Apache Kyuubi 在 T3 出行的深度实践
- 支撑了80%的离线作业,日作业量在1W+
- 大多数场景比 Hive 性能提升了3-6倍
- 多租户、并发的场景更加高效稳定
T3出行是一家基于车联网驱动的智慧出行平台,拥有海量且丰富的数据源。因为车联网数据的多样性,T3出行构建了以 Apache Hudi 为基础的企业级数据湖,提供强有力的业务支撑。而对于负责数据价值挖掘的终端用户而言,平台的技术门槛是另一种挑战。如果能将平台的能力统合,并不断地优化和迭代,让用户能够通过 JDBC 和 SQL 这种最普遍最通用的技术来使用,数据生产力将可以得到进一步的提升。
T3出行选择了基于网易数帆主导开源的 Apache Kyuubi(以下简称Kyuubi)来搭建这样的能力。在2021 中国开源年会(COSCon'21)上,T3出行高级大数据工程师李心恺详细解读了选择 Kyuubi 的原因,以及基于 Kyuubi 的深度实践和实现的价值。
引入 Kyuubi 前的技术架构
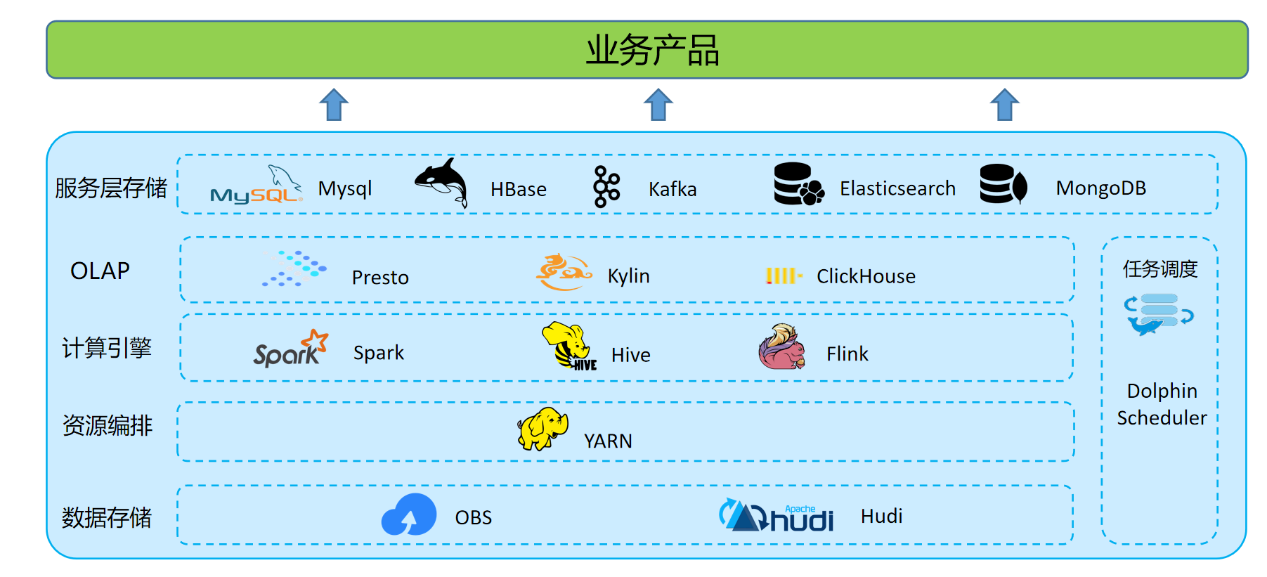
T3出行整个数据湖体系,由数据存储与计算、数据查询与分析和应用服务层组成。其中数据计算分为离线和实时。
数据存储
OBS 对象存储,格式化数据存储格式以 Hudi 格式为主。
数据计算
离线数据处理:利用 Hive on Spark 批处理能力,在 Apache Dolphin Scheduler 上定时调度,承担所有的离线数仓的 ETL 和数据模型加工的工作。
实时数据处理:建设了以 Apache Flink 引擎为基础的开发平台,开发部署实时作业。
数据查询与分析
OLAP 层主要为面向管理和运营人员的报表,对接报表平台,查询要求低时延响应,需求多变快速响应。面向数据分析师的即席查询,更是要求 OLAP 引擎能支持复杂 SQL 处理、从海量数据中快速甄选数据的能力。
应用服务层
