TopN算法,流式数据获取前N条数据
背景:由于业务需求,用户想要统计每周,每月,几个月,一年之中的前N条数据。
根据已有的思路无非就是对全部的数据进行排序,然后取出前N条数据,可是这样的话按照目前最优的排序算法复杂度也在O(nlog(n)),而且如果把所有的数据都放到内存之中排序,数据量太大的话可能不仅仅是慢,还可能因为占用内存过大而导致OOM而产生不可预估的影响。
如果利用分而治之的思想,把所有的数据都存储到磁盘之中,然后数据平均分成M个文件,这样可以利用分批次算出每一个文件之中的前N条数据,然后在合并。但是这样会多次读取磁盘,无形之中增加了多次IO,所以效率也不是很乐观。
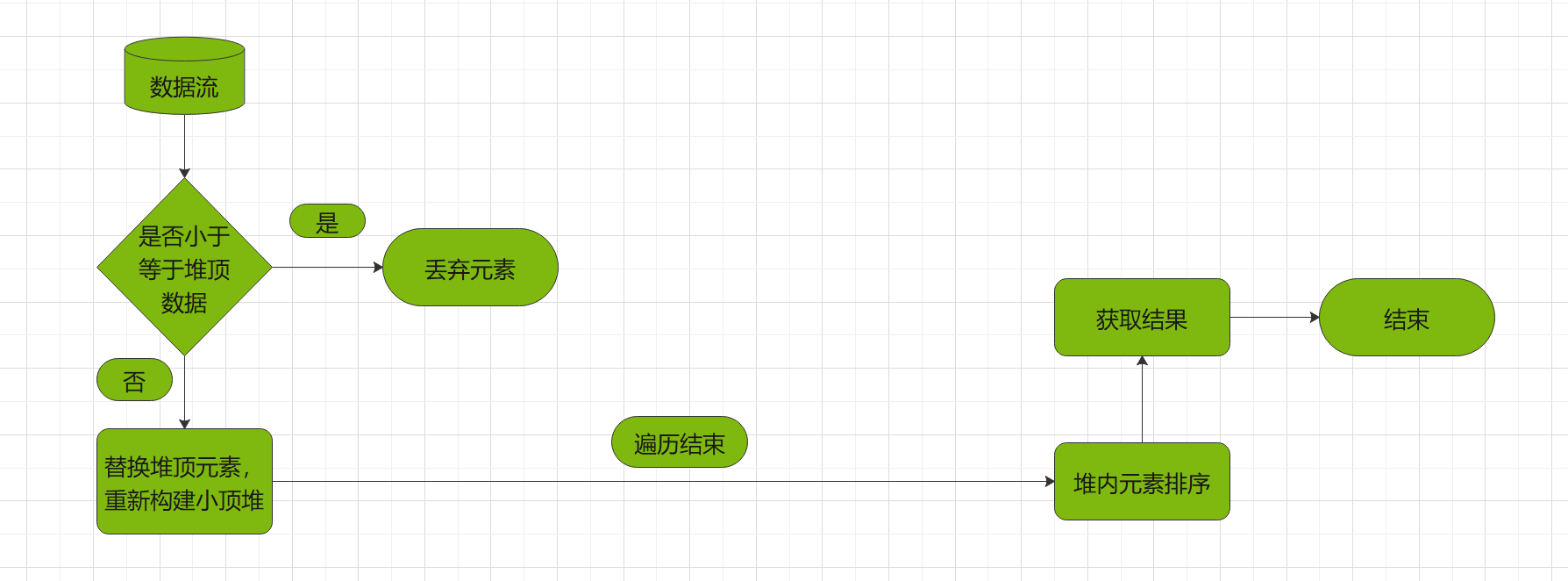
在仔细思考各种排序算法之后,发现我们可以借鉴堆排序算法,采用堆排序,而不采用其他排序算法的原因就是堆排序是分成了两部分。首先构建小/大顶堆,然后在对小/大顶堆进行排序。比如我们可以想要从N条数据中得最大的前Q条数据,那我们就可以构建一个大小为Q的小顶堆,先不对其进行排序,继续读取数据,如果读取的数据小于堆顶数据,直接略过,如果大于对顶数据,则替换堆顶数据,重新构建小/大顶堆。至此,当数据遍历完成,在堆中的所有数据便是最大的前Q条数据,只需对着前十条数据排序即可。这个时间复杂度最大是O(nlog(Q)),最小是O(n)。
如有对堆排序不了解的同学,请自行询问度娘,这里不再解释。
堆排序代码参考:https://baike.baidu.com/item/%E5%A0%86%E6%8E%92%E5%BA%8F/2840151?fr=aladdin
下面是得到对打的前N条数据的流程图:
下面是代码实现:
交换元素代码
/**
* 交换元素
*
* @param arr arr
* @param a 元素的下标
* @param b 元素的下标
* @return void
* @author liekkas
*/
private void swap(int[] arr, int a, int b) {
arr[a] = arr[a] ^ arr[b];
arr[b] = arr[a] ^ arr[b];
arr[a] = arr[a] ^ arr[b];
}
整个堆排序最关键的地方 以当前节点为根节点构建小顶堆
/**
* 整个堆排序最关键的地方 以当前节点为根节点构建小顶堆
*
* @param array 待组堆
* @param i 起始结点
* @param length 堆的长度
* @return void
* @author liekkas
*/
private void adjustMinHeap(int[] array, int i, int length) {
