILQ_HEAD(name, type) \
struct name { \
struct type *tqh_first; /* first element */ \
struct type **tqh_last; /* addr of last next element */ \
TRACEBUF \
}
可以看出结构体是通过宏来定义的,非常恶心,看代码ctags 找不到。conn_tqh是一个队列头部结构体,嵌入到一个server中,链表中每个元素是一个conn结构体,内嵌入一个TAILQ_ENTRY,用于将conn串入server的队列中。宏定义如下:
#define TAILQ_ENTRY(type) \
struct { \
struct type *tqe_next; /* next element */ \
struct type **tqe_prev; /* address of previous next element */ \
TRACEBUF \
}
各个field的关系如下图所示:
看一个很重要的结构conn,可以表示client和proxy之间的connection,也可以表示proxy和redis server之间的connection:
struct conn {
TAILQ_ENTRY(conn) conn_tqe; /* link in server_pool / server / free q */ // 队列entry字段,用于和其他的conn串起来
void *owner; /* connection owner - server_pool / server */ // 每个连接属于一个server
int sd; /* socket descriptor */
int family; /* socket address family */
socklen_t addrlen; /* socket length */
struct sockaddr *addr; /* socket address (ref in server or server_pool) */
struct msg_tqh imsg_q; /* incoming request Q */ //从名字看出,和conn_tqh类似,这里也是一个消息队列,从连接读入的数据会组织成msg,push到这个消息队列,msg由mbuf队列组成用来存储具体的数据。
struct msg_tqh omsg_q; /* outstanding request Q */ // 需要往这个连接中写的msg push到这个消息队列
struct msg *rmsg; /* current message being rcvd */ //从连接上读到的数据往rmsg指向的msg里面填
struct msg *smsg; /* current message being sent */ //当前正在写的msg指针
conn_recv_t recv; /* recv (read) handler */ //读事件触发时回调
conn_recv_next_t recv_next; /* recv next message handler */ //实际读数据之前,调这个函数来得到当前正在使用的msg
conn_recv_done_t recv_done; /* read done handler */ // 每次接收到一个完整的消息后,回调
conn_send_t send; /* send (write) handler */ //写事件触发时回调
conn_send_next_t send_next; /* write next message handler */ 实际写数据之前,定位当前要写的msg
conn_send_done_t send_done; /* write done handler */ //发送完一个msg则回调一次
conn_close_t close; /* close handler */ //
conn_active_t active; /* active? handler */
conn_ref_t ref; /* connection reference handler */ // 得到一个连接后,将连接加入相应的队列
conn_unref_t unref; /* connection unreference handler */
conn_msgq_t enqueue_inq; /* connection inq msg enqueue handler */ //这四个队列用于存放msg的指针,和Zero Copy密切相关,后续详述
conn_msgq_t dequeue_inq; /* connection inq msg dequeue handler */
conn_msgq_t enqueue_outq; /* connection outq msg enqueue handler */
conn_msgq_t dequeue_outq; /* connection outq msg dequeue handler */
size_t recv_bytes; /* received (read) bytes */ //该连接上读了多少数据
size_t send_bytes; /* sent (written) bytes */
uint32_t events; /* connection io events */
err_t err; /* connection errno */
unsigned recv_active:; /* recv active? */
unsigned recv_ready:; /* recv ready? */
unsigned send_active:; /* send active? */
unsigned send_ready:; /* send ready? */
unsigned client:; /* client? or server? */ //连接属于proxy和client之间时,client为1,连接属于proxy和后端server之间时,client为0
unsigned proxy:; /* proxy? */ // listen fd封装在conn中时,proxy置1,响应的recv回调函数accept连接
unsigned connecting:; /* connecting? */
unsigned connected:; /* connected? */
unsigned eof:; /* eof? aka passive close? */
unsigned done:; /* done? aka close? */
unsigned redis:; /* redis? */ //后端server是redis还是memcached
};
二、
不管是proxy accept了Client的连接从而分配一个conn结构,还是proxy主动和后端server建立连接从而分配一个conn结构,都调用conn_get()函数,如下:
struct conn *conn_get(void *owner, bool client, bool redis)
{
struct conn *conn; conn = _conn_get();
if (conn == NULL) {
return NULL;
} /* connection either handles redis or memcache messages */
conn->redis = redis ? : ; conn->client = client ? : ; if (conn->client) {
/*
* client receives a request, possibly parsing it, and sends a
* response downstream.
