日志收集系统系列(五)之LogTransfer
从kafka里面把日志取出来,写入ES,使用Kibana做可视化展示
1. ElasticSearch
1.1 介绍
Elasticsearch(ES)是一个基于Lucene构建的开源、分布式、RESTful接口的全文搜索引擎。Elasticsearch还是一个分布式文档数据库,其中每个字段均可被索引,而且每个字段的数据均可被搜索,ES能够横向扩展至数以百计的服务器存储以及处理PB级的数据。可以在极短的时间内存储、搜索和分析大量的数据。通常作为具有复杂搜索场景情况下的核心发动机。
1.2 Elasticsearch能做什么
当你经营一家网上商店,你可以让你的客户搜索你卖的商品。在这种情况下,你可以使用ElasticSearch来存储你的整个产品目录和库存信息,为客户提供精准搜索,可以为客户推荐相关商品。
当你想收集日志或者交易数据的时候,需要分析和挖掘这些数据,寻找趋势,进行统计,总结,或发现异常。在这种情况下,你可以使用Logstash或者其他工具来进行收集数据,当这引起数据存储到ElasticsSearch中。你可以搜索和汇总这些数据,找到任何你感兴趣的信息。
对于程序员来说,比较有名的案例是GitHub,GitHub的搜索是基于ElasticSearch构建的,在github.com/search页面,你可以搜索项目、用户、issue、pull request,还有代码。共有40~50个索引库,分别用于索引网站需要跟踪的各种数据。虽然只索引项目的主分支(master),但这个数据量依然巨大,包括20亿个索引文档,30TB的索引文件。
1.3 Elasticsearch基本概念
Near Realtime(NRT) 几乎实时
Elasticsearch是一个几乎实时的搜索平台。意思是,从索引一个文档到这个文档可被搜索只需要一点点的延迟,这个时间一般为毫秒级。
Cluster 集群
群集是一个或多个节点(服务器)的集合, 这些节点共同保存整个数据,并在所有节点上提供联合索引和搜索功能。一个集群由一个唯一集群ID确定,并指定一个集群名(默认为“elasticsearch”)。该集群名非常重要,因为节点可以通过这个集群名加入群集,一个节点只能是群集的一部分。
确保在不同的环境中不要使用相同的群集名称,否则可能会导致连接错误的群集节点。例如,你可以使用logging-dev、logging-stage、logging-prod分别为开发、阶段产品、生产集群做记录。
Node节点
节点是单个服务器实例,它是群集的一部分,可以存储数据,并参与群集的索引和搜索功能。就像一个集群,节点的名称默认为一个随机的通用唯一标识符(UUID),确定在启动时分配给该节点。如果不希望默认,可以定义任何节点名。这个名字对管理很重要,目的是要确定你的网络服务器对应于你的ElasticSearch群集节点。
我们可以通过群集名配置节点以连接特定的群集。默认情况下,每个节点设置加入名为“elasticSearch”的集群。这意味着如果你启动多个节点在网络上,假设他们能发现彼此都会自动形成和加入一个名为“elasticsearch”的集群。
在单个群集中,你可以拥有尽可能多的节点。此外,如果“elasticsearch”在同一个网络中,没有其他节点正在运行,从单个节点的默认情况下会形成一个新的单节点名为”elasticsearch”的集群。
Index索引
索引是具有相似特性的文档集合。例如,可以为客户数据提供索引,为产品目录建立另一个索引,以及为订单数据建立另一个索引。索引由名称(必须全部为小写)标识,该名称用于在对其中的文档执行索引、搜索、更新和删除操作时引用索引。在单个群集中,你可以定义尽可能多的索引。
Type类型
在索引中,可以定义一个或多个类型。类型是索引的逻辑类别/分区,其语义完全取决于你。一般来说,类型定义为具有公共字段集的文档。例如,假设你运行一个博客平台,并将所有数据存储在一个索引中。在这个索引中,你可以为用户数据定义一种类型,为博客数据定义另一种类型,以及为注释数据定义另一类型。
