教你几招HASH表查找的方法
摘要:根据设定的哈希函数 H(key) 和所选中的处理冲突的方法,将一组关键字映象到一个有限的、地址连续的地址集 (区间) 上,并以关键字在地址集中的“象”作为相应记录在表中的存储位置,如此构造所得的查找表称之为“哈希表”。
本文分享自华为云社区《查找——HASH》,原文作者:ruochen。
对于频繁使用的查找表,希望 ASL = 0
记录在表中位置和其关键字之间存在一种确定的关系
HASH
定义
根据设定的哈希函数 H(key) 和所选中的处理冲突的方法,将一组关键字映象到一个有限的、地址连续的地址集 (区间) 上,并以关键字在地址集中的“象”作为相应记录在表中的存储位置,如此构造所得的查找表称之为“哈希表”
HASH函数的构造
- 构造原则
- 函数本身便于计算
- 计算出来的地址分布均匀,即对任一关键字k,f(k) 对应不同地址的概率相等,目的是尽可能减少冲突
直接定址法
- 哈希函数为关键字的线性函数
- H(key) = key
- H(key) = a * key + b
- 此法仅适合于:
地址集合的大小 = = 关键字集合的大小 - 优点:以关键码key的某个线性函数值为哈希地址,不会产生冲突
- 缺点:要占用连续地址空间,空间效率低
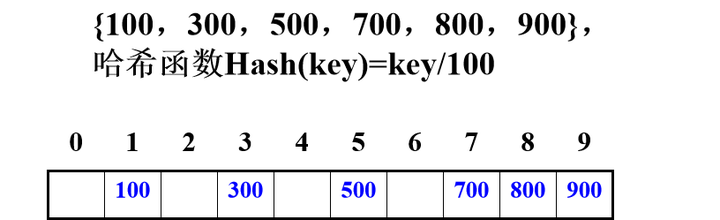
数字分析法
- 假设关键字集合中的每个关键字都是由 s 位数字组成 (u1, u2, …, us),分析关键字集中的全体, 并从中提取分布均匀的若干位或它们的组合作为地址
- 此方法仅适合于:
能预先估计出全体关键字的每一位上各种数字出现的频度
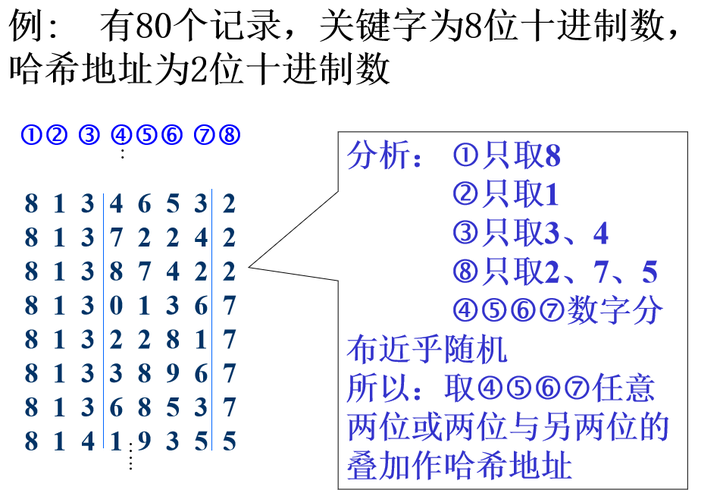
平方取中法
- 以关键字的平方值的中间几位作为存储地址。求“关键字的平方值” 的目的是“扩大差别” ,同时平方值的中间各位又能受到整个关键字中各位的影响
- 此方法适合于:
关键字中的每一位都有某些数字重复出现频度很高的现象
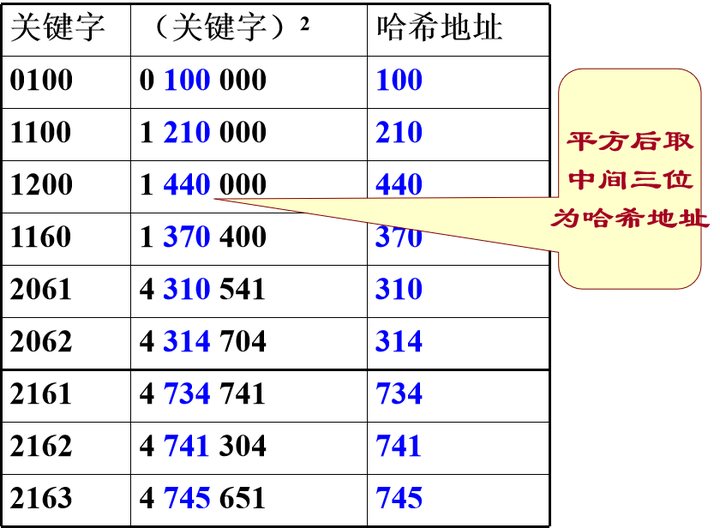
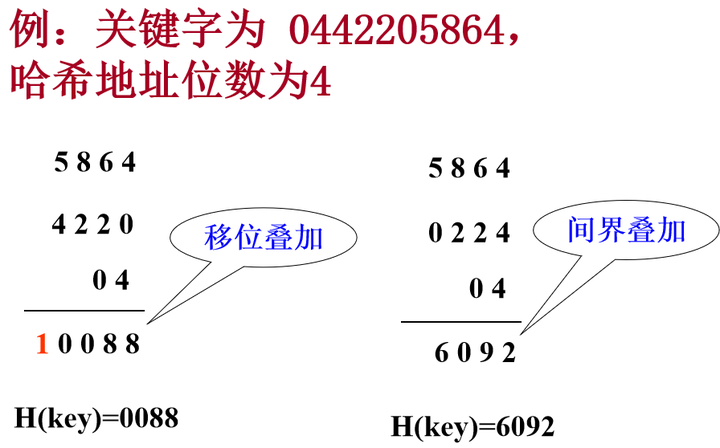
折叠法
- 将关键字分割成若干部分,然后取它们的叠加和为哈希地址。有两种叠加处理的方法:移位叠加和间界叠加