*/
conn->recv = msg_recv; // 从conn读数据
conn->recv_next = req_recv_next; // 在真正从conn读数据之前,需要分配一个req_msg,用于承载读进来的数据
conn->recv_done = req_recv_done; //每次读完一个完整的消req_msg被调用 conn->send = msg_send; // 将从server收到的响应rsp_msg发给客户端
conn->send_next = rsp_send_next; // 每次发送rsp_msg之前需要首先确定从哪个开始发
conn->send_done = rsp_send_done; // 每次发送完成一个rsp_msg给客户端,调一次 conn->close = client_close; //用于proxy断开和client的半连接
conn->active = client_active; conn->ref = client_ref; //获取conn后将conn丢进客户端连接队列
conn->unref = client_unref; conn->enqueue_inq = NULL;
conn->dequeue_inq = NULL;
conn->enqueue_outq = req_client_enqueue_omsgq; // proxy每次接收到一个client发过来的req_msg,将req_msg入conn的output 队列
conn->dequeue_outq = req_client_dequeue_omsgq; // 给客户端发送完rsp_msg后将其对应的req_msg从conn的output队列中删除
} else {
/*
* server receives a response, possibly parsing it, and sends a
* request upstream.
*/
conn->recv = msg_recv;
conn->recv_next = rsp_recv_next; //从后端server接收数据之前需要先得到一个rsp_msg,用于承载读到的数据
conn->recv_done = rsp_recv_done; // 每次读完一个完整的rsp_msg,则回调
conn->send = msg_send; // 将req_msg往后端server发
conn->send_next = req_send_next; // 确定发哪个req_msg
conn->send_done = req_send_done; // 每转发完一个即回调 conn->close = server_close;
conn->active = server_active; conn->ref = server_ref;
conn->unref = server_unref; conn->enqueue_inq = req_server_enqueue_imsgq; // proxy将需要转发的req_msg放入对应后端server连接的input队列
conn->dequeue_inq = req_server_dequeue_imsgq; //proxy从input队列中取出req_msg发送给后端server完成后,需要将req_msg从这个后端连接的input队列中删除
conn->enqueue_outq = req_server_enqueue_omsgq; // 继上一步,需要将req_msg放入到后端连接的output队列
conn->dequeue_outq = req_server_dequeue_omsgq; // 收到后端server的rsp_msg后,将rsp_msg对应的req_msg从连接的output队列删除
} conn->ref(conn, owner); log_debug(LOG_VVERB, "get conn %p client %d", conn, conn->client); return conn;
}
如果该连接是proxy和后端server建立的,则client为false,否则为true,如果后端server是redis,则redis为true,如果为memcached,则为false,连接上的多个读写回调函数根据传入的标记不同而不同。
三、 请求具体处理流程
从前面可以看出,当proxy和Client之间有数据可读时,会调用msg_recv(),如下:
rstatus_t
msg_recv(struct context *ctx, struct conn *conn)
{
rstatus_t status;
struct msg *msg; ASSERT(conn->recv_active); conn->recv_ready = ;
do {
msg = conn->recv_next(ctx, conn, true); //req_recv_next()
if (msg == NULL) {
return NC_OK;
} status = msg_recv_chain(ctx, conn, msg);
if (status != NC_OK) {
return status;
}
} while (conn->recv_ready); return NC_OK;
}