Document文档
文档是可以被索引的信息的基本单位。例如,你可以为单个客户提供一个文档,单个产品提供另一个文档,以及单个订单提供另一个文档。本文件的表示形式为JSON(JavaScript Object Notation)格式,这是一种非常普遍的互联网数据交换格式。
在索引/类型中,你可以存储尽可能多的文档。请注意,尽管文档物理驻留在索引中,文档实际上必须索引或分配到索引中的类型。
Shards & Replicas分片与副本
索引可以存储大量的数据,这些数据可能超过单个节点的硬件限制。例如,十亿个文件占用磁盘空间1TB的单指标可能不适合对单个节点的磁盘或可能太慢服务仅从单个节点的搜索请求。
为了解决这一问题,Elasticsearch提供细分你的指标分成多个块称为分片的能力。当你创建一个索引,你可以简单地定义你想要的分片数量。每个分片本身是一个全功能的、独立的“指数”,可以托管在集群中的任何节点。
Shards分片的重要性主要体现在以下两个特征:**
分片允许你水平拆分或缩放内容的大小
分片允许你分配和并行操作的碎片(可能在多个节点上)从而提高性能/吞吐量 这个机制中的碎片是分布式的以及其文件汇总到搜索请求是完全由ElasticSearch管理,对用户来说是透明的。
在同一个集群网络或云环境上,故障是任何时候都会出现的,拥有一个故障转移机制以防分片和节点因为某些原因离线或消失是非常有用的,并且被强烈推荐。为此,Elasticsearch允许你创建一个或多个拷贝,你的索引分片进入所谓的副本或称作复制品的分片,简称Replicas。
Replicas的重要性主要体现在以下两个特征:
副本为分片或节点失败提供了高可用性。为此,需要注意的是,一个副本的分片不会分配在同一个节点作为原始的或主分片,副本是从主分片那里复制过来的。
副本允许用户扩展你的搜索量或吞吐量,因为搜索可以在所有副本上并行执行。
1.4 ES基本概念与关系型数据库的比较
| ES概念 | 关系型数据库 |
|---|---|
| Index(索引)支持全文检索 | Database(数据库) |
| Type(类型) | Table(表) |
| Document(文档),不同文档可以有不同的字段集合 | Row(数据行) |
| Field(字段) | Column(数据列) |
| Mapping(映射) | Schema(模式) |
1.5 ES下载及安装
下载
访问 Elasticsearch 官网下载安装包,下载完成之后,解压到指定目录。
若下载速度慢,可使用国内镜像,华为云:https://mirrors.huaweicloud.com/elasticsearch
安装
终端进入ES的解压目录,输入命令
\bin\elasticsearch.bat

 访问127.0.0.1::9200,若成功返回以上信息,则说明安装成功。
访问127.0.0.1::9200,若成功返回以上信息,则说明安装成功。
1.6 Go操作ES
下载
go get github.com/olivere/elastic/v7 注意版本和es一致
示例
package main
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
)
// Elasticsearch demo
type Student struct {
Name string `json:"name"`
Age int `json:"age"`
Married bool `json:"married"`
}
func main() {
// 1, 初始化连接,得到一个client连接
client, err := elastic.NewClient(elastic.SetURL("http://127.0.0.1:9200"))
if err != nil {
// Handle error
panic(err)
}
fmt.Println("connect to es success")
p1 := Student{Name: "ball", Age: 22, Married: false}
