数仓建模—ID Mapping
早晨起床的时候,发现自己尿分叉,我没有多想,简单洗洗就匆忙出门。路过早餐店,我看到师傅熟练的拉扯一小块面团,拉至细长条,然后放入油锅中,不一会功夫,一根屎黄色的油条便出锅了,卖相不错。我在想,小到炸屎黄色的油条,大到学习,其实都是一个熟能生巧的过程。
数据仓库系列文章(持续更新)
- 数仓架构发展史
- 数仓建模方法论
- 数仓建模分层理论
- 数仓建模—宽表的设计
- 数仓建模—指标体系
- 数据仓库之拉链表
- 数仓—数据集成
- 数仓—数据集市
- 数仓—商业智能系统
- 数仓—埋点设计与管理
- 数仓—ID Mapping
- 数仓—OneID
- 数仓—AARRR海盗模型
- 数仓—总线矩阵
- 数仓—数据安全
- 数仓—数据质量
- 数仓—数仓建模和业务建模
关注
大数据技术派,回复:资料,领取1024G资料。
顾名思义我们知道ID Mapping 的操作对象是ID,目标或者是动作是Mapping,也就是说我们要做的事情其实就是想把不同平台不同设备上的ID 打通,从而更好的去刻画用户,也就是说我们希望能打通用户各个维度的数据,从而更好的去服务业务服务用户
通常公司有产品矩阵,而每个产品都有自己的注册账号产生的用户ID。从公司全局,整合用户表,用户行为数据来看,确定不同产品的用户ID是相同一个人非常重要, 选取合适的用户标识对于提高用户行为分析的准确性有非常大的影响,尤其是对用户画像、推荐、漏斗、留存、Session 等用户相关的分析功能。
其实对于任何分析都是一样的,如果我们不能准确标识一个用户,那么我们的计算结果就没有准确性可言,其实对于数据服务方而言,数据的准确性是我们的第一要务,我们宁愿不出数据,也不要出错误的数据。
ID Mapping 的背景
网络身份证
假如没有网络身份证,那么每个商家(App)只能基于自己的账号体系标识用户,并记录用户的行为。而有了统一的网络身份证之后,各个商家之间的数据就可以打通了,天猫不仅知道用户A在淘宝系的购物数据,也能了解到该用户在社交网络的行为,以及旅游的喜好,等等。
在现实的数据中,由于,用户可能使用各种各样的设备,有着各种各样的前端入口,甚至同一个用户拥有多个设备以及使用多种前端入口,就会导致,日志数据中对同一个人,不同时间段所收集到的日志数据中,可能取到的标识个数、种类各不相同;
比如用户可能使用各种各样的设备,其次是不同设备有不同的操作系统,设置是软件本身的版本也会影响我们对用户的标识,
- 手机、平板电脑、PC
- 安卓手机、ios手机、winphone手机
- 安卓系统有各种版本 ( 5.0 6.0 7.0 8.0 9.0 )
- ios系统也有各种版本(3.x 4.x 5.x 6.x 7.x … 12.x )
存在的问题
- 用户设备的标识,没办法轻易定制一个规则来取某个作为唯一标识:
- mac地址:手机网卡物理地址, 若干早期版本的ios,winphone,android可取到
- imei(入网许可证序号):安卓系统可取到,若干早期版本的ios,winphone可取到,运营商可取到
- imsi(手机SIM卡序号):安卓系统可取到,若干早期版本的ios,winphone可取到,运营商可取到
- androidid :安卓系统id
- openuuid(app自己生成的序号) :卸载重装app就会变更
- IDFA(广告跟踪码)
扩展 IDFA
IDFA,英文全称 Identifier for Advertising ,可以理解为广告id,苹果公司提供的用于追踪用户的广告标识符,可以用来打通不同app之间的广告。每个设备只有一个IDFA,不同APP在同一设备上获取IDFA的结果是一样的
