社交网络分析的 R 基础:(四)循环与并行
前三章中列出的大多数示例代码都很短,并没有涉及到复杂的操作。从本章开始将会把前面介绍的数据结构组合起来,构成真正的程序。大部分程序是由条件语句和循环语句控制,R 语言中的条件语句(if-else)和 C 语言中类似此处就不再介绍,循环语句包括 for 和 while 控制块。循环是社交网络分析的主旋律,比如使用 for 循环遍历分析网络中的每一个节点。当网络规模足够大时,并行处理又变得十分必要。熟练掌握本章的内容后,你的程序将会优雅而自然。
循环语句
while
while 循环作为最简单的一种循环,只要满足条件(condition 为 TRUE),循环将会一直进行。
while (condition) {
# TODO
}
在 R 语言中还存在特殊的关键字 repeat,在 repeat 控制块内的语句将会无限的执行。下面的示例代码效果是等价的:
repeat {
# TODO
}
while (TRUE) {
# TODO
}
for
R 语言中的 for 循环更像某些语言中的 foreach,本质上就是遍历向量(或其他数据结构)中的元素:
for (name in vector) {
# TODO
}
下面的示例将会输出向量中的元素:
> v <- c("a", "b", "c")
> for (item in v) {
+ print(item)
+ }
[1] "a"
[1] "b"
[1] "c"
循环控制
有时当满足条件时,需要使用 break 退出循环:
while (TRUE) {
# TODO
if (condition) {
break
}
}
或者使用 next 退出当前循环(类似其他语言的 continue):
for (name in vector) {
# TODO
if (condition) {
next
}
}
apply() 系列函数
R 语言中循环语句的执行效率是无法忍受的,这是因为循环语句是基于 R 语言本身来实现的,而向量操作是基于 C 语言实现的,所以应避免使用显式循环,使用 apply() 系列函数进行替代。举个例子,对一个矩阵的行求和,并封装一个函数,使用 for 循环应该是这样:
func1 <- function(matrix) {
row_sum <- c()
for (i in 1: nrow(matrix)) {
row_sum[i] <- sum(matrix[i, ]) # 对每一行求和
}
return(row_sum)
}
使用 sapply() 可以这样简化代码:
func2 <- function(matrix) {
return(sapply(1: nrow(matrix), function(i) { return(sum(matrix[i, ])) }))
}
下面测试一下两种方法的性能消耗:
> m <- matrix(c(1: (10000 * 10000)), nrow = 10000) # 10000x10000 的方阵
> system.time(func1(m))
用户 系统 流逝
0.79 0.00 0.79
> system.time(func2(m))
用户 系统 流逝
0.72 0.00 0.72
上面的例子说明使用 for 循环不仅代码冗余,而且 for 循环实现的计算是耗时最长的,这就是为什么要了解 apply() 系列函数的原因。apply() 系列函数本身就是解决数据循环处理的问题,为了面向不同的数据类型,不同的返回值,apply() 函数组成了一个函数族。一般使用最多的是对矩阵处理的函数 apply() 以及对向量处理的函数 sapply()。
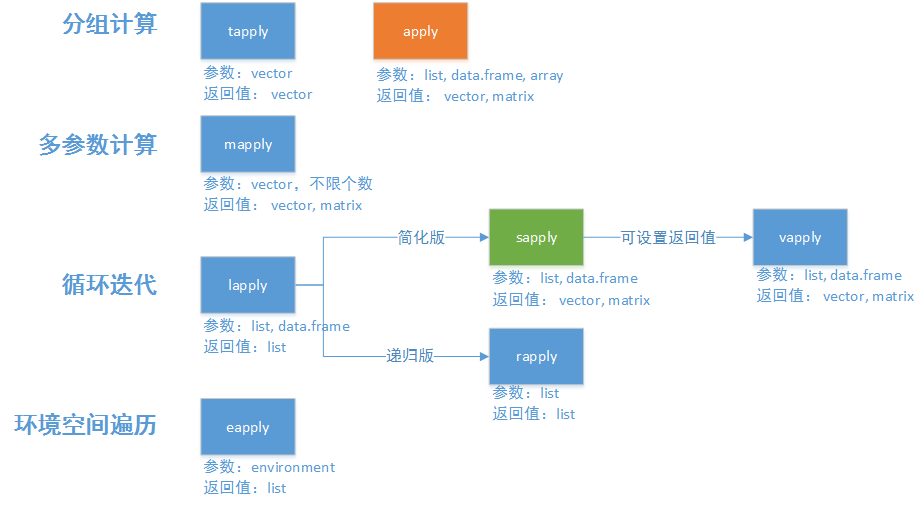
apply() 系列函数[1]
apply()
apply() 函数用于多维数据的处理,比如矩阵。其本质上是对 for 循环的进一步封装,并不会加快计算速度。apply() 函数的定义如下:
apply(X, MARGIN, FUN)
提示
要查看函数的文档可以在 R 终端中键入“?函数名”,比如查看 apply() 的文档输入 ?apply。
其中 X 是要循环处理的数据,即矩阵;MARGIN 是数据处理的维度,1 是按行处理,2 是按列处理;FUN 是循环处理的函数。对一个矩阵的行求和使用 apply() 函数更简单,但效率上不如 sapply()。
func2 <- function(matrix) {
return(apply(matrix, 1, sum))
