初识python 之 爬虫:爬取某网站的壁纸图片
用到的主要知识点:
requests.get 获取网页HTML
etree.HTML 使用lxml解析器解析网页
xpath 使用xpath获取网页标签信息、图片地址
request.urlretrieve 下载图片(注:该网站使用urlretrieve下载图片时,返回403错误。原因目前未知!)
改用 with as 下载图片:
with open('文件地址及名字', 'wb') as f:
f.write(res.content)
详细代码如下:
#!/user/bin env python
# author:Simple-Sir
# time:2019/7/17 10:14
# 爬取某网站的壁纸图片
import requests
from lxml import etree
from urllib import request
import urllib
import time # 伪装浏览器
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
}
# 获取壁纸首页网页信息并解析
def getUrlText(url):
respons = requests.get(url,headers=headers) # 获取网页信息
urlText = respons.text
html = etree.HTML(urlText) # 使用lxml解析网页
return html # 提取壁纸链接地址列表
def getWallUrl(url):
hrefUrl = getUrlText(url)
section = hrefUrl.xpath('//section[@class="thumb-listing-page"]')[0] # 获取section标签
hrefList = section.xpath('./ul//@href') # 获取首页图片对应链接地址
return hrefList # 获取当前时间
def getTime():
nowtime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
return nowtime # 解析壁纸下载地址
def downWall(url,page):
'''
:param url: 网页地址
:param page: 下载页数
:return: 下载结束提醒
'''
m = 0
page += 1
for i in range(1,page):
hrefList = getWallUrl(url+str(i))
n = 0
print('\033[36;1m*********** 开始下载第{}页壁纸 ************\033[0m'.format(i))
for href in hrefList:
n += 1
imgUrl = getUrlText(href) # 获取壁纸链接网页信息并解析
imgSrc = imgUrl.xpath('//img[@id="wallpaper"]/@src')[0]
# strUl = etree.tostring(imgSrc, encoding='utf-8').decode('utf-8') # 对获取到ul解码
# print(strUl)
imgType = imgSrc[-4:] # 壁纸格式
print('{}:\033[31;1m开始下载第{}页第{}张壁纸\033[0m'.format(getTime(),i,n))
# request.urlretrieve(imgSrc, './wall/' + str(n) + imgType) #403错误
res = requests.get(imgSrc)
with open('./wall/'+str(i)+'_'+str(n)+imgType, 'wb') as f:
f.write(res.content)
print('{}:\033[31;1m第{}页第{}张壁纸下载完成\033[0m'.format(getTime(),i,n))
m = m + n
return print('{}:\033[36;1m所有壁纸已下载完成,一共{}页{}张。\033[0m'.format(getTime(),i,m)) # url = 'https://wallhaven.cc/search?q=id%3A711&ref=fp&tdsourcetag=s_pcqq_aiomsg&page=' if __name__ == '__main__':
page =int(input('\033[36;1m请输入你想下载的页数:\033[0m'))
print('\033[36;1m程序执行中,请稍等。。。即将下载。\033[0m')
downWall('https://wall***&page=',page)
运行结果:


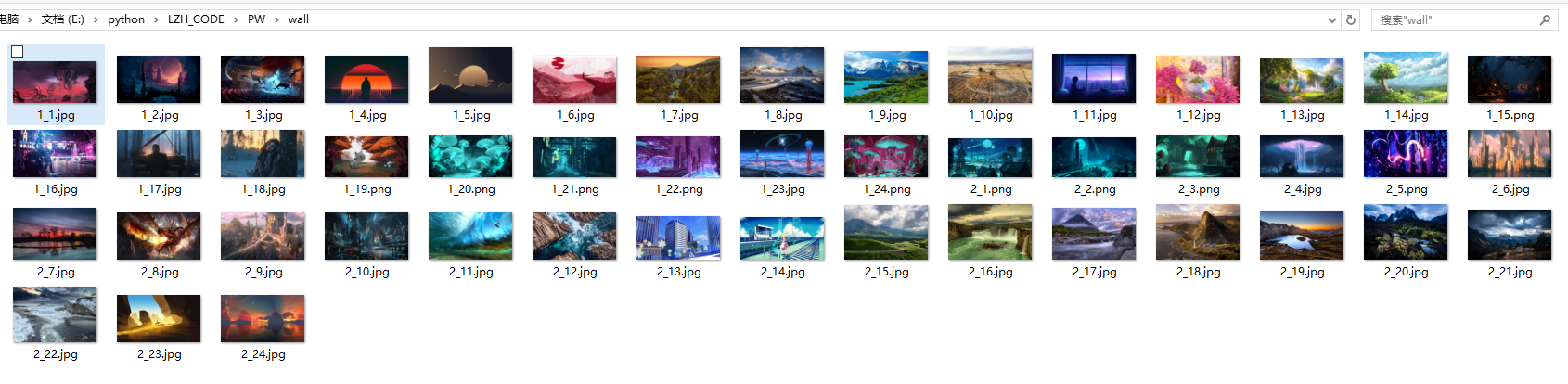
初识python 之 爬虫:爬取某网站的壁纸图片的更多相关文章
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- python爬虫--爬取某网站电影信息并写入mysql数据库
书接上文,前文最后提到将爬取的电影信息写入数据库,以方便查看,今天就具体实现. 首先还是上代码: # -*- coding:utf-8 -*- import requests import re im ...