苹果为了保护用户隐私,早在2012年就不再允许其生态中的玩家获取用户的唯一标识符,但是商家在移动端打广告的时候又希望能监控到每一次广告投放的效果,因此,苹果想出了折中的办法,就是提供另外一套和硬件无关的标识符,用于给商家监测广告效果,同时用户可以在设置里改变这串字符,导致商家没有办法长期跟踪用户行为。这个就叫做广告标识符(IDFA),设置路径是“设置->隐私->广告->还原广告标识符”,如下图所示(iOS9)
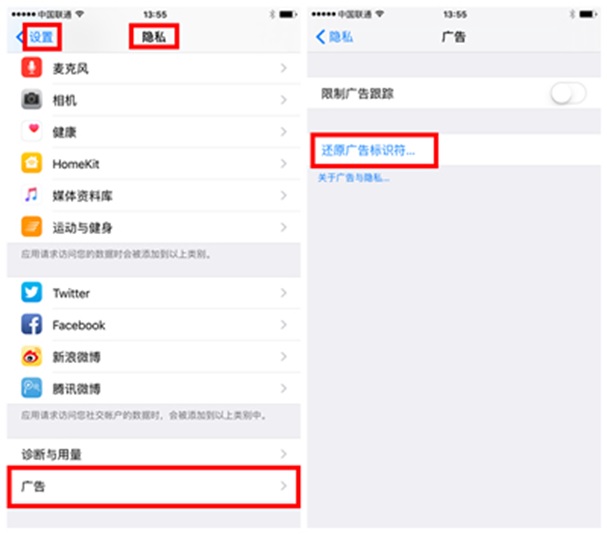
常见的标识
设备 ID
需要注意的是,设备 ID 并不一定是设备的唯一标识。例如 Web 端的 Cookies 有可能被清空(例如各种安全卫士),而 iOS 端的 IDFV( Identifier For Vendor)在不同厂商的 App 间是不同的,而且重新安装IDFV会被重置。
| 设备 | 规则 |
|---|---|
| Android | 1.10.5 之前版本,默认使用 UUID(例如:550e8400-e29b-41d4-a716-446655440000),App 卸载重装 UUID 会变,为了保证设备 ID 不变,可以通过配置使用 AndroidId(例如:774d56d682e549c3);1.10.5 及之后的版本 SDK 默认使用 AndroidId 作为设备 ID,如果 AndroidId 获取不到则获取随机的 UUID。 |
| iOS | 1.10.18 及之后版本,如果 App 引入了 AdSupport 库,SDK 默认使用 IDFA 作为匿名 ID。1.10.18 之前版本,可以优先使用 IDFV(例如:1E2DFA10-236A-47UD-6641-AB1FC4E6483F),如果 IDFV 获取失败,则使用随机的 UUID(例如:550e8400-e29b-41d4-a716-446655440000),一般情况下都能够获取到 IDFV。如果使用 IDFV 或 UUID ,当用户卸载重装 App 时设备 ID 会变。也可以通过配置使用 IDFA(例如:1E2DFA89-496A-47FD-9941-DF1FC4E6484A),如果开启 IDFA ,可以优先获取 IDFA,如果获取失败再尝试获取 IDFV。使用 IDFA 能避免用户在重装 App 后设备 ID 发生变化的情况,需要注意的是IDFA 也是可以被重置的 |
登录 ID
登录 ID 通常是业务数据库里的主键或其它唯一标识。所以 登录 ID,相对来说更精确更持久。但是,用户在使用时不一定注册或者登录,而这个时候是没有登录 ID 的。
平台 ID
| 设备 | 规则 |
|---|---|
| JavaScript | 默认情况下使用 cookie_id(例如:15ffdb0a3f898-02045d1cb7be78-31126a5d-250125-15ffdb0a3fa40a),cookie_id 存贮在浏览器的 cookie 中,依然有被重置的风险 这里还有一个问题,就是 cookie 只能隶属于同一个域名,也就是说你访问邮箱的 cookie ,与百度广的 cookie 并不是同一个,所以在网站与网站也要做 ID Mapping ,这就是为什么你在百度上搜索了“养生”,到购物网站上就会给你推荐“枸杞”。 |
