JAVA自定义连接池原理设计(一)
一,概述
本人认为在开发过程中,需要挑战更高的阶段和更优的代码,虽然在真正开发工作中,代码质量和按时交付项目功能相比总是无足轻重。但是个人认为开发是一条任重而道远的路。现在本人在网上找到一个自定义连接池的代码,分享给大家。无论是线程池还是db连接池,他们都有一个共同的特征:资源复用,在普通的场景中,我们使用一个连接,它的生命周期可能是这样的:
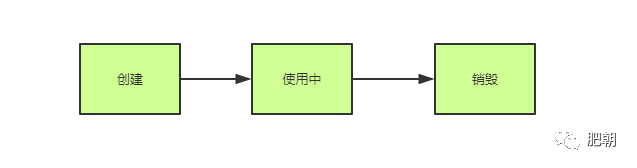
一个连接,从创建完毕到销毁,期间只被使用一次,当周期结束之后,另外的调用者仍然需要这个连接去做事,就要重复去经历这种生命周期。因为创建和销毁都是需要对应服务消耗时间以及系统资源去处理的,这样不仅浪费了大量的系统资源,而且导致业务响应过程中都要花费部分时间去重复的创建和销毁,得不偿失,而连接池便被赋予了解决这种问题的使命!
二,连接池简要需求
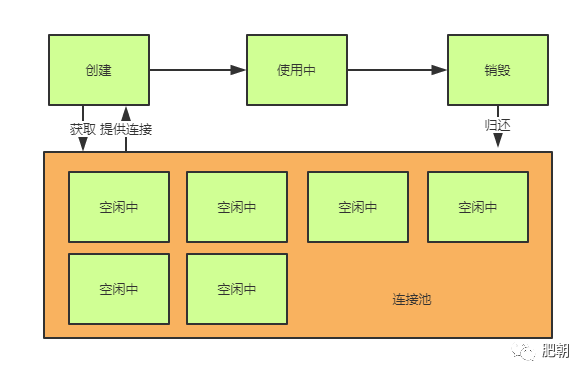
和原始周期相比,连接池多了一下特性:
1,创建并不是真的创建,而是从池子中选出空闲连接。
2,销毁并不是真的销毁,而是将使用中的连接放回池中。
3,真正的创建和销毁由线程池的特性机制来决定。
 ’
’
4,保存连接的容器是必不可少的,另外,该容器也要支持连接的添加和移除功能,并保证线程安全。
5,我们需要因为要对连接的销毁做逻辑调整,我们需要重写它的close以及isClosed方法。
6,我们需要有个入口对连接池做管理,例如回收空闲连接,连接池不仅仅只是对Connection生命周期的控制,还应该加入一些特色,例如初始连接数,最大连接数,最小连接数、最大空闲时长以及获取连接的等待时长,这些我们也简单支持一下。
容器连接池的选型:
1,要保证线程安全,我们可以将目标瞄准在JUC包下的神通们,设我们想要的容器为X,那么X不仅需要满足基本的增删改查功能,而且也要提供获取超时功能,这是为了保证当池内长时间没有空闲连接时不会导致业务阻塞,即刻熔断。另外,x需要满足双向操作,这是为了连接池可以识别出饱和的空闲连接,方便回收操作。
综上所述,LinkedBlockingDeque是最合适的选择,它使用InterruptibleReentrantLock来保证线程安全,使用Condition来做获取元素的阻塞,另外支持双向操作。
另外,我们可以将连接池分为3个类型:
工作池:存在正在被使用的连接。
空闲池:存在空闲连接。
回收池:已经被回收(物理关闭)的连接。
其中,工作池和回收池大可不必用双向队列,或许用单向队列或者set都可以代替之:
private LinkedBlockingQueue<HoneycombConnection> workQueue;
private LinkedBlockingQueue<HoneycombConnection> idleQueue;
private LinkedBlockingQueue<HoneycombConnection> freezeQueue;
Connection 的装饰
连接池的输出是Connection,它代表着一个db连接,上游服务使用它做完操作后,会直接调用它的close方法来释放连接,而我们必须做的是在调用者无感知的情况下改变它的关闭逻辑,当调用close的方法时,我们将它放回空闲队列中,保证其的可复用性!