数据应用层主要对接各个业务系统。离线 ETL 后的数据写入不同业务不同数据库中,面向下游提供服务。
现有架构痛点
跨存储
数据分布在 Hudi、ClickHouse、MongoDB 等不同存储,需要写代码关联分析增加数据处理门槛和成本。
SQL不统一
Hive 不支持通过 upsert、update、delete 等语法操作 Hudi 表,同时 MongoDB、ClickHouse 等语法又各不相同,开发转换成本较高。
资源管控乏力
Hive on Spark、Spark ThriftServer 没有较好的资源隔离方案,无法根据租户权限做并发控制。
选型 Apache Kyuubi
Apache Kyuubi 是一个 Thrift JDBC/ODBC 服务,对接了 Spark 引擎,支持多租户和分布式的特性,可以满足企业内诸如 ETL、BI 报表等多种大数据场景的应用。Kyuubi 可以为企业级数据湖探索提供标准化的接口,赋予用户调动整个数据湖生态的数据的能力,使得用户能够像处理普通数据一样处理大数据。项目已于2021年 6 月 21 号正式进入 Apache 孵化器。于T3出行而言,Kyuubi 的角色是一个面向 Serverless SQL on Lakehouse 的服务。
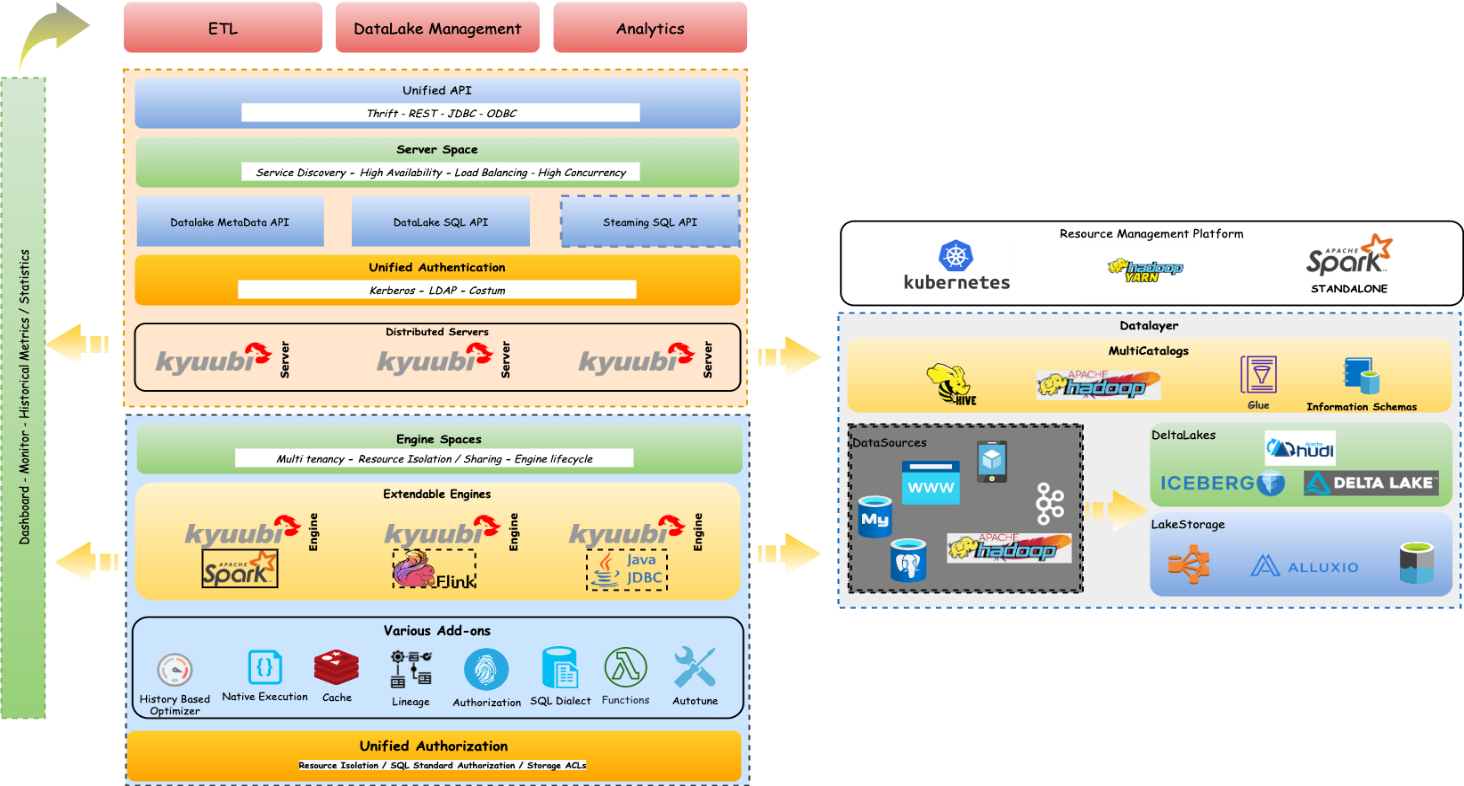 Apache Kyuubi 架构
Apache Kyuubi 架构
HiveServer 是一个广泛应用的大数据组件。因传统的 MR 引擎处理效率已经较为落后,Hive 引擎替换为了 Spark,但是为了和原本的 MR 及 TEZ 引擎共存,Hive 保留了自己的优化器,这使得Hive Parse 性能在大多数场景下都落后于 Spark Parse。