| 微信小程序 | 默认情况下使用 UUID(例如:1558509239724-9278730-00c1875d5f63f8-41373096),但是删除小程序,UUID 会变。为了保证设备 ID 不变,建议获取并使用 openid(例如:oWDMZ0WHqfsjIz7A9B2XNQOWmN3E)。 如果选择使用 openid 的话,请注意【操作暂存】,由于获取 openid 是一个异步的操作,但是冷启动事件等会先发生,这时候这个冷启动事件的 distinct_id 就不对了。所以我们会把先发生的操作,暂存起来,等获取到 openid 等后调用 sa.init() 后才会发送数据。 openid 的获取和操作暂存的方法。 |
其实这里的平台指的一些大的生态系统,例如微信的生态、今日头条等,我们很多依赖这些平台的应用就可以使用用户在这些平台上的用户标识作为标识,当然我们也可以在此基础上为我们自己平台上的用户创建属于本平台的用户表示,往往就是用户的登录ID
方案详解
因此,我们在进行任何数据接入之前,都应当先确定如何来标识用户。下面会介绍几种用户标识方案的原理,以及几种典型情况下的用户标识方案。
方案一:只使用设备 ID
适合没有用户注册体系,或者极少数用户会进行多设备登录的产品,如工具类产品、搜索引擎、部分电商等。这也是绝大多数其它数据分析产品唯一提供的方案。
局限性
- 同一用户在不同设备使用会被认为不同的用户,对后续的分析统计有影响。
- 不同用户在相同设备使用会被认为是一个用户,也对后续的分析统计有影响。
- 但如果用户跨设备使用或者多用户共用设备不是产品的常见场景的话,可以忽略上述问题。
方案二:关联设备 ID 和登录 ID(一对一)
仅使用 设备 ID 标识用户虽然简单,但是对于某些应用场景这种方式不够准确,因此我们可以采用 设备 ID 和 登录 ID 的方案,在一定程度上融合 设备 ID 和 登录 ID,从而实现更准确的用户追踪。
成功关联设备 ID 和登录 ID 之后,用户在该设备 ID 上或该登录 ID 下的行为就会贯通,被认为是一个用户 ID 发生的。在进行事件、漏斗、留存等用户相关分析时也会算作一个用户。
关联设备 ID 和登录 ID 的方法虽然实现了更准确的用户追踪,但是也会增加埋点接入的复杂度。所以一般来说,我们建议只有当同时满足以下条件时,才考虑进行 ID 关联:
- 需要贯通一个用户在一个设备上注册前后的行为。
- 需要贯通一个注册用户在不同设备上登录之后的行为。
局限性
- 一个设备 ID 只能和一个登录 ID 关联,而事实上一台设备可能有多个用户使用。
- 一个登录 ID 只能和一个设备 ID 关联,而事实上一个用户可能用一个登录 ID 在多台设备上登录。
方案三:关联设备 ID 和登录 ID(多对一)
关联设备 ID 和登录 ID(一对一)虽然已经实现了跨设备的用户贯通,但是对于某些应用场景还是不够准确,因此这里提供一个新的关联方案,支持一个登录 ID 绑定多个设备 ID 的方案,从而实现更准确的用户追踪。
也就是跨端,其实这是非常常见的一种场景,例如你在PC 端和 移动端使用同一个产品。
一个用户在多个设备上进行登录是一种比较常见的场景,比如 Web 端和 App 端可能都需要进行登录。支持一个登录 ID 下关联多设备 ID 之后,用户在多设备下的行为就会贯通,被认为是一个ID 发生的。
局限性
- 一个设备 ID 只能和一个登录 ID 关联,而事实上一台设备可能有多个用户使用 多用户使用同一个设备这个问题是无解的。
- 一个设备 ID 一旦跟某个登录 ID 关联或者一个登录 ID 和一个设备 ID 关联,就不能解除(自动解除)。而事实上,设备 ID 和登录 ID 的动态关联才应该是更合理的。
方案对比
将上述三个方案放到一起,可以明显看到三种方案的区别,如下表所示:
- 方案一:仅使用设备 ID,不管用户是谁,只要设备未变,设备ID 就不变,即使多人使用同一个设备,也会被识别为同一个用户。
