Python数模笔记-Sklearn(5)支持向量机
支持向量机(Support vector machine, SVM)是一种二分类模型,是按有监督学习方式对数据进行二元分类的广义线性分类器。
支持向量机经常应用于模式识别问题,如人像识别、文本分类、手写识别、生物信息识别等领域。
1、支持向量机(SVM)的基本原理
SVM 的基本模型是特征空间上间隔最大的线性分类器,还可以通过核函数方法扩展为非线性分类器。
SVM 的分割策略是间隔最大化,通过寻求结构化风险最小来提高模型的泛化能力,实现经验风险和置信范围的最小化。SVM 可以转化为求解凸二次规划的问题,学习算法就是求解凸二次规划的最优化算法。
=== 关注 Youcans,分享更多原创系列 https://www.cnblogs.com/youcans/ ===
1.1 SVM 线性分类器
线性可分,在二维平面上是指可以用一条直线将两个点集完全分开,在三维空间上是指可以用一个平面将两个点集完全分开,扩展到多维空间上就是可以用一个超平面完全分割两个点集。
对于线性可分问题,不是仅存在一个超平面可以完全分割两个点集,而是存在无穷多个完全可分的超平面。显然。可以找到两个这样的超平面:(1)完全分割两个点集;(1)两者相互平行;(2)两者距离最大(图中的两条虚线),这两个超平面上的样本点称为支持向量。
样本集中的样本被分为两类,SVM 学习算法就是寻找最大间隔超平面(maximum-margin hyperplane),使样本集的两类数据点以尽可能宽的间隔被超平面分开,其特征是:(1)两类样本被分割在超平面的两侧;(2)两侧距离超平面最近的样本点到超平面的距离最大。显然,最大间隔超平面就是上述两个支持向量超平面的均值。
顺便说一句,感知机()就是采用错误分类最小的策略求分离超平面,有无穷多个解;线性可分支持向量机以间隔最大化求解最优分离超平面,解是唯一的。
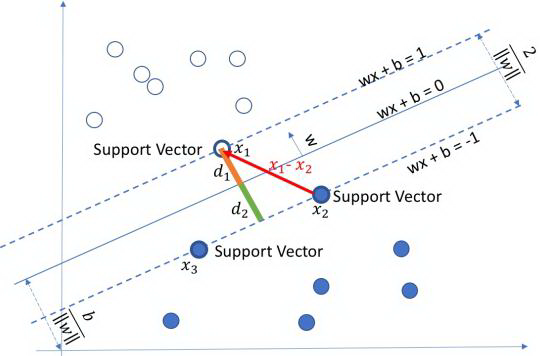
超平面可以用线性方程来描述:
\]
寻找最大间隔超平面,可以转化为凸二次规划的最优化问题:
\]
SKlearn 的 SVM 模块有很多方法,就是针对凸二次规划问题的最优化的不同算法,将在后文中介绍。
1.2 从线性可分到线性不可分
除了线性可分,不就是线性不可分吗?没错,但世界是复杂的,也是丰富多彩的,不一定是非黑即白的。
首先,一个线性不可分问题,但是可以用非线性曲面分割,是非线性可分的问题,这很好理解。其次,一个线性不可分问题,也可能是近似线性可分的。什么是近似线性可分呢?这就需要先说说硬间隔和软间隔。
间隔(margin)是指样本点到超平面的距离。硬间隔(hard margin)是指对给定的样本数据集中所有的样本都能正确分类。
对于线性不可分的样本集,无法满足线性可分支持向量机的不等式约束,也就是不存在对所有样本都能正确分类的超平面。这种情况可能是因为问题本身是非线性的,也可能问题是线性可分的,但个别样本点标记错误或存在误差而导致样本集线性不可分。
因此,我们可以允许对少量的样本分类错误,容忍特异点的存在,而对于去除特异点的样本集是线性可分的,这时称为软间隔(soft margin)。

在凸二次规划问题中引入损失函数和松弛变量 \xi,目标函数为:
\]
目标函数包括两部分,一部分是样本点到间隔的距离,另一部分是错误分类的损失函数,C 是惩罚系数。C 值越大,对错误分类的惩罚项越强,说明要求分类的准确性较高;C 值越小,对错误分类的惩罚项越弱,说明要求间隔比较大,而对分类错误比较宽容。
1.3 非线性可分
有些线性不可分的问题并不是个别样本的误差或错误,而是由于问题本身是非线性的,这时采用软间隔方法也不能有效地分割。容易想到,如果不能用平面分割样本集,能不能用曲面分割样本集呢?基于核函数的支持向量机,就是使用映射函数将一类非线性可分问题从原始的特征空间映射到更高维的特征空间,转化为高维特征空间的线性可分问题。
通过映射函数 ϕi(x) 构造的超曲面可以用非线性方程来描述:
\]
映射函数 ϕi(x) 对应的核函数 K(x,z) 是一个对称的半正定矩阵:
\]