STS(Spark Thrift Server)支持HiveServer 的接口和协议,允许用户直接使用 Hive 接口提交 SQL 作业。但是 STS 不支持多租户,同时所有 Spark SQL 查询都走唯一一个 Spark Thrift 节点上的同一个 Spark Driver,并发过高,并且任何故障都会导致这个唯一的 Spark Thrift 节点上的所有作业失败,从而需要重启 Spark Thrift Server,存在单点问题。
对比 Apache Kyuubi 和 Hive、STS,我们发现,Kyuubi 在租户控制,任务资源隔离,引擎升级对接,性能等方面拥有诸多优势。详情见下图。
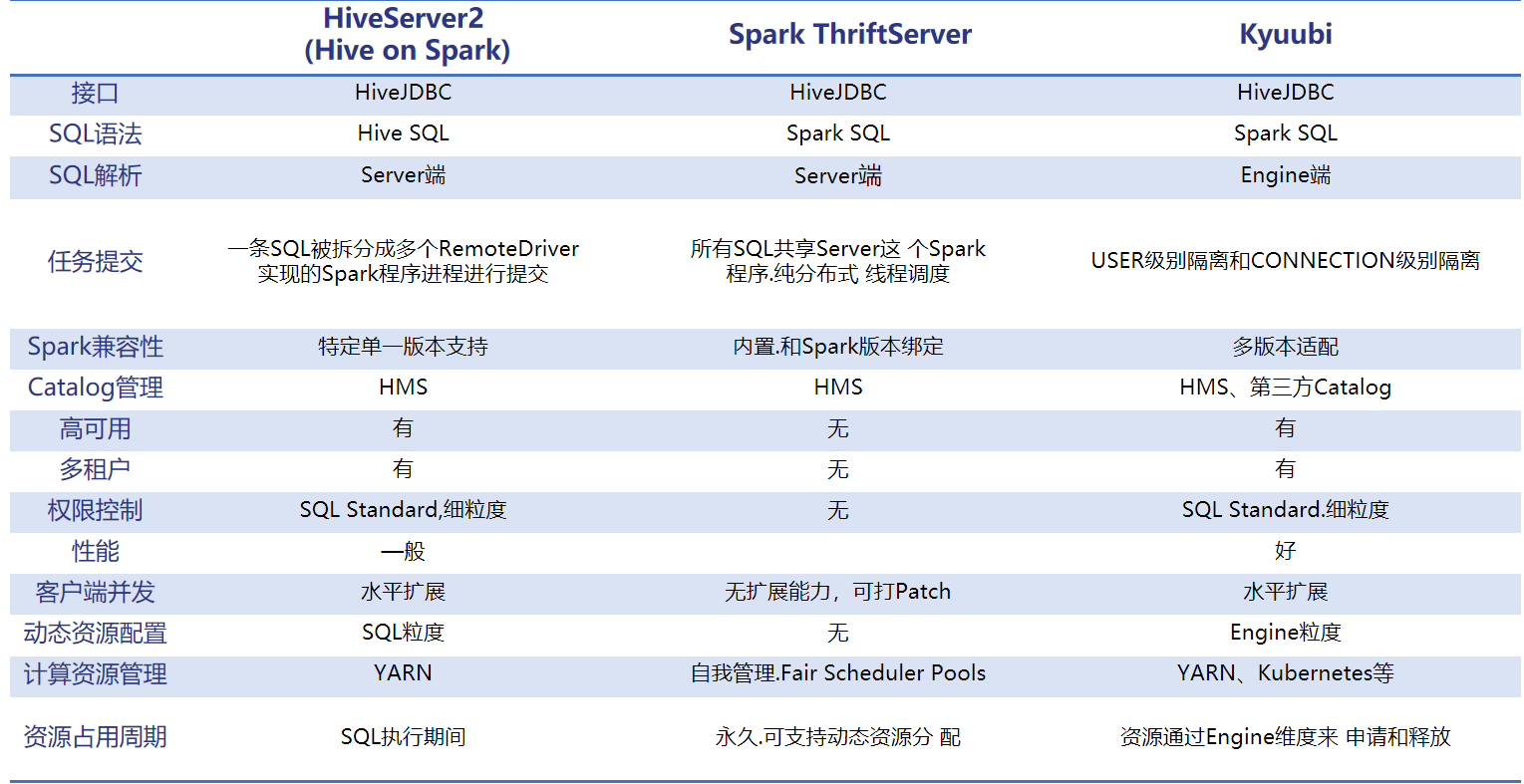
Apache Kyuubi 优势
Apache Kyuubi在T3出行场景
AD-HOC场景
Hue 整合 Kyuubi,替代 Hive 为分析师和大数据开发提供服务。
我们在 hue_safety_valve.ini 配置文件中,增加如下配置:
[notebook]
[[interpreters]]
[[[cuntom]]]
name=Kyuubi
interface=hiveserver2
[spark]
sql_server_host=Kyuubi Server IP
sql_server_port=Kyuubi Port然后重启 Hue 即可。
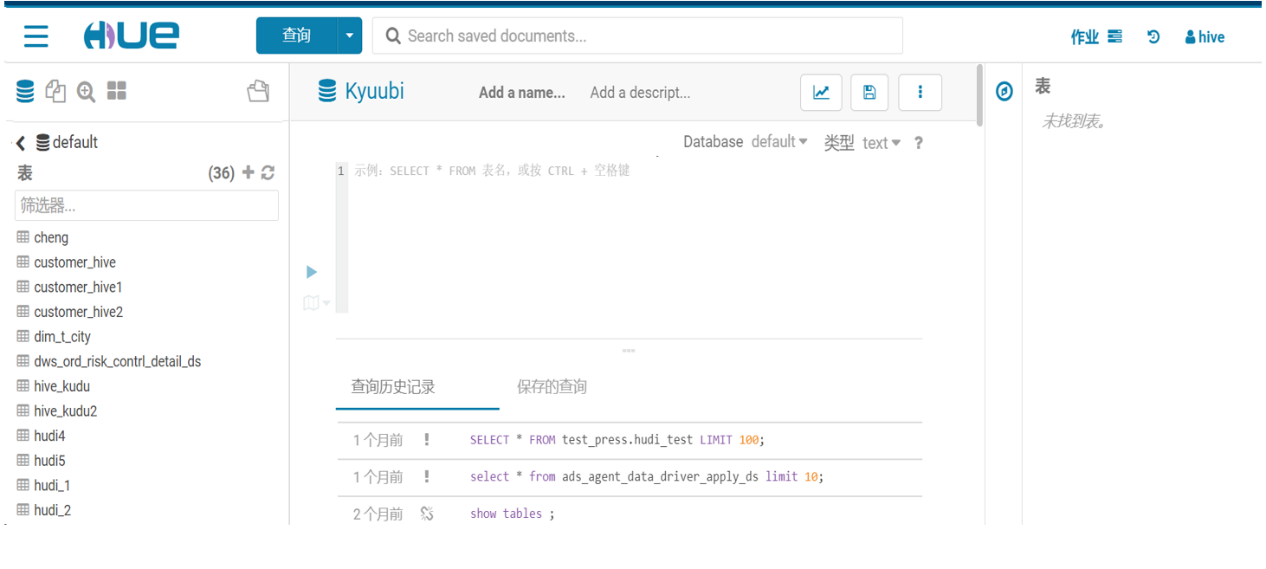
ETL场景
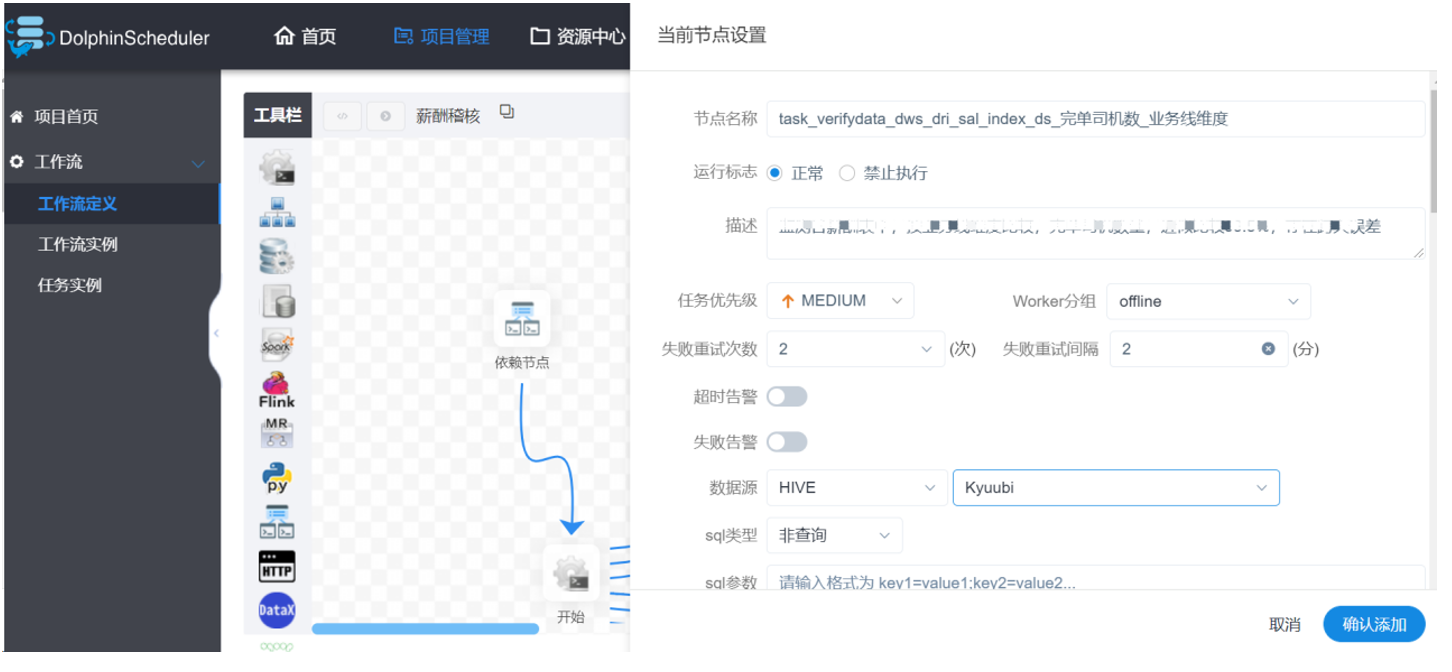
DS 配置 Kyuubi 数据源,进行离线 ETL 作业。因为 Kyuubi Server 的接口、协议都和 HiveServer2 完全一致,所以 DS 只需要数据源中 Hive 数据源类型配置为 Kyuubi 多数据源,就可以直接提交 SQL 任务。
目前,Kyuubi 在T3出行支撑了80%的离线作业,日作业量在1W+。
联邦查询场景
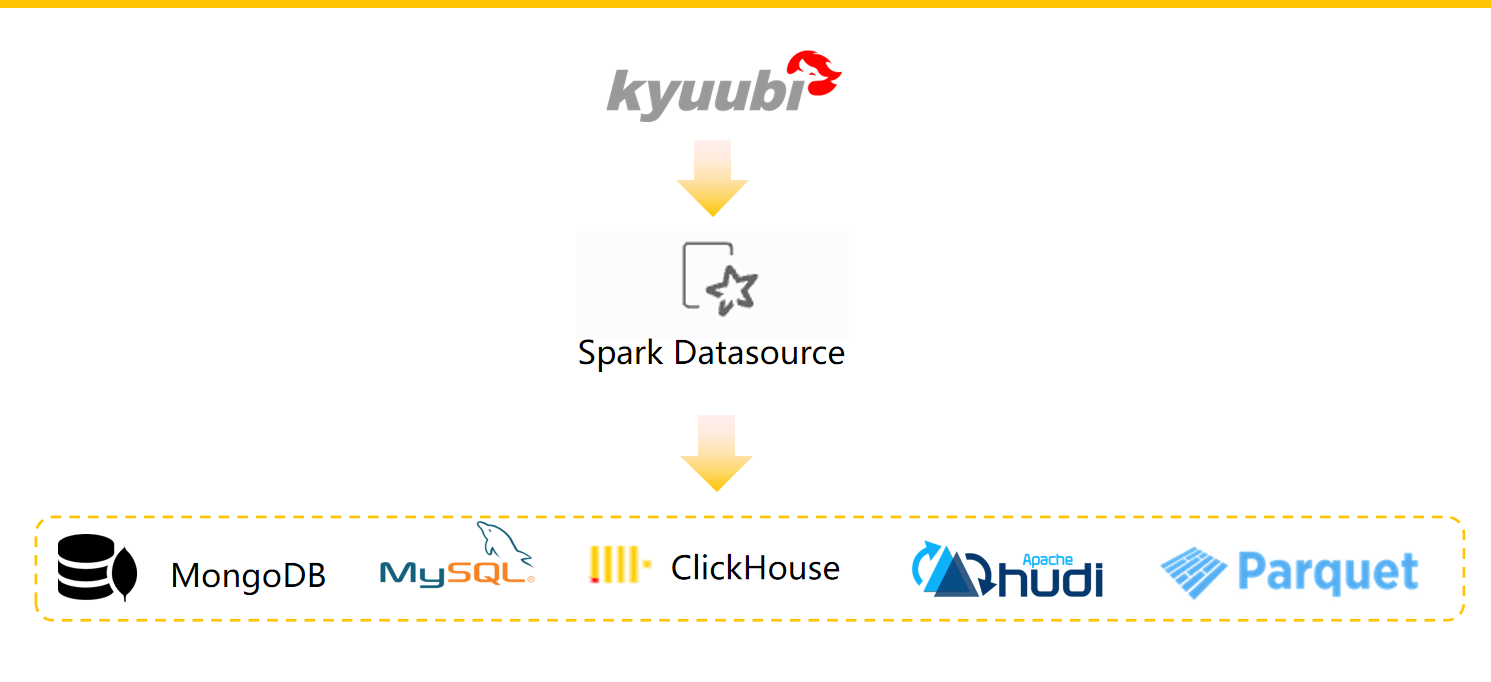
