HDFS05 NameNode和SecondaryNameNode
NameNode和SecondaryNameNode(了解)
NN 和 2NN 工作机制
问题1:NN的元数据存储在内存中还是磁盘中?
| 存储点 | 好处 | 坏处 |
|---|---|---|
| 内存 | 计算快 | 可靠性差 |
| 磁盘 | 可靠性高 | 计算速度慢 |
总和两者的好处,采用内存加磁盘的存储方式存储,磁盘中备份元数据Fslmage镜像文件。
如果内存中计算出结果之后,写入磁盘中,效率过低。引入了Edits编辑日志。
三个地方存储的内容
Fsimage:NameNode内存中元数据序列化后形成的文件。
Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
内存中有的数据=fslmage镜像文件的数据+Edits的操作
服务器一启动将 fslmage镜像文件的数据+Edits的操作 的结果加载到内存。因此,需要定期进行 FsImage 和 Edits 的合并,引入一个新的节点SecondaryNamenode,协助nn在过程中 FsImage 和 Edits 的合并。
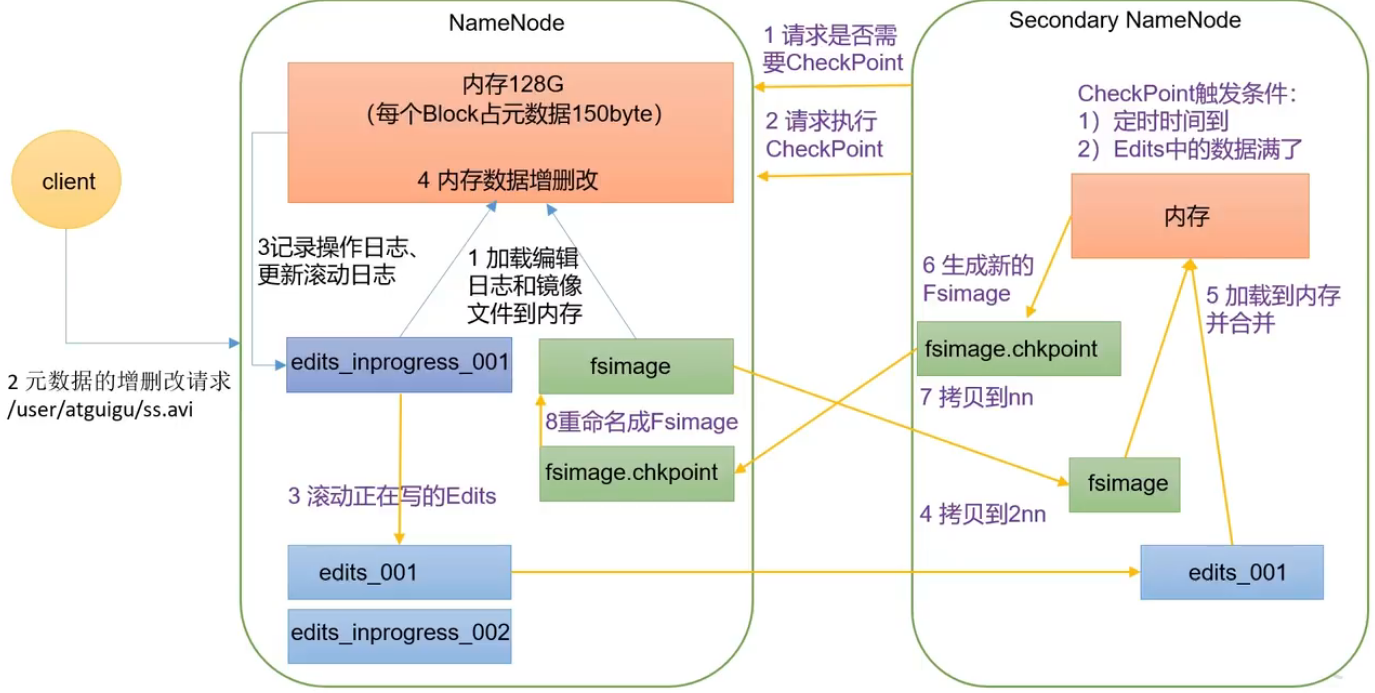
NameNode工作机制
1.第一次启动 NameNode 格式化后,创建 Fsimage镜像文件、和 Edits编辑日志文件edits_inprogress_001。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
2.客户端对元数据访问,如增删改请求。
3.记录操作日志、更新滚动日志。
4.NameNode 在内存中对元数据进行增删改。
Secondary NameNode
1.Secondary NameNode 询问 NameNode 是否需要 CheckPoint,直接带回 NameNode是否检查结果。
问题1:多久询问一次NameNode,checkPoint触发条件。
①定时时间到了,默认一个小时
②Edits中的数据满了
2.Secondary NameNode 请求执行 CheckPoint。
3.NameNode 滚动正在写的Edits日志。
问题2:怎么滚动的?