常用的核函数有:线性核函数(Linear),多项式核函数(polynomial)、高斯核函数(RBF)、拉普拉斯核函数(Laplacian)和 Sigmoid核函数(Sigmoid)。
2、线性可分支持向量机(LinearSVC)
SKlearn 中的支持向量机模块是 sklearn.svm,包括分类算法和回归算法。本文介绍分类算法,包括 SVC、NuSVC 和 LinearSVC 三个类。
2.1 LinearSVC 类使用说明
LinearSVC 是线性分类支持向量机,不能使用核函数方法处理非线性分类问题。
LinearSVC 算法与 SVC 算法在使用 'linear' 核函数时的结果基本一致,但 LinearSVC 是基于 liblinear 库实现,计算速度更快。
LinearSVC 有多种惩罚参数和损失函数可供选择,可以应用于大样本集(大于10000)训练。
sklearn.svm.LinearSVC 类是线性分类支持向量机的具体实现,官网介绍详见:https://scikit-learn.org/stable/modules/generated/sklearn.svm.LinearSVC.html#sklearn.svm.LinearSVC
sklearn.svm.LinearSVC()
class sklearn.svm.LinearSVC(penalty='l2', loss='squared_hinge', *, dual=True, tol=0.0001, C=1.0, multi_class='ovr', fit_intercept=True, intercept_scaling=1, class_weight=None, verbose=0, random_state=None, max_iter=1000)
LinearSVC() 类的主要参数:
- C:float, default=1.0 惩罚系数,必须大于0,默认值 1.0。用于设置对错误分类的惩罚强度,对于完全线性可分的硬间隔问题不需要设置。
- fit_intercept : boolean, optional (default=True) 是否计算截距,默认为 True。如果数据均值为 0,则可以选择 False 不计算截距。
- multi_class : string, ‘ovr’ or ‘crammer_singer’ (default=’ovr’) 多类别分类策略开关。对于多元分类问题,选择 'ovr' 将使用多类别策略(one-vs-rest)直接对多个类别进行分类(默认方法);选择 'crammer_singer' 将逐次进行二值分类。
- class_weight:dict or ‘balanced’, default=None 特征变量的加权系数。用于为某个特征变量设权重,默认所有特征变量的权重相同。
LinearSVC() 类的主要属性:
- coef_: 决策函数的参数估计值,即线性模型参数 w1,w2,... 的估计值。
- intercept_: 决策函数中的常数项,即线性模型截距 w0 的估计值。
- classes_: 样本数据的分类标签。指分几类,每一类如何表示。
LinearSVC() 类的主要方法:
- fit(X, y[, sample_weight]) 用样本集的数据(X,y)训练SVM模型。
- get_params([deep]) 获取模型参数。注意不是指分类模型的系数,而是指 penalty, C, fit_intercept, class_weight 等训练的设置参数。
- decision_function(X) 由SVM模型计算 X 的决策函数值,即样本 X 到分离超平面的距离。注意不是分类判别结果。
- predict(X) 用训练好的 SVM 模型预测数据集 X 的分类判别结果,如0/1。
- score(X,y[,sample_weight]) 评价指标,对训练样本集 X 的分类准确度。
LinearSVC 定义训练样本集的输入格式为 (X,y),X 是 n行(样本数)*m列(特征数)的二维数组,y 是样本分类标签。
2.2 LinearSVC 使用例程
