Spark产生数据倾斜的原因以及解决办法
Spark数据倾斜
产生原因
首先RDD的逻辑其实时表示一个对象集合。在物理执行期间,RDD会被分为一系列的分区,每个分区都是整个数据集的子集。当spark调度并运行任务的时候,Spark会为每一个分区中的数据创建一个任务。大部分的任务处理的数据量差不多,但是有少部分的任务处理的数据量很大,因而Spark作业会看起来运行的十分的慢,从而产生数据倾斜(进行shuffle的时候)。
数据倾斜只会发生在shuffle过程中。这里给大家罗列一些常用的并且可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。出现数据倾斜时,可能就是你的代码中使用了这些算子中的某一个所导致的。例子:
多个key对应的values,比如一共是90万。可能某个key对应了88万数据,被分配到一个task上去面去执行。另外两个task,可能各分配到了1万数据,可能是数百个key,对应的1万条数据。这样就会出现数据倾斜问题。解决方法
(1):数据混洗的时候,使用参数的方式为混洗后的RDD指定并行度实现原理:提高shuffle操作的并行度,增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据,举例来说,如果原本有5个key,每个key对应10条数据,这5个key都是分配给一个task的,那么这个task就要处理50条数据。而增加了shuffle read task以后,每个task就分配到一个key,即每个task就处理10条数据,那么自然每个task的执行时间都会变短了(很简单,主要给我们所有的shuffle算子,比如groupByKey、countByKey、reduceByKey。在调用的时候,传入进去一个参数。那个数字,就代表了那个shuffle操作的reduce端的并行度。那么在进行shuffle操作的时候,就会对应着创建指定数量的reduce task)
方法的缺点:只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限,该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个key对应的数据量有100万,那么无论你的task数量增加到多少,这个对应着100万数据的key肯定还是会分配到一个task中去处理,因此注定还是会发生数据倾斜的。
(2)使用随机key实现双重聚合(groupByKey、reduceByKey比较适合使用这种方式)
实现原理:将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。
如下图所示:
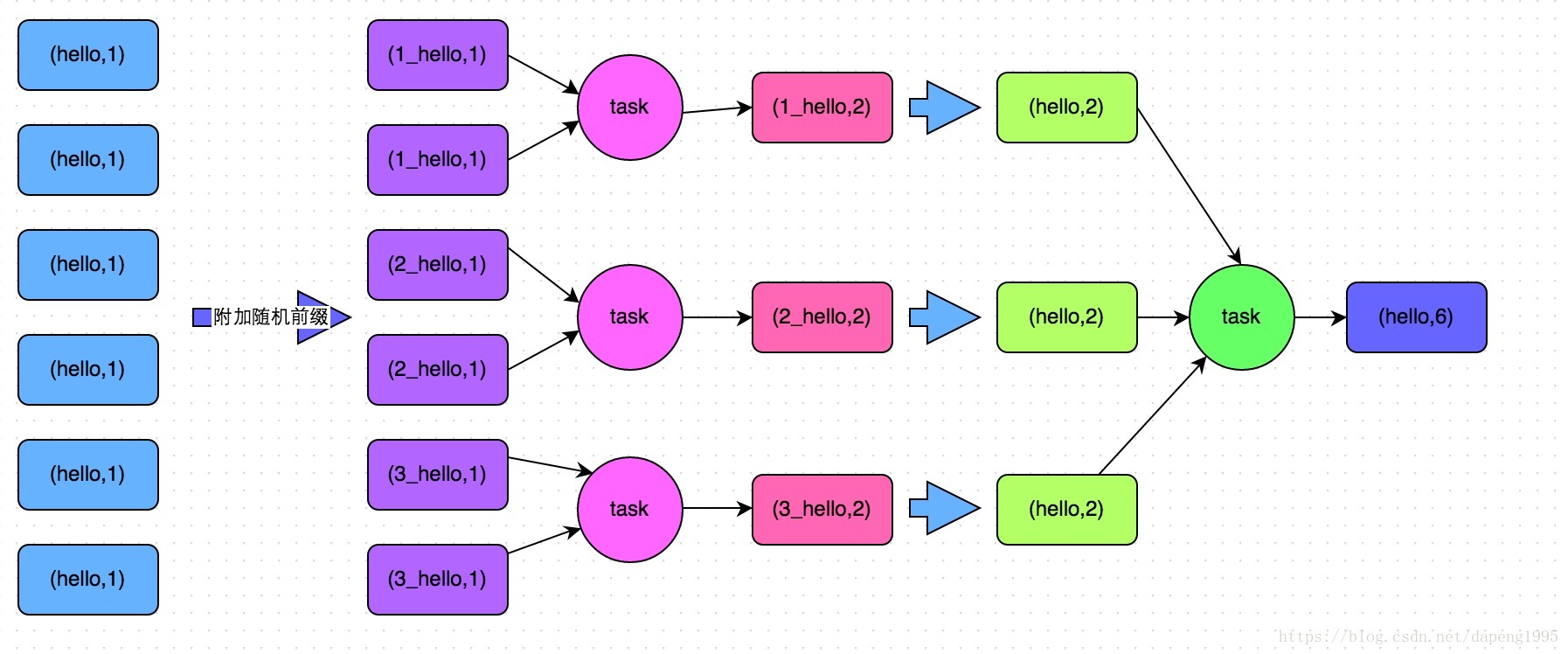
代码:
object DataLean {
def main(args: Array[String]): Unit = {
//创建Spark配置对象
val conf = new SparkConf();
conf.setAppName("WordCountScala")
conf.setMaster("local") ;
//通过conf创建sc
val sc = new SparkContext(conf);
val rdd1=sc.textFile("F:/spark/b.txt",3);
rdd1.flatMap(_.split(" ")).map((_,1)).map(t=>{
val word=t._1
val r=Random.nextInt(100)
(word+"_"+r,1)
}).reduceByKey(_+_).map(t=>{
val word=t._1
val count=t._2
val w=word.split("_")(0)
(w,count)
}).reduceByKey(_+_).saveAsTextFile("F:/spark/lean/out")
}
}(3):过滤少数导致倾斜的key
如果我们判断那少数几个数据量特别多的key,对作业的执行和计算结果不是特别重要的话,那么干脆就直接过滤掉那少数几个key。比如,在Spark SQL中可以使用where子句过滤掉这些key或者在Spark Core中对RDD执行filter算子过滤掉这些key。如果需要每次作业执行时,动态判定哪些key的数据量最多然后再进行过滤,那么可以使用sample算子对RDD进行采样,然后计算出每个key的数量,取数据量最多的key过滤掉即可。
参考文章:
1.https://blog.csdn.net/qq_38247150/article/details/80366769
2.https://blog.csdn.net/qq_38534715/article/details/78707759
Spark产生数据倾斜的原因以及解决办法的更多相关文章
- spark性能调优 数据倾斜 内存不足 oom解决办法
[重要] Spark性能调优——扩展篇 : http://blog.csdn.net/zdy0_2004/article/details/51705043
- Android手机出现"已安装了存在签名冲突的同名数据包"的原因及解决办法
http://blog.csdn.net/dyllove98/article/details/8830264 如果你不是开发者:如果你在android上更新一个已经安装过较早版本软件时,安装到最后一步 ...