put1, err := client.Index().Index("student").Type("go").BodyJson(p1).Do(context.Background())
if err != nil {
// Handle error
panic(err)
}
fmt.Printf("Indexed user %s to index %s, type %s\n", put1.Id, put1.Index, put1.Type)
}
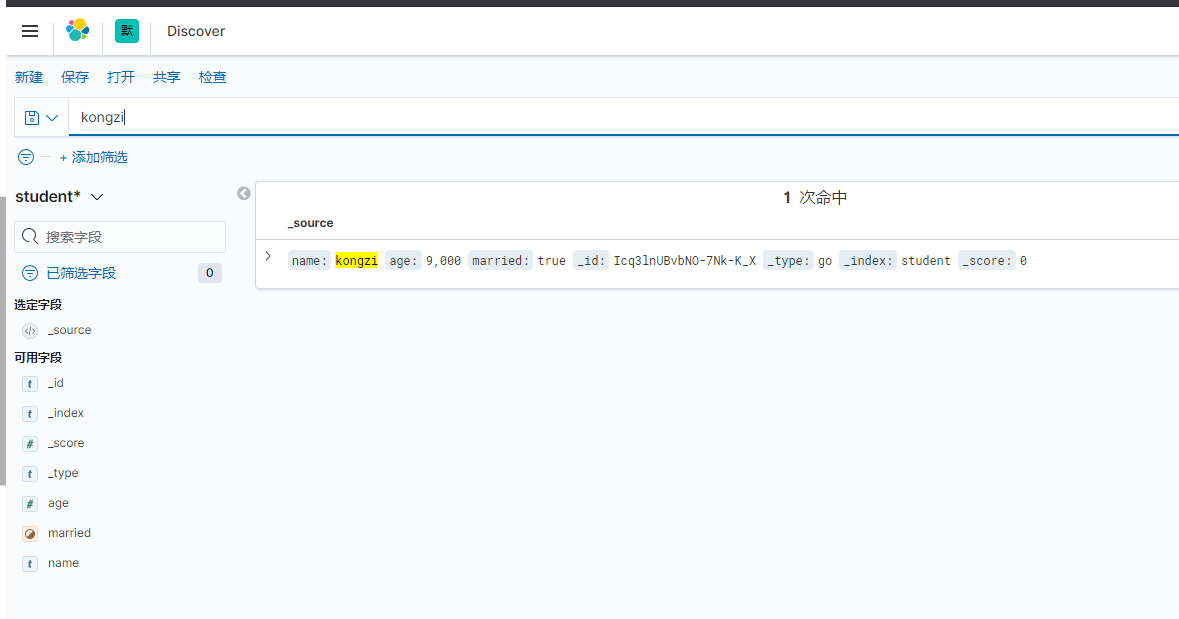
查询结果
get 127.0.0.1:9200/student/go/_search
之前添加了两条数据
post 127.0.0.1:9200/student/go
{
"name": "james",
"age": 36,
"married": true
}
{
"name": "kongzi",
"age": 9000,
"married": true
}
2. Kibana
2.1 简介
Kibana是一个开源分析和可视化平台,旨在与Elasticsearch协同工作。您使用Kibana搜索,查看和与存储在Elasticsearch索引中的数据进行交互。您可以轻松地执行高级数据分析,并在各种图表,表格和地图中可视化您的数据。
Kibana使您可以轻松理解大量数据。其简单的基于浏览器的界面使您能够快速创建和共享动态仪表板,实时显示Elasticsearch查询的更改。
设置Kibana非常容易。您可以安装Kibana并在几分钟内开始探索您的Elasticsearch索引 - 无需代码,无需额外的基础架构。
2.2 下载
版本要求
应将Kibana和Elasticsearch配置为相同版本的,这是官方推荐的配置。
不支持Kibana和Elasticsearch运行在不同主要版本(例如Kibana 5.x和Elasticsearch 2.x),也不支持比Elasticsearch版本更新的Kibana次要版本(例如Kibana 5.1和Elasticsearch 5.0)。
运行高于Kibana的次要版本的Elasticsearch通常可以用于促进首先升级Elasticsearch的升级过程(例如Kibana 5.0和Elasticsearch 5.1)。在此配置中,将在Kibana服务器启动时记录警告,因此在Kibana升级到与Elasticsearch相同的版本之前,它只是暂时的。
通常支持Kibana和Elasticsearch运行在不同补丁版本(例如Kibana 5.0.0和Elasticsearch 5.0.1),但我们鼓励用户将Kibana和Elasticsearch运行在相同的版本和补丁版本。
下载
官网:https://www.elastic.co/cn/downloads/kibana
国内加速:https://mirrors.huaweicloud.com/kibana
下载指定版本的kibana压缩包即可

2.3 运行
修改配置文件
打开
config/kibana.yml文件,可以编辑服务器地址和端口,以及语言模式
# Kibana is served by a back end server. This setting specifies the port to use.
#server.port: 5601
# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.
# The default is 'localhost', which usually means remote machines will not be able to connect.
# To allow connections from remote users, set this parameter to a non-loopback address.
#server.host: "localhost"
...