因此,我们需要对原来的Connection做装饰,其做法很简单,但是很累,这里新建一个类来实现Connection接口,通过重写所有的方法来实现一个“可编辑”的Connection,我们称之为Connection的装饰者:
public class HoneycombConnectionDecorator implements Connection{
protected Connection connection;
protected HoneycombConnectionDecorator(Connection connection) {
this.connection = connection;
}
此处省略对方法实现的三百行代码...
}
之后,我们需要新建一个自己的Connection来继承这个装饰者,并重写相应的方法:
public class HoneycombConnection extends HoneycombConnectionDecorator implements HoneycombConnectionSwitcher{
@Override
public void close() { do some things }
@Override
public boolean isClosed() throws SQLException { do some things }
省略...
}
DataSource的重写
DataSource是JDK为了更好的统合和管理数据源而定义出的一个规范,获取连接的入口,方便我们在这一层更好的扩展数据源(例如增加特殊属性),使我们的连接池的功能更加丰富,我们需要实现一个自己的DataSource:
public class HoneycombWrapperDatasource implements DataSource{
protected HoneycombDatasourceConfig config;
省略其它方法的实现...
@Override
public Connection getConnection() throws SQLException {
return DriverManager.getConnection(config.getUrl(), config.getUser(), config.getPassword());
}
@Override
public Connection getConnection(String username, String password) throws SQLException {
return DriverManager.getConnection(config.getUrl(), username, password);
}
省略其它方法的实现...
}
我们完成了对数据源的实现,但是这里获取连接的方式是物理创建,我们需要满足池化的目的,需要重写HoneycombWrapperDatasource中的连接获取逻辑,做法是创建一个新的类对父类方法重写:
public class HoneycombDataSource extends HoneycombWrapperDatasource{
private HoneycombConnectionPool pool;
@Override
public Connection getConnection() throws SQLException {
这里实现从pool中取出连接的逻辑
}
省略...
}
特性扩展
在当前结构体系下,我们的连接池逐渐浮现出了雏形,但远远不够的是,我们需要在此结构下可以做自由的扩展,使连接池对连接的控制更加灵活,因此我们可以引入特性这个概念,它允许我们在其内部访问连接池,并对连接池做一系列的扩展操作:
public abstract class AbstractFeature{
public abstract void doing(HoneycombConnectionPool pool);
}
AbstractFeature抽象父类需要实现doing方法,我们可以在方法内部实现对连接池的控制,其中一个典型的例子就是对池中空闲连接左回收:
public class CleanerFeature extends AbstractFeature{
@Override
public void doing(HoneycombConnectionPool pool) {
这里做空闲连接的回收
}
}
三,落实计划
JAVA自定义连接池原理设计(一)的更多相关文章
- java自定义连接池
1.java自定义连接池 1.1连接池的概念: 实际开发中"获取连接"或“释放资源”是非常消耗系统资源的两个过程,为了姐姐此类性能问题,通常情况我们采用连接池技术来贡献连接Conn ...
- JDBC连接池原理、自定义连接池代码实现
首先自己实现一个简单的连接池: 数据准备: CREATE DATABASE mybase; USE mybase; CREATE TABLE users( uid INT PRIMARY KEY AU ...
- JDBC连接池-自定义连接池
JDBC连接池 java JDBC连接中用到Connection 在每次对数据进行增删查改 都要 开启 .关闭 ,在实例开发项目中 ,浪费了很大的资源 ,以下是之前连接JDBC的案例 pack ...
- JDBC自定义连接池
开发中,"获得连接"和"释放资源"是非常消耗系统资源的,为了解决此类性能问题可以采用连接池技术来共享连接Connection. 1.概述 用池来管理Connec ...