edits滚动生成一个新的edits.inprogress文件edits_inprogress_002。原来的edits_inprogress_001修改名称为edits_001,之后的操作都记录在edits_inprogress_002。
4.将edits_001和镜像文件fsimage拷贝到Secondary NameNode。
5.Secondary NameNode 加载编辑日志edits_001和镜像文件到内存。
6.合并生成新的镜像文件fsimage.chkpoint。
7.拷贝 fsimage.chkpoint 到 NameNode。
8.NameNode 将 fsimage.chkpoint 重新命名成 fsimage。
下次启动就将新的fsimage和edits_inprogress_002的内容加在一起就是最新的元数据。
Fsimage 和 Edits 解析
NameNode服务器在hadoop102,在NameNode目录下有Fsiamge和Edits文件,NameNode目录/opt/module/hadoop-3.1.3/data/dfs/name/current。
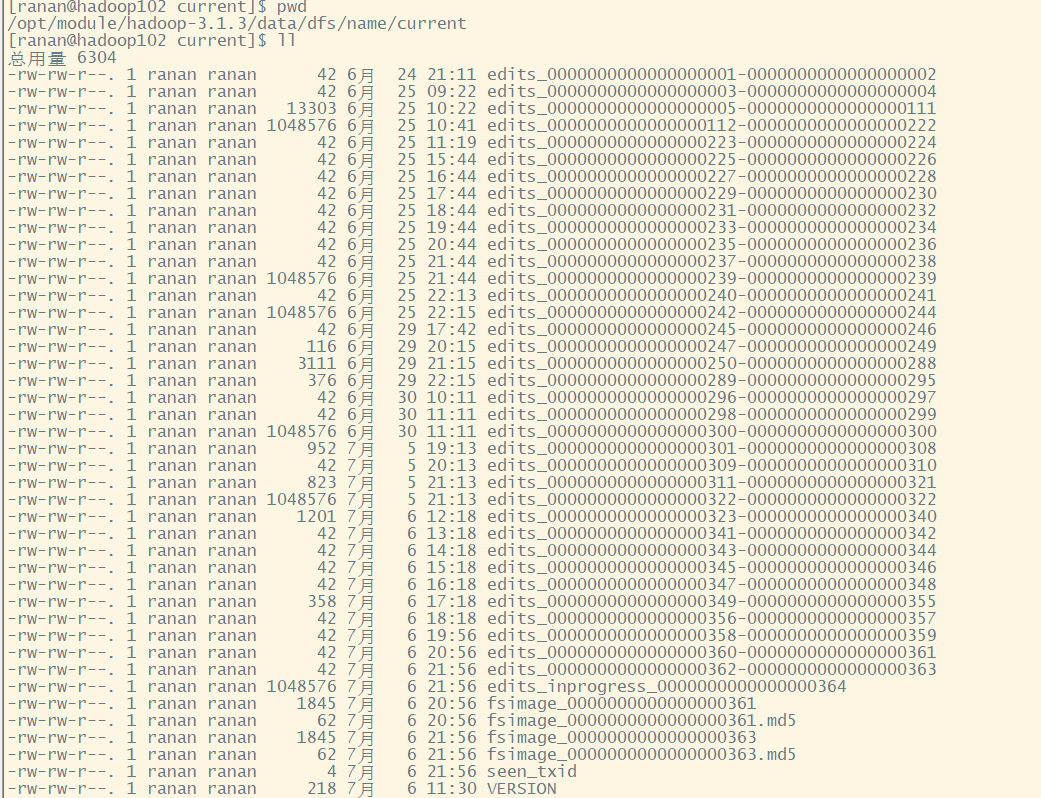
Secondary NameNode服务器在hadoop104,Secondary NameNode目录/opt/module/hadoop-3.1.3/data/dfs/namesecondary/current/
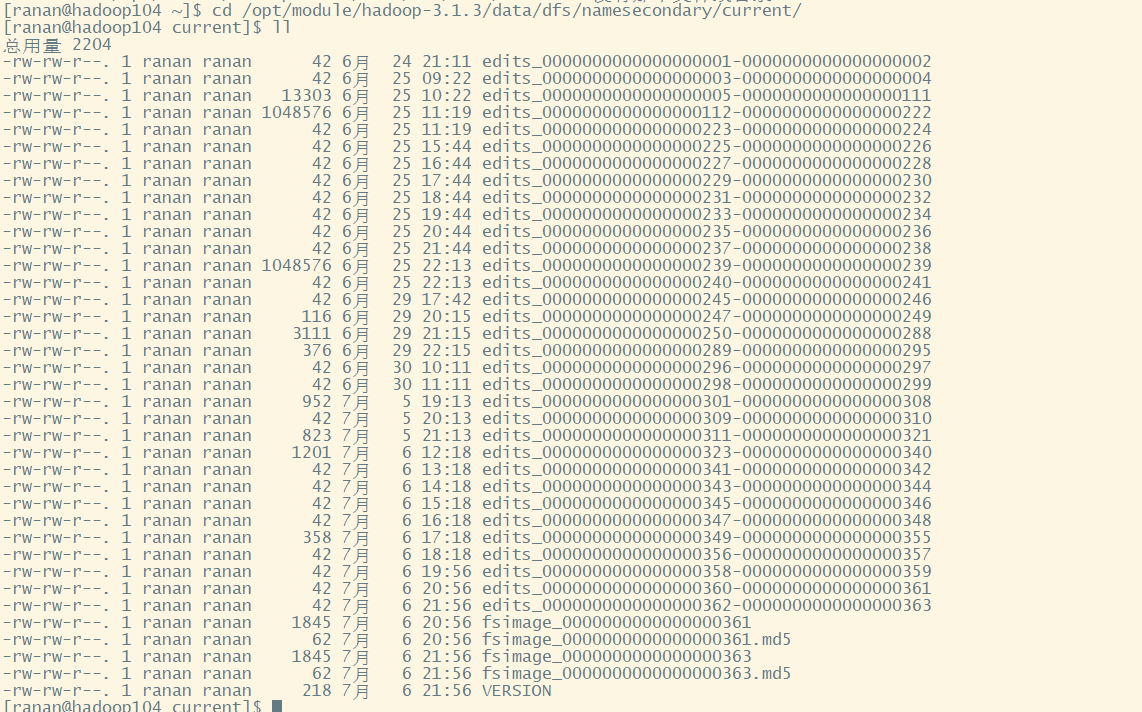
NameNode比Secondary NameNode多一个edits_inprogress_xxxx,最新的操作

NameNode在格式化(初始化)之后,会在/opt/module/hadoop-3.1.3/data/dfs/name/current目录中产生如下文件

oiv查看 Fsimage 文件
oiv和oev查看命令
oiv 查看Fsiamge文件
oev 查看Edits文件
基本语法
dfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径
正常通过cat看镜像文件看不了,全是乱码,需要通过-p把镜像文件转换成其他格式,输出在其他路径下。