}
sapply()
sapply() 函数用于循环处理一维数据,比如向量。参数上更加精简,处理完成的数据返回的结果集为向量,其定义如下:
sapply(X, FUN)
其中 X 是要循环处理的数据,即向量;FUN 是循环处理的函数。在不使用向量运算的前提下计算向量的平方,使用 sapply() 函数可以这样:
> v <- c(1, 2, 3)
> sapply(v, function(item) { return(item ^ 2) })
[1] 1 4 9
使用 parallel 包并行处理
现代 CPU 通常拥有 4 个以上的核心,为了使计算机更努力的“工作”,将任务并行化处理变得很有意义。充分利用多核 CPU,运行速度可能会快四倍,这样我们等待实验的时间更少,并且可以运行更多的实验。在开始将任务并行化之前,首先需要问自己一个问题:任务是否能够并行?要回答这个问题,你需要思考任务是否具有“重复性”,即每个子任务可以保持计算的独立性,只有可重复的任务才能分配到多个 CPU 上运行。回到上文中“对一个矩阵的行求和”这个问题上,“求和”是一个可重复的任务,矩阵的行数决定了“求和”的次数,对矩阵中某一行向量的求和并不会干扰其他行向量的求和,因此该问题可以进行并行处理。或者更简单的说,包含在循环控制块内的代码基本都可以进行并行处理。
在 R 语言中并行计算有 snow 和 parallel 两个包可选,两个包功能上一样,这里使用 parallel,最直接的原因是 R 语言集成了这个包,无需额外安装。并行函数的用法基本等同于 apply() 系列函数,比如:apply() 对应的并行计算函数为 parApply()、sapply() 对应的并行计算函数为 parSapply() 等等。
在本机上并行
在本机上处理并行计算的概念很好理解,就是将需要并行处理的任务分配到计算机的多个 CPU 内核中,这也是最常见的场景。继续以“对一个矩阵的行求和”为例,采用并行的方式解决这个问题。首先需要创建一个并行集群:
> library(parallel)
> parallel.cores <- detectCores() # 检测本机的内核数
> cl <- makeCluster(parallel.cores) # 创建集群,从机的数量为内核数
提示
通常创建集群的从机数量不要超过 最大内核数 - 1,最好保留 1~2 个内核供系统调度以及其他任务使用。
如果没有任何错误提示的话,则本机集群创建完成,可以将创建的集群打印出来以查看信息。
> print(cl)
socket cluster with 16 nodes on host 'localhost'
提示
本机集群的创建错误通常和端口占用有关,处理该问题可以查看端口的占用情况并结束程序,或者重启计算机。
紧接着调用 parApply() 进行并行计算,并行计算的 parApply() 系列方法仅仅需要在第一个参数将创建的集群传递进去即可。
func3 <- function(cluster, matrix) {
return(parApply(cluster, matrix, 1, sum))
}
下面来测试一下并行计算的时间开销:
> system.time(func3(cl, m))
用户 系统 流逝
3.43 0.47 4.86
测试的结果似乎与想象的有些不同,时间变得更慢了。这是由于 parallel 创建的是套接字集群,从机之间的通信速度是较慢的,由于求和这个任务本身就很简单,通信的开销远远大于计算的时间消耗,因此导致了计算速度并没有变得更快。这也告诉我们过于“轻松”的任务,并不需要并行执行。
最后在并行计算完成后需要及时关闭集群:
> stopCluster(cl)
由于集群是一个独立的环境,本地环境所引入的包、拥有的变量在集群内是无法访问的。在进行更复杂的并行任务时,需要将包或者变量传递至集群中:
> clusterEvalQ(cl, { library(igraph) }) # 为集群引入包
> clusterExport(cl, c("graph", "subgraph"), envir = environment()) # 为集群引入本地变量
在多台计算机上并行
由于 parallel 创建的是套接字集群,这使得将并行任务分配至多台计算机成为可能。当然这并不意味着计算机越多就能获得更快的计算速度。parallel 分配任务的方式类似均分,如果计算机之间单核的性能差距过大,那么会出现一台计算机分配的任务已经完成而等待其他计算机的现象,这样反而会出现计算速度的下降。并且并行计算的速度还与计算机之间的通信速度有关,从机的变量共享来自于主机,当网络情况不佳时,通信的消耗也是不容忽视的。因此在多台计算机上进行并行任务时需要谨慎考虑。在多台计算机上并行与在本机上并行的区别仅在于集群的创建,因此本小节将只介绍集群创建的不同。