公司内部使用多种数据存储系统,这些不同的系统解决了对应的使用场景。除了传统的 RDBMS (比如 MySQL) 之外,我们还使用 Apache Kafka 来获取流和事件数据,还有 HBase、MongoDB,以及数据湖对象存储和 Hudi 格式的数据源。
我们知道,要将不同存储来源的数据进行关联,我们需要对数据进行提取,并放到同一种存储介质中,比如 HDFS,然后进行关联操作。这种数据割裂,会给我们的数据关联分析带来很大的麻烦,如果我们能够使用一种统一的查询引擎分别查询不同数据源的数据,然后直接进行关联操作,这将带来巨大的效率提升。
所以,我们利用 Spark DatasourceV2 实现了统一语法的跨存储联邦查询。其提供高效,统一的 SQL 访问。这样做的优势如下:
- 单个 SQL 方言和 API
- 统一安全控制和审计跟踪
- 统一控制
- 能够组合来自多个来源的数据
- 数据独立性
基于 Spark DatasourceV2 ,对于读取程序,我们只需定义一个 DefaultSource 的类,实现 ReadSupport 相关接口,就可以对接外部数据源,同时 SupportsPushDownFilters、SupportsPushDownRequiredColumns、SupportsReportPartitioning 等相关的优化,实现了算子下推功能。由此我们可以将查询规则下推到 JDBC 等数据源,在不同数据源层面上进行一些过滤,再将计算结果返回给 Spark,这样可以减少数据的量,从而提高查询效率。
现有方案是通过建立外部表,利用 HiveMeta Server 管理外部数据源的元信息, 对表进行统一多权限管理。
例如:MongoDB 表映射
CREATE EXTERNALTABLE mongo_test
USING com.mongodb.spark.sql
OPTIONS (