案例
[ranan@hadoop102 current]$ hdfs oiv -p XML -i fsimage_0000000000000000363 -o /opt/software/fsimage.xml

将fsimage.xml下载到桌面,SecureCRT设置默认下载/上传路径
[ranan@hadoop102 software]$ sz fsimage.xml
fsimage.xml文件内容理解
文件组成
<INodeDirectorySection>
<inode> ... </inode>
<inode> ... </inode>
</INodeDirectorySection>
<INodeDirectorySection>..</INodeDirectorySection>
<INodeDirectorySection>..</INodeDirectorySection>
主要内容
<inode>
<id>16417</id>
<type>FILE</type> ------ 文件类型:常规文件(如果是文件夹则为 'DIRECTORY')
<name>b.xml</name> ----- 文件名
<replication>3</replication> --- 副本数
<mtime>1603342078483</mtime> --- 创建时间
<atime>1603342078253</atime> --- 修改时间
<perferredBlockSize>134217728</perferredBlockSize> --- 块大小
<permission>ranan:supergroup:rw-r--r--</permission> --- 权限
<blocks> ---- 被切成了几个块
<block> ---- 第一个块
<id>1073741836</id> ----- 块的id
<genstamp>1013</genstamp> --- 块的时间戳
<numBytes>313</numBytes> --- 块中存放的数据的大小(该文件只有一个块,该大小即为文件大小)
</block>
</blocks>
</inode>
问题:Fsimage 中没有记录块所对应 DataNode,为什么?
在集群启动后,要求 DataNode 上报数据块信息,并间隔一段时间后再次上报。
oev查看Edits文件
基本语法
dfs oev -p 文件类型 -i 日志文件 -o 转换后文件输出路径
正常通过cat看镜像文件看不了,全是乱码,需要通过-p把镜像文件转换成其他格式,输出在其他路径下。
案例
[ranan@hadoop102 current]$ hdfs oev -p XML -i edits_inprogress_0000000000000000400 -o /opt/software/edits.xml
将edits.xml下载到桌面
[ranan@hadoop102 software]$ sz edits.xml
edits.xml文件内容理解
文件组成
一个edits文件记录了一次写文件的过程,该过程被分解成多个部分进行记录;(每条记录在hdfs中有一个编号)
<RECORD> ---一个部分
<OPCODE> ... </OPCODE>
<DATA> ... </DATA>
</RECORD>
<RECORD> ---一个部分
<OPCODE> ... </OPCODE>
<DATA> ... </DATA>
</RECORD>
文件内容理解,写入a.xml
1.文件首<OPCODE>OP_START_LOG_SEGMENT</OPCODE>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE> --- 表示对一次写操作记录的开始
<DATA>
<TXID>138</TXID> ---------- HDFS的第138号记录
</DATA>
</RECORD>
2.写入临时文件夹 <OPCODE>OP_ADD</OPCODE>
写入 'a.xml' 文件的过程中,会先将文件写到临时文件a.xml._COPYING_中,最后再将该文件重命名后存放到DN;
<RECORD>
<OPCODE>OP_ADD</OPCODE> ------------- 写文件操作
<DATA>
<TXID>139</TXID> ---------------- HDFS的第139号记录
<LENGTH>0</LENGTH>
<INODEID>16416</INODEID>
<PATH>/a.xml._COPYING_</PATH> --- 写'a.xml'文件的过程中生成临时文件'a.xml._COPYING'
<REPLICATION>3</REPLICATION> --- 副本数
<MTIME>1603341874966</MTIME> --- 创建时间
<ATIME>1603341874966</ATIME> --- 修改时间
<BLOCKSIZE>134217728</BLOCKSIZE> --- 文件块的大小:128M
<CLIENT_NAME>DFSClient_NONMAPREDUCE_-1327338057_1</CLIENT_NAME> ---- 来源哪个客户端
<CLIENT_MACHINE>192.168.10.102</CLIENT_MACHINE> --------------- 通过哪个机器上传的
<OVERWRITE>true</OVERWRITE> --------------- 是否允许被覆盖
<PERMISSION_STATUS> ---------- 权限信息
<USERNAME>ranan</USERNAME> ---------- 所属主
<GROUPNAME>supergroup</GROUPNAME> ---------- 所属组
<MODE>420</MODE> ---------- 权限大小(777最大)
</PERMISSION_STATUS>
<RPC_CLIENTID>3299ce83-ba14-4468-8cf8-b5edb5dea153</RPC_CLIENTID> ---- 集群ID
<RPC_CALLID>3</RPC_CALLID>
</DATA>
</RECORD>
3.分配块id<OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE>
<RECORD>
<OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE> ---- 表示该步为记录 “定义块ID”
<DATA>
<TXID>140</TXID> ---- HDFS的第140号记录
<BLOCK_ID>1073741835</BLOCK_ID> ----- 块ID
</DATA>
</RECORD>
4.为块生成一个时间戳<OPCODE>OP_SET_GENSTAMP_V2</OPCODE>
<RECORD>
<OPCODE>OP_SET_GENSTAMP_V2</OPCODE>
<DATA>
<TXID>141</TXID>
<GENSTAMPV2>1012</GENSTAMPV2>
</DATA>
</RECORD>
5.添加块<OPCODE>OP_ADD_BLOCK</OPCODE>
<RECORD>
<OPCODE>OP_ADD_BLOCK</OPCODE>
<DATA>
<TXID>142</TXID>
<PATH>/a.xml._COPYING_</PATH>
<BLOCK>
<BLOCK_ID>1073741835</BLOCK_ID>
<NUM_BYTES>0</NUM_BYTES>
<GENSTAMP>1012</GENSTAMP>
</BLOCK>
<RPC_CLIENTID></RPC_CLIENTID>
<RPC_CALLID>-2</RPC_CALLID>
</DATA>
</RECORD>
6.封闭文件<OPCODE>OP_CLOSE</OPCODE>
<RECORD>
<OPCODE>OP_CLOSE</OPCODE>
<DATA>
<TXID>143</TXID>
<LENGTH>0</LENGTH>
<INODEID>0</INODEID>
<PATH>/a.xml._COPYING_</PATH>
<REPLICATION>3</REPLICATION>
<MTIME>1603341875516</MTIME>
<ATIME>1603341874966</ATIME>
<BLOCKSIZE>134217728</BLOCKSIZE>
<CLIENT_NAME></CLIENT_NAME>
<CLIENT_MACHINE></CLIENT_MACHINE>
<OVERWRITE>false</OVERWRITE>
<BLOCK>
<BLOCK_ID>1073741835</BLOCK_ID>
<NUM_BYTES>313</NUM_BYTES>
<GENSTAMP>1012</GENSTAMP>
</BLOCK>
<PERMISSION_STATUS>
<USERNAME>ranan</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>420</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
7.重命名临时文件 'a.xml.COPYING' 为 'a.xml' <OPCODE>OP_RENAME_OLD</OPCODE>
<RECORD>
<OPCODE>OP_RENAME_OLD</OPCODE>
<DATA>
<TXID>144</TXID>
<LENGTH>0</LENGTH>
<SRC>/a.xml._COPYING_</SRC>
<DST>/a.xml</DST>
<TIMESTAMP>1603341875552</TIMESTAMP>
<RPC_CLIENTID>3299ce83-ba14-4468-8cf8-b5edb5dea153</RPC_CLIENTID>
<RPC_CALLID>8</RPC_CALLID>
</DATA>
</RECORD>
问题:NameNode如何确定下次开机启动的时候合并哪些Edits

注意时间,看到每间隔1h进行一次合并
集群开关机要合并一次
CheckPoint时间设置
hdfs-default.xml
1.通常情况下,SecondaryNameNode每隔一小时执行一次CheckPoint
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600s</value>
</property>
2.一分钟检查一次操作次数,当操作次数达到 1 百万时,SecondaryNameNode执行一次CheckPoint
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60s</value>
<description> 1 分钟检查一次操作次数</description>
</property>
HDFS05 NameNode和SecondaryNameNode的更多相关文章
- NameNode和SecondaryNameNode工作原理剖析
NameNode和SecondaryNameNode工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode中的元数据是存储在那里的? 1>.首先,我 ...
- NameNode和SecondaryNameNode(面试开发重点)
NameNode和SecondaryNameNode(面试开发重点) 1 NN和2NN工作机制 思考:NameNode中的元数据是存储在哪里的? 首先,我们做个假设,如果存储在NameNode节点的磁 ...