这里使用两台计算机进行模拟实验,主机的操作系统为 Windows 10,从机的操作系统为 Ubuntu 20.04,使用两台安装了不同操作系统的计算机模拟了最复杂的情况,拓扑图如下所示。

提示
计算机之间的通信需要 SSH,Windows 10 请在“可选功能”中添加“OpenSSH 服务器”,Ubuntu Desktop 请运行命令 apt install openssh-server。
同时为了避免在创建集群时手动输入 SSH 登录密码,请配置 SSH 密钥登录。
首先创建一个列表,用于配置集群计算机的信息。其中 host 为计算机的地址;user 为 SSH 登录的用户名;rscript 为 Rscript 程序的路径,当主从机的操作系统相同时该字段可以省略;ncore 为分配的 CPU 内核数。
> master <- '192.168.122.100'
> addresses <- list(
+ list(host = master, user = "zhang", rscript = "C:/Program Files/R/R-4.0.5/bin/Rscript", ncore = 4),
+ list(host = "192.168.122.200", user = "zhang", rscript = "/usr/lib/R/bin/Rscript", ncore = 4)
+ )
由于 parallel 是将一个 CPU 内核作为从机,而上面的配置是按照计算机进行的,因此还需要根据 ncore 字段创建分配 CPU 内核数的从机:
> spec <- lapply(addresses, function(machine) {
+ rep(list(list(host = machine$host, user = machine$user, rscript = machine$rscript)), machine$ncore)
+ })
> spec <- unlist(spec, recursive = FALSE)
可以将创建的 spec 变量打印出来,观察是否创建了 8 个从机的信息。
> length(addresses)
[1] 2
> length(spec)
[1] 8
紧接着就可以调用 makeCluster() 创建集群,此过程根据计算机的数量可能需要数分钟。其中 manual 为是否手动激活从机,当创建集群出现问题时,可以将该字段设置为 TRUE,根据提示手动激活从机,以此来观察哪一台计算机出现了问题;outfile 为日志文件的存储地址,当创建集群出现问题时,也可以查看该文件。
cl <- makeCluster(type = "PSOCK", master = master, spec = spec, manual = FALSE, outfile = "log.txt")
此时如果没有提示任何错误,那么一个由多台计算机组成的集群已经创建完成。现在可以使用 parApply() 系列函数将任务并行的在多台计算机上运行。
> print(cl)
socket cluster with 8 nodes on hosts
'192.168.122.100', '192.168.122.200'
提示
多台计算机集群的创建错误通常与 SSH 登录和包的引用有关。SSH 登录的错误根据提示信息进行处理,包引用的错误请确保计算机之间的 R 语言版本、包的版本一致。
️ 练习
1. 使用 for 循环倒序输出 0~100;
2. 定义一个函数,使用 apply() 系列函数,求一个矩阵列向量的平均值。
参考
社交网络分析的 R 基础:(四)循环与并行的更多相关文章
- 社交网络分析的 R 基础:(一)初探 R 语言
写在前面 3 年的硕士生涯一转眼就过去了,和社交网络也打了很长时间交道.最近突然想给自己挖个坑,想给这 3 年写个总结,画上一个句号.回想当时学习 R 语言时也是非常戏剧性的,开始科研生活时到处发邮件 ...
- 社交网络分析的 R 基础:(二)变量与字符串
本章会从 R 语言中最基本的数据类型开始介绍,在此之后就可以开始 R 语言实践了.对社交网络分析而言,我们在处理字符串上所花费的时间要远远大于处理数字的时间,因此本章还会介绍常用的字符串处理操作. 变 ...