- 此方法适合于:
关键字的数字位数特别多
除留余数法
- Hash(key)=key mod p (p是一个整数)
- p≤m (表长)
- p 应为小于等于 m 的最大素数
为什么要对 p 加限制?
给定一组关键字为: 12, 39, 18, 24, 33, 21若取 p=9, 则他们对应的哈希函数值将为:
3, 3, 0, 6, 6, 3
可见,若 p 中含质因子 3, 则所有含质因子 3 的关键字均映射到“3 的倍数”的地址上,从而增加了“冲突”的可能

随机数法
- H(key) = Random(key) (Random 为伪随机函数)
- 此方法用于对长度不等的关键字构造哈希函数
考虑因素
- 执行速度(即计算哈希函数所需时间)
- 关键字的长度
- 哈希表的大小
- 关键字的分布情况
- 查找频率
采用何种构造哈希函数的方法取决于建表的关键字集合的情况
原则是使产生冲突的可能性降到尽可能地小
处理冲突的方法
1. 开放定址法
基本思想
- 有冲突时就去寻找下一个空的哈希地址,只要哈希表足够大,空的哈希地址总能找到,并将数据元素存入
线性探测法
- Hi=(Hash(key)+di) mod m ( 1≤i < m )
其中:m为哈希表长度
di 为增量序列 1,2,…m-1,且di=i
一旦冲突,就找下一个空地址存入

- 优点:只要哈希表未被填满,保证能找到一个空地址单元存放有冲突的元素
- 缺点:能使第i个哈希地址的同义词存入第i+1个地址,这样本应存入第i+1个哈希地址的元素变成了第i+2个哈希地址的同义词,……,产生“聚集”现象,降低查找效率
二次探测法
di = 12, -12, 22, -22, …±k2

伪随机探测法
Hi=(Hash(key)+di) mod m ( 1≤i < m )
其中:m为哈希表长度
di 为随机数
开放定址法建立哈希表步骤
- 取数据元素的关键字key,计算其哈希函数值(地址)。若该地址对应的存储 空间还没有被占用,则将该元素存入;否则执行step2解决冲突
- 根据选择的冲突处理方法,计算关键字key的下一个存储地址。若下一个存储地址仍被占用,则继续执行step2,直到找 到能用的存储地址为止
开放定址哈希表的存储结构
/* ------------- 开放定址哈希表的存储结构 ------------- */
