python爬虫——拉钩网python岗位信息
之前爬取的网页都是采用“GET”方法,这次爬取“拉勾网”是采取了“POST”的方法。其中,"GET"和“POST”之间最大的区别就是:"GET"请求时,数据会直接显示在地址栏;“POST”请求时,数据在数据包(封装在请求体中,通常是js中),爬取难度相对大点。“拉勾网”恰好是需要“POST”请求才能获取信息。于是,就写了这次的程序:
首先,还是从抓包开始,在拉勾网中输入python,再选中深圳,在network中找到position.Ajax的文件,里面包含当前页面的岗位详细信息、岗位总数等。
![]()
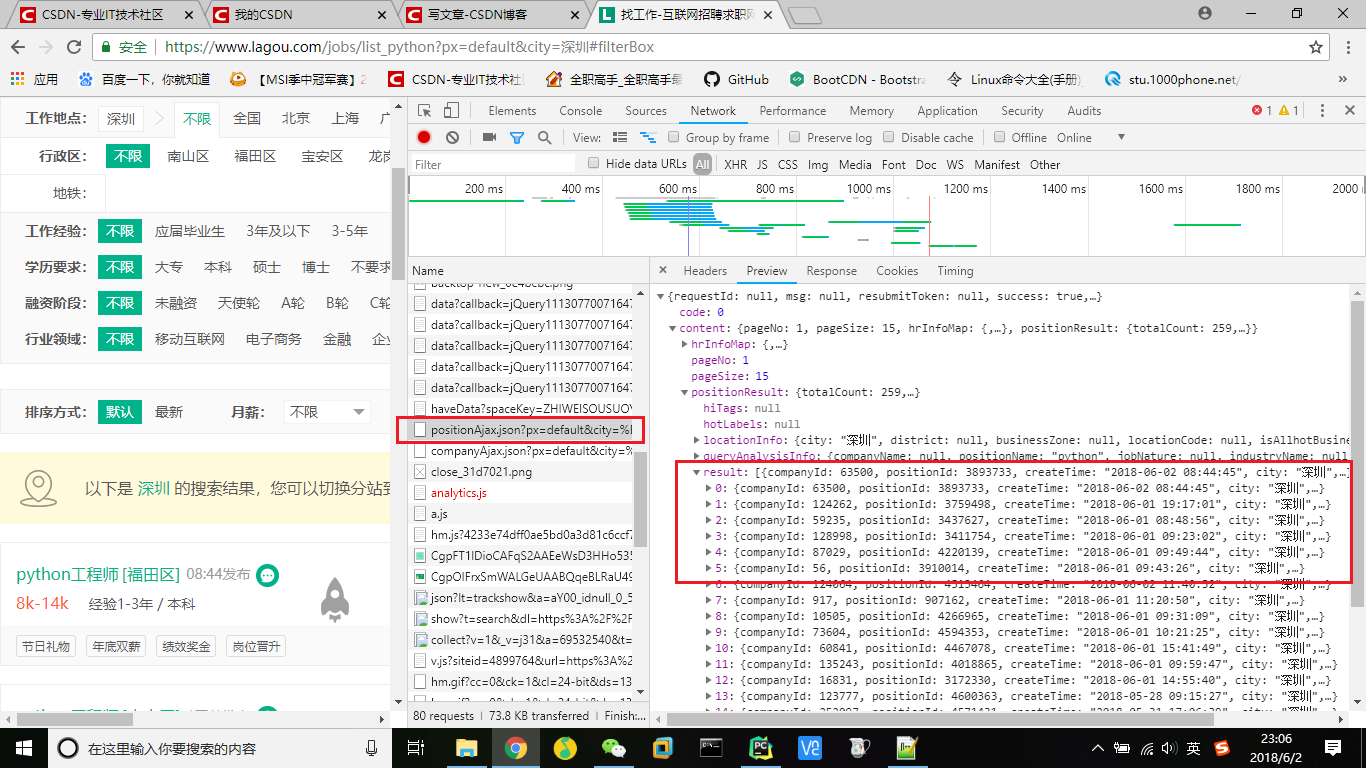
因此,就以这个作为请求网址(URL),再从headers中找到相关请求头参数以及data数据,接下来就可以发起请求了,采用requests的post方法。
#请求内容(请求网址、请求头和请求数据)
url = r'https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3423.2 Safari/537.36",
"Accept":"application/json, text/javascript, */*; q=0.01",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"Host":"www.lagou.com",
"Origin":"https://www.lagou.com",
"Referer":"https://www.lagou.com/jobs/list_python?px=default&city=%E5%B9%BF%E5%B7%9E",
"Cookie":"JSESSIONID=ABAAABAABEEAAJAED90BA4E80FADBE9F613E7A3EC91067E; _ga=GA1.2.1013282376.1527477899; user_trace_token=20180528112458-b2b32f84-6226-11e8-ad57-525400f775ce; LGUID=20180528112458-b2b3338b-6226-11e8-ad57-525400f775ce; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1527346927,1527406449,1527423846,1527477899; _gid=GA1.2.1184022975.1527477899; index_location_city=%E5%85%A8%E5%9B%BD; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1527487349; LGSID=20180528140228-b38fe5f2-623c-11e8-ad79-525400f775ce; PRE_UTM=; PRE_HOST=; PRE_SITE=https%3A%2F%2Fwww.lagou.com%2Fzhaopin%2