spark.mongodb.input.uri "mongodb://用户名:密码@IP:PORT/库名?authSource=admin",
spark.mongodb.input.database "库名",
spark.mongodb.input.collection "表名",
spark.mongodb.input.readPreference.name "secondaryPreferred",
spark.mongodb.input.batchSize "20000"
);后续升级 Spark3.X ,引入了 namespace 的概念后,DatasouceV2 可实现插件形式的Multiple Catalog 模式,这将大大提高联邦查询的灵活度。
Kyuubi 性能测试

我们基于 TPC-DS 生成了 500GB 数据量进行了测试。选用部分事实表和维度表,分别在 Hive 和 Kyuubi 上进行性能压测。主要关注场景有:
- 单用户和多用户场景
- 聚合函数性能对比
- Join 性能对比
- 单 stage 和多 stage 性能对比
压测结果对比,Kyuubi 基于 Spark 引擎大多数场景比 Hive 性能提升了3-6倍,同时多租户、并发的场景更加高效稳定。
T3出行对 Kyuubi 的改进与优化
我们对 Kyuubi 的改进和优化主要包括如下几个方面:
- Kyuubi Web:启动一个独立多 web 服务,监控管理 Kyuubi Server。
- Kyuubi EventBus:定义了一个全局的事件总线。
- Kyuubi Router:路由模块,可以将专有语法的 SQL 请求转发到不同的原生 JDBC 服务上。
- Kyuubi Spark Engine:修改原生 Spark Engine。
- Kyuubi Lineage:数据血缘解析服务,将执行成功多 SQL 解析存入图数据库,提供 API 调用。