代码很短,其实就是反复的做两件事:req_recv_next和msg_recv_chain
req_recv_next获取当前用于接收数据的msg,设置到conn->rmsg中,并且返回rmsg,然后传给msg_recv_chain,每次重新接收一个完整的请求时,rmsg为空,如果某次读取只读取了请求的一部分,则rmsg不为空,下次读取时数据继续追加到上一次的msg中。
重点看msg_recv_chain()做的事情:
1. 从conn->rmsg中拿出最后一个mbuf(一个msg的数据实际上存在mbuf中,一个msg可以包含多个mbuf,同样通过队列组织),下一次读最多读最后一个mbuf的剩余空间大小,如果最后一个mbuf满了,分配一个新的,插入到rmsg的mbuf队列尾部
2. 循环从conn读数据,如果读取到的数据小于参入的buf大小,设置conn->recv_ready为0,表示后续没有数据要读了,外部的while(conn->recv_ready)循环退出。同样,如果读操作返回0表示客户端主动断开连接,将conn的eof标记置位,同时recv_ready也清0
3. 调用msg_parse()解析rmsg数据,如果成功解析到一条完整的命令,则继续调用msg_parsed(msg),由于msg由多个mbuf组成,并且TCP是流式协议,所以一次读可能接收到了多条完整的命令,甚至是部分命令。这时,msg_parsed(msg)会将后面这些多余的数据拷贝到一个新的mbuf中,并且产生一个新的msg,作为conn的rmsg。由于一次读可能会读到多条命令,这就是为什么msg_recv_chain()中有下面这个循环:
for (;;) {
status = msg_parse(ctx, conn, msg); //每次解析一条命令
if (status != NC_OK) {
return status;
}
/* get next message to parse */
nmsg = conn->recv_next(ctx, conn, false);
if (nmsg == NULL || nmsg == msg) {
/* no more data to parse */
break;
}
msg = nmsg;
}
4. 同时,每次调msg_parse(ctx,conn,msg)解析出一条新的命令后,都会回调req_recv_done()方法。这个方法对请求进行过滤(req_filter)和转发(req_forward)给后端server。
5. msg_recv_chain()完成。
回到msg_recv,根据conn->recv_ready来判断是否连接中还有未读数据,有则继续读,parse。。
下面看请求转发给后端函数 req_forward():
1. 将解析出来的msg(以后将从客户端发过来的msg叫做req_msg)push进conn的output队列
2. 根据key和策略从server pool中选择一个server,并且获得和server的连接,记作server_conn,将req_msg push到server_conn的输入队列,起server_conn的写事件
至此,req_msg从client接收到解析到转发结束。下面看发消息给后端server,从后端server接收响应,将响应回复给客户端的过程
起server_conn写事件后,回调函数msg_send(struct context *ctx, struct conn *conn):
rstatus_t
msg_send(struct context *ctx, struct conn *conn)
{
rstatus_t status;
struct msg *msg; ASSERT(conn->send_active); conn->send_ready = ;
do {
msg = conn->send_next(ctx, conn);
if (msg == NULL) {
/* nothing to send */
return NC_OK;
} status = msg_send_chain(ctx, conn, msg);
if (status != NC_OK) {
return status;
} } while (conn->send_ready);
可以看出和接收函数msg_recv类似。req_send_next()从server_conn的input队列中拿出一个待发消息赋值给conn->smsg。然后调用msg_send_chain()对消息进行实际的发送。
msg_send_chain()流程如下:
1. 准备NC_IOV_MAX个iov,遍历smsg的mbuf队列,每个mbuf的数据用一个iov指向。
2. 循环调用req_send_next()不断的取出待发送的smsg,将其加入到一个局部消息队列send_msgq,同时遍历smsg的mbuf队列,每个mbuf用一个iov指向,直到NC_IOV_MAX个iov被装满,或者没有消息需要发送了,记录下装进去的消息总大小,记作nsend。