# skl_SVM_v1a.py# Demo of linear SVM by scikit-learn# v1.0a: 线性可分支持向量机模型(SciKitLearn)# Copyright 2021 YouCans, XUPT# Crated:2021-05-15import numpy as npimport matplotlib.pyplot as pltfrom sklearn.svm import SVC, LinearSVCfrom sklearn.datasets import make_blobsX, y = make_blobs(n_samples=40, centers=2, random_state=27) # 产生数据集: 40个样本, 2类modelSVM = SVC(kernel='linear', C=100) # SVC 建模:使用 SVC类,线性核函数# modelSVM = LinearSVC(C=100) # SVC 建模:使用 LinearSVC类,运行结果同上modelSVM.fit(X, y) # 用样本集 X,y 训练 SVM 模型print("\nSVM model: Y = w0 + w1*x1 + w2*x2") # 分类超平面模型print('截距: w0={}'.format(modelSVM.intercept_)) # w0: 截距, YouCansprint('系数: w1={}'.format(modelSVM.coef_)) # w1,w2: 系数, XUPTprint('分类准确度:{:.4f}'.format(modelSVM.score(X, y))) # 对训练集的分类准确度# 绘制分割超平面和样本集分类结果plt.scatter(X[:,0], X[:,1], c=y, s=30, cmap=plt.cm.Paired) # 散点图,根据 y值设置不同颜色ax = plt.gca() # 移动坐标轴xlim = ax.get_xlim() # 获得Axes的 x坐标范围ylim = ax.get_ylim() # 获得Axes的 y坐标范围xx = np.linspace(xlim[0], xlim[1], 30) # 创建等差数列,从 start 到 stop,共 num 个yy = np.linspace(ylim[0], ylim[1], 30) #YY, XX = np.meshgrid(yy, xx) # 生成网格点坐标矩阵 XUPTxy = np.vstack([XX.ravel(), YY.ravel()]).T # 将网格矩阵展平后重构为数组Z = modelSVM.decision_function(xy).reshape(XX.shape)ax.contour(XX, YY, Z, colors='k', levels=[-1, 0, 1], alpha=0.5,linestyles=['--', '-', '--']) # 绘制决策边界和分隔ax.scatter(modelSVM.support_vectors_[:, 0], modelSVM.support_vectors_[:, 1], s=100,linewidth=1, facecolors='none', edgecolors='k') # 绘制 支持向量plt.title("Classification by LinearSVM (youcans, XUPT)")plt.show()# === 关注 Youcans,分享更多原创系列 https://www.cnblogs.com/youcans/ ===
2.3 LinearSVC 程序运行结果
SVM model: Y = w0 + w1*x1 + w2*x2截距: w0=[-3.89974328]系数: w1=[[0.72181271 0.34692337]]分类准确度:1.0000
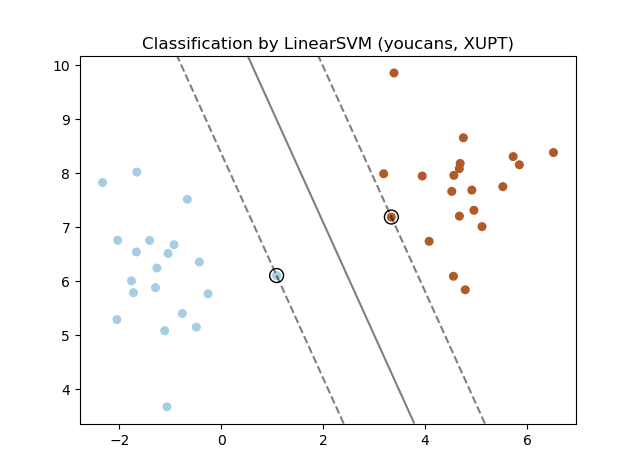
2.4 LinearSVC 程序说明
modelSVM = SVC(kernel='linear', C=100) # SVC 建模:使用 SVC类,线性核函数
modelSVM = LinearSVC(C=100) # SVC 建模:使用 LinearSVC类,运行结果同上