#i18n.locale: "en"
i18n.locale: "zh-CN"
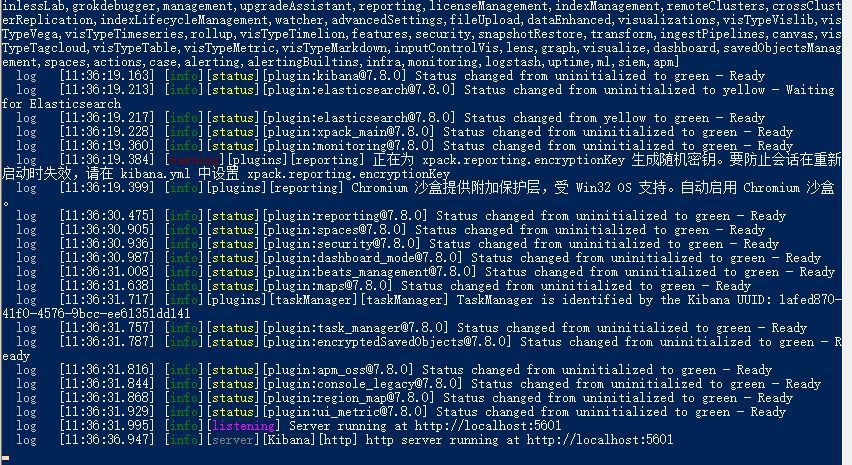
运行,运行之前首先运行elasticsearch
bin\kibana.bat
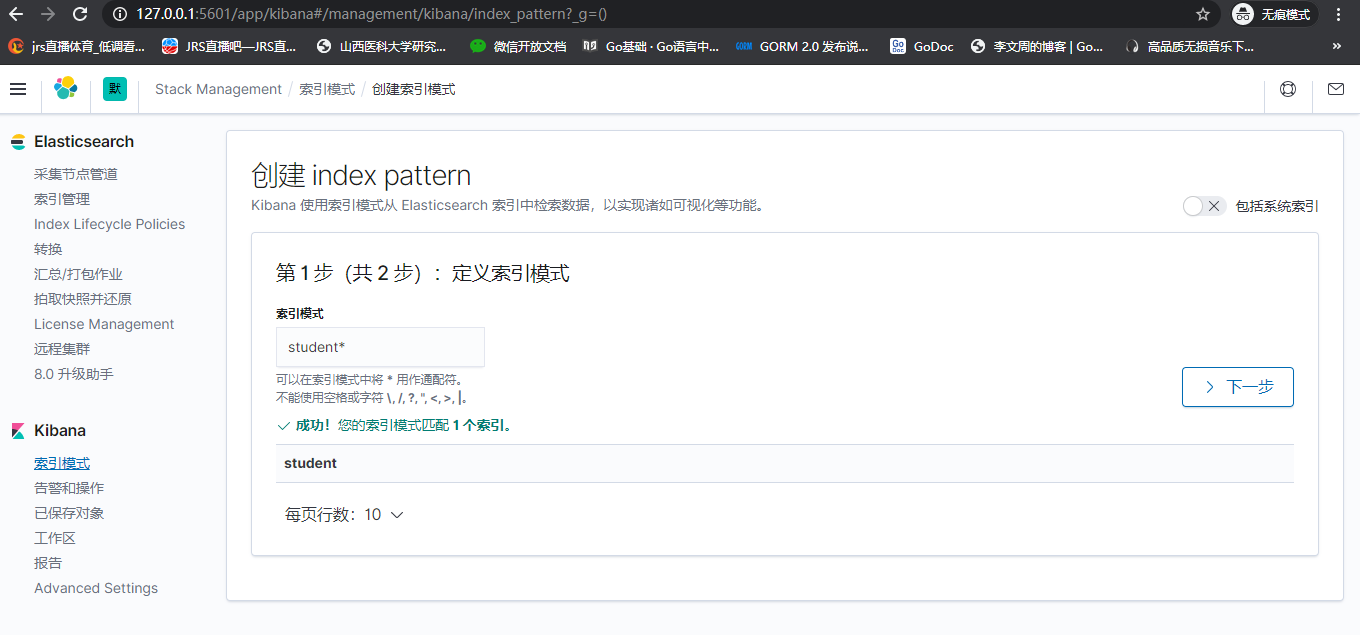

3. LogTransfer实现
3.1 加载配置文件
conf/config.ini[kafka]
address=127.0.0.1:9092
topic=web_log
[es]
address=127.0.0.1:9200
chan_max_size=100000
workers=16
conf/config.gopackage conf
type LogTansfer struct {
Kafka Kafka `ini:"kafka"`
ES ES `ini:"es"`
}
type Kafka struct {
Address string `ini:"address"`
Topic string `ini:"topic"`
}
type ES struct {
Address string `ini:"address"`
ChanMaxSize int `ini:"chan_max_size"`
Workers int `ini:"workers"`
}
加载配置文件
// 0. 加载配置文件
var cfg conf.LogTansfer
err := ini.MapTo(&cfg, "./conf/config.ini")
if err != nil {
fmt.Println("init config, err:%v\n", err)
return
}
fmt.Printf("cfg:%v\n", cfg)注意点:
在一个函数中修改变量一定要传指针
在配置文件对应的额接固体中一定要设置tag(特别是嵌套的结构体)
3.2 初始化ES
实现思路:初始化ES,准备接收从kafka中取出的数据
初始化ES客户端连接
初始化日志channel
开启若干个协程监听channel中数据的变化,将channel中的数据发往ES
代码实现
es/es.gopackage es
import (
"context"
"fmt"
"github.com/olivere/elastic/v7"
"strings"
"time"
)
var (
esClient *elastic.Client
logESChan chan LogData
)
type LogData struct {
Topic string `json:"topic"`
Data string `json:"data"`
}
// 初始化ES,准备接受KAFKA那边发出来的数据
func Init(address string, chan_max_size int, workers int) (err error) {
if !strings.HasPrefix(address, "http://") {
address = "http://" + address
}
esClient, err = elastic.NewClient(elastic.SetURL(address))
if err != nil {
return
}
fmt.Println("connect to es success")
logESChan = make(chan LogData, chan_max_size)
for i := 0; i < workers; i++ {
go SendToES()
}
return
}
func SendToChan(data LogData) {
logChan <- data
}
// 发送数据到ES