3. 循环往fd上写,返回成功写的大小nsent,遍历send_msgq中的msg,和msg中的mbuf队列,将已发送成功的mbuf置为空,并且将发送了部分msg的pos指向第一个未发送的字节。并且,如果一个msg的mbuf队列中的所有的mbuf都发送完成了,则将调用req_send_done(),将这个msg(指针)从这个连接的input队列中删除,并且放入到连接的output队列中。从这里可以看出,只有一个msg的所有的mbuf都被发送出去了才会从input队列中删除,如果只发送了部分mbuf,这些mbuf会被标记为空,下次继续发送这个msg时,会略过空的msg,实现一个msg过大或者网络阻塞导致需要多次发送才能发出一个msg的情况。
4. 至此,发送流程分析完成。
Redis接收到消息,处理返回,proxy接收响应,和proxy接收client的数据类似,同样调用msg_recv()
rstatus_t
msg_recv(struct context *ctx, struct conn *conn)
{
rstatus_t status;
struct msg *msg; ASSERT(conn->recv_active); conn->recv_ready = ;
do {
msg = conn->recv_next(ctx, conn, true); //rsp_recv_next()
if (msg == NULL) {
return NC_OK;
} status = msg_recv_chain(ctx, conn, msg);
if (status != NC_OK) {
return status;
}
} while (conn->recv_ready); return NC_OK;
}
只是,在这里,conn->recv_next指向的函数是rsp_recv_next(),不是req_recv_next()。同理,接收回消息的处理函数是rsp_recv_done(),不是req_recv_done()
rsp_recv_next():
1. 如果当前conn的rmsg为空,则分配一个新的返回,否则返回当前这个rmsg
2. 将上一步返回的rmsg传给msg_recv_chain()处理。这个函数之前在proxy接收client请求时分析了,不再赘述。
收到一个完整的响应rsp_msg后,调rsp_recv_done():
1. 同样和前面类似,在这里调用rsp_filter()和rsp_forward(),而不是req_filter()和req_forward()
重点说rsp_forward():
1. 从连接的output队列中弹出第一个元素,记作req_msg,这个msg即是目前收到的这个msg(rsp_msg)相对应的请求msg
2. 将req_msg的标记done置为1,表示这个请求已完成。
3. 通过以下两个语句将这两个msg建立对应关系:
pmsg->peer = msg; //pmsg为req_msg,msg为rsp_msg
msg->peer = pmsg
4. 从pmsg的owner可以找到所属的client conn,然后启client conn的写事件。
5. 至此,proxy从后端server接收响应分析完成。
最后,看一下proxy将响应写给client的流程。
类似,调用msg_send():
rstatus_t
msg_send(struct context *ctx, struct conn *conn)
{
rstatus_t status;
struct msg *msg; ASSERT(conn->send_active); conn->send_ready = ;
do {
msg = conn->send_next(ctx, conn); // rsp_send_next()
if (msg == NULL) {
/* nothing to send */
return NC_OK;
} status = msg_send_chain(ctx, conn, msg);
if (status != NC_OK) {
return status;
} } while (conn->send_ready); return NC_OK;
}
同理,在这里,conn->send_next函数指针指向rsp_send_next():
1. 从client conn的output队列中拿出msg,记作req_msg,从req_msg的peer字段将相应的rsp_msg拿出来,放在conn的smsg上待发送
发出完成后,调用rsp_send_done(),主要做的事就是将req_msg从client conn的output队列中删除。
twemproxy源码分析的更多相关文章
- twemproxy源码分析2——守护进程的创建
twemproxy源码中关于守护进程的创建实现得比较标准,先贴出代码来,然后结合一些资料来分析和列举一些实现守护进程的常用方法,不过不得不说twemproxy的实现确实是不错的,注释都写在了代码中,直 ...
- twemproxy源码分析1——入口函数及启动过程
最近工作中需要写一个一致性哈希的代理,在网上找到了twemproxy,结合网上资料先学习一下源码. 一.Twemproxy简介 Twemproxy是memcache与redis的代理,由twitter ...
- ABP源码分析一:整体项目结构及目录
ABP是一套非常优秀的web应用程序架构,适合用来搭建集中式架构的web应用程序. 整个Abp的Infrastructure是以Abp这个package为核心模块(core)+15个模块(module ...