int hashsize[] = {997, ...};
typedef struct{
ElemType* elem;
int count; // 当前数据元素个数
int sizeindex; // hashsize[sizeindex]为当前容量
} HashTable;
#define SUCCESS 1
#define UNSUCCESS 0
#define DUPLICATE -1
Status SearchHash(HashTable H, KeyType K, int &p, int &c){
// 在开放定址哈希表H中查找关键码为K的记录
p = Hash(K); // 求得哈希地址
while(H.elem[p].key != NULLKEY && !EQ(K, H.elem[p].key))
collisiion(p, ++c); // 求得下一探测地址p
if(EQ(K, H.elem[p].key)) return SUCCESS; // 查找成功,返回待查数据元素位置 p
else return UNSUCCESS; // 查找不成功
}
2. 再HASH法
- H2(key) 是另设定的一个哈希函数,它的函数值应和 m 互质

3. 链地址法
基本思想
- 相同哈希地址的记录链成一单链表,m个哈希地址就设m个单链表,然后用用一个数组将m个单链表的表头指针存储起来,形成一个动态的结构
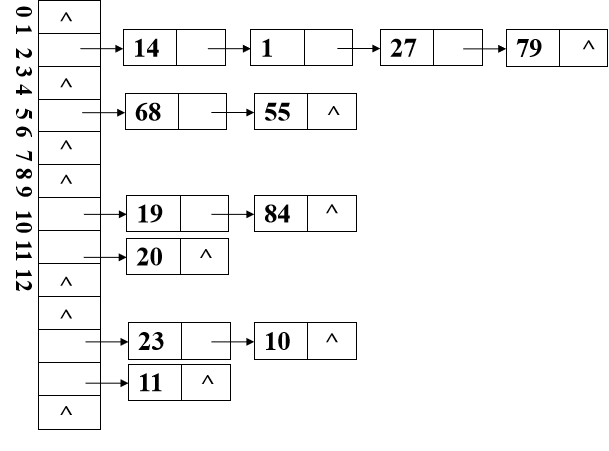
优点:
- 非同义词不会冲突,无“聚集”现象
- 链表上结点空间动态申请,更适合于表长不确定的情况
哈希表的查找
对于给定值 K,计算哈希地址 i = H(K)
- 若 r[i] = NULL 则查找不成功
- 若 r[i].key = K 则查找成功, 否则 “求下一地址 Hi” ,直至r[Hi] = NULL (查找不成功) 或r[Hi].key = K (查找成功) 为止
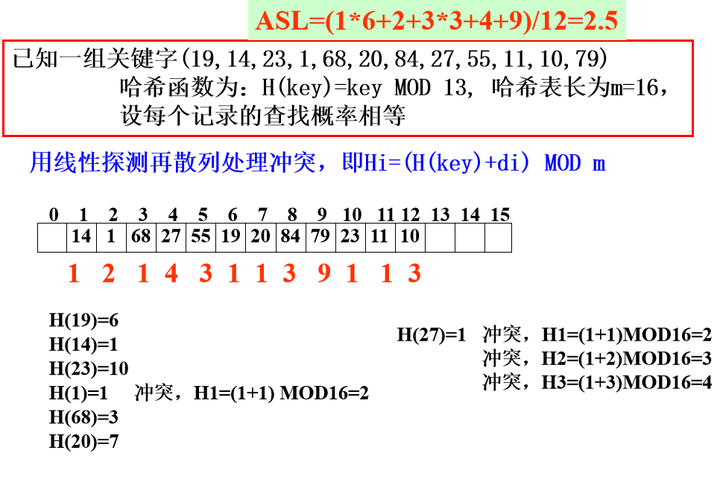
案例v01
- 线性探测法解决冲突
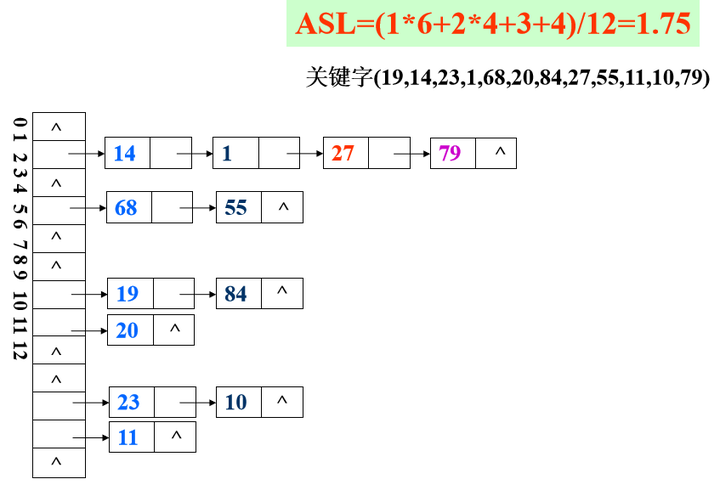
案例v02
- 链地址法处理冲突
哈希表查找的分析