FPython%2F%3FlabelWords%3Dlabel; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_Python%3Fpx%3Ddefault%26city%3D%25E5%25B9%25BF%25E5%25B7%259E; TG-TRACK-CODE=index_search; _gat=1; LGRID=20180528141611-9e278316-623e-11e8-ad7c-525400f775ce; SEARCH_ID=42c704951afa48b5944a3dd0f820373d"
}
data = {
"first":True,
"pn":1,
"kd":"python"
}![]()
#json数据爬取
def dataJson(url,headers,data):
#发起请求(POST)
req = requests.post(url, data = data, headers = headers)
#返回并解析请求结果(字符串格式)
response = req.text
#转换成json格式
htmlJson = json.loads(response)
#返回json格式数据
return htmlJson![]()
返回的数据转换成json格式,方便后面的数据筛选,通过分析发现,岗位详细信息在json数据中显示,通过筛选出来再返回总的岗位数量以及岗位页数
#岗位数量和页数筛选
def positonCount(htmlJson):
# 筛选岗位数量和页数
totalCount = htmlJson["content"]["positionResult"]["totalCount"]
#每页显示15个岗位(向上取整)
page = math.ceil((totalCount)/15)
# 拉勾网最多显示30页结果
if page > 30:
return 30
else:
return (totalCount,page)![]()
#岗位详细信息筛选
def selectData(htmlJson):
#筛选出岗位详细信息
jobList = htmlJson["content"]["positionResult"]["result"]
#创建工作信息列表(外表)
jobinfoList = []
#遍历,找出数据
for jobDict in jobList:
#创建工作信息列表(内表)
jobinfo = []
# 岗位名称
jobinfo.append(jobDict['positionName'])
#公司名称
jobinfo.append(jobDict['companyFullName'])
#公司性质
jobinfo.append(jobDict['financeStage'])
#公司规模
jobinfo.append(jobDict['companySize'])
#行业领域
jobinfo.append(jobDict['industryField'])
# 办公地点(所处地区)
jobinfo.append(jobDict['district'])