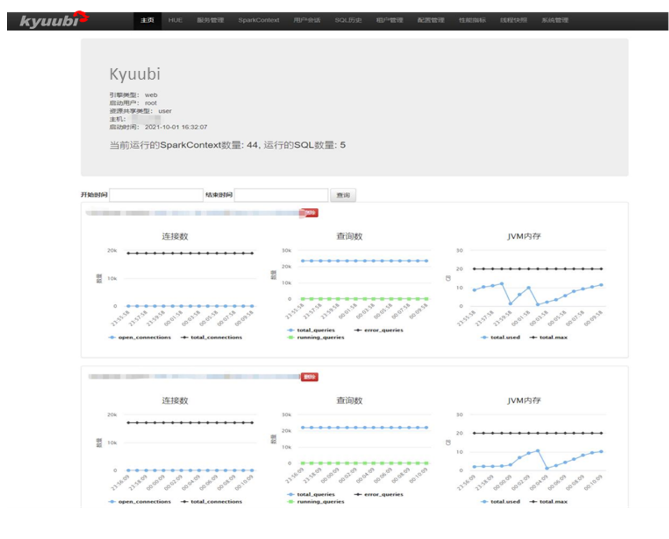
Kyuubi Web 服务功能
- 当前运行的 SparkContext 和 SQL 数量
- 各个 Kyuubi Server 实例状态
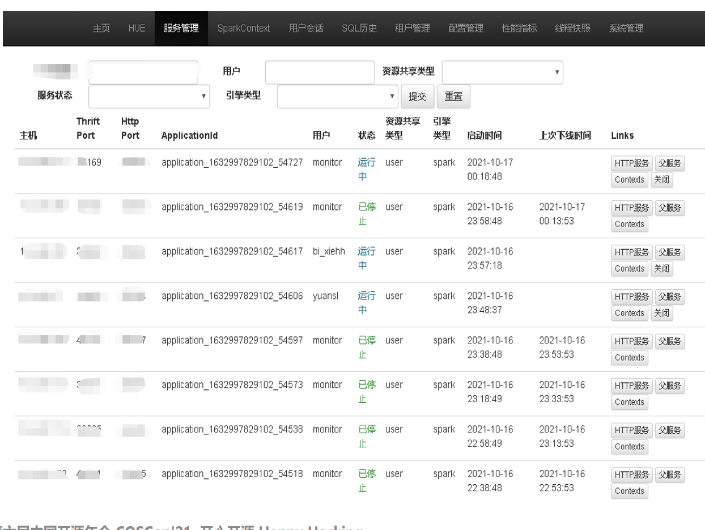
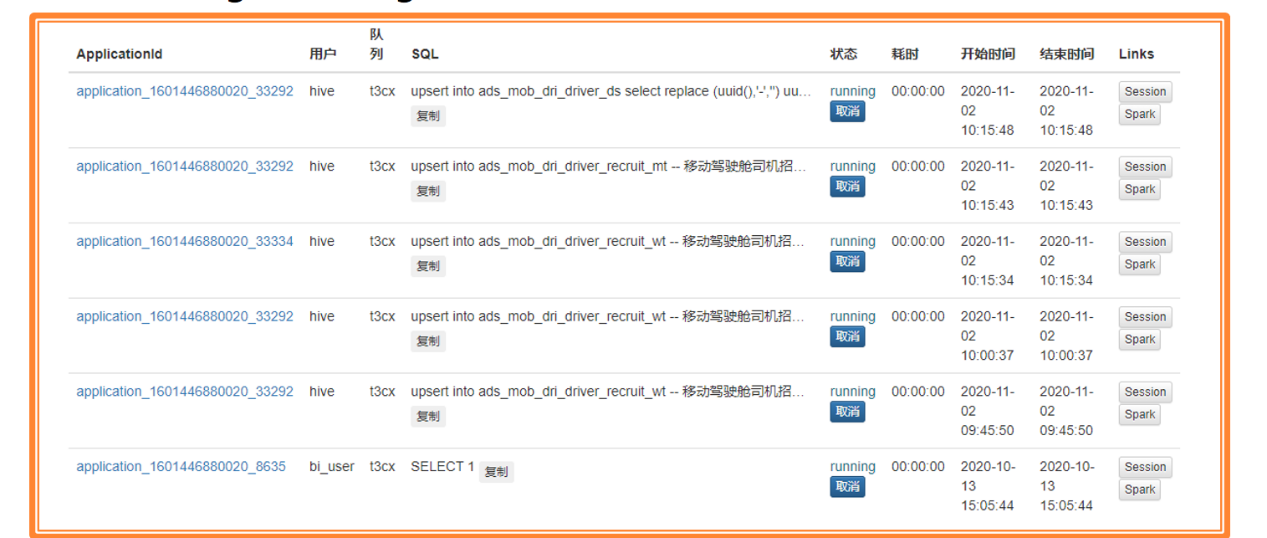
- Top 20: 1天内最耗时的 SQL
- 用户提交 SQL 排名(1天内)
- 展示各用户 SQL 运行的情况和具体语句
- SQL 状态分为:closed,cancelled,waiting和running。其中waiting和running 的 SQL 可取消
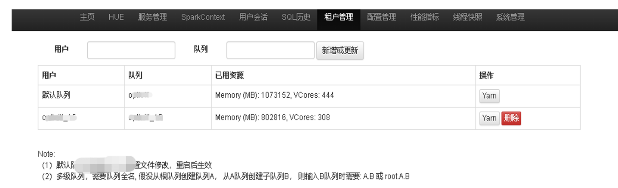
- 根据管理租户引擎对应队列和资源配置、并发量
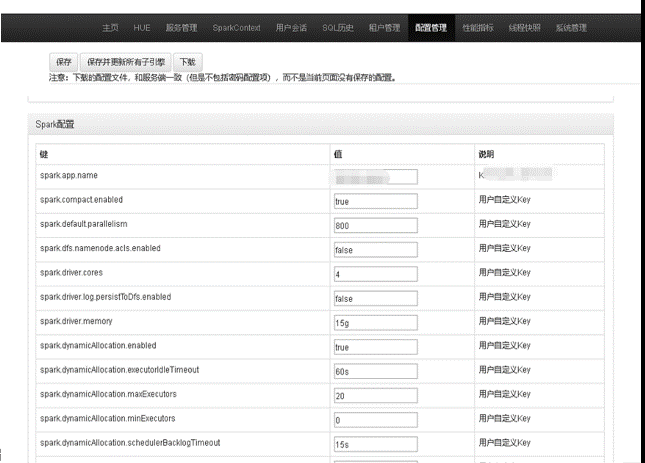
- 可以在线查看、修改 Kyuubi Server、Engine 相关配置
Kyuubi EventBus
Server 端引入了 RESTful Service。
在Server应用进程中,事件总线监听了包括应用停止时间、JDBC 会话关闭、JDBC 操作取消等事件。引入事件总线的目的,是为了在单个应用中和不同的子服务间进行通信。否则不同的子服务对象需要包含对方的实例依赖,服务对象的模型会非常复杂。

Kyuubi Router
增加了 Kyuubi JDBC Route 模块,JDBC 连接会先打向此服务。
该服务根据既定策略转发到不同服务。下图为具体策略。
Kyuubi Spark Engine
- 将 Kyuubi-Spark-Sql-Engine 的 Spark 3.X 版本改成了 Spark 2.4.5,适配集群版本,后续集群升级会跟上社区版本融合