以上程序分别用 SVC()类、LinearSVC()类建模。使用 SVC() 类并选择 'linear' 线性核函数时,模型训练结果与 LinearSVC() 是一致的。但 SVC()类、LinearSVC()类的参数、属性和方法的定义存在差异,例如 LinearSVC()类没有程序中的 support_vectors_ 属性。
3、基于核函数非线性可分支持向量机(NuSVC)
SVC 和 NuSVC 都可以使用核函数方法实现非线性分类。
3.1 NuSVC 类使用说明
NuSVC 是非线性分类支持向量机,使用核函数方法来处理非线性分类问题,基于 libsvm 库实现。
SVC 和 NuSVC 都可以使用核函数方法实现非线性分类,但参数设置有所区别。对于多类别分类问题,通过构造多个“one-versus-one”的二值分类器逐次分类。
sklearn.svm.NuSVC 类是线性分类支持向量机的具体实现,官网介绍详见:https://scikit-learn.org/stable/modules/generated/sklearn.svm.NuSVC.html#sklearn.svm.NuSVC
sklearn.svm.NuSVC()
class sklearn.svm.NuSVC(*, nu=0.5, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=- 1, decision_function_shape='ovr', break_ties=False, random_state=None)
NuSVC() 类的主要参数:
- kernel:{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’}, default=’rbf’ 设定核函数,‘linear’:线性核函数,‘poly’:多项式核函数,‘rbf’:高斯核函数,‘sigmoid’:S形核函数,‘precomputed’:自定义核。默认值为 'rbf' 。
- nu:float, default=0.5 训练错误率的上限,也即支持向量的百分比下限。默认值0.5,取值范围(0,1]。
- degree:int, default=3 多项式核函数的次数,默认值为 3。其它核函数时不适用。
- gamma:{‘scale’, ‘auto’} or float, default=’scale’ ‘rbf’,'poly’ 和 ’sigmoid' 核函数的参数选择方式。
- coef0:float, default=0.0 'poly’ 和 ’sigmoid‘ 核函数的参数。
- class_weight:dict or ‘balanced’, default=None 特征变量的加权系数。用于为某个特征变量设权重,默认所有特征变量的权重相同。\
- probabilitybool:default=False 是否启用概率估计。默认值 False:不启用。
需要注意的是,NuSVC() 类的参数有两类:一类是针对模型训练的通用参数,对所有核函数都适用,例如 nu、tol、max_iter;另一类是针对特定的核函数,只对某种核函数有效,并不适用于其它核函数,例如 degree 只适用于 'poly'核函数,coef0 只适用于'poly’ 和 ’sigmoid‘ 核函数,而且在 'poly’ 和 ’sigmoid‘ 核函数中的含义也不相同。
NuSVC() 类的主要属性:
- classes_: 样本数据的分类标签。指分几类,每一类如何表示。
- coef_: 决策函数的参数估计值。仅在核函数 ‘linear' 时有效,其它核函数时不适用。
- dual_coef_: 对偶系数,即支持向量在决策函数中的系数。
- fit_status_: 算法状态。0 表示算法成功,1 表示算法不收敛。
- intercept_: 决策函数中的常数项。
NuSVC() 类的主要方法:
- fit(X, y[, sample_weight]) 用样本集的数据(X,y)训练 SVM 模型。