- 方案二:关联设备 ID 和登录 ID(一对一),
- 当用户换手机后,登录账号之后的行为与换手机之前的行为贯通了,但是在新设备上首次登录之前的行为仍没法贯通,仍被识别为新的用户的行为。
- 当用户把旧手机送给朋友之后,由于旧手机已被关联到自己的登录 ID 了,无法再与朋友的登录 ID 关联。后续使用这台旧手机的用户们,若不登录就操作,则都会被识别为同一个用户。
- 方案三:关联设备 ID 和登录 ID(多对一)
- 当用户把旧手机送给朋友之后,由于旧手机已被关联到自己的登录 ID 了,无法再与朋友的登录 ID 关联。后续使用这台旧手机的用户们,若不登录就操作,则都会被识别为同一个用户)。
- 而事实上,旧手机上后续的匿名登录很难识别到底是谁,可能归为匿名登录之前最近一次登录的用户会更合理一些。
其实,三种方案没有对与错,我们应该结合自己的业务场景以及埋点复杂度来选择合适的方案。
总结
ID Mapping 就如同它的名字一样,我们要做的就是将一系列的ID 关联起来,一些列的ID 可能是用户在不同平台上的标识,也可能是用户在不同设备上的标识,也可能是用户在不同状态下的标识,总之我们就是要将这一系列的ID 关联起来,尽可能地将用户的数据打通,从而提供更加全面准确的分析。
我们知道只有打破数据孤岛数据才能发挥更大的价值,可能很多人都知道数据仓库的数据集成环节其实就是为了打破数据孤岛,其实我们的ID Mapping 也是为了打破数据孤岛,其实ID Mapping 就两个使命 1. 多端数据的识别;2. 多源数据的打通,其他的都是基于ID Mapping 的应用。
知识星球
通过调查,大部分同学表示愿意加入知识星球,我也觉得这样让大家的提问更加有层次和意义,而不是问一些比较肤浅和不太合适的问题,有问题也能自己先查询一下,这样更好的交流和解答疑问,提升时间利用率。
加入星球可以获得什么:
- 博主总结的大数据学习资料免费获得;
- 可以向星主和嘉宾提问;
- 互相交流,别人的提问和答案所有人都可以看到;
- 每周分享大数据前沿知识;
- 每周分享大数据面试题目和面试技巧;
知识星球是付费的,如果你不想知识付费,也没关系我这也有免费的微信群,加我微信:ddxygq,回复: 加群,我拉你进大数据交流群。知识星球完全是自愿付费加入。平时问答,资料分享等,知识星球成员优先,大家都是出来打工的,都不容易,不喜勿喷。

数仓建模—ID Mapping的更多相关文章
- 数仓建模—OneID
今天是我在上海租房的小区被封的第三天,由于我的大意,没有屯吃的,外卖今天完全点不到了,中午的时候我找到了一包快过期的肉松饼,才补充了1000焦耳的能量.但是中午去做核酸的时候,我感觉走路有点不稳,我看 ...
- 数仓建模—建模工具PdMan(CHINER)介绍
数据仓库系列文章(持续更新) 数仓架构发展史 数仓建模方法论 数仓建模分层理论 数仓建模-宽表的设计 数仓建模-指标体系 数据仓库之拉链表 数仓-数据集成 数仓-数据集市 数仓-商业智能系统 数仓-埋 ...
- Inmon和Kimball数仓建模思想
Inmon和Kimball是数据仓库领域伟大的开拓者,他们均多年从事数据仓库的研究,Inmon还被称为“数据仓库之父”.Inmon的<数据仓库>和Kimball的<数据仓库工具箱&g ...
- 数仓建设中最常用模型--Kimball维度建模详解
数仓建模首推书籍<数据仓库工具箱:维度建模权威指南>,本篇文章参考此书而作.文章首发公众号:五分钟学大数据,公众号中发送"维度建模"即可获取此书籍第三版电子书 先来介绍 ...
