Spurious Local Minima are Common in Two-Layer ReLU Neural Networks
@article{safran2017spurious,
title={Spurious Local Minima are Common in Two-Layer ReLU Neural Networks},
author={Safran, Itay and Shamir, Ohad},
journal={arXiv: Learning},
year={2017}}
引
文章的论证部分让人头疼,仅在这里介绍一下主要内容. 这篇文章关注的是单个隐层, 激活函数为ReLU的神经网络, 且对输入数据有特殊的限制, 数据为:
\]
其中\(\mathbf{v}_i\)是给定的, 而\(\mathbf{x} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})\). 而这篇文章考虑的是:
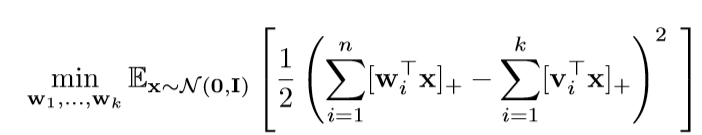
即, 这个损失函数是否具有局部最优解.
主要内容
定理1

注意, \(\mathbf{v}_1, \mathbf{v}_2, \ldots, \mathbf{v}_k\)是正交的, 且\(n=k\). 这个时候,损失函数是有局部最优解的, 不过在后面作者提到, 如果\(n>k\), 即overparameter的情况, 这个情况是大大优化的, 甚至出现没有局部最优解(不过是通过实验说明的).
推论1

引理1 引理2
这部分有些符号没有给出, 如果感兴趣回看论文, 这俩个引理是用来说明, 如何在实验中, 通过一些指标来判断是否收敛到某个极值点了(当然, 这需要特别的计算机制来避免舍入误差带来的影响, 作者似乎是通过Matlab里的一个包实现的).


Spurious Local Minima are Common in Two-Layer ReLU Neural Networks的更多相关文章
- Learning local feature descriptors with triplets and shallow convolutional neural networks 论文阅读笔记
题目翻译:学习 local feature descriptors 使用 triplets 还有浅的卷积神经网络.读罢此文,只觉收获满满,同时另外印象最深的也是一个浅(文章中会提及)字. 1 Cont ...
- 缓存地图 ArcGIS ——Local compact and exploded tile cache layer for WPF API
ArcGISArcGIS 主页 特色 合约 图库 地图 组 帮助 我的内容 我的组织 登录 我的个人资料 帮助 管理员指南 登出 0 搜索全部内容 搜索地图 搜索图层 搜索应用程序 搜索工具 搜索 ...
- Deep Linear Networks with Arbitrary Loss: All Local Minima Are Global
目录 问题 假设和重要结果 证明 注 Laurent T, Von Brecht J H. Deep linear networks with arbitrary loss: All local mi ...
- Visualizing LSTM Layer with t-sne in Neural Networks
LSTM 可视化 Visualizing Layer Representations in Neural Networks Visualizing and interpreting represent ...
- Local Binary Convolutional Neural Networks ---卷积深度网络移植到嵌入式设备上?
前言:今天他给大家带来一篇发表在CVPR 2017上的文章. 原文:LBCNN 原文代码:https://github.com/juefeix/lbcnn.torch 本文主要内容:把局部二值与卷积神 ...
- 课程一(Neural Networks and Deep Learning),第三周(Shallow neural networks)—— 3.Programming Assignment : Planar data classification with a hidden layer
Planar data classification with a hidden layer Welcome to the second programming exercise of the dee ...
- 论文解读(LA-GNN)《Local Augmentation for Graph Neural Networks》
论文信息 论文标题:Local Augmentation for Graph Neural Networks论文作者:Songtao Liu, Hanze Dong, Lanqing Li, Ting ...
- 论文翻译:LP-3DCNN: Unveiling Local Phase in 3D Convolutional Neural Networks
引言 传统的3D卷积神经网络(CNN)计算成本高,内存密集,容易过度拟合,最重要的是,需要改进其特征学习能力.为了解决这些问题,我们提出了整流局部相位体积(ReLPV)模块,它是标准3D卷积层的有效替 ...
- Neural Networks and Deep Learning(week3)Planar data classification with one hidden layer(基于单隐藏层神经网络的平面数据分类)
Planar data classification with one hidden layer 你会学习到如何: 用单隐层实现一个二分类神经网络 使用一个非线性激励函数,如 tanh 计算交叉熵的损 ...
随机推荐
- 学会这几步,简单集成视频编辑原子能力SDK
华为视频编辑服务6.2.0版本上线后,我们为大家带来了两大变化:分别是丰富多样的AI能力和灵活选择的集成方式.为让开发者更快上手使用,今天小编带来了视频编辑原子能力SDK的具体集成方法.快来试试吧! ...
- Ecshop 后台管理员密码忘记了吧~!~!~!
方法1:把下面的代码保存为文件 mima.php <?php define('IN_ECS', true); require(dirname(__FILE__) . '/includes/ini ...
- C语言中的使用内存的三段
1.正文段即代码和赋值数据段 一般存放二进制代码和常量 2.数据堆段 动态分配的存储区在数据堆段 3.数据栈段 临时使用的变量在数据栈段 典例 若一个进程实体由PCB.共享正文段.数据堆段和数据栈段组 ...
- fastjson转换数字时,格式化小数点
使用fastjson类库转换java对象时,对于BigDecimal类型,有时需要特殊格式,比如: 1.0,转为json时候,要求显式为1,因此需要在转换时做处理.步骤如下: 1.新建类,实现Valu ...
- Copy constructor vs assignment operator in C++
Difficulty Level: Rookie Consider the following C++ program. 1 #include<iostream> 2 #include&l ...
- dom4j解析XML学习
原理:把dom与SAX进行了封装 优点:JDOM的一个智能分支.扩充了其灵活性增加了一些额外的功能. package com.dom4j.xml; import java.io.FileNotFoun ...
- 如何将java对象转换成json数据
package cn.hopetesting.com.test;import cn.hopetesting.com.domain.User;import com.fasterxml.jackson.c ...
- 铁人三项(第五赛区)_2018_rop
拿到程序依旧老样子checksec和file一下 可以看到是32位的程序开启了nx保护,将程序放入ida进行查看 shift+f12 看到没有system和binsh等字样,考虑用泄露libc来做这道 ...
- 一道栈溢出babystack
我太天真了,师傅说让我做做这个平台的题,我就注册了个号,信心满满的打开了change,找到了pwn,一看第一道题是babystack,我想着,嗯,十分钟搞定他!直到我下载了题目,题目给了libc,然后 ...
- 我在这里的处女篇(Word技巧集团)
传说这里的文章可以在Word上打好了发布,Word嘛,有[听写]功能,不用打字了: 写好的文章还可以[大声朗读],边听边看最容易找"通假字"了. 冲这,我的新阵地就定这里了,哈哈~