- get_params([deep]) 获取模型参数。注意不是指分类模型的系数,而是指kernel, nu,class_weight等训练的设置参数。
- decision_function(X) 由SVM模型计算 X 的决策函数值,即样本 X 到分离超平面的距离。注意不是分类判别结果。
- predict(X) 用训练好的 SVM 模型预测数据集 X 的分类判别结果,如0/1。
- score(X,y[,sample_weight]) 评价指标,对训练样本集 X 的分类准确度。
3.2 NuSVC 使用例程
# skl_SVM_v1b.py# Demo of nonlinear SVM by scikit-learn# v1.0b: 线性可分支持向量机模型(SciKitLearn)# Copyright 2021 YouCans, XUPT# Crated:2021-05-15import numpy as npimport matplotlib.pyplot as pltfrom sklearn.svm import SVC, NuSVC, LinearSVCfrom sklearn.datasets import make_moons# 数据准备:生成训练数据集,生成等高线网格数据X, y = make_moons(n_samples=100, noise=0.1, random_state=27) # 生成数据集x0s = np.linspace(-1.5, 2.5, 100) # 创建等差数列,从 start 到 stop,共 num 个x1s = np.linspace(-1.0, 1.5, 100) # start, stop 根据 Moon 数据范围选择确定x0, x1 = np.meshgrid(x0s, x1s) # 生成网格点坐标矩阵Xtest = np.c_[x0.ravel(), x1.ravel()] # 返回展平的一维数组# SVC 建模,训练和输出modelSVM1 = SVC(kernel='poly', degree=3, coef0=0.2) # 'poly' 多项式核函数modelSVM1.fit(X, y) # 用样本集 X,y 训练支持向量机 1yPred1 = modelSVM1.predict(Xtest).reshape(x0.shape) # 用模型 1 预测分类结果# NuSVC 建模,训练和输出modelSVM2 = NuSVC(kernel='rbf', gamma='scale', nu=0.1) #'rbf' 高斯核函数modelSVM2.fit(X, y) # 用样本集 X,y 训练支持向量机 2yPred2 = modelSVM2.predict(Xtest).reshape(x0.shape) # 用模型 2 预测分类结果# === 关注 Youcans,分享更多原创系列 https://www.cnblogs.com/youcans/ ===fig, ax = plt.subplots(figsize=(8, 6))ax.contourf(x0, x1, yPred1, cmap=plt.cm.brg, alpha=0.1) # 绘制模型1 分类结果ax.contourf(x0, x1, yPred2, cmap='PuBuGn_r', alpha=0.1) # 绘制模型2 分类结果ax.plot(X[:,0][y==0], X[:,1][y==0], "bo") # 按分类绘制数据样本点ax.plot(X[:,0][y==1], X[:,1][y==1], "r^") # XUPTax.grid(True, which='both')ax.set_title("Classification of moon data by LinearSVM")plt.show()
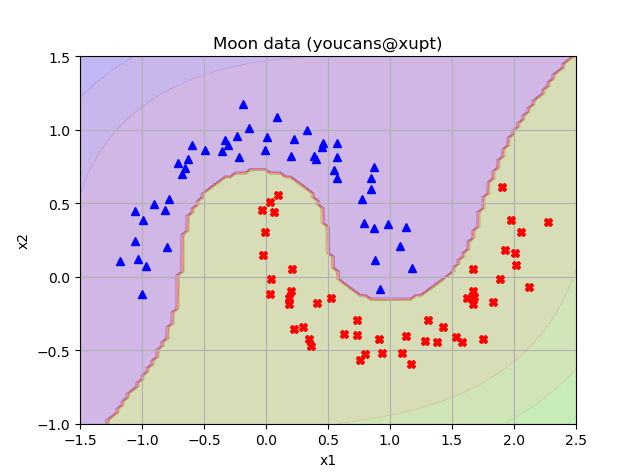
3.3 NuSVC 程序运行结果
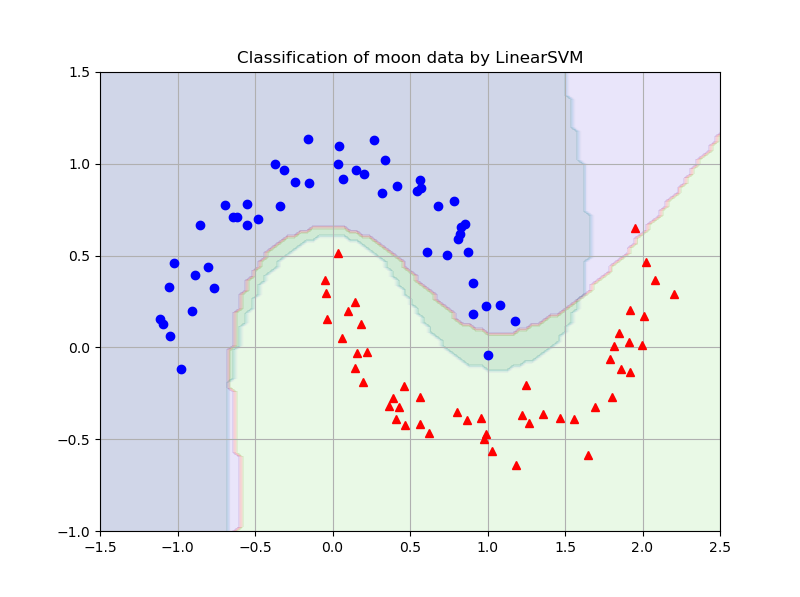
3.4 NuSVC 程序说明
modelSVM1 = SVC(kernel='poly', degree=3, coef0=0.2) # 'poly' 多项式核函数