- 数仓1.4 |业务数仓搭建| 拉链表| Presto
电商业务及数据结构 SKU库存量,剩余多少SPU商品聚集的最小单位,,,这类商品的抽象,提取公共的内容 订单表:周期性状态变化(order_info) id 订单编号 total_amount 订单金 ...
- 数仓建设 | ODS、DWD、DWM等理论实战(好文收藏)
本文目录: 一.数据流向 二.应用示例 三.何为数仓DW 四.为何要分层 五.数据分层 六.数据集市 七.问题总结 导读 数仓在建设过程中,对数据的组织管理上,不仅要根据业务进行纵向的主题域划分,还需 ...
- 数仓1.1 分层| ODS& DWD层
数仓分层 ODS:Operation Data Store原始数据 DWD(数据清洗/DWI) data warehouse detail数据明细详情,去除空值,脏数据,超过极限范围的明细解析具体表 ...
- 在HUE中将文本格式的数据导入hive数仓中
今天有一个需求需要将一份文档形式的hft与fdd的城市关系关系的数据导入到hive数仓中,之前没有在hue中进行这项操作(上家都是通过xshell登录堡垒机直接连服务器进行操作的),特此记录一下. - ...
- HAWQ取代传统数仓实践(十九)——OLAP
一.OLAP简介 1. 概念 OLAP是英文是On-Line Analytical Processing的缩写,意为联机分析处理.此概念最早由关系数据库之父E.F.Codd于1993年提出.OLAP允 ...
随机推荐
- 只要一行代码,实现五种 CSS 经典布局
常用的页面布局,其实就那么几个.下面我会介绍5个经典布局,只要掌握了它们,就能应对绝大多数常规页面. 这几个布局都是自适应的,自动适配桌面设备和移动设备.代码实现很简单,核心代码只有一行,有很大的学习 ...
- python引用列表--10
#!/usr/bin/python #coding=utf-8 #好好学习,天天向上 python=["a","b","c","d ...
- Datawhale 人工智能培养方案
版本号:V0.9 阅读须知 每个专业方向对应一个课程表格 课程表格里的课程排列顺序即为本培养方案推荐的学习顺序 诚挚欢迎为本培养方案贡献课程,有意向的同学请联系Datawhale开源项目管理委员会 本 ...
- https的页面内嵌入http页面报错的问题
1.https的页面内嵌入http页面报错 在HTTPS的页面上嵌入http的页面时,浏览器会直接报错.比如在HTTPS页面上用 iframe 直接嵌入一个 http 页面,比如我们可以在百度上直接嵌 ...
- AtCoder ABC 215 简要题解
A - B 模拟 C 可以直接爆搜,也可以写逐位确定的多项式复杂度算法,使用多重组合式求随意乱排的方案数. D 首先对 \(A\) 所有数暴力分解质因数,然后把遇到过的质因数打上标记. 接下来再对 \ ...
- [USACO18DEC]The Cow Gathering P
首先可以思考一下每次能删去的点有什么性质. 不难发现,每次能删去的点都是入度恰好为 \(1\) 的那些点(包括 \(a_i \rightarrow b_i\) 的有向边). 换句话说,每次能删去的点既 ...
- Swift 介绍
简介 Swift 语言由苹果公司在 2014 年推出,用来撰写 OS X 和 iOS 应用程序 2014 年,在 Apple WWDC 发布 几家欢喜,几家愁 愁者:只学Object-C的人 欢喜者: ...
- linux sftp
转载请注明来源:https://www.cnblogs.com/hookjc/ sftp用法 1. 用sftp如何登录服务器 sftp 是一个交互式文件传输程式.它类似于 ftp, 但它进行加密传输, ...
- 一文详解Kafka API
摘要:Kafka的API有Producer API,Consumer API还有自定义Interceptor (自定义拦截器),以及处理的流使用的Streams API和构建连接器的Kafka Con ...
- 《Effective Python》笔记——第2章 函数
一.函数出错的时候抛异常,而不要返回None pass 二.闭包 书里的例子不好,参考https://www.cnblogs.com/Lin-Yi/p/7305364.html 在一个外函数中定义了一 ...