- 增加了Hudi datasource 模块,使用 Spark datasource 计划查询 Hudi,提高对 Hudi 的查询效率
- 集成 Hudi 社区的 update、delete 语法,新增了 upsert 语法和 Hudi 建表语句

Kyuubi Lineage
基于 ANTLR 的 SQL 血缘解析功能。现有提供了两个模式,一个是定时调度,解析一定时间范围内的执行成功的 SQL 语句,将解析结果存储到 HugeGraph 图库中,用于数据治理系统等调用。另一个模式为提供 API 调用,查询时用户直接调用,SQL 复杂时可以直观理清自己的 SQL 逻辑,方便修改和优化自己的 SQL。
基于 Kyuubi 的解决方案

总结
T3出行大数据平台基于 Apache Kyuubi 0.8,实现了数据服务统一化,大大简化了离线数据处理链路,同时也能保障查询时延要求,之后我们将用来提升更多业务场景的数据服务和查询能力。最后,感谢 Apache Kyuubi 社区的相关支持。后续计划升级到社区的新版本跟社区保持同步,同时基于T3出行场景做的一些功能点,也会陆续回馈给社区,共同发展。也期望 Apache kyuubi 作为 Serverless SQL on Lakehouse 引领者越来越好!
作者:李心恺,T3出行高级大数据工程师
Kyuubi 主页:
https://kyuubi.apache.org/
Kyuubi 源码:
https://github.com/apache/incubator-kyuubi
Apache Kyuubi 在 T3 出行的深度实践的更多相关文章
- Apache Kyuubi 助力 CDH 解锁 Spark SQL
Apache Kyuubi(Incubating)(下文简称Kyuubi)是⼀个构建在Spark SQL之上的企业级JDBC网关,兼容HiveServer2通信协议,提供高可用.多租户能力.Kyuub ...
