《吃透MQ系列》之扒开Kafka的神秘面纱

大家好,这是《吃透 MQ 系列》的第二弹,有些珊珊来迟,后台被好几个读者催更了,实属抱歉!
这篇文章拖更了好几周,起初的想法是:围绕每一个具体的消息中间件,不仅要写透,而且要控制好篇幅,写下来发现实在太难了,两者很难兼得。
最后决定还是分成多篇写吧。一方面,能加快下输出频率;另一方面,大家也更容易消化。
废话不多说了,第二弹开始发车。
01 为什么从 Kafka 开始?
《吃透 MQ 》的开篇 围绕 MQ 「一发一存一消费」的本质展开,讲解了 MQ 的通用知识,同时系统性地回答了:如何着手设计一个 MQ?
从这篇文章开始,我会讲解具体的消息中间件, 之所以选择从 Kafka 开始,有 3 点考虑:
第一,RocketMQ 和 Kafka 是目前最热门的两种消息中间件,互联网公司应用最为广泛,将作为本系列的重点。
第二,从 MQ 的发展历程来看,Kafka 先于 RocketMQ 诞生,并且阿里团队在实现 RocketMQ 时,充分借鉴了 Kafka 的设计思想。掌握了 Kafka 的设计原理,后面再去理解 RocketMQ 会容易很多。

第三,Kafka 其实是一个轻量级的 MQ,它具备 MQ 最基础的能力,但是在延迟队列、重试机制等高级特性上并未做支持,因此降低了实现复杂度。从 Kafka 入手,有利于大家快速掌握 MQ 最核心的东西。
交代完背景,下面请大家跟着我的思路,一起由浅入深地分析下 Kafka。
02 扒开 Kafka 的面纱
在深入分析一门技术之前,不建议上来就去了解架构以及技术细节,而是先弄清楚它是什么?它是为了解决什么问题而产生的?
掌握这些背景知识后,有利于我们理解它背后的设计考虑以及设计思想。
在写这篇文章时,我查阅了很多资料,关于 Kafka 的定义可以说五花八门,不仔细推敲很容易懵圈,我觉得有必要带大家捋一捋。
我们先看看 Kafka 官网给自己下的定义:
Apache Kafka is an open-source distributed event streaming platform.
翻译成中文就是:Apache Kafka 是一个开源的分布式流处理平台。
Kafka 不是一个消息系统吗?为什么被称为分布式的流处理平台呢?这两者是一回事吗?
一定有读者会有这样的疑问,要解释这个问题,需要先从 Kafka 的诞生背景说起。
Kafka 最开始其实是 Linkedin 内部孵化的项目,在设计之初是被当做「数据管道」,用于处理以下两种场景:
1、运营活动场景:记录用户的浏览、搜索、点击、活跃度等行为。
2、系统运维场景:监控服务器的 CPU、内存、请求耗时等性能指标。
可以看到这两种数据都属于日志范畴,特点是:数据实时生产,而且数据量很大。
Linkedin 最初也尝试过用 ActiveMQ 来解决数据传输问题,但是性能无法满足要求,然后才决定自研 Kafka。
所以从一开始,Kafka 就是为实时日志流而生的。了解了这个背景,就不难理解 Kafka 与流数据的关系了,以及 Kafka 为什么在大数据领域有如此广泛的应用?也是因为它最初就是为解决大数据的管道问题而诞生的。
接着再解释下:为什么 Kafka 被官方定义成流处理平台呢?它不就提供了一个数据通道能力吗,怎么还和平台扯上关系了?
这是因为 Kafka 从 0.8 版本开始,就已经在提供一些和数据处理有关的组件了,比如:
1、Kafka Streams:一个轻量化的流计算库,性质类似于 Spark、Flink。
2、Kafka Connect:一个数据同步工具,能将 Kