【Spark】【RDD】初次学习RDD 笔记 汇总
RDD
Author:萌狼蓝天
【哔哩哔哩】萌狼蓝天
【博客】https://mllt.cc
【博客园】萌狼蓝天 - 博客园
【微信公众号】mllt9920
【学习交流QQ群】238948804
@萌狼蓝天
【!】启动spark集群
【!】启动
spark-shell
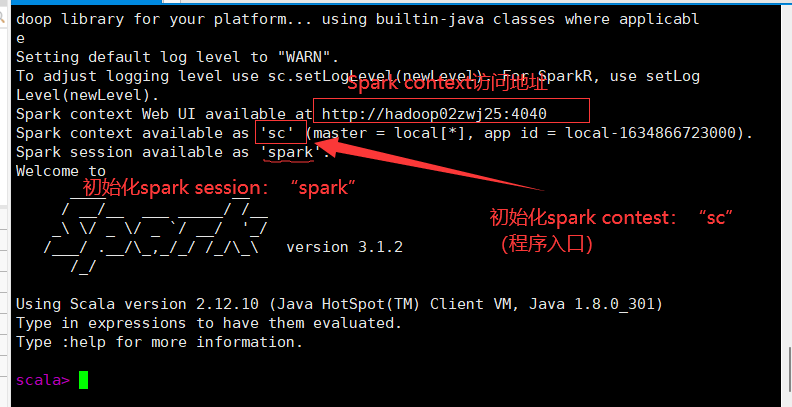
spark2.0将spark context 和hive context集成到了spark session
spark也可以作为程序入口
spark用scala编程

特点
它是集群节点上的不可改变的、已分区的集合对象;
- 通过并行转换的方式来创建如(map、filter、join等);
- 失败自动重建;
- 可以控制存储级别(内存、磁盘等)来进行重用;
- 必须是可序列化的;在内存不足时可自动降级为磁盘存储,把RDD存储于磁盘上,这时性能有大的下降但不会差于现在的MapReduce;
- 对于丢失部分数据分区只需要根据它的lineage就可重新计算出来,而不需要做特定的checkpoint;
创建
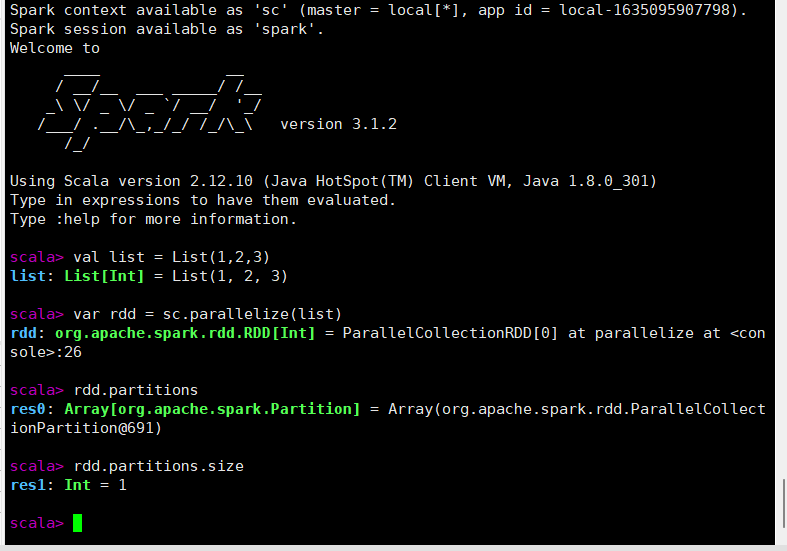
从内存中创建RDD
启动spark-shell
val list = List(1,2,3)
var rdd = sc.parallelize(list)
rdd.partitions.size
从外部存储创建RDD
1.创建本地文件
cd /home
mkdir data
touch a.txt
- 不一定非要在家目录创建
- 可以使用vim在a.txt中添加一些内容
2.启动spark-shell
3.从本地文件系统中读取
val localrdd = sc.textFile("file:///home/用户名/data/a.txt")
路径前面加
file://表示从本地文件系统读取

localrdd.collect//返回RDD中所有的元素
注意:若在完全分布式spark-shell模式下,该文件需要在所有节点的相同位置保存才可以被读取,否则会报错“文件不存在”

从HDFS创建RDD
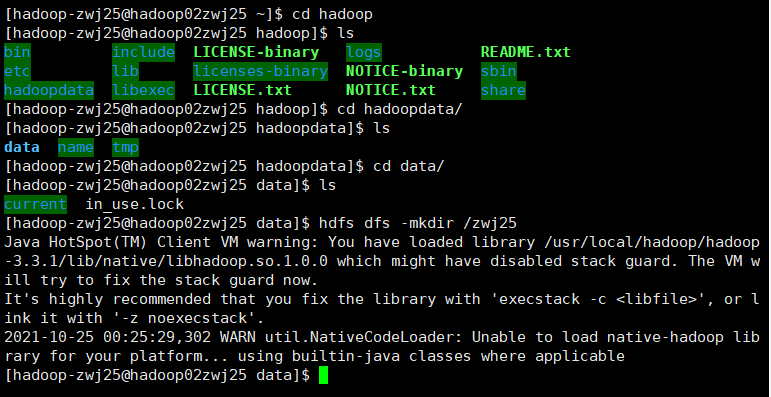
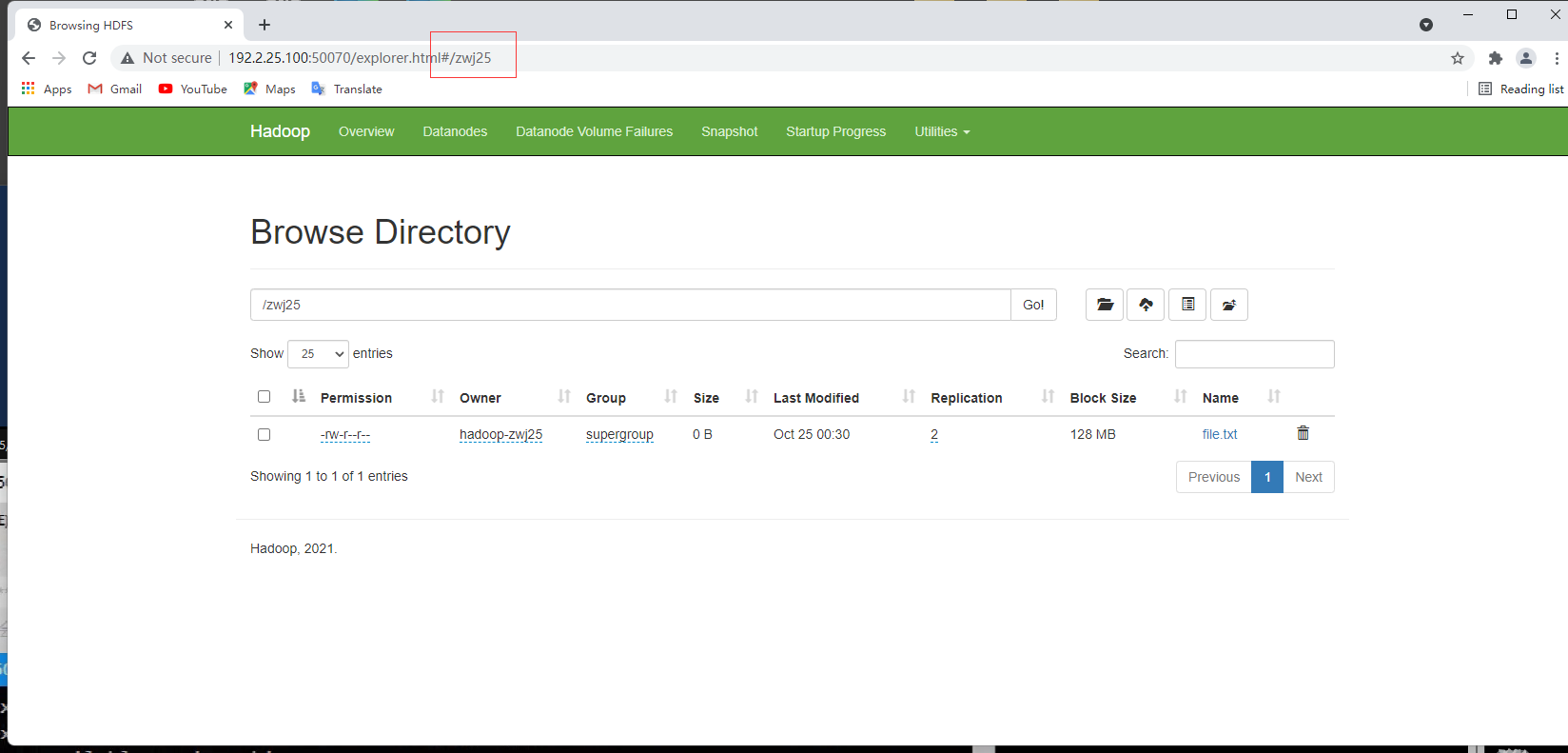
1.在HDFS根目录下创建目录(姓名学号)
hdfs dfs -mkdir /zwj25
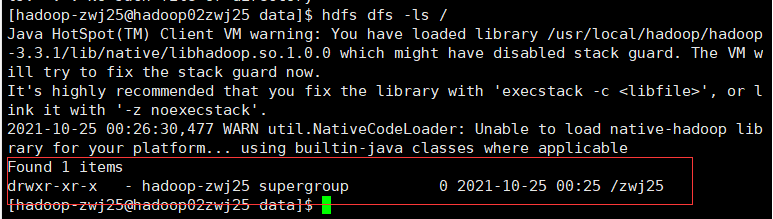
hdfs dfs -ls /
访问 http://[IP]:50070
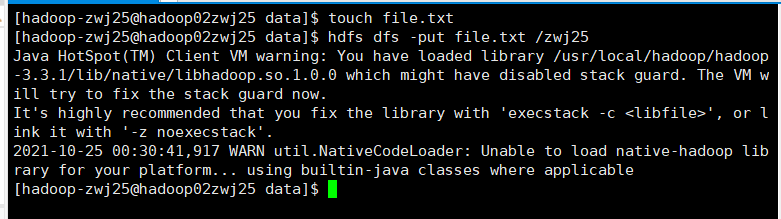
2.上传本地文件到HDFS
hdfs dfs -put file.txt /zwj25
3.进入spark4-shell
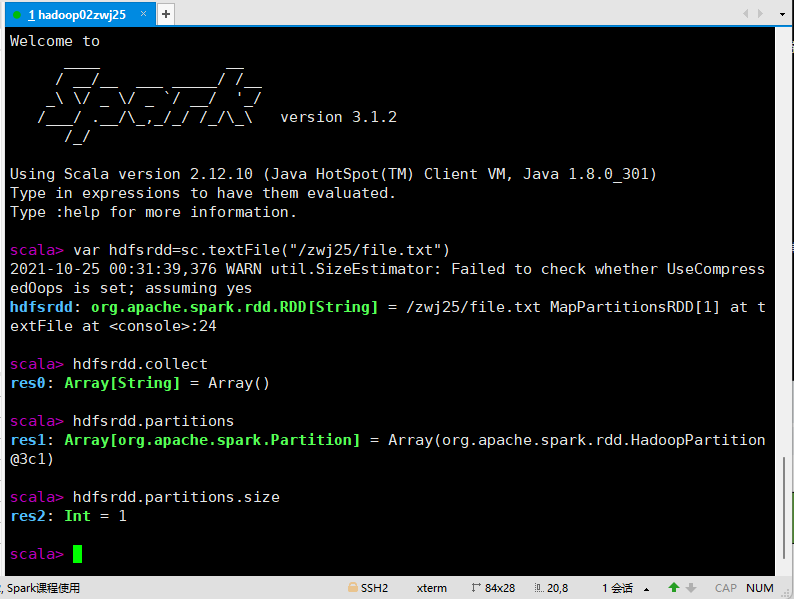
var hdfsrdd=sc.textFile("/zwj25/file.txt")
hdfsrdd.collect
hdfsrdd.partitions
hdfsrdd.partitions.size
sc.defaultMinPartitions=min(sc.defaultParallelism,2)
rdd分区数=max(hdfs文件的block数目,sc.defaultMinPartitions)
从其他RDD创建
算子
map(func)
类型:Transformation类型算子
map: 将原来RDD的每个数据项通过map中的用户自定义函数f转换成一个新的RDD,map操作不会改变RDD的分区数目
filter 过滤
filter(func)
Transformation类型算子
保留通过函数func,返回值为true的元素,组成新的RDD
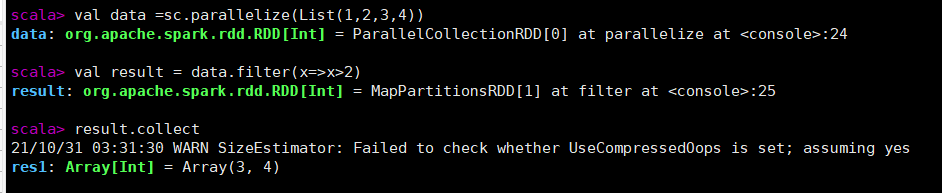
eg:过滤掉data RDD中元素小于或等于2的元素
val data =sc.parallelize(List(1,2,3,4))
val result = data.filter(x=>x>2)
result.collect
flatMap(func) 分割单词
类型:Transformation类型算子
flatMap:对集合中的每个元素进行map操作再扁平化
val data = sc.parallelize(List("I am Meng Lang Lan Tian","my wechat is mllt9920"))
data.map(x=>x.split(" ")).collect
data.flatMap(x=>x.split(" ")).collect

sortBy 排序
sortBy(f:(T) => K, ascending, numPartitions)
类型:Transformation类型算子
作用:对标准RDD进行排序
sortBy()可接受三个参数:
f:(T) => K:左边是要被排序对象中的每一个元素,右边返回的值是元素中要进行排序的值。
ascending:决定排序后RDD中的元素是升序还是降序,默认是true,也就是升序,false为降序排序。
numPartitions:该参数决定排序后的RDD的分区个数,默认排序后的分区个数和排序之前的个数相等。
eg:按照每个元素的第二个值进行降序排序,将得到的结果存放到RDD "data2" 中
val data1 = sc.parallelize(List((1,3),(2,4),(5,7),(6,8)))
val data2 = data1.sortBy(x=>x._2,false,1)
val data3 = data1.sortBy(x=>x._1,false,1)




distinct 去重复
distinct([numPartitions]))
类型:Transformation类型算子
作用:去重。针对RDD中重复的元素,只保留一个元素
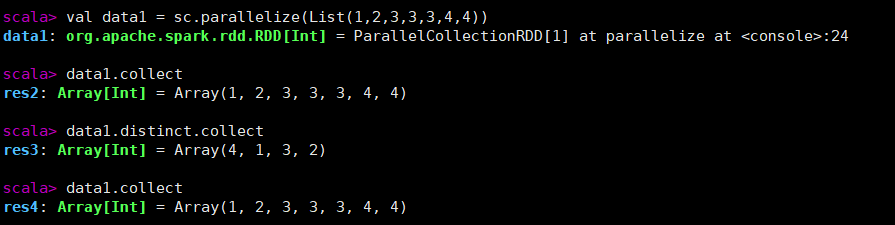
eg:
val data1 = sc.parallelize(List(1,2,3,3,3,4,4))
data1.collect
data1.distinct.collect
data1.collect
union 合并
union(otherDataset)
作用:合并RDD,需要保证两个RDD元素类型一致
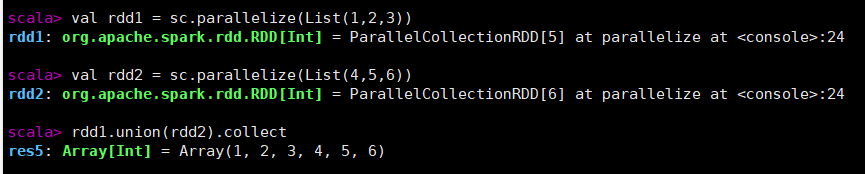
eg:合并rdd1和rdd2
val rdd1 = sc.parallelize(List(1,2,3))
val rdd2 = sc.parallelize(List(4,5,6))
rdd1.union(rdd2).collect
注意:union两个RDD元素类型要一致
intersection 交集
intersection(otherDataset)
作用:找出两个RDD的共同元素,也就是找出两个RDD的交集
eg:找出c_rdd1和c_rdd2中相同的元素
val c_rdd1 = sc.parallelize(List(('a',1),('b',2),('a',1),('c',1)))
val c_rdd2 = sc.parallelize(List(('a',1),('b',1),('d',1),('e',1)))
c_rdd1.intersection(c_rdd2).collect

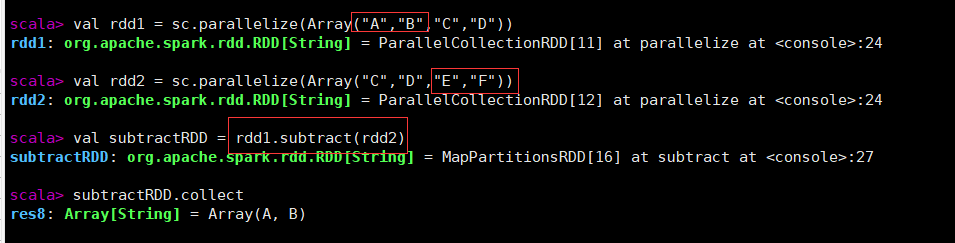
subtract 差集
subtract (otherDataset)
作用:获取两个RDD之间的差集
eg:找出rdd1与rdd2之间的差集
val rdd1 = sc.parallelize(Array("A","B","C","D"))
val rdd2 = sc.parallelize(Array("C","D","E","F"))
val subtractRDD = rdd1.subtract(rdd2)
subtractRDD.collect
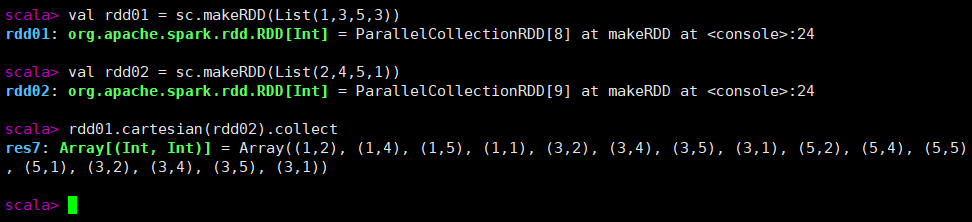
cartesian
cartesian(otherDataset)
名称:笛卡尔积
作用:将两个集合的元素两两组合成一组
eg:
val rdd01 = sc.makeRDD(List(1,3,5,3))
val rdd02 = sc.makeRDD(List(2,4,5,1))
rdd01.cartesian(rdd02).collect
take(num)
返回RDD前面num条记录
val data = sc.parallelize(List(1,2,3,4))
data.take(2)

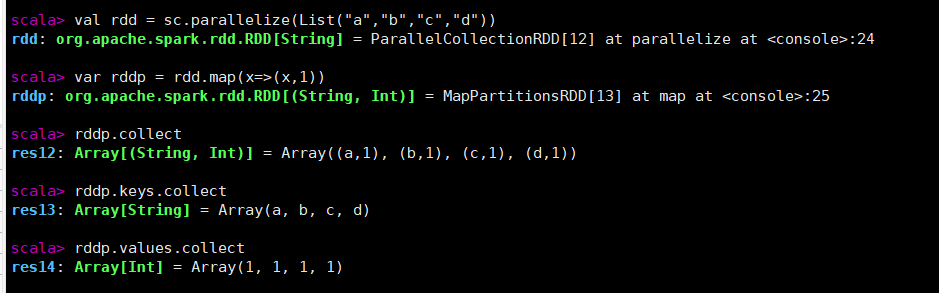
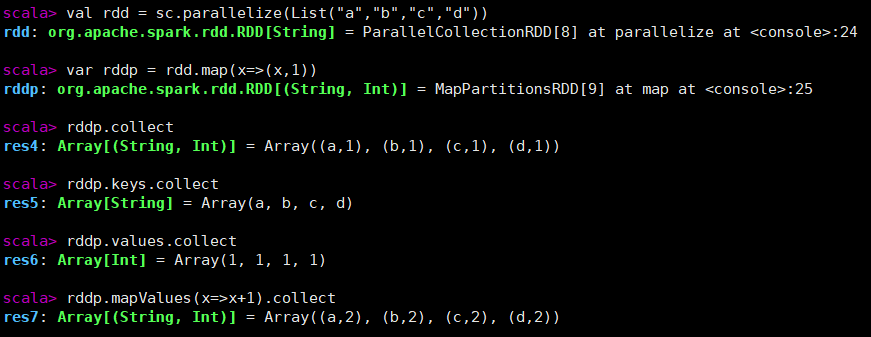
键值对RDD
mapValues
val rdd = sc.parallelize(List("a","b","c","d"))
//通过map创建键值对
var rddp = rdd.map(x=>(x,1))
rddp.collect
rddp.keys.collect
rddp.values.collect
//通过mapValues让所有Value值加一
rddp.mapValues(x=>x+1).collect
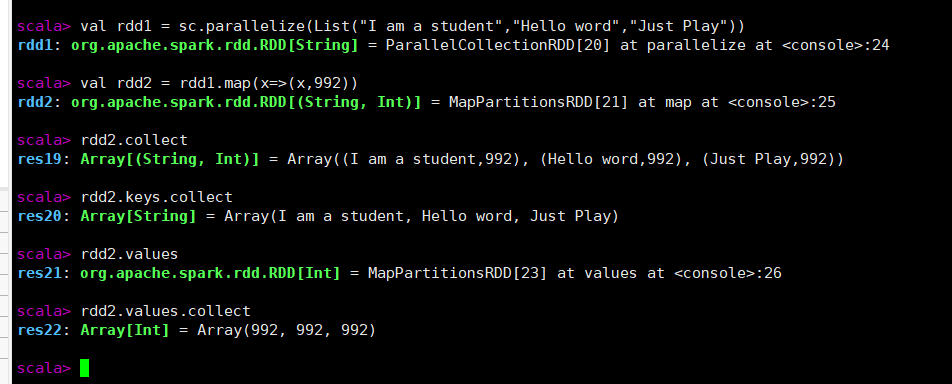
val rdd1 = sc.parallelize(List("I am a student","Hello word","Just Play"))
val rdd2 = rdd1.map(x=>(x,992))
rdd2.collect
rdd2.keys.collect
rdd2.values
rdd2.values.collect
val rdd3 = sc.parallelize(List("I am a student","Hello word","Just Play"))
val rdd4 = rdd1.map(x=>x.split(" "))
rdd4.collect
val p1=rdd4.map(x=>(x.split(" "),x))
p1.collect
join按键内连接
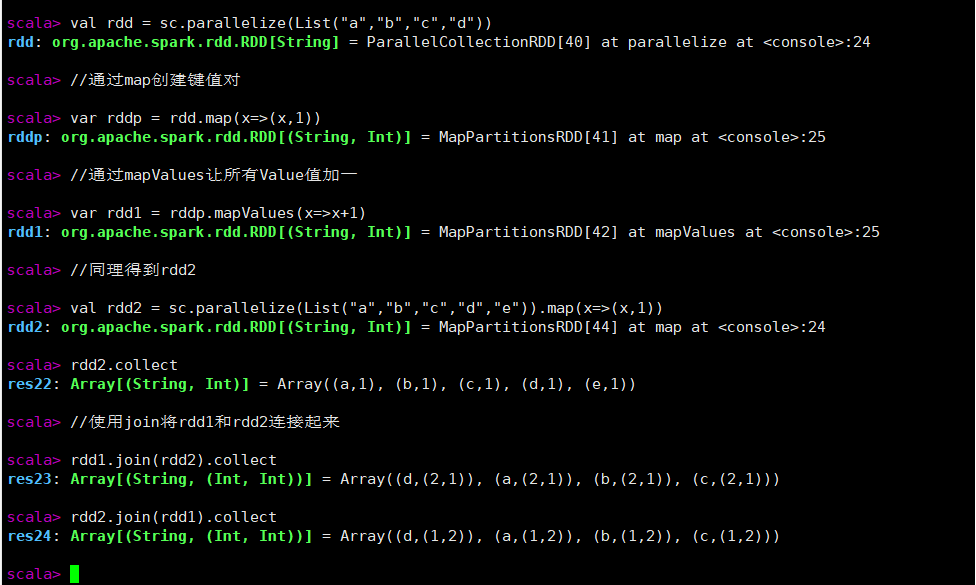
val rdd = sc.parallelize(List("a","b","c","d"))
//通过map创建键值对
var rddp = rdd.map(x=>(x,1))
//通过mapValues让所有Value值加一
var rdd1 = rddp.mapValues(x=>x+1)
//同理得到rdd2
val rdd2 = sc.parallelize(List("a","b","c","d","e")).map(x=>(x,1))
rdd1.collect
rdd2.collect
//使用join将rdd1和rdd2连接起来
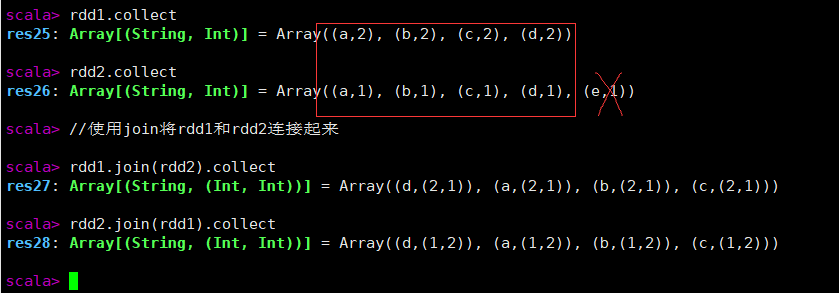
rdd1.join(rdd2).collect
rdd2.join(rdd1).collect
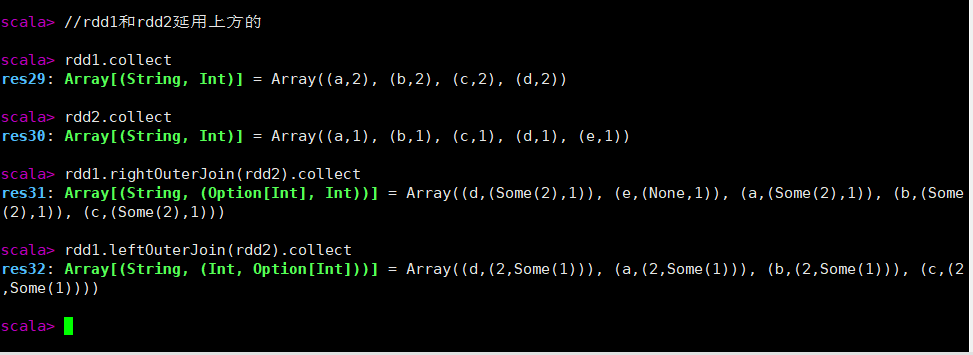
leftOuterJoin和rightOuterJoin和fullOuterJoin
rightOuterJoin 右外连接。第二个RDD的键必须存在
leftOuterJoin 左外连接。第一个RDD的键必须存在
fullOuterJoin 全外连接。两个键都要有
//rdd1和rdd2延用上方的
rdd1.collect
rdd2.collect
//右外连接
rdd1.rightOuterJoin(rdd2).collect
//左外连接
rdd1.leftOuterJoin(rdd2).collect
//全外连接
rdd1.fullOuterJoin(rdd2).collect
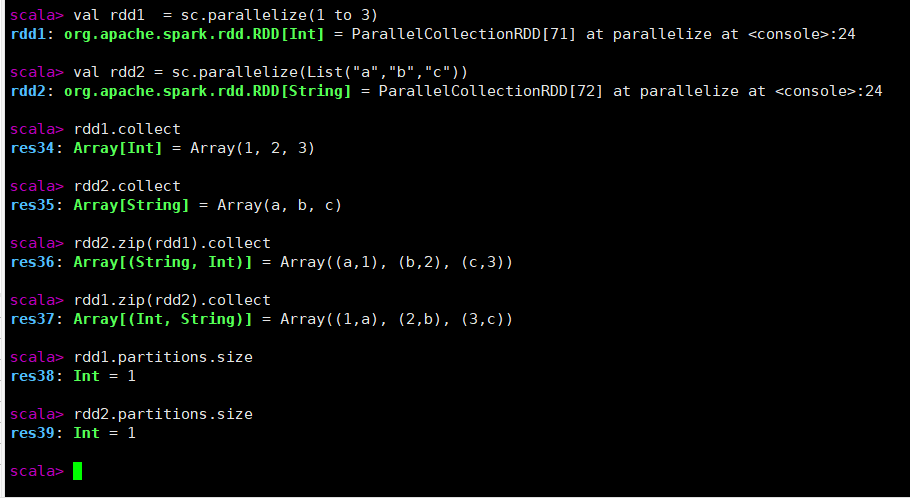
zip
作用:组合两个RDD为键值对RDD
- 两个RDD的分区数必须相同(查询分区数rdd.partitions.size)
- 两个RDD的元素个数必须相同
val rdd1 = sc.parallelize(1 to 3)
val rdd2 = sc.parallelize(List("a","b","c"))
rdd1.collect
rdd2.collect
rdd2.zip(rdd1).collect
rdd1.zip(rdd2).collect
rdd1.partitions.size
rdd2.partitions.size
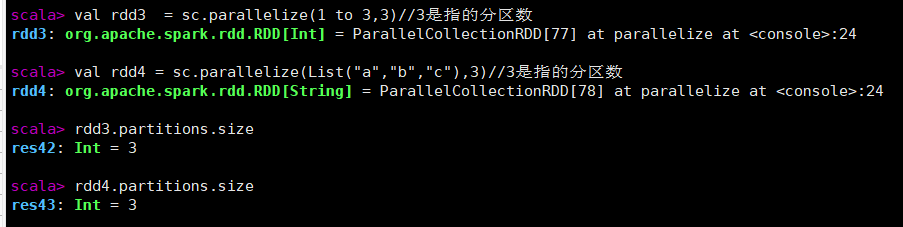
val rdd3 = sc.parallelize(1 to 3,3)//3是指的分区数
val rdd4 = sc.parallelize(List("a","b","c"),3)//3是指的分区数
rdd3.partitions.size
rdd4.partitions.size
CombineByKey
合并相同键的值,合并后值的类型可以不同
目标:想将值转换为List类型
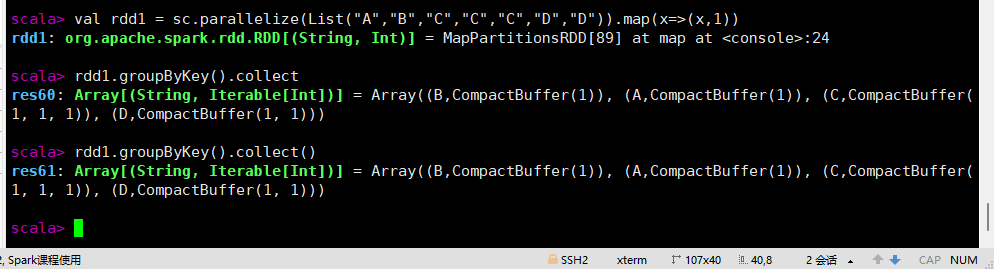
groupByKey([numPartitions])
按键分组,在(K,V)对组成的RDD上调用时,返回(K,Iterable)对组成的新的RDD。
val rdd1 = sc.parallelize(List("A","B","C","C","C","D","D")).map(x=>(x,1))
rdd1.groupByKey().collect
rdd1.groupByKey().collect()
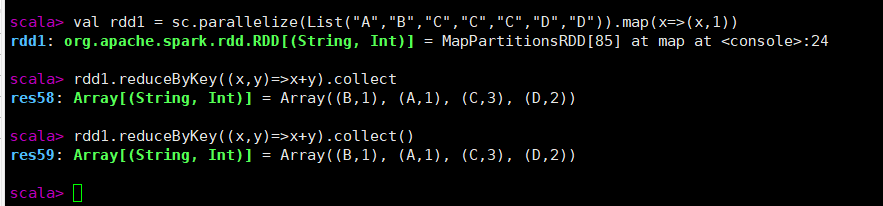
reduceByKey(func, [numPartitions])
将键值对RDD按键分组后进行聚合(Key相同,则只保留一个Key,值+1)
- 当在(K,V)类型的键值对组成的RDD上调用时,返回一个(K,V)类型键值对组成的新RDD
- 其中新RDD每个键的值使用给定的reduce函数func进行聚合,该函数必须是(V,V)=>V类型
- 可用来统计每个键出现的次数
val rdd1 = sc.parallelize(List("A","B","C","C","C","D","D")).map(x=>(x,1))
rdd1.reduceByKey((x,y)=>x+y).collect
rdd1.reduceByKey((x,y)=>x+y).collect()
文件读取与存储
| 结构名称 | 结构化 | 描述 |
|---|---|---|
| 文本文件 | 否 | 普通文本文件,每一行一条记录 |
| SequenceFile | 是 | 用于键值对数据的常见Hadoop文件格式 |
rdd.partitions.size
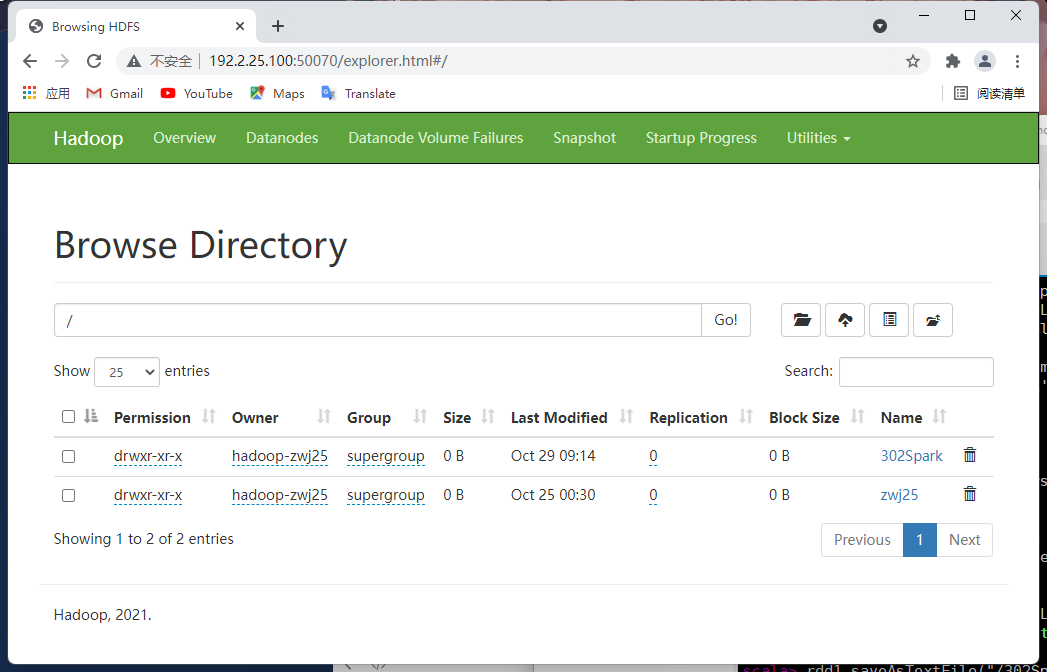
saveAsTextFile(Path:String)
把RDD保存到HDFS中
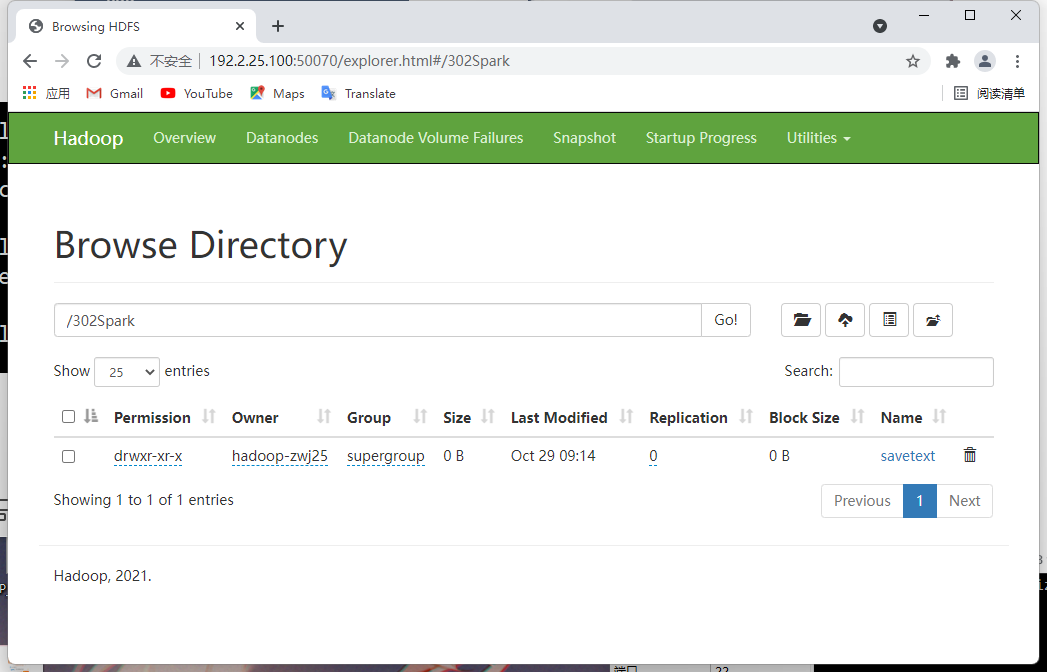
val rdd1 = sc.parallelize(List(1,2,3,4))
rdd1.saveAsTextFile("/302Spark/savetext")
//输入IP:50070 查询

saveAsSequenceFile and sc.sequenceFile
saveAsSequenceFile(Path:String)
序列化文件,仅支持键值对RDD
sequenceFile[K, V](path: String, keyClass: Class[K], valueClass: Class[V], minPartitions: Int)
读序列化文件:
//为了让Spark支持Hadoop的数据类型,需要导包
import org.apache.hadoop.io.