从查找过程得知,哈希表查找的平均查找长度实际上并不等于零
决定哈希表查找的ASL的因素
- 选用的哈希函数
- 选用的处理冲突的方法
- 哈希表饱和的程度,装载因子 α=n/m 值的大小(n—记录数,m—表的长度)
α 越大,表中记录数越多,说明表装得越满,发生冲突的可能性就越大,查找时比较次数就越多

- 对哈希表技术具有很好的平均性能,优于一些传统的技术
- 链地址法优于开地址法
- 除留余数法作哈希函数优于其它类型函数
哈希表应用举例
编译器对标识符的管理多是采用哈希表
- 构造哈希函数的方法
- 将标识符中的每个字符转换为一个非负整数
- 将得到的各个整数组合成一个整数(可以将第一个、中间的和最后一个字符值加在一起,也可以将所有字符的值加起来)
- 将结果数调整到0~M-1范围内,可以利用取模的方法,Ki%M(M为素数)
教你几招HASH表查找的方法的更多相关文章
- NGINX(三)HASH表
前言 nginx的hash表有几种不同的种类, 不过都是以ngx_hash_t为基础的, ngx_hash_t是最普通的hash表, 冲突采用的是链地址法, 不过这里冲突的元素不是一个链表, 而是一个 ...
- Hash表的扩容(转载)
Hash表(Hash Table) hash表实际上由size个的桶组成一个桶数组table[0...size-1] . 当一个对象经过哈希之后.得到一个对应的value , 于是我们把这个对象放 ...
- HASH表的实现(拉链法)
本文的一些基本概念参考了一部分百度百科,当然只保留了最有价值的部分,代码部分完全是自己实现! 简介 哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据 ...
- hash表的理解
哈希表 先从数组说起 任何一个程序员,基本上对数组都不会陌生,这个最常用的数据结构,说到它的优点,最明显的就是两点: 简单易用,数组的简易操作甚至让大多数程序员依赖上了它,在资源富足的情况下,我们甚至 ...
- 海量路由表能够使用HASH表存储吗-HASH查找和TRIE树查找
千万别! 非常多人这样说,也包括我. Linux内核早就把HASH路由表去掉了.如今就仅仅剩下TRIE了,只是我还是希望就这两种数据结构展开一些形而上的讨论. 1.hash和trie/radix ha ...