// 先把当前元素取出来,因为当前元素可能要一直移动
int temp = array[i];
for (int k = 2 * i + 1; k < length; k = 2 * k + 1) {
//2*i+1为左子树i的左子树(因为i是从0开始的),2*k+1为k的左子树
// 让k先指向子节点中最小的节点
if (k + 1 < length && array[k] > array[k + 1]) {
//如果有右子树,并且右子树大于左子树
k++;
}
//如果发现结点(左右子结点)大于根结点,则进行值的交换
if (array[k] < temp) {
swap(array, i, k);
// 如果子节点更换了,那么,以子节点为根的子树会受到影响,所以,循环对子节点所在的树继续进行判断
i = k;
} else { //不用交换,直接终止循环
break;
}
}
}
构建小顶堆
/**
* 构建小顶堆
*
* @param array 待构建数组
* @return void
* @author liekkas
*/
private void buildMinHeap(int[] array) { //这里元素的索引是从0开始的,所以最后一个非叶子结点array.length/2 - 1
for (int i = array.length / 2 - 1; i >= 0; i--) {
//调整堆
adjustMinHeap(array, i, array.length);
}
}
堆排序
/**
* 堆排序
*
* @param array 待排序数组
* @return int[] 已排序数组
* @author liekkas
*/ private int[] sort(int[] array) { buildMinHeap(array); // 上述逻辑,建堆结束
// 下面,开始排序逻辑
for (int j = array.length - 1; j > 0; j--) {
// 元素交换,作用是去掉大顶堆
// 把大顶堆的根元素,放到数组的最后;换句话说,就是每一次的堆调整之后,都会有一个元素到达自己的最终位置
swap(array, 0, j);
// 元素交换之后,毫无疑问,最后一个元素无需再考虑排序问题了。
// 接下来我们需要排序的,就是已经去掉了部分元素的堆了,这也是为什么此方法放在循环里的原因
// 而这里,实质上是自上而下,自左向右进行调整的
adjustMinHeap(array, 0, j);
}
return array;
}
测试代码:
public static void main(String[] args) {