func SendToES() {
for {
select {
case msg := <-logESChan:
// 链式操作
put1, err := esClient.Index().Index(msg.Topic).BodyJson(msg).Do(context.Background())
if err != nil {
// Handle error
fmt.Printf("send to es failed, err: %v\n", err)
continue
}
fmt.Printf("Indexed user %s to index %s, type %s\n", put1.Id, put1.Index, put1.Type)
default:
time.Sleep(time.Second)
}
}
}main.gofunc main() {
// 0. 加载配置文件
...
// 1. 初始化ES
// 1.1 初始化一个ES连接的client
err = es.Init(cfg.ES.Address, cfg.ES.ChanMaxSize, cfg.ES.Workers)
if err != nil {
fmt.Printf("init ES client failed,err:%v\n", err)
return
}
fmt.Println("init ES client success.")
...
}
3.3 初始化Kafka
实现思路:初始化
kafka创建kafka消费者连接
初始化kafka客户端,包含kafka消费者连接、addrs和topic
代码实现
kafka/kafka.go package kafka
import (
"fmt"
"github.com/Shopify/sarama"
"logtransfer/es"
"sync"
)
// 初始化kafka连接的一个client
type KafkaClient struct {
client sarama.Consumer
addrs []string
topic string
}
var (
kafkaClient *KafkaClient
)
// init初始化client
func Init(addrs []string, topic string) (err error) {
consumer, err := sarama.NewConsumer(addrs, nil)
if err != nil {
fmt.Printf("fail to start consumer, err:%v\n", err)
return
}
kafkaClient = &KafkaClient{
client: consumer,
addrs: addrs,
topic: topic,
}
return
}
// 将Kafka数据发往ES
func Run(){
...
}
main.gofunc main() {
// 0. 加载配置文件
...
// 1. 初始化ES
// 1.1 初始化一个ES连接的client
...
// 2. 初始化kafka
// 2.1 连接kafka,创建分区的消费者
// 2.2 每个分区的消费者分别取出数据 通过SendToChan()将数据发往管道
// 2.3 初始化时就开起协程去channel中取数据发往ES
err = kafka.Init(strings.Split(cfg.Kafka.Address, ";"), cfg.Kafka.Topic)
if err != nil {
fmt.Printf("init kafka consumer failed,err:%v\n", err)
return
}
fmt.Println("init kafka success.")
...