- 社交网络分析的 R 基础:(三)向量、矩阵与列表
在第二章介绍了 R 语言中的基本数据类型,本章会将其组装起来,构成特殊的数据结构,即向量.矩阵与列表.这些数据结构在社交网络分析中极其重要,本质上对图的分析,就是对邻接矩阵的分析,而矩阵又是由若干个向 ...
- 社交网络分析的 R 基础:(五)图的导入与简单分析
如何将存储在磁盘上的邻接矩阵输入到 R 程序中,是进行社交网络分析的起点.在前面的章节中已经介绍了基本的数据结构以及代码结构,本章将会面对一个实质性问题,学习如何导入一个图以及计算图的一些属性. 图的 ...
- 社交网络分析的 R 基础:(六)绘图操作
R 语言强大的可视化功能在科学研究中非常受欢迎,丰富的类库使得 R 语言可以绘制各种各样的图表.当然这些与本章内容毫无关系,因为笔者对绘制图表了解有限,仅限于能用的程度.接下来的内容无需额外安装任何包 ...
- JavaScript 基础(四) 循环
JavaScript的循环有两种,一种是for 循环,通过初始条件,结束条件和递增条件来循环执行语句块: var x = 0; var i; for(i=1; i <=10000; i++){ ...
- Python全栈开发【基础四】
Python全栈开发[基础四] 本节内容: 匿名函数(lambda) 函数式编程(map,filter,reduce) 文件处理 迭代器 三元表达式 列表解析与生成器表达式 生成器 匿名函数 lamb ...
- [转] X-RIME: 基于Hadoop的开源大规模社交网络分析工具
转自http://www.dataguru.cn/forum.php?mod=viewthread&tid=286174 随着互联网的快速发展,涌现出了一大批以Facebook,Twitter ...
- 记一个社交APP的开发过程——基础架构选型(转自一位大哥)
记一个社交APP的开发过程——基础架构选型 目录[-] 基本产品形态 技术选型 最近两周在忙于开发一个社交App,因为之前做过一点儿社交方面的东西,就被拉去做API后端了,一个人头一次完整的去搭这么一 ...
随机推荐
- 编写Java程序,用套接字编程模拟实现银行认证过程
需求说明: 某银行一核心服务器部署了一个资金交易来往的系统,为了防止黑客入侵窃取数据,该银行专门开发了一款负责安全认证的智能机器人守护服务器,对外来访问做多重身份认证.现在要求你用套接字编程模拟实现这 ...
- 开源实践 | 携程在OceanBase的探索与实践
写在前面:选型考虑 携程于1999年创立,2016-2018年全面推进应用 MySQL 数据库,前期线上业务.前端技术等以 SQL Server 为主,后期数据库逐步从 SQL Server 转到开源 ...
- python+openpyxl 获取最大行数,不是真正想获取的行数,导致替换时,报”NoneType' object has no attribute 'find'
问题描述: 使用excel对接口的数据进行管理,添加接口数据时,可能习惯性选择多行,设置了格式,导致多选了很多空行也被设置了格式,在读取这个sheet的最大行数时,发现有问题,获取到了为None的空行 ...
- 初识python 之 爬虫:BeautifulSoup 的 find、find_all、select 方法
from bs4 import BeautifulSoup lxml 以lxml形式解析html,例:BeautifulSoup(html,'lxml') # 注:html5lib 容错率最高fin ...
- captcha_生成图片验证码并返回给前端展示
使用pip install captcha 安装模块 import random import string import os import io from captcha.image import ...
- Go语言系列之标准库log
Go语言内置的log包实现了简单的日志服务.本文介绍了标准库log的基本使用. 使用Logger log包定义了Logger类型,该类型提供了一些格式化输出的方法.本包也提供了一个预定义的" ...
- HDU 2084 数塔 (动态规划DP)
原题链接:http://acm.hdu.edu.cn/showproblem.php?pid=2084 题目分析:此题采用动态规划自底向上计算,如果我们要知道所走之和最大,那么最后一步肯定是走最后一排 ...
- 【刷题-LeetCode】228. Summary Ranges
Summary Ranges Given a sorted integer array without duplicates, return the summary of its ranges. Ex ...
- StringBuilder类练习
1 package cn.itcast.p2.stringbuffer.demo; 2 3 public class StringBuilderTest { 4 public static void ...
- 带你十天轻松搞定 Go 微服务系列(三)
序言 我们通过一个系列文章跟大家详细展示一个 go-zero 微服务示例,整个系列分十篇文章,目录结构如下: 环境搭建 服务拆分 用户服务(本文) 产品服务 订单服务 支付服务 RPC 服务 Auth ...