- HashMap与TreeMap源码分析
1. 引言 在红黑树--算法导论(15)中学习了红黑树的原理.本来打算自己来试着实现一下,然而在看了JDK(1.8.0)TreeMap的源码后恍然发现原来它就是利用红黑树实现的(很惭愧学了Ja ...
- nginx源码分析之网络初始化
nginx作为一个高性能的HTTP服务器,网络的处理是其核心,了解网络的初始化有助于加深对nginx网络处理的了解,本文主要通过nginx的源代码来分析其网络初始化. 从配置文件中读取初始化信息 与网 ...
- zookeeper源码分析之五服务端(集群leader)处理请求流程
leader的实现类为LeaderZooKeeperServer,它间接继承自标准ZookeeperServer.它规定了请求到达leader时需要经历的路径: PrepRequestProcesso ...
- zookeeper源码分析之四服务端(单机)处理请求流程
上文: zookeeper源码分析之一服务端启动过程 中,我们介绍了zookeeper服务器的启动过程,其中单机是ZookeeperServer启动,集群使用QuorumPeer启动,那么这次我们分析 ...
- zookeeper源码分析之三客户端发送请求流程
znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的 ...
- java使用websocket,并且获取HttpSession,源码分析
转载请在页首注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/6238826.html 一:本文使用范围 此文不仅仅局限于spring boot,普通的sprin ...
随机推荐
- java8时间类
java8引入了一套全新的时间日期API 新的时间及日期API位于java.time中java.time包中的是类是不可变且线程安全的. 下面是一些关键类 LocalDateTime // ...
- 微信小程序开发-概述
微信小程序开发-概述 一.小程序申请&APPID 登录微信平台申请成为小程序开发者,小程序不可直接使用服务号或订阅号的AppID,需要登录微信公众平台管理后台,在网站的"设置&quo ...
- webpack4重新梳理一下2
上一篇已经实现了webpack的基本打包操作,但是并没有使用配置文件,而是使用 CLI 来实现打包. 配置文件 // webpack.config.js module.exports = { //入口 ...
- docker “no space left on device”问题定位解决
在paas环境上使用docker加载镜像的时候出现了如下问题 第一反应应该是存储镜像的路径磁盘满了 docker info查看docker的根路径,可以看到为/opt/docker: 查看/opt/d ...
- R语言之数据处理常用包
dplyr包是Hadley Wickham的新作,主要用于数据清洗和整理,该包专注dataframe数据格式,从而大幅提高了数据处理速度,并且提供了与其它数据库的接口:tidyr包的作者是Hadley ...
- freepbx的SIP通话客户端X-lite Yate eyeBeam Linphone
在上一篇文章安装freepbx后创建sip分机里我们已经创建好了SIP分机,接下来我们使用几大客户端进行登陆.我们接下来会使用到的软件有X-lite,Yate client,eyeBeam, Linp ...
- 使用Koa2搭建web项目
随着Node.js的日益火热,各种框架开始层出不穷的涌现出来,Node.js也开始逐渐的被应用到处理服务端请求的场景中.搭建Web项目的框架也随之开始出现——express.koa.koa2.egg等 ...
- python实现float/double的0x转化
1. 问题引出 最近遇到了一个小问题,即: 读取文本文件的内容,然后将文件中出现的数字(包括double, int, float等)转化为16进制0x存储 原本以为非常简单的内容,然后就着手去写了py ...
- 阿里云centos6.5实践编译安装LNMP架构web环境
LNMP 代表的就是:Linux系统下Nginx+MySQL+PHP这种网站服务器架构. 本次测试需求: **实践centos6.5编译安装 LNMP生产环境 架构 web生产环境 使用 ngx_pa ...
- 使用 Flask 框架写用户登录功能的Demo时碰到的各种坑(四)——对 run.py 的调整
使用 Flask 框架写用户登录功能的Demo时碰到的各种坑(一)——创建应用 使用 Flask 框架写用户登录功能的Demo时碰到的各种坑(二)——使用蓝图功能进行模块化 使用 Flask 框架写用 ...