}
3.4 将Kafka中的数据发往ES
实现思路
kafka客户端中每个分区的消费者分别取出数据
异步通过SendToChan()将数据发往channel
初始化时就开起协程去channel中取数据发往ES
代码实现
kafka/kafka.gofunc Run() {
partitionList, err := kafkaClient.client.Partitions(kafkaClient.topic) // topic取到所有的分区
if err != nil {
fmt.Printf("fail to get list of partition:err%v\n", err)
return
}
fmt.Println("分区: ", partitionList)
for partition := range partitionList { // 遍历所有的分区
// 针对每个分区创建一个对应的分区消费者
pc, err := kafkaClient.client.ConsumePartition(kafkaClient.topic, int32(partition), sarama.OffsetNewest)
if err != nil {
fmt.Printf("failed to start consumer for partition %d,err:%v\n", partition, err)
return
}
defer pc.AsyncClose()
// 异步从每个分区消费信息
go func(sarama.PartitionConsumer) {
for msg := range pc.Messages() {
fmt.Printf("Partition:%d Offset:%d Key:%s Value:%s\n", msg.Partition, msg.Offset, msg.Key, msg.Value)
log_data := es.LogData{
Topic: kafkaClient.topic,
Data: string(msg.Value),
}
es.SendToChan(log_data) // 函数调函数 一个函数的执行时间和另一个函数相关,应该通过channel进行性能优化
}
}(pc)
}
defer kafkaClient.client.Close()
select {}
}main.gofunc main() {
// 0. 加载配置文件
var cfg conf.LogTansfer
err := ini.MapTo(&cfg, "./conf/config.ini")
if err != nil {
fmt.Println("init config, err:%v\n", err)