- hadoop及NameNode和SecondaryNameNode工作机制
hadoop及NameNode和SecondaryNameNode工作机制 1.hadoop组成 Common MapReduce Yarn HDFS (1)HDFS namenode:存放目录,最重 ...
- HDFS【Namenode、SecondaryNamenode、Datanode】
目录 一. NameNode和SecondaryNameNode 1.NN和2NN 工作机制 2. NN和2NN中的fsimage.edits分析 3.checkpoint设置 4.namenode故 ...
- 一探究竟:Namenode、SecondaryNamenode、NamenodeHA关系
NameNode与Secondary NameNode 很多人都认为,Secondary NameNode是NameNode的备份,是为了防止NameNode的单点失败的,其实并不是在这样.文章Sec ...
- NameNode 与 SecondaryNameNode 的工作机制
一.NameNode.Fsimage .Edits 和 SecondaryNameNode 概述 NameNode:在内存中储存 HDFS 文件的元数据信息(目录) 如果节点故障或断电,存在内存中的数 ...
- Hadoop(9)-HDFS的NameNode和SecondaryNameNode详解
1.NN和2NN工作机制 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中,一旦 ...
- NameNode和SecondaryNameNode的工作机制
NameNode&Secondary NameNode 工作机制 NameNode: 1.启动时,加载编辑日志和镜像文件到内存 2.当客户端对元数据进行增删改,请求NameNode 3.Nam ...
- 浅谈HDFS(二)之NameNode与SecondaryNameNode
NN与2NN工作机制 思考:NameNode中的元数据是存储在哪里的? 假设存储在NameNode节点的硬盘中,因为经常需要随机访问和响应客户请求,必然效率太低,所以是存储在内存中的 但是,如果存储在 ...
随机推荐
- linux 蓝牙开发调试(rtl8821cs模块)
刚调完rtl8821cs的wifi功能,项目需要打通蓝牙配网功能. 调试过程中遇到各种问题中间几乎放弃,倒腾了几天最后还是打通了,顺便记录下过程. 通信接口:SDIO @WiFi.Uart @BT;工 ...
- springboot入门之版本依赖和自动配置原理
前言 Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that ...
- .NET Conf 2021 正在进行中,带你看一看微软带来了什么内容
今年最大的.NET活动正在进行, 可以通过Channel9 https://channel9.msdn.com/Events/dotnetConf/2021 看具体的Session .微软和社区一直在 ...
- 聊一聊声明式接口调用与Nacos的结合使用
背景 对于公司内部的 API 接口,在引入注册中心之后,免不了会用上服务发现这个东西. 现在比较流行的接口调用方式应该是基于声明式接口的调用,它使得开发变得更加简化和快捷. .NET 在声明式接口调用 ...
- Python基础(API接口测试)
import flask,json,pymysql from flask import request, jsonify, Response from datetime import datetime ...
- 环境(8)Linux用户组权限
一:Linux时间日期-时间同步策略 1.日期与时间 ①时间命令 data:查看当前系统时间 cal :查看日历 cal 2020 修改时间: date -s 11:11:11 ...
- 导出 doc
... /** * 导出word * @return * @throws Exception */ @JCall public String word() throws Exception{ Stri ...
- ubuntu更換清華軟件源
打开软件源的编辑sudo gedit /etc/apt/sources.list 软件源: Ubuntu--更改国内镜像源(阿里.网易.清华.中科大) 打開軟件源文件進行修改: 使用 sudo vim ...
- Spark SQL知识点大全与实战
Spark SQL概述 1.什么是Spark SQL Spark SQL是Spark用于结构化数据(structured data)处理的Spark模块. 与基本的Spark RDD API不同,Sp ...
- [cf1240F]Football
(事实上,总是可以让每一场都比,因此$w_{i}$并没有意义) 当$k=2$时,有如下做法-- 新建一个点,向所有奇度数的点连边,并对得到的图求欧拉回路,那么只需要将欧拉回路上的边交替染色,即可保证$ ...