#岗位标签
positionLables = jobDict['positionLables']
ret1 = ""
for positionLable in positionLables:
ret1 += positionLable + ";"
jobinfo.append(ret1)
#学历要求
jobinfo.append(jobDict['education'])
#工作经验
jobinfo.append(jobDict['workYear'])
#工资
jobinfo.append(jobDict['salary'])
#待遇
jobinfo.append(jobDict['positionAdvantage'])
#公司福利
companyLabelList = jobDict['companyLabelList']
ret2 = ""
for companyLabel in companyLabelList:
ret2 += companyLabel + ";"
jobinfo.append(ret2)
#岗位类型
jobinfo.append(jobDict['firstType'])
#发布时间
jobinfo.append(jobDict['createTime'])
#添加都岗位信息列表
jobinfoList.append(jobinfo)
#间隔时间为30s,防止访问过于频繁
time.sleep(30)
return jobinfoList![]()
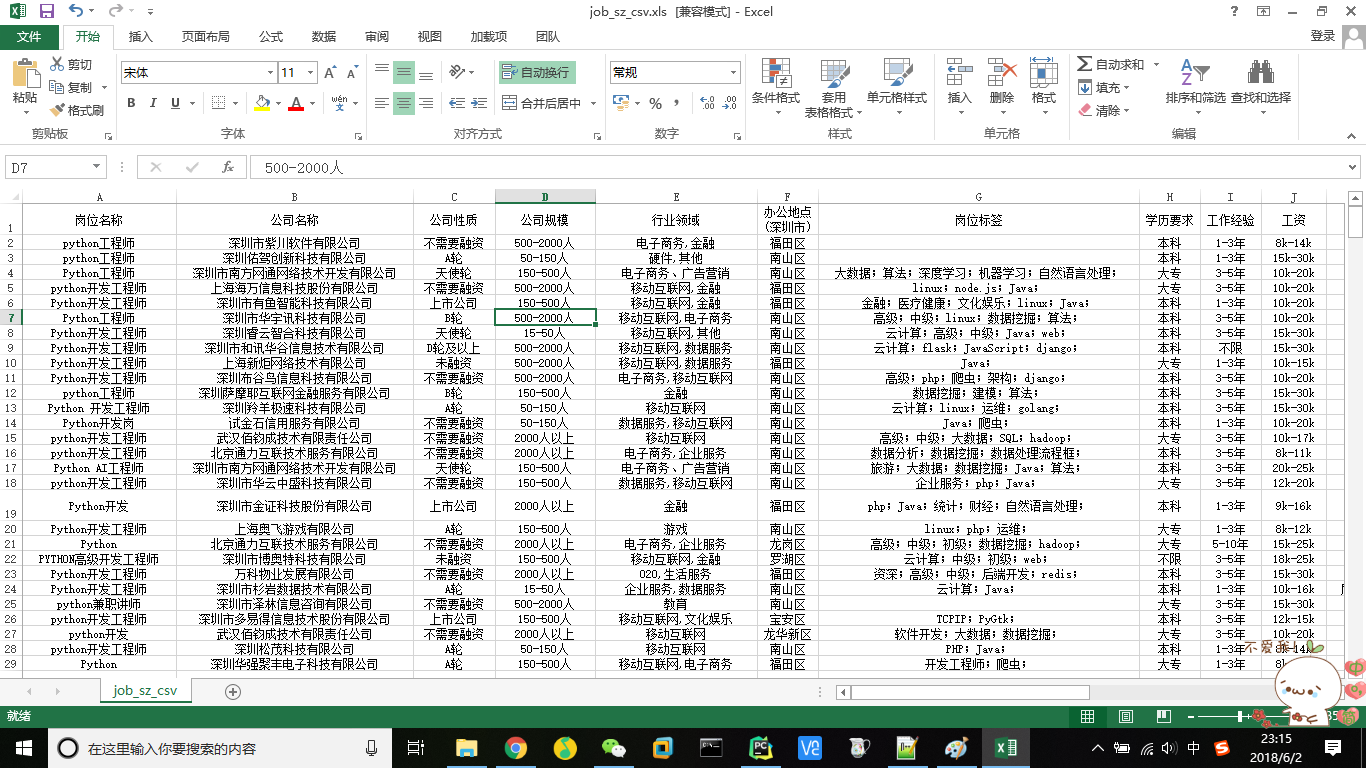
结果如下:
![]()
![]()
以上就是我的分享,如果有什么不足之处请指出,多交流,谢谢!
如果喜欢,请关注我的博客:https://www.cnblogs.com/qiuwuzhidi/
想获取更多数据或定制爬虫的请点击python爬虫专业定制
python爬虫——拉钩网python岗位信息的更多相关文章
- python爬虫拉钩网:{'msg': '您操作太频繁,请稍后再访问', 'clientIp': '113.57.176.181', 'success': False}
反爬第一课: 在打印html.text的时候总会提示 {'success': False, 'msg': '您操作太频繁,请稍后再访问', 'clientIp': '113.14.1.254'} 需要 ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- python爬虫---->github上python的项目
这里面通过爬虫github上的一些start比较高的python项目来学习一下BeautifulSoup和pymysql的使用.我一直以为山是水的故事,云是风的故事,你是我的故事,可是却不知道,我是不 ...
- day 112天,爬虫(拉钩网,斗音,GitHub)第二天
提前准备工作.安装准备工作(day3用) 1. 安装scrapy https://www.cnblogs.com/wupeiqi/articles/6229292.html a. 下载twiste ...