sc.sequenceFile(Path:String,KeyClass:key[K])
实例
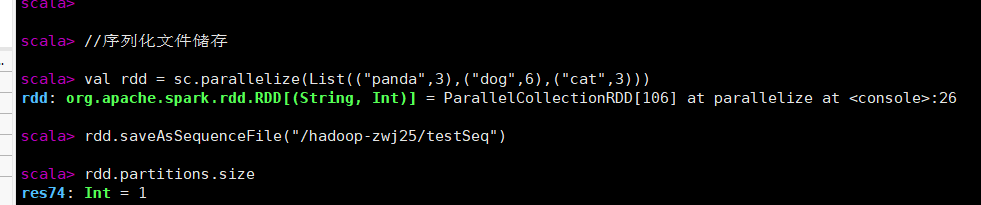
//序列化文件储存
val rdd = sc.parallelize(List(("panda",3),("dog",6),("cat",3)))
rdd.saveAsSequenceFile("/hadoop-zwj25/testSeq")
rdd.partitions.size
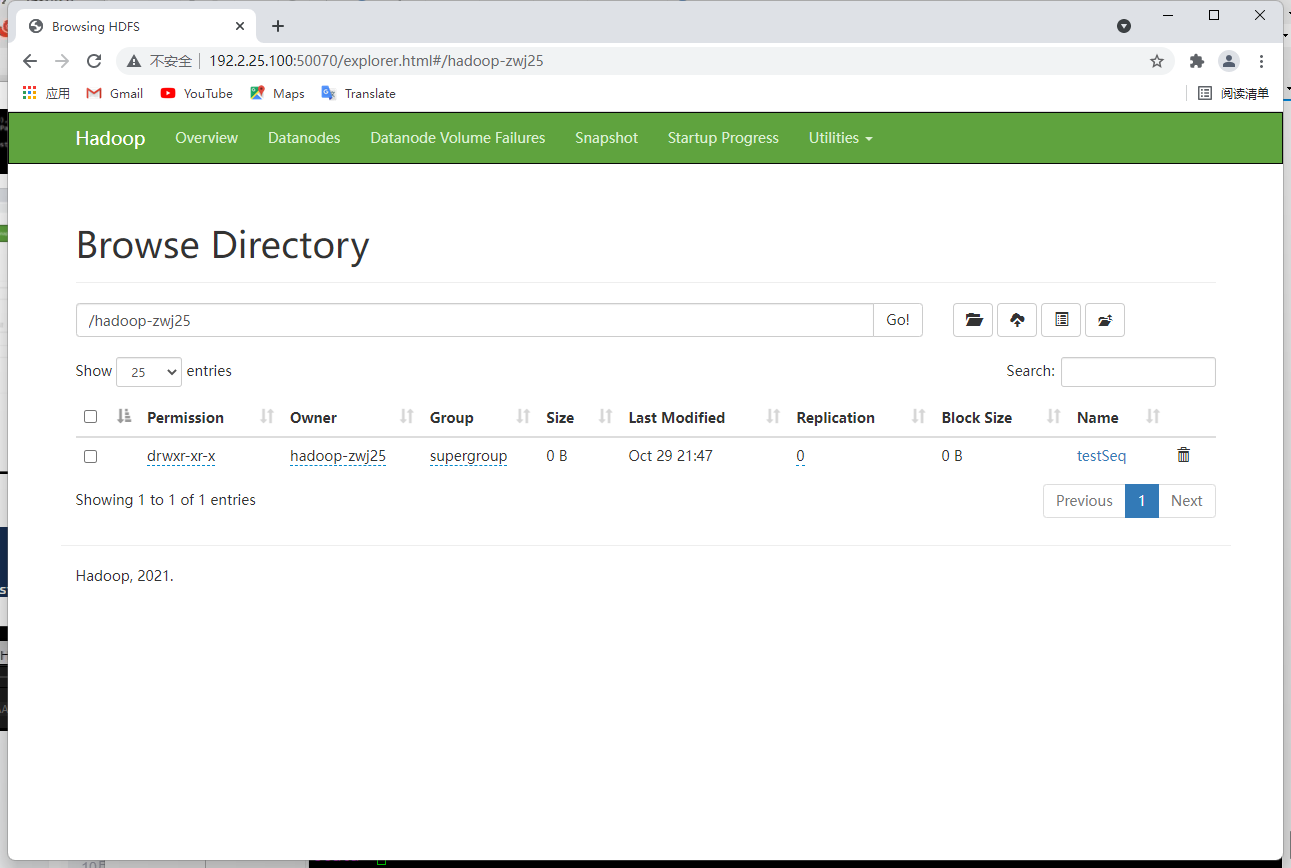
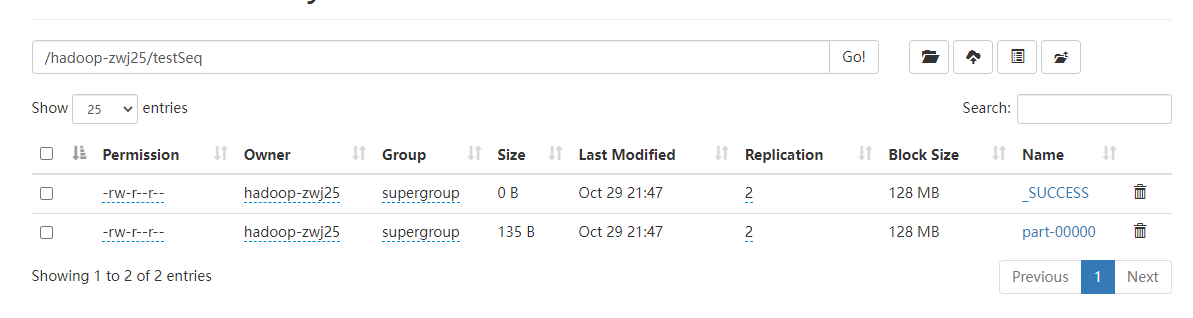
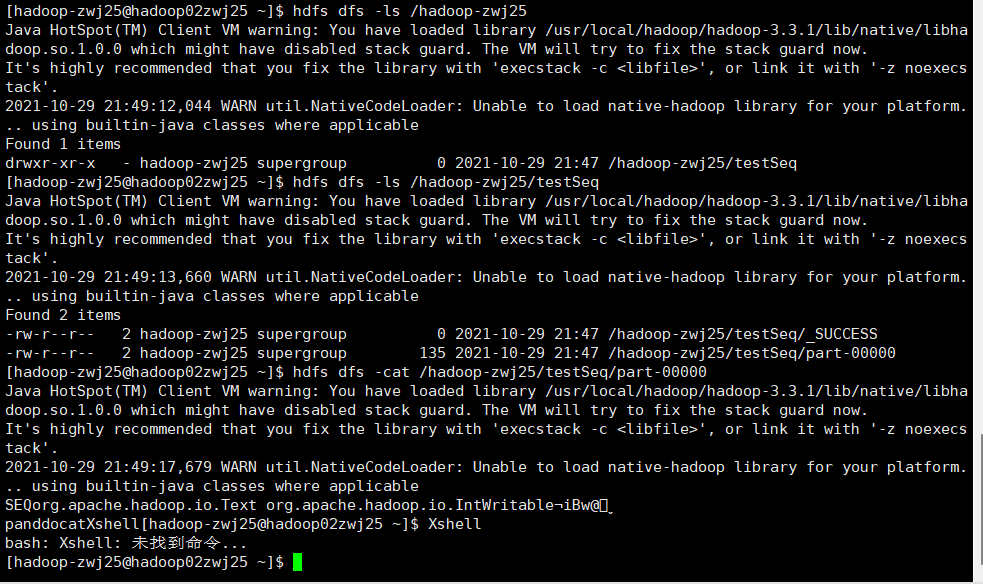
//查看序列化文件
hdfs dfs -ls /hadoop-zwj25
hdfs dfs -ls /hadoop-zwj25/testSeq
hdfs dfs -cat /hadoop-zwj25/testSeq/part-00000
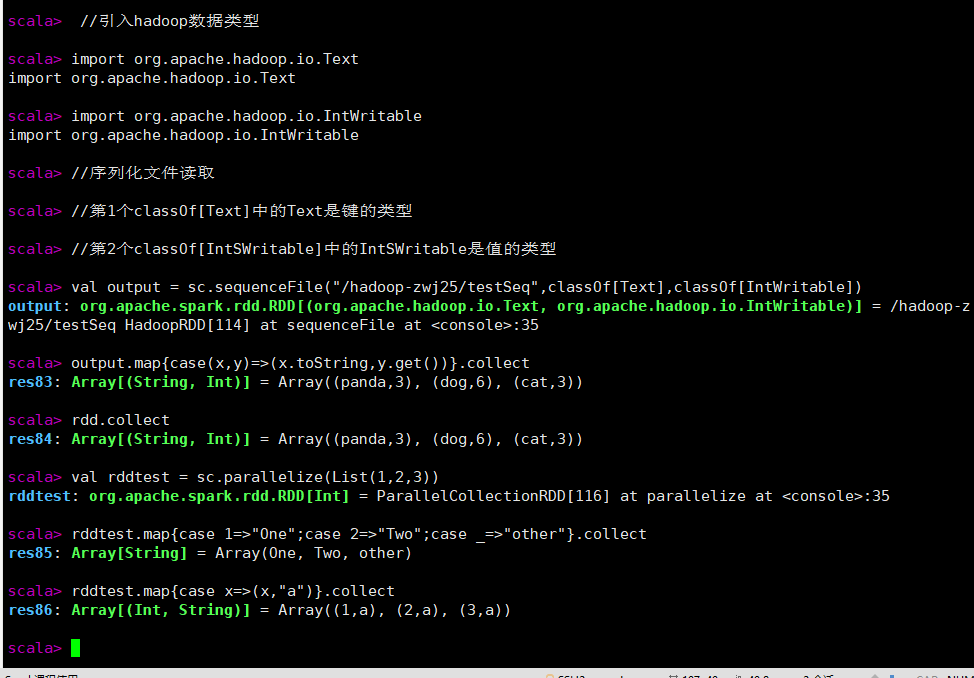
//引入hadoop数据类型
import org.apache.hadoop.io.Text
import org.apache.hadoop.io.IntWritable
//序列化文件读取
//第1个classOf[Text]中的Text是键的类型
//第2个classOf[IntSWritable]中的IntSWritable是值的类型
val output = sc.sequenceFile("/hadoop-zwj25/testSeq",classOf[Text],classOf[IntWritable])
output.map{case(x,y)=>(x.toString,y.get())}.collect
rdd.collect
val rddtest = sc.parallelize(List(1,2,3))
rddtest.map{case 1=>"One";case 2=>"Two";case _=>"other"}.collect
rddtest.map{case x=>(x,"a")}.collect
repartition() 重新分区
repartition(numPartitions: Int)
- 可以增加或减少此RDD中的并行级别。在内部,它使用shuffle重新分发数据。
- 如果要减少此RDD中的分区数,请考虑使用coalesce,这样可以避免执行shuffle。
coalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
查询分区:partitions.size
rdd.repartition(numPartitions:Int).partitions.size
减少分区数,请考虑使用coalesce,这样可以避免执行
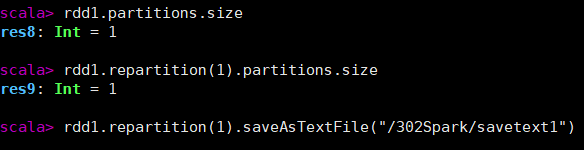
val rdd1 = sc.parallelize(List(1,2,3,4))
rdd1.saveAsTextFile("/302Spark/savetext")
//输入IP:50070 查询
//---------------------------------------
rdd1.partitions.size
rdd1.repartition(1).partitions.size
rdd1.repartition(1).saveAsTextFile("/302Spark/savetext1")
练习
Practice01
题目
找出考试成绩得过100分的学生ID,最终的结果需要集合到一个RDD中。
素材
请将下面代码块中内容粘贴到文本文档result_bigdata.txt中
1001 大数据基础 90
1002 大数据基础 94
1003 大数据基础 100
1004 大数据基础 99
1005 大数据基础 90
1006 大数据基础 94
1007 大数据基础 100
1008 大数据基础 93
1009 大数据基础 89
1010 大数据基础 78
1011 大数据基础 91
1012 大数据基础 84
代码
//从本地文件创建RDD
val rdd_bigdata = sc.textFile("file:///home/用户名/result_bigdata.txt")
//随便输出一个测试
rdd_bigdata.take(2)
//查看所有结果
rdd_bigdata.collect
//下面这种方法需要转为Int型
val bigdata_100=rdd_bigdata.map(x=>x.split("\t")).map(x=>(x(0),x(1),x(2).toInt)).filter(x=>x._3==100).map(x=>x._1)
bigdata_100.collect
//下面这种方法无需转为Int型
val bigdata_100=rdd_bigdata.map(x=>x.split("\t")).filter(x=>x(2)=="100").map(x=>x(0))
bigdata_100.collect
Practice02
题目
输出每位学生的总成绩,要求将两个成绩表中学生ID相同的成绩相加。
素材
请将下面代码块中内容粘贴到文本文档score.txt中
math John 90
math Betty 88
math Mike 95
math Lily 92
chinese John 78
chinese Betty 80
chinese Mike 88
chinese Lily 85
english John 92
english Betty 84
english Mike 90
english Lily 85
请将下面代码块中内容粘贴到文本文档result_math.txt中
1001 应用数学 96
1002 应用数学 94
1003 应用数学 100
1004 应用数学 100
1005 应用数学 94
1006 应用数学 80
1007 应用数学 90
1008 应用数学 94
1009 应用数学 84
1010 应用数学 86
1011 应用数学 79
1012 应用数学 91
请将下面代码块中内容粘贴到文本文档result_bigdata.txt中
1001 大数据基础 90
1002 大数据基础 94
1003 大数据基础 100
1004 大数据基础 99
1005 大数据基础 90
1006 大数据基础 94
1007 大数据基础 100
1008 大数据基础 93
1009 大数据基础 89
1010 大数据基础 78
1011 大数据基础 91
1012 大数据基础 84
代码
//从本地文件创建RDD
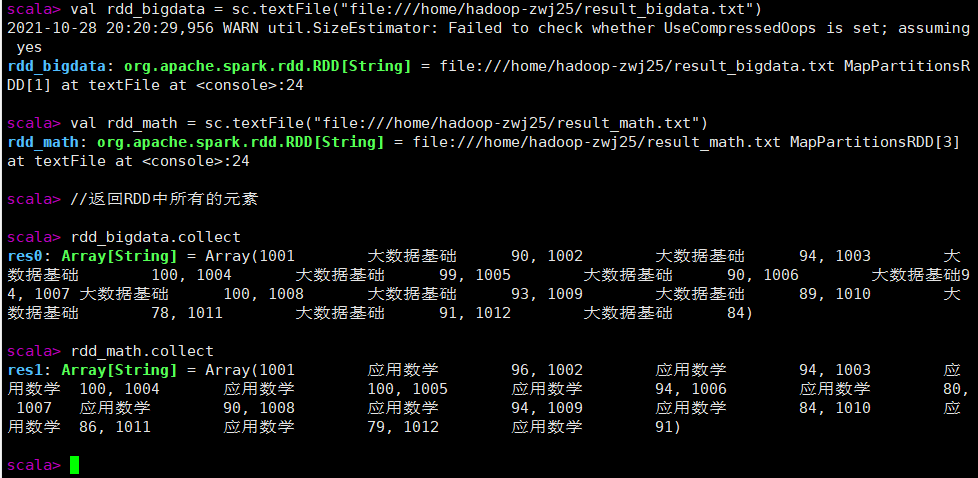
val rdd_bigdata = sc.textFile("file:///home/hadoop-zwj25/result_bigdata.txt")
val rdd_math = sc.textFile("file:///home/hadoop-zwj25/result_math.txt")
//返回RDD中所有的元素
rdd_bigdata.collect
rdd_math.collect
//合并两个RDD
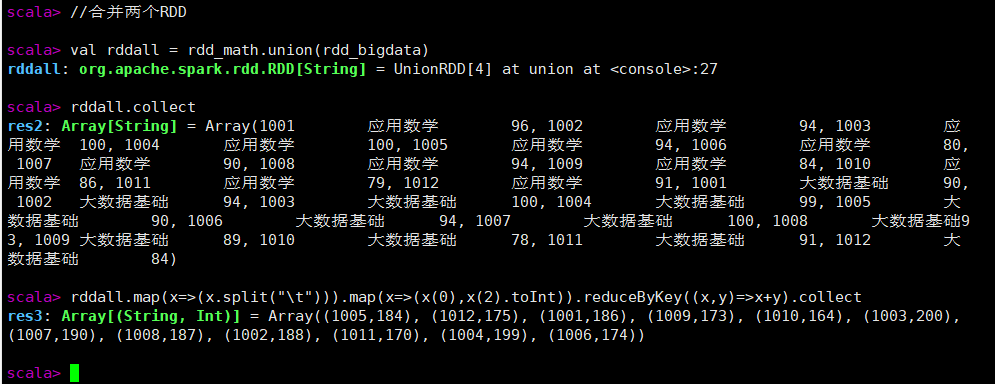
val rddall = rdd_math.union(rdd_bigdata)
rddall.collect
rddall.map(x=>(x.split("\t"))).map(x=>(x(0),x(2).toInt)).reduceByKey((x,y)=>x+y).collect
Practice03
题目
1.输出每位同学的平均成绩,要求将两个成绩表中学生ID相同的成绩相加并计算出平均分。
2.合并每位同学的总成绩和平均成绩
完成平均分及合并任务
素材
代码
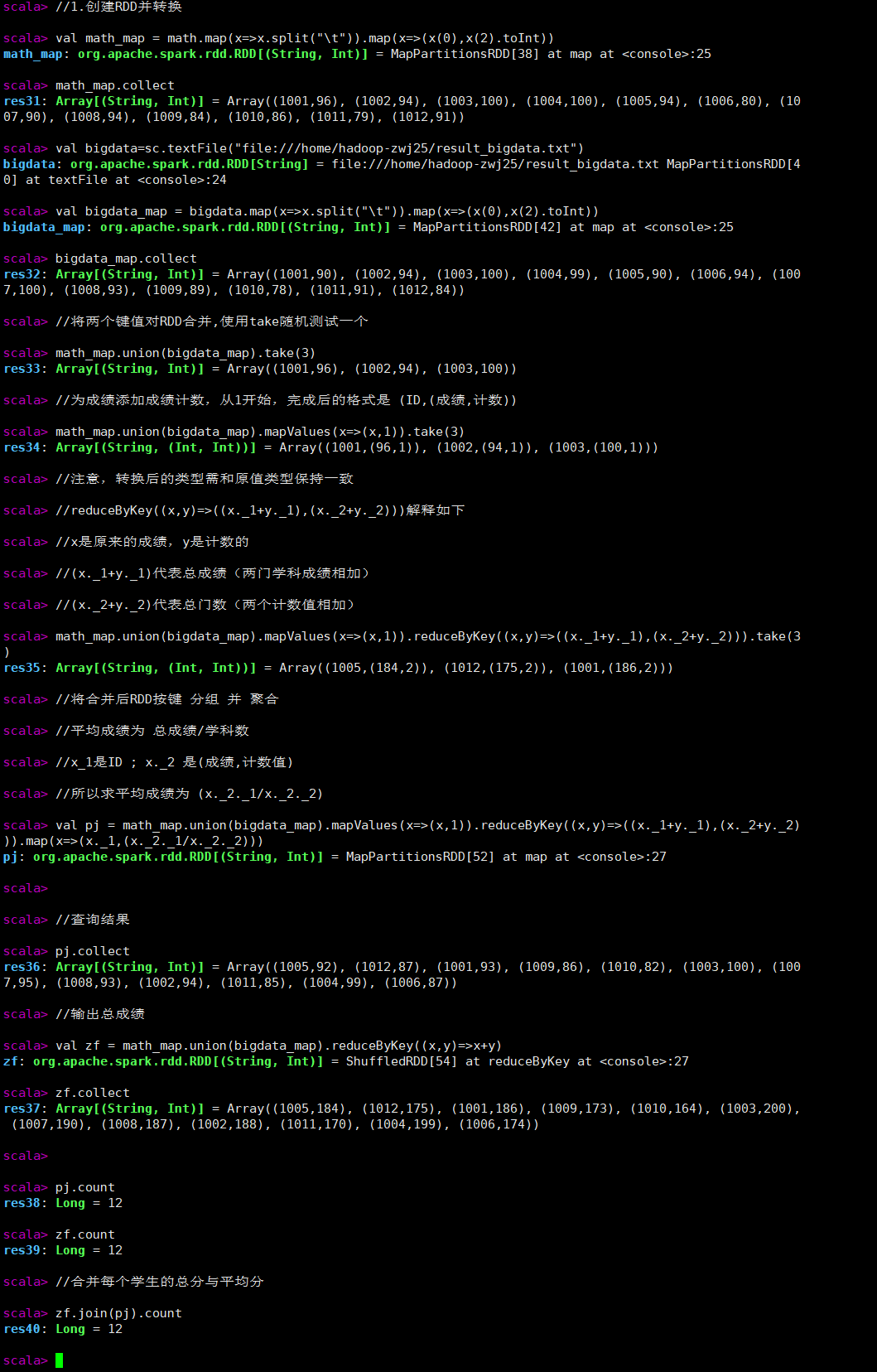
//1.创建RDD并转换
val math_map = math.map(x=>x.split("\t")).map(x=>(x(0),x(2).toInt))
math_map.collect
val bigdata=sc.textFile("file:///home/hadoop-zwj25/result_bigdata.txt")
val bigdata_map = bigdata.map(x=>x.split("\t")).map(x=>(x(0),x(2).toInt))
bigdata_map.collect
//将两个键值对RDD合并,使用take随机测试一个
math_map.union(bigdata_map).take(3)
//为成绩添加成绩计数,从1开始,完成后的格式是 (ID,(成绩,计数))
math_map.union(bigdata_map).mapValues(x=>(x,1)).take(3)
//注意,转换后的类型需和原值类型保持一致
//reduceByKey((x,y)=>((x._1+y._1),(x._2+y._2)))解释如下
//x是原来的成绩,y是计数的
//(x._1+y._1)代表总成绩(两门学科成绩相加)
//(x._2+y._2)代表总门数(两个计数值相加)
math_map.union(bigdata_map).mapValues(x=>(x,1)).reduceByKey((x,y)=>((x._1+y._1),(x._2+y._2))).take(3)
//将合并后RDD按键 分组 并 聚合
//平均成绩为 总成绩/学科数
//x_1是ID ; x._2 是(成绩,计数值)
//所以求平均成绩为 (x._2._1/x._2._2)
val pj = math_map.union(bigdata_map).mapValues(x=>(x,1)).reduceByKey((x,y)=>((x._1+y._1),(x._2+y._2))).map(x=>(x._1,(x._2._1/x._2._2)))
//查询结果
pj.collect
//输出总成绩
val zf = math_map.union(bigdata_map).reduceByKey((x,y)=>x+y)
zf.collect
pj.count
zf.count
//合并每个学生的总分与平均分
zf.join(pj).count
【Spark】【RDD】初次学习RDD 笔记 汇总的更多相关文章
- Spark RDD设计学习笔记
本文档是学习RDD经典论文<Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster ...
- 【原】Learning Spark (Python版) 学习笔记(一)----RDD 基本概念与命令
<Learning Spark>这本书算是Spark入门的必读书了,中文版是<Spark快速大数据分析>,不过豆瓣书评很有意思的是,英文原版评分7.4,评论都说入门而已深入不足 ...
- Learning Spark (Python版) 学习笔记(一)----RDD 基本概念与命令
<Learning Spark>这本书算是Spark入门的必读书了,中文版是<Spark快速大数据分析>,不过豆瓣书评很有意思的是,英文原版评分7.4,评论都说入门而已深入不足 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- Spark源码系列:RDD repartition、coalesce 对比
在上一篇文章中 Spark源码系列:DataFrame repartition.coalesce 对比 对DataFrame的repartition.coalesce进行了对比,在这篇文章中,将会对R ...
- Spark(三)RDD与广播变量、累加器
一.RDD的概述 1.1 什么是RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可 ...
- spark第一篇:RDD Programming Guide
预览 在高层次上,每一个Spark应用(application)都包含一个驱动程序(driver program),该程序运行用户的主函数(main function),并在集群上执行各种并行操作. ...
- spark——spark中常说RDD,究竟RDD是什么?
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark专题第二篇文章,我们来看spark非常重要的一个概念--RDD. 在上一讲当中我们在本地安装好了spark,虽然我们只有lo ...
- Spark RDD详解 | RDD特性、lineage、缓存、checkpoint、依赖关系
RDD(Resilient Distributed Datasets)弹性的分布式数据集,又称Spark core,它代表一个只读的.不可变.可分区,里面的元素可分布式并行计算的数据集. RDD是一个 ...
随机推荐
- Django笔记&教程 6-3 使用模型(models)创建表单(form)
Django 自学笔记兼学习教程第6章第3节--使用模型(models)创建表单(form) 点击查看教程总目录 本文参考:Forms for models 1 - 初步介绍 很多时候,我们使用的表单 ...
- Django 小实例S1 简易学生选课管理系统 1 项目流程梳理与数据库设计
Django 小实例S1 简易学生选课管理系统 第1章--项目流程梳理与数据库设计 点击查看教程总目录 作者自我介绍:b站小UP主,时常直播编程+红警三,python1对1辅导老师. 1 项目流程梳理 ...
- Java设计模式之(二)——工厂模式
1.什么是工厂模式 Define an interface for creating an object,but let subclasses decide which class toinstant ...
- [bzoj4557]侦察守卫
令g[i][j]表示覆盖了i的子树中距离i大于等于j的所有点,f[i][j]表示覆盖了i的子树和子树外距离i小于等于j的所有点,有递推式$f[i][j]=min(f[i][j]+g[son][j],f ...
- [luogu3573]RAJ-Rally
先建一个$S$和$T$,$\forall 1\le i\le n$连边$(S,i)$和$(i,T)$,则最长路即为$S到T的最长路-2$ 对于这张DAG,求出一个拓扑序,点$i$为第$i$个(特别的, ...
- [loj3329]有根树
题目即求$\min_{C}\max(|C|,\min_{x\notin C}w_{x})$,考虑将$w$从大到小排序,即为$\min_{1\le k\le n}\max(k,w_{k+1})$ 考虑若 ...
- [bzoj4651]网格
考虑将最上中最左的跳蚤孤立,容易发现他的上面和左面没有跳蚤,因此只需要将他的右边和下边替换掉就可以了答案为-1有两种情况:1.c>=n*m-1;2.c=n*m-2且这两只跳蚤相邻对于其他情况,将 ...
- Jmeter——变量嵌套函数使用(__V)案例分析
jmeter版本:5.3 __V官方函数解释: (https://jmeter.apache.org/usermanual/functions.html#__V) 图1-1 解决问题:实现字符串拼接 ...
- 数据仓库和数据集市:ODS、DW、DWD、DWM、DWS、ADS
@ 目录 数据流向 何为数仓DW 主要特点 与数据库的对比 为何要分层 数据分层 数据运营层ODS 数据仓库层 数据细节层DWD 数据中间层DWM 数据服务层DWS(DWT) 数据应用层ADS 事实表 ...
- Oracle-like 多条件过滤以及and or用法
1.select * from file where DOC_SUBJECT not like '%测试%' and (DOC_STATUS like '待审' or DOC_STATUS li ...