- MySQL学习(六)——自定义连接池
1.连接池概念 用池来管理Connection,这样可以重复使用Connection.有了池,我们就不用自己来创建Connection,而是通过池来获取Connection对象.当使用完Connect ...
- SpringBoot 整合mongoDB并自定义连接池
SpringBoot 整合mongoDB并自定义连接池 得力于SpringBoot的特性,整合mongoDB是很容易的,我们整合mongoDB的目的就是想用它给我们提供的mongoTemplate,它 ...
- 自定义连接池DataSourse
自定义连接池DataSourse 连接池概述: 管理数据库的连接, 作用: 提高项目的性能.就是在连接池初始化的时候存入一定数量的连接,用的时候通过方法获取,不用的时候归还连接即可.所有的连接池必须实 ...
- Java Mysql连接池配置和案例分析--超时异常和处理
前言: 最近在开发服务的时候, 发现服务只要一段时间不用, 下次首次访问总是失败. 该问题影响虽不大, 但终究影响用户体验. 观察日志后发现, mysql连接因长时间空闲而被关闭, 使用时没有死链检测 ...
- Java 自定义线程池
Java 自定义线程池 https://www.cnblogs.com/yaoxiaowen/p/6576898.html public ThreadPoolExecutor(int corePool ...
随机推荐
- css预处理器和css Modules是干嘛的?
CSS预处理器 1.css和js的区别 js是编程语言,它可以声明变量,编写逻辑.而css实际上只是个"表",表头是选择器,内容是里面的样式.它并不能写逻辑啥的.也就是说,对于cs ...
- Fiddler抓包ios设备
Fiddler绝对称得上是"抓包神器", Fiddler不但能截获各种浏览器发出的HTTP请求, 也可以截获各种智能手机发出的HTTP/HTTPS请求. Fiddler能捕获ISO ...
- JS 双向数据绑定、单项数据绑定
简单的双向数据绑定 <!DOCTYPE html> <html lang="en"> <head> <meta charset=" ...
- [BUUCTF]PWN——pwnable_hacknote
pwnable_hacknote 附件 步骤: 例行检查,32位程序,开启了nx和canary保护 本地试运行看一下大概的情况,熟悉的堆的菜单 32位ida载入 add() gdb看一下堆块的布局更方 ...
- MySQL 分区表,为什么分区键必须是主键的一部分?
随着业务的不断发展,数据库中的数据会越来越多,相应地,单表的数据量也会越到越大,大到一个临界值,单表的查询性能就会下降. 这个临界值,并不能一概而论,它与硬件能力.具体业务有关. 虽然在很多 MySQ ...
- CF1003C Intense Heat 题解
Content 给定一个长度为 \(n\) 的数列,求数列中所有长度 \(\geqslant k\) 的区间的最大平均值. 数据范围:\(1\leqslant k,n,a_i\leqslant 500 ...
- textarea标签换行符以br存入数据库 ,br转 textArea换行符
textArea换行符转 <br/> textarea标签回车符是/n,在html里识别回车是<br/>,在存入数据库之前要进行转换成<br/>,在取出展示在htm ...
- MindSpore联邦学习框架解决行业级难题
内容来源:华为开发者大会2021 HMS Core 6 AI技术论坛,主题演讲<MindSpore联邦学习框架解决隐私合规下的数据孤岛问题>. 演讲嘉宾:华为MindSpore联邦学习工程 ...
- 遍历显示自定义的widget
需求 列表展示: 列表项都是同一格式,列表项数据从List里取 解决方案 使用map map源码 Iterable<T> map<T>(T f(E e)) => Mapp ...
- 聊一下 TS 中的交叉类型
交叉类型不能完全按照传统编程中的 与 来理解. 交叉类型的定义:将多个类型合并为一个类型,包含了所有类型的特性,而且要同时满足要交叉的所有类型. 后半段话不是很好理解,看一下接口类型和联合类型的交叉类 ...