- python之简单爬取一个网站信息
requests库是一个简介且简单的处理HTTP请求的第三方库 get()是获取网页最常用的方式,其基本使用方式如下 使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
- 利用python实现爬虫爬取某招聘网站,北京地区岗位名称包含某关键字的所有岗位平均月薪
#通过输入的关键字,爬取北京地区某岗位的平均月薪 # -*- coding: utf-8 -*- import re import requests import time import lxml.h ...
- Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
随机推荐
- SpringMvc分析
1.用户单击某个请求路径,发起一个request请求,此请求会被前端控制器(DispatcherServlet)处理 2.前端控制器(DispatcherServlet)请求处理器映射器(Handle ...
- JSP常用内置对象
1.request 1.1getAttribute(String name) 2.getAttributeName() 3.getCookies() 4.getCharacterEncoding() ...
- $(document).ready()与window.onload的区别,站在三个维度回答问题
1.执行时机 window.onload必须等到页面内包括图片的所有元素加载完毕后才能执行. $(document).ready()是DOM结构绘制完毕后就执行,不必等到加载完毕. 2 ...
- C# SAP Connector .NET Framework 4.5 版本下载
公司对接 SAP 数据使用 SAP Connector 程序,主要是两个类库:sapnco.dll.sapnco_utils.dll 但是没想到它的版本如此混乱,.NET 2.0 和 .NET 4.0 ...
- 万字长文入门 Redis 命令、事务、锁、订阅、性能测试
作者:痴者工良 Redis 基本数据类型 Redis 中,常用的数据类型有以下几种: String:字符串类型,二进制安全字符串: Hash:哈希表: List 列表:链表结构,按照插入顺序排序的字符 ...
- CF1059A Cashier 题解
Content 定义一天长度为 \(L\),每次休息的时间为 \(a\).一天会有 \(n\) 个客人到访,第 \(i\) 个客人会在 \(t_i\) 的时刻到访,会停留 \(l_i\) 的时间.只有 ...
- Tornado 异步浅解
7.1 认识异步 1. 同步 我们用两个函数来模拟两个客户端请求,并依次进行处理: #!/usr/bin/env python3 # -*- coding:utf-8 -*- # @Time: 202 ...
- 在Winform项目和Web API的.NetCore项目中使用Serilog 来记录日志信息
在我们常规的调试或者测试的时候,喜欢把一些测试信息打印在控制台或者记录在文件中,对于.netframework项目来说,我们输出控制台的日志信息习惯的用Console.WriteLine来输出查看,不 ...
- JAVA中BufferedImage与byte[]转换
BufferedImage转byte[] ByteArrayOutputStream out = new ByteArrayOutputStream(); ImageIO.write(imgBuff, ...
- JAVA将Byte数组(byte[])转换成文件
/** * 将Byte数组转换成文件 * @param bytes byte数组 * @param filePath 文件路径 如 D://test/ 最后"/"结尾 * @par ...