- 【python爬虫】用python编写LOL战绩查询
介绍一个简单的python爬虫,通过Tkinter创建一个客户端,当输入要查询的LOL用户名称的时候,可以显示出当前用户的所在服务器,当前战力和当前段位. 爬取网页地址:http://lol.duow ...
- python爬虫27 | 当Python遇到MongoDB的时候,存储av女优的数据变得如此顺滑爽~
上次 我们知道了怎么操作 MySQL 数据库 python爬虫26 | 把数据爬取下来之后就存储到你的MySQL数据库. MySQL 有些年头了 开源又成熟又牛逼 所以现在很多企业都在使用 MySQL ...
- 简单python爬虫编写,Python采集妹子图!
疫情期间在家闲来无事,每天打游戏荒废了一段时间.我觉得自己不能在这么颓废下去,就立马起身写了一点python代码(本人只是python新手). 很多人学习python,不知道从何学起.很多人学习pyt ...
- Python爬虫学习--用Python结合Selenium实现 明日之子节目直播时为自己喜欢的选手自动点赞拉票!!!
声明:本脚本纯属娱乐,请勿用来非法点赞拉票,任何使用不当造成的后果自行承担. 闲话: 明日之子第二季开始好久了,作者一直再追,特别喜欢里面那个酷酷的小哥-蔡泽明.前两天晋选9大厂牌,采取的是直播的形式 ...
- Python爬虫学习:Python内置的爬虫模块urllib库
urllib库 urllib库是Python中一个最基本的网络请求的库.它可以模拟浏览器的行为发送请求(都是这样),从而获取返回的数据 urllib.request 在Python3的urllib库当 ...
随机推荐
- vim命令c编程
1.移动光标的常用命令 h--向左移动光标 l--向右移动光标 j--向下移动光标 k--向上移动光标 ^--将光标移动至该行的开头 $--将光标移动至该行的结尾 O--将光标移动至该行行首 G--将 ...
- 【LeetCode】52. N-Queens II(位运算)
[题意] 输出N皇后问题的解法个数. [题解] 解法一:传统dfs回溯,模拟Q放置的位置即可,应该不难,虽然能通过,但是时间复杂度很高. 解法二:位运算大法好! 首先要明白这道题里两个核心的位运算 1 ...
- MyBatis、Spring、SpringMVC 源码下载地址
MyBatis.Spring.SpringMVC 源码下载地址 github mybatis https://github.com/fengyu415/MyBatis-Learn.git spring ...
- JAVA面试核心知识点(一):计算机网络
一·计算机网络 1.1 网络基础知识 OSI 七层协议(制定标准使用的标准概念框架): 物理层(传递比特流0101)->数据链路层(将比特流转换为逻辑传输线路)->网络层(逻辑编址,分组传 ...
- (三)SpringBoot启动过程的分析-创建应用程序上下文
-- 以下内容均基于2.1.8.RELEASE版本 紧接着上一篇(二)SpringBoot启动过程的分析-环境信息准备,本文将分析环境准备完毕之后的下一步操作:ApplicationContext的创 ...
- Maven项目中resources配置总结
目录 背景 第一部分 基本配置介绍 第二部分 具体配置和注意事项 第三部分 读取resources资源 参考文献及资料 背景 通常Maven项目的文件目录结构如下: # Maven项目的标准目录结构 ...
- 单链表c语言实现的形式
包括初始化,创建,查询,长度,删除,清空,销毁等操作 代码如下: #include<stdio.h> #include<stdlib.h> //定义单链表的数据类型 typed ...
- 我的xshell配色方案,绿色/护眼/留存/备份
[mycolor] text(bold)=e9e9e9 magenta(bold)=ff00ff text=00ff80 white(bold)=fdf6e3 green=80ff00 red(bol ...
- 折腾kubernetes各种问题汇总-<1>
折腾kubernetes各种问题汇总-<1> 折腾部署fluend-elasticsearch日志,折腾出一大堆问题,解决这些问题过程中,感觉又了解了不少. 如何删除不一致状态下的rc,d ...
- 第十届蓝桥杯大赛软件类省赛C/C++研究生组 试题I:灵能传输
在游戏<星际争霸 II>中,高阶圣堂武士作为星灵的重要 AOE 单位,在游戏的中后期发挥着重要的作用,其技能"灵能风暴"可以消耗大量的灵能对一片区域内的敌军造成毁灭性的 ...