- python 字典有序无序及查找效率,hash表
刚学python的时候认为字典是无序,通过多次插入,如di = {}, 多次di['testkey']='testvalue' 这样测试来证明无序的.后来接触到了字典查找效率这个东西,查了一下,原来字 ...
- Hash表的平均查找长度ASL计算方法
Hash表的“查找成功的ASL”和“查找不成功的ASL” ASL指的是 平均查找时间 关键字序列:(7.8.30.11.18.9.14) 散列函数: H(Key) = (key x 3) MOD 7 ...
- hash表的建立和查找
(1)冲突处理方法为:顺次循环后移到下一个位置,寻找空位插入.(2)BKDE 字符串哈希unsigned int hash_BKDE(char *str){/* 初始种子seed 可取31 131 1 ...
- IE-“无法浏览网页” 教你十招解决疑难杂症
“无法浏览网页” 教你十招解决疑难杂症 相信大家也有遇到过像IE不能上网浏览的问题.下面就来给大家介绍一下常见原因和解决方法: 一.网络设置的问题 这种原因比较多出现在需要手动指定IP.网关.DNS服 ...
随机推荐
- Linux 内存 占用较高问题排查
Linux 内存 占用较高问题排查 niuhao307523005 2019-04-24 14:31:55 11087 收藏 11展开一 查看内存情况#按 k 查看 free #按兆M查看 free ...
- 034.Python的__str__,__repr__,__bool__ ,__add__和__len__魔术方法
Python的其他方法 1 __str__方法 触发时机: 使用print(对象)或者str(对象)的时候触发 功能: 查看对象信息 参数: 一个self接受当前对象 返回值: 必须返回字符串类型 基 ...
- 011.Kubernetes使用共享存储持久化数据
本次实验是以前面的实验为基础,使用的是模拟使用kubernetes集群部署一个企业版的wordpress为实例进行研究学习,主要的过程如下: 1.mysql deployment部署, wordpre ...
- mysql基础之视图、事务、索引、外键
一.视图 视图是一个虚拟表,其内容由查询定义.同真实的表一样,视图包含一系列带有名称的列和行数据.但是,视图并不在数据库中以存储的数据值集形式存在.行和列数据来自由定义视图的查询所引用的表,并且在引用 ...
- thinkphp api接口 统一结果返回处理类
20210602 修正 wqy的笔记:http://www.upwqy.com/details/216.html 返回结果处理,归根结底 主要是有两点 数据结构和返回的数据类型 1.数据类型 :一般情 ...
- 关于一类docker容器闪退问题定位
背景:正在学习docker期间,接到一个任务,通过docker部署一个应用A.该应用A类似于之前部署的应用B,结果很自然地犯了形而上学的错误. 思路:基于dockerfile+docker-compo ...
- [转]CAP和BASE理论
1. CAP理论 2000年7月,加州大学伯克利分校的Eric Brewer教授在ACM PODC会议上提出CAP猜想.2年后,麻省理工学院的Seth Gilbert和Nancy Lynch从理论上证 ...
- python 导入同级目录文件、上级目录文件以及下级目录数据集和模块包
划重点: 其中dataset_path = ''表示在Python工作文件夹 dataset_path = '..'表示在Python工作文件夹的上级文件夹 dataset_path = '某某文件夹 ...
- Django(50)drf异常模块源码分析
异常模块源码入口 APIView类中dispatch方法中的:response = self.handle_exception(exc) 源码分析 我们点击handle_exception跳转,查看该 ...
- 『动善时』JMeter基础 — 38、JMeter中实现跨线程组关联
目录 1.JMeter中实现跨线程组关联说明 (1)JMeter中实现跨线程组关联步骤 (2)测试计划内包含的元件 2.用户登陆请求的相关操作 (1)进行登陆操作获取Cookie信息 (2)把Cook ...