HeapSort heapSort = new HeapSort();
int len = 100000000;
int topN = 10;
Random random = new Random();
int[] arr = new int[len];
int[] topArr = new int[topN];
//生成随机数组
for (int i = 0; i < len; i++) {
arr[i] = random.nextInt(1000000000);
}
//初始化数组
System.arraycopy(arr, 0, topArr, 0, topN);
System.out.println("==============>初始化完成");
long start = System.currentTimeMillis();
heapSort.buildMinHeap(topArr);
for (int i = 0; i < len; i++) {
if (arr[i] > topArr[0]) {
topArr[0] = arr[i];
heapSort.buildMinHeap(topArr);
}
}
int[] sort = heapSort.sort(topArr);
long end = System.currentTimeMillis();
for (int i : sort) {
System.out.println(i);
}
System.out.println("time:" + (end - start) + "ms");
}
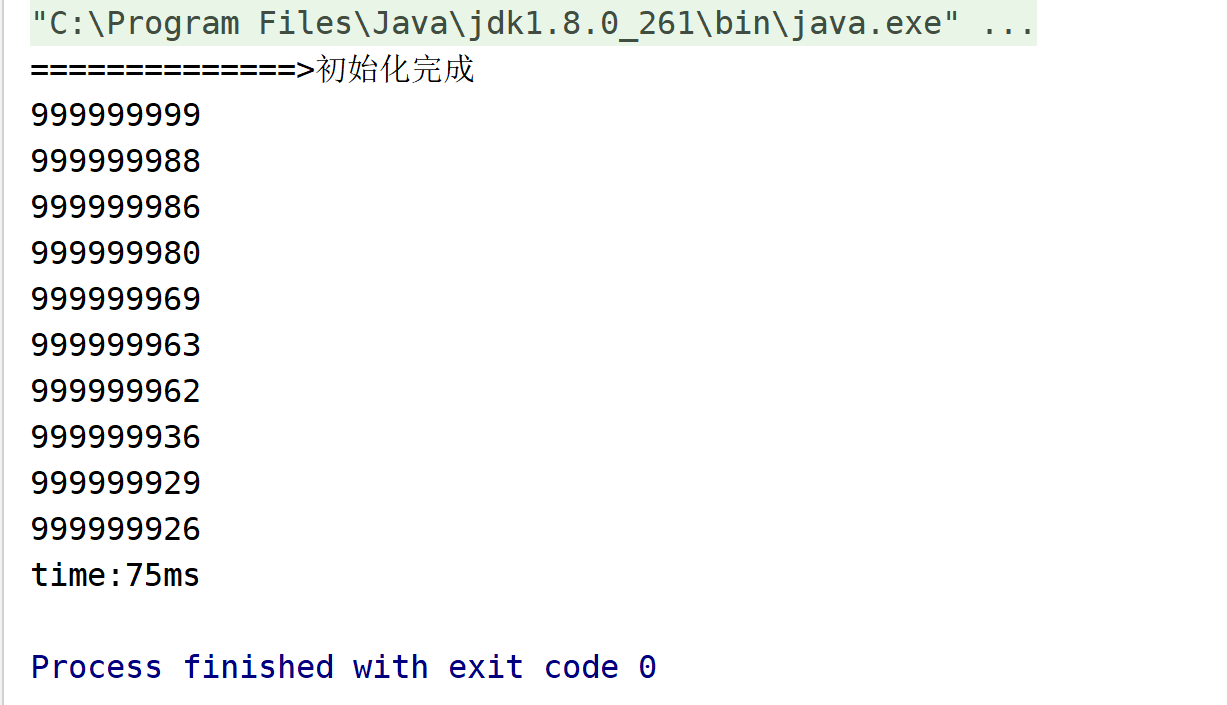
测试结果:
TopN算法,流式数据获取前N条数据的更多相关文章
- 不同数据库,查询前n条数据的SQL语句
不同的数据库,支持的SQL语法略有不同,以下是不同数据库查询前n条数据的SQl语句 SQL Server(MSSQL) SELECT TOP n * FROM table_name ORACLE SE ...
- DataTable相关操作,筛选,取前N条数据,获取指定列数据
DataTable相关操作,筛选,取前N条数据,获取指定列数据2013-03-12 14:50 by Miracle520, 2667 阅读, 0 评论, 收藏, 编辑 1 #region DataT ...
- JAVA List根据字段排序以及取前几条数据
1.经常会遇到对组装的list排序或提取list中前几条数据,例如: 根据时间排序: list.sort((o1, o2) -> o2.getCreateTime().compareTo(o1. ...