modelSVM2 = NuSVC(kernel='rbf', gamma='scale', nu=0.1) #'rbf' 高斯核函数
- 以上程序分别用 SVC()类、NuSVC()类建模,并且使用了不同的核函数。
- 如果使用相同的核函数、模型参数, SVC()类、NuSVC()类的模型训练结果是一致的,但参数、属性和方法的定义存在差异。
- 图中分类结果的差异,不是使用 SVC()类、NuSVC()类所导致的,而是使用不同的核函数和模型参数的结果。
- SVC()类、NuSVC()类的参数都有两种,一类是针对模型训练的通用参数,另一类是针对特定的核函数,只对某种核函数有效,并不适用于其它核函数。例如,degree、coef0 都是针对多项式核函数的专用参数,nu、gamma 则是NuSVC() 学习算法的通用参数。
4、支持向量机分类的总结
- 两分分类问题,按照从简单到复杂的程度可以分为:线性可分、近似线性可分、非线性可分、非线性可分也搞不定。
- 近似线性可分与非线性可分具有本质区别,千万不能把近似线性可分理解为轻微的非线性。近似线性可分,针对的还是线性可分的问题,只是由于数据集中个别样本的误差或错误,造成线性分割时个别点会分类判别错误,训练的结果得到的是一个线性分类器。非线性可分,针对的是非线性分类问题,训练结果得到的是一个非线性分类器。
- 针对具体问题如何选择线性分类、近似线性分类还是非线性分类?这其实是两个问题。线性分类与近似线性分类不是非此即彼的对立关系,只是对分类准确性要求的程度差异。惩罚系数 C>0 就反映了对于分类错误的惩罚程度,C值越大表示对于分类准确性的要求越高,C取无穷大就意味着要求严格线性可分、没有错误分类。选择线性分类模型,如果对训练样本或检验样本进行分类判断的错误率很高(score 低),就要考虑使用非线性模型进行分类了。
- 核函数的选择,这是一个非常复杂而且没有标准答案的问题。SVC() 和 NuSVC() 都提供了核函数 'linear','poly','rbf','sigmoid','precomputed' 可供选择。
- 'linear' 就不用说了,这简直就是来捣乱的;'precomputed' 也不用说,你如果能搞定就不用看这篇文章里。
- 接下来,推荐使用 'poly' 和 'rbf' 核函数,优先选择 'poly' 多项式核函数。
- 再接下来,使用 'poly' 核函数时,推荐选择 degree=2、degree=3 分别试试。
=== 关注 Youcans,分享更多原创系列 https://www.cnblogs.com/youcans/ ===
版权说明:
本文中案例问题和数据来自:Sci-Kit Learn 官网:https://scikit-learn.org/stable/modules/svm.html#svm-classification
本文例程参考了Sci-Kit Learn 官网的例程,但作者重写了这些例程。
本文内容为作者原创,并非转载书籍或网络内容。
YouCans 原创作品
Copyright 2021 YouCans, XUPT
Crated:2021-05-09
Python数模笔记-Sklearn(5)支持向量机的更多相关文章
- Python数模笔记-Sklearn(1) 介绍
1.SKlearn 是什么 Sklearn(全称 SciKit-Learn),是基于 Python 语言的机器学习工具包. Sklearn 主要用Python编写,建立在 Numpy.Scipy.Pa ...
- Python数模笔记-Sklearn(4)线性回归
1.什么是线性回归? 回归分析(Regression analysis)是一种统计分析方法,研究自变量和因变量之间的定量关系.回归分析不仅包括建立数学模型并估计模型参数,检验数学模型的可信度,也包括利 ...
- Python数模笔记-Sklearn(2)样本聚类分析
1.分类的分类 分类的分类?没错,分类也有不同的种类,而且在数学建模.机器学习领域常常被混淆. 首先我们谈谈有监督学习(Supervised learning)和无监督学习(Unsupervised ...