return
}
fmt.Printf("cfg:%v\n", cfg)
// 1. 初始化ES
// 1.1 初始化一个ES连接的client
err = es.Init(cfg.ES.Address, cfg.ES.ChanMaxSize, cfg.ES.Workers)
if err != nil {
fmt.Printf("init ES client failed,err:%v\n", err)
return
}
fmt.Println("init ES client success.")
// 2. 初始化kafka
// 2.1 连接kafka,创建分区的消费者
// 2.2 每个分区的消费者分别取出数据 通过SendToChan()将数据发往管道
// 2.3 初始化时就开起协程去channel中取数据发往ES
err = kafka.Init(strings.Split(cfg.Kafka.Address, ";"), cfg.Kafka.Topic)
if err != nil {
fmt.Printf("init kafka consumer failed,err:%v\n", err)
return
}
fmt.Println("init kafka success.")
// 3. 从kafka取日志数据并放入channel中
kafka.Run()
}
3.5 项目运行
运行方法
开启
zookeeper开启
kafka开启
etcd开启
elasticsearch开启
kibana运行
logagent运行
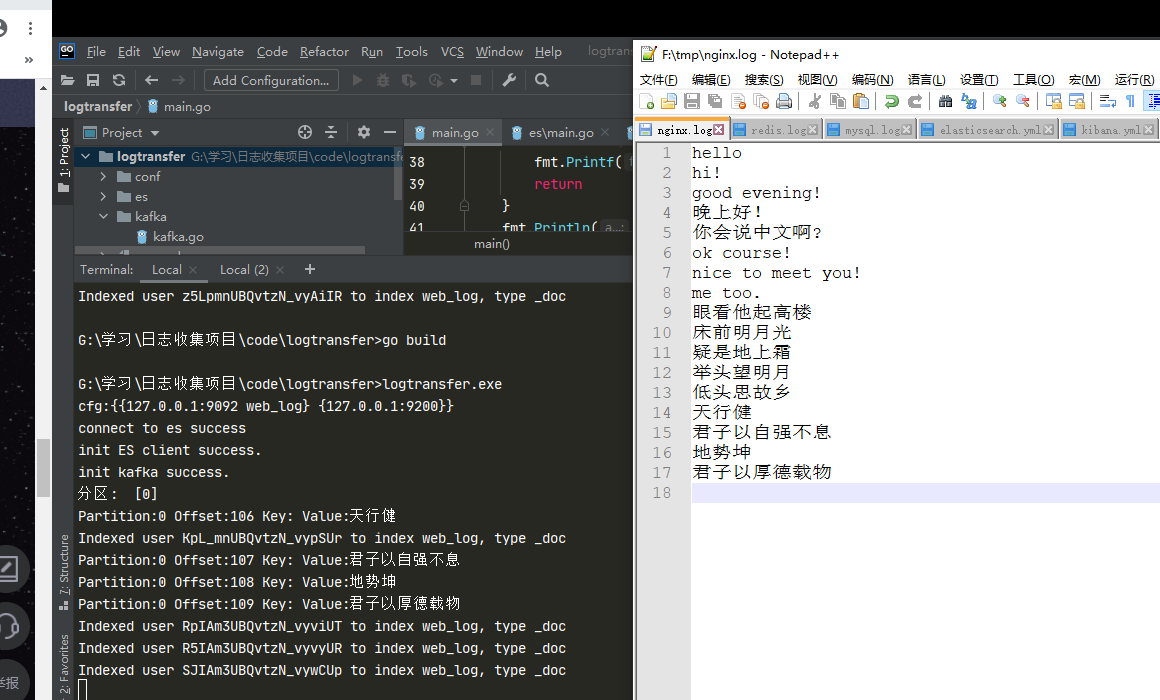
logtransfer往监听的日志文件写入内容,观察
logagent(监听日志内容发往kafka)、logtransfer(将kafka中的内容发往ES)控制台中的输出信息,打开kibana的Web服务网址,查看ES数据是否实时更新
运行效果



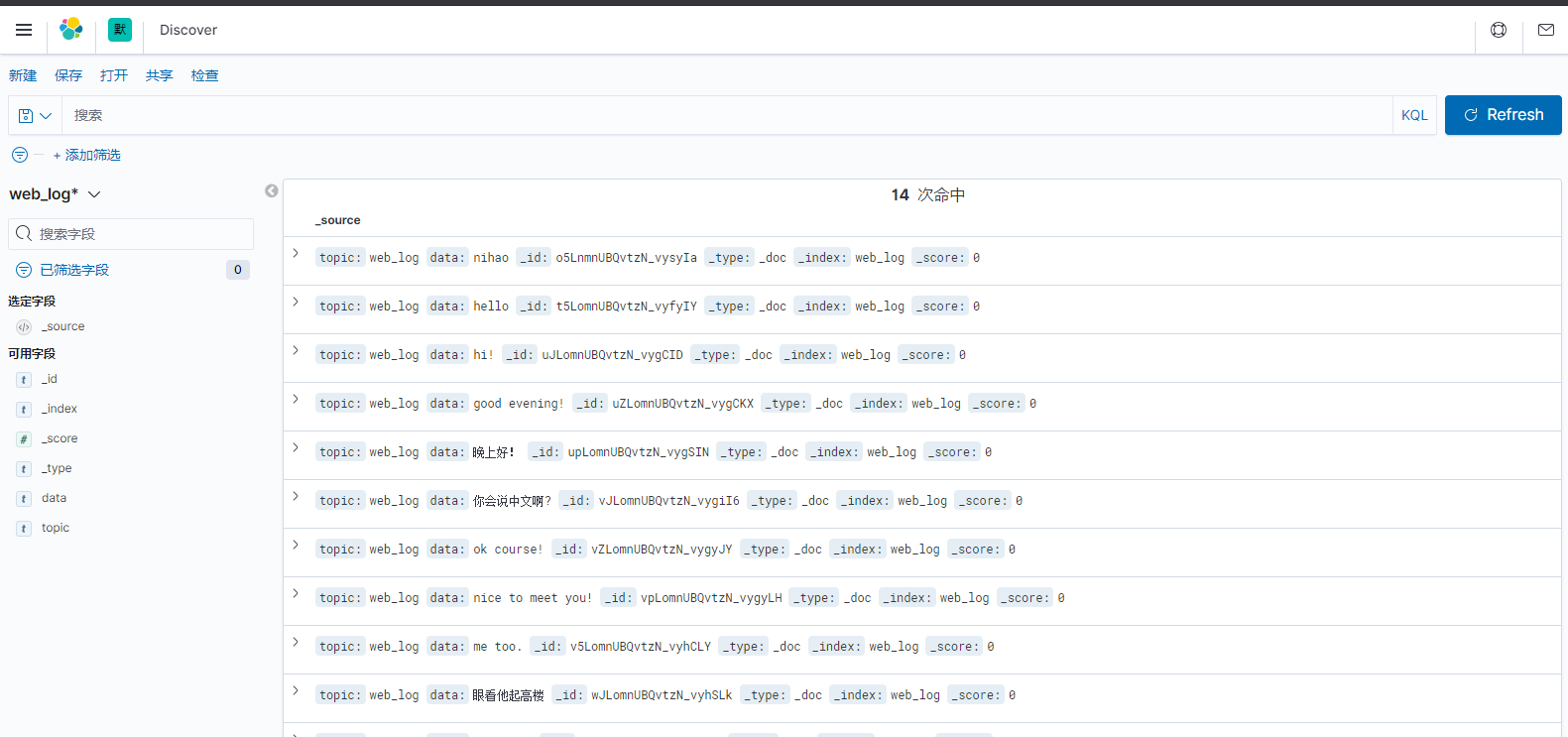
四、系统监控
gopsutil做系统监控信息的采集,写入influxDB,使用grafanna做展示
prometheus监控:采集性能指标数据,保存起来,使用grafana做展示


项目地址:https://gitee.com/zhangyafeii/go-log-collect
日志收集系统系列(五)之LogTransfer的更多相关文章
- 日志收集系统系列(三)之LogAgent
一.什么是LogAhent 类似于在linux下通过tail的方法读日志文件,将读取的内容发给kafka,这里的tailf是可以动态变化的,当配置文件发生变化时,可以通知我们程序自动增加需要增加的配置 ...