- 获取DataTable前几条数据
#region 获取DataTable前几条数据 /// <summary> /// 获取DataTable前几条数据 /// </summary> /// <param ...
- oracle--合并行数据(拼接字符串),获取查询数据的前3条数据...
--标准函数Lpad 可以实现左补零,但是如果多于需要长度,则会截断字符串 SELECT LPAD ('1' , 3 , '0') FROM DUAL -- return 001 情况一:需要补零. ...
- MySQL 分组后取每组前N条数据
与oracle的 rownumber() over(partition by xxx order by xxx )语句类似,即:对表分组后排序 创建测试emp表 1 2 3 4 5 6 7 8 9 ...
- SQL Server 获取满足条件的每个条件下的前N条数据
从数据库获取数据时,经常会遇到获取一个数据列表和该列表中每条数据对应的另一个列表的情况,如果二级列表获取的是全部数据,那么就比较简单.如果二级列表获取的是前n条数据,就会比较麻烦. 从操作上来看,好像 ...
- Oracle数据库实现获取前几条数据的方法
如何在Oracle数据库中实现获取前几条数据的方法呢?就是类似SQL语句中的SELECT TOP N的方法.本文将告诉您答案,举例说明了哟! 1.在Oracle中实现SELECT TOP N : ...
- DataTable相关操作,筛选,取前N条数据,去重复行,获取指定列数据
#region DataTable筛选,排序返回符合条件行组成的新DataTable或直接用DefaultView按条件返回 /// <summary> /// Dat ...
随机推荐
- 【.NET 与树莓派】六轴飞控传感器(MPU 6050)
所谓"飞控",其实是重力加速度计和陀螺仪的组合,因为多用于控制飞行器的平衡(无人机.遥控飞机).有同学会问,这货为什么会有六轴呢?咱们常见的不是X.Y.Z三轴吗?重力加速度有三轴, ...
- Python数模笔记-Sklearn(3)主成分分析
主成分分析(Principal Components Analysis,PCA)是一种数据降维技术,通过正交变换将一组相关性高的变量转换为较少的彼此独立.互不相关的变量,从而减少数据的维数. 1.数据 ...
- Java_接口
接口 接口中的方法全都是抽象方法,用来指定一些规则,让子类去重写.接口的作用主要体现在一下两点 1.指定规则2.利用这些规则给类做功能扩展 接口的定义和使用 接口使用interface关键字来定义,使 ...
- 结对项目:求交点pro
[2020 BUAA 软件工程]结对项目作业 项目 内容 课程:北航2020春软件工程 博客园班级博客 作业:阅读并撰写博客回答问题 结对项目作业 我在这个课程的目标是 积累两人结对编程过程中的经验 ...
- mouseenter mouseleave鼠标悬浮离开事件
- ES系列(五):获取单条数据get处理过程实现
前面讲的都是些比较大的东西,即框架层面的东西.今天咱们来个轻松点的,只讲一个点:如题,get单条记录的es查询实现. 1. get语义说明 get是用于搜索单条es的数据,是根据主键id查询数据方式. ...
- 从零搭建springboot服务02-内嵌持久层框架Mybatis
愿历尽千帆,归来仍是少年 内嵌持久层框架Mybatis 1.所需依赖 <!-- Mysql驱动包 --> <dependency> <groupId>mysql&l ...
- [设计模式] 读懂UML图
类之间关系(由强到弱) realize(继承):三角+实线(指向类),继承类(SUV是一种汽车) generalization(实现):三角+虚线(指向接口),实现接口(汽车是一种车) composi ...
- Ubuntu 15.04下安装Docker
最近听说Docker很火,不知道什么东西,只知道是一个容器,可以跨平台.闲来无事,我也来倒弄倒弄.本文主要介绍:Ubuntu下的安装,以及基本的入门命令介绍:我的机器是Ubuntu 15.04 64位 ...
- VMware vCenter重置web console SSO登录密码
On a Windows Platform Services Controller or vCenter Server with Embedded Platform Services Controll ...