- TiDB 深度实践之旅--真实“踩坑”经历
美团点评 TiDB 深度实践之旅(9000 字长文 / 真实“踩坑”经历) 4 PingCAP · 154 天前 · 3956 次点击 这是一个创建于 154 天前的主题,其中的信息可能已经有所发 ...
- Zabbix监控系统深度实践
Zabbix监控系统深度实践(企业级分布式系统自动化运维必选利器,大规模Zabbix集群实战经验技巧总结,由浅入深全面讲解配置.设计.案例和内部原理) 姚仁捷 著 ISBN 978-7-121-24 ...
- 深度实践KVM笔记
深度实践KVM笔记 libvirt(virt-install,API,服务,virsh)->qemu(qemu-kvm进程,qemu-img)->KVM虚拟机->kvm.ko 内核模 ...
- Windows10 + eclipse + JDK1.8 + Apache Maven 3.6.0 + dl4j深度学习环境配置
Windows10 + eclipse + JDK1.8 + Apache Maven 3.6.0 + dl4j深度学习环境配置 JDK下载安装请自行,并设置好环境变量1 查看Java版本C:\Use ...
- [5.19 线下活动]Docker Meetup杭州站—拥抱Kubernetes,容器深度实践
对本次线下活动感兴趣的朋友,欢迎点击此处报名,领取免费票. 今年3月,Docker刚刚过完5岁生日,五年期间,Docker也逐渐在技术和实践方面趋于成熟,更是在去年年底主动拥抱Kubernetes. ...
- Springboot单元测试Junit深度实践
Springboot单元测试Junit深度实践 前言 单元测试的好处估计大家也都知道了,但是大家可以发现在国内IT公司中真正推行单测的很少很少,一些大厂大部分也只是在核心产品推广单测来保障质量,今天这 ...
- 触宝科技基于Apache Hudi的流批一体架构实践
1. 前言 当前公司的大数据实时链路如下图,数据源是MySQL数据库,然后通过Binlog Query的方式消费或者直接客户端采集到Kafka,最终通过基于Spark/Flink实现的批流一体计算引擎 ...
- 使用Scala开发Apache Kafka的TOP 20大好用实践
本文作者是一位软件工程师,他对20位开发人员和数据科学家使用Apache Kafka的方式进行了最大限度得深入研究,最终将生产实践环节需要注意的问题总结为本文所列的20条建议. Apache Kafk ...
随机推荐
- ARM平台如何玩转GDB远程调试?
前 言 关于GDB工具 GDB工具是GNU项目调试器,基于命令行使用.和其他的调试器一样,可使用GDB工具单步运行程序.单步执行.跳入/跳出函数.设置断点.查看变量等等,它是UNIX/LINUX操作 ...
- Javascript设计模式之原型模式、发布订阅模式
原型模式 原型模式用于在创建对象时,通过共享某个对象原型的属性和方法,从而达到提高性能.降低内存占用.代码复用的效果. 示例一 function Person(name) { this.name = ...
- apiserver源码分析——启动流程
前言 apiserver是k8s控制面的一个组件,在众多组件中唯一一个对接etcd,对外暴露http服务的形式为k8s中各种资源提供增删改查等服务.它是RESTful风格,每个资源的URI都会形如 / ...
- 11.5.2 LVS-NAT 实验
NAT拓扑 lvs-server VIP:10.211.55.99DIP:10.37.129.99 负载均衡器 开启路由功能(VIP桥接,DIP仅主机) rs01 RIP:10.37.129.3 后端 ...
- SpringBoot+WebSocket实时监控异常
写在前面 此异常非彼异常,标题所说的异常是业务上的异常. 最近做了一个需求,消防的设备巡检,如果巡检发现异常,通过手机端提交,后台的实时监控页面实时获取到该设备的信息及位置,然后安排员工去处理. 因为 ...
- 复杂对象List集合的排序
对于集合的排序,直接的有sort().间接的有借用compareTo.Comparable等,但是对于相对复杂的对象集合,还得自己实现方法来处理. 现在有这样一个思路: 第一步:从需要排序的对象集合中 ...
- netty系列之:让TLS支持http2
目录 简介 TLS的扩展协议NPN和ALPN SslProvider ApplicationProtocolConfig 构建SslContext ProtocolNegotiationHandler ...
- Apache Shiro漏洞绕过waf小tips
看了篇文章觉得不错记录下以免以后找不到,原理是通过base64解码特性导致waf不能成功解码绕过waf检测从而进行攻击 解码情况: payload php python openresty java ...
- 异常大讨论-抛出异常还是返回false
iteye精华帖之异常大讨论 原帖链接http://www.iteye.com/topic/2038 Robbin的观点 观点1:Exception实际上代表了一个UseCase中的异常流的处理. 绝 ...
- Java基础-Java8新特性
一.Lambda表达式 在了解 Lambda 之前,首先回顾以下Java的方法. Java的方法分为实例方法,例如:Integer的equals()方法: public final class Int ...