- hive数据倾斜原因以及解决办法
何谓数据倾斜?数据倾斜指的是,并行处理的数据集 中,某一部分(如Spark的一个Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈. 表现为整体任务基本完成, ...
- Hive数据倾斜的原因及主要解决方法
数据倾斜产生的原因 数据倾斜的原因很大部分是join倾斜和聚合倾斜两大类 Hive倾斜之group by聚合倾斜 原因: 分组的维度过少,每个维度的值过多,导致处理某值的reduce耗时很久: 对一些 ...
- .Net内存泄露原因及解决办法
.Net内存泄露原因及解决办法 1. 什么是.Net内存泄露 (1).NET 应用程序中的内存 您大概已经知道,.NET 应用程序中要使用多种类型的内存,包括:堆栈.非托管堆和托管堆.这里我们需 ...
- HttpClient的CircularRedirectException异常原因及解决办法
HttpClient的CircularRedirectException异常原因及解决办法 这两天在使用我自己爬虫抓取网页的时候总是出现 org.apache.http.client.ClientPr ...
- mysql保存中文乱码的原因和解决办法
当你遇到这个mysql保存中文乱码问题的时候,期待找到mysql保存中文乱码的原因和解决办法这样一篇能解决问题的文章是多么激动人心. 也许30%的程序员会选择自己百度,结果发现网友已经贴了很多类 ...
- html页面顶部出现一段空白,检查控制台发现body 下出现字符,原因及解决办法
html页面顶部出现一段空白,检查控制台发现body 下出现字符,原因及解决办法 分析: 原来是页面编码时增加了BOM,此页面后端数据主要是PHP语言,对PHP来讲PHP在设计时 ...
- mysql数据库死锁的产生原因及解决办法
这篇文章主要介绍了mysql数据库锁的产生原因及解决办法,需要的朋友可以参考下 数据库和操作系统一样,是一个多用户使用的共享资源.当多个用户并发地存取数据 时,在数据库中就会产生多个事务同时存取同 ...
随机推荐
- best-time-to-buy-and-sell-stock-ii leetcode C++
Say you have an array for which the i th element is the price of a given stock on day i. Design an a ...
- Luogu P1563 [NOIp2016提高组]玩具谜题 | 模拟
题目链接 纯模拟题,没啥好说的,就是要判断地方有点多,一定要注意细节. #include<iostream> #include<cstdio> #include<fstr ...
- uni-app(Vue)中(picker)用联动(关联)选择以至于完成某些功能
如下图所示,在项目中需求是通过首先选择学生的专业,选好之后在每个专业下面选择对应的学期,每个学期有对应的学费,因此就需要联动选择来实现这一功能. 以下仅展示此功能主要代码: <div class ...
- SSH 提示密码过期,如何通过 ansible 批量更新线上服务器密码
起因 线上环境是在内网,登陆线上环境需要使用 VPN + 堡垒机 登陆,但是我日常登陆线上环境都是 VPN + 堡垒机 + Socks5常驻代理,在shell端只需要保存会话,会话使用socks5代理 ...
- CrawlSpider_获取图片名称地址,及入库
1.继承自scrapy.Spider 2.独门秘笈 CrawlSpider可以定义规则,再解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求 所以,如果有需要跟进链接的 ...
- Sentry 官方 JavaScript SDK 简介与调试指南
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- PAT A1060——string的常见用法详解
string 常用函数实例 (1)operator += 可以将两个string直接拼接起来 (2)compare operator 可以直接使用==.!=.<.<=.>.>= ...
- [atAGC106E]Medals
暴力二分答案+网络流,点数为$o(nk)$,无法通过 考虑Hall定理,即有完美匹配当且仅当$\forall S\subseteq V_{left}$,令$S'=\{x|\exists y\in V_ ...
- SpringCloud升级之路2020.0.x版-41. SpringCloudGateway 基本流程讲解(1)
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 接下来,将进入我们升级之路的又一大模块,即网关模块.网关模块我们废弃了已经进入维护状态的 ...
- mybatis-批量操作数据(list对象 )
在实际工作中老是忘记 传入的参数和数据库参数名称要一致还是与实体类型一致导致很多笑话发生. 那我还是做个记录吧! dao层: int addRemark(@Param("list" ...