- 日志收集系统系列(四)之LogAgent优化
实现功能 logagent根据etcd的配置创建多个tailtask logagent实现watch新配置 logagent实现新增收集任务 logagent删除新配置中没有的那个任务 logagen ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- 快速搭建应用服务日志收集系统(Filebeat + ElasticSearch + kibana)
快速搭建应用服务日志收集系统(Filebeat + ElasticSearch + kibana) 概要说明 需求场景,系统环境是CentOS,多个应用部署在多台服务器上,平时查看应用日志及排查问题十 ...
- 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
作者:大数据女神-诺蓝(微信公号:dashujunvshen).本文是36大数据专稿,转载必须标明来源36大数据. 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要 ...
- GO学习-(35) Go实现日志收集系统4
Go实现日志收集系统4 到这一步,我的收集系统就已经完成很大一部分工作,我们重新看一下我们之前画的图: 我们已经完成前面的部分,剩下是要完成后半部分,将kafka中的数据扔到ElasticSear ...
- ELK+kafka构建日志收集系统
ELK+kafka构建日志收集系统 原文 http://lx.wxqrcode.com/index.php/post/101.html 背景: 最近线上上了ELK,但是只用了一台Redis在 ...
- Flume -- 开源分布式日志收集系统
Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. 一.Flum ...
- 用fabric部署维护kle日志收集系统
最近搞了一个logstash kafka elasticsearch kibana 整合部署的日志收集系统.部署参考lagstash + elasticsearch + kibana 3 + kafk ...
随机推荐
- Spring Cloud Alibaba 整合 Nacos 实现服务配置中心
在之前的文章 <Nacos 本地单机版部署步骤和使用> 中,大家应该了解了 Nacos 是什么?其中 Nacos 提供了动态配置服务功能 一.Nacos 动态配置服务是什么? 官方是这么说 ...
- docker容器使用loki收集日志
docker-compose安装loki套件(loki+promtail+grafana) loki进行日志聚合处理 类似elk中的es promtail是日志收集,类似elk中的logstash ...
- 🔥🔥🔥Flutter 字节跳动穿山甲广告插件发布 - FlutterAds
前言 Flutter 已成为目前最流行的跨平台框架之一,在近期的几个大版本的发布中都提到了 Flutter 版本 Google 广告插件 [google_mobile_ads] .对于"出海 ...
- Redis的一致性哈希算法
一.节点取余 根据redis的键或者ID,再根据节点数量进行取余. key:value如下 name:1 zhangsna:18:北京 对name:1 进行hash操作,得出来得值是242342345 ...
- glViewport()函数和glOrtho()函数的理解
glViewport()函数和glOrtho()函数的理解 OpenGL中有两个比较重要的投影变换函数,glViewport和glOrtho. glOrtho是创建一个正交平行的视景体. 一般 ...
- postgresql很强大,为何在中国,mysql成为主流?
你找一个能安装起来的数据库,都可以学,不管什么版本. 数据库的基本功,是那些基本概念(SQL,表,存储过程,索引,锁,连接配置等等),这些在任何一个版本中都是一样的. 目录 postgresql很强大 ...
- Python语法之基本数据类型
一.数据类型之字符串str 作用:主要用于记录描述性性质的数据,如姓名.地址.邮箱: 定义: 方式1 # 单引号 name = 'jason' 方式2 # 双引号 name = "jason ...
- Oracle 函数高级查询
目录 oracle高级查询 Oracle SQL获取每个分组中日期最新的一条数据 求平均值(为0的参数不均摊) 字符串清除前面的0 判断字符串串是否包含某个字符串 switch 判断 oracle不足 ...
- 新建日历(Project)
<Project2016 企业项目管理实践>张会斌 董方好 编著 默认的标准日历设置好了以后,问题又来了:出现某些特殊的原因,可能还需要一个与标准日历设置不同的日历,这个可怎么弄? 没关系 ...
- Blazor中的无状态组件
声明:本文将RenderFragment称之为组件DOM树或者是组件DOM节点,将*.razor称之为组件. 1. 什么是无状态组件 如果了解React,那就应该清楚,React中存在着一种组件,它只 ...