- Python数模笔记-Sklearn(3)主成分分析
主成分分析(Principal Components Analysis,PCA)是一种数据降维技术,通过正交变换将一组相关性高的变量转换为较少的彼此独立.互不相关的变量,从而减少数据的维数. 1.数据 ...
- Python数模笔记-StatsModels 统计回归(4)可视化
1.如何认识可视化? 图形总是比数据更加醒目.直观.解决统计回归问题,无论在分析问题的过程中,还是在结果的呈现和发表时,都需要可视化工具的帮助和支持. 需要指出的是,虽然不同绘图工具包的功能.效果会有 ...
- Python数模笔记-StatsModels 统计回归(1)简介
1.关于 StatsModels statsmodels(http://www.statsmodels.org)是一个Python库,用于拟合多种统计模型,执行统计测试以及数据探索和可视化. 2.文档 ...
- Python数模笔记-Scipy库(1)线性规划问题
1.最优化问题建模 最优化问题的三要素是决策变量.目标函数和约束条件. (1)分析影响结果的因素是什么,确定决策变量 (2)决策变量与优化目标的关系是什么,确定目标函数 (3)决策变量所受的限制条件是 ...
- Python数模笔记-NetworkX(3)条件最短路径
1.带有条件约束的最短路径问题 最短路径问题是图论中求两个顶点之间的最短路径问题,通常是求最短加权路径. 条件最短路径,指带有约束条件.限制条件的最短路径.例如,顶点约束,包括必经点或禁止点的限制:边 ...
- Python数模笔记-(1)NetworkX 图的操作
1.NetworkX 图论与网络工具包 NetworkX 是基于 Python 语言的图论与复杂网络工具包,用于创建.操作和研究复杂网络的结构.动力学和功能. NetworkX 可以以标准和非标准的数 ...
随机推荐
- react第三方库
作者:慕课网链接:https://www.zhihu.com/question/59073695/answer/1071631250来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请 ...
- js前端技术
一.前端技术 1.HTML HTML(hypertext markup language)超文本标记语言,不同于编程语言. 超文本就是超出纯文本的范畴,描述文本的颜色.大小.字体. HTML由一个个标 ...
- 攻防世界 reverse 进阶 notsequence
notsequence RCTF-2015 关键就是两个check函数 1 signed int __cdecl check1_80486CD(int a1[]) 2 { 3 signed int ...
- 密码学系列之:csrf跨站点请求伪造
目录 简介 CSRF的特点 CSRF的历史 CSRF攻击的限制 CSRF攻击的防范 STP技术 Cookie-to-header token Double Submit Cookie SameSite ...
- 为了效率,我们可以用的招数 之 strlen
如果要你写一个计算字符串长度的函数 strlen,应该怎么写?相信你很容易写出如下实现: 1 int strlen_1(const char* str) { 2 int cnt = 0; 3 4 if ...
- Activiti工作流学习笔记(四)——工作流引擎中责任链模式的建立与应用原理
原创/朱季谦 本文需要一定责任链模式的基础,主要分成三部分讲解: 一.简单理解责任链模式概念 二.Activiti工作流里责任链模式的建立 三.Activiti工作流里责任链模式的应用 一.简单理解责 ...
- 2020 OO 第二单元总结
只要跑得够快即使从头关到尾你也喜欢吗? 一.设计策略 1.1 总体策略概述 在多线程的协同和同步控制方面,我三次作业都是采用生产者/消费者模式(还憨憨地在内部分了customer.producer.t ...
- Python写的微服务如何融入Spring Cloud体系?
前言 在今天的文章中小码哥将会给大家分享一个目前工作中遇到的一个比较有趣的案例,就是如何将Python写的微服务融入到以Java技术栈为主的Spring Cloud微服务体系中?也许有朋友会有疑问,到 ...
- 铁人三项(第五赛区)_2018_seven
铁人三项(第五赛区)_2018_seven 先来看看保护 保护全开,IDA分析 首先申请了mmap两个随机地址的空间,一个为rwx,一个为rw 读入的都shellcode长度小于等于7,且这7个字符不 ...
- Salesforce学习之路(一)几个简单概念
Salesforce是一款非常强大的CRM(Customer Relationship Management)系统,国外企业使用十分频繁,而国内目前仅有几家在使用(当然,国内外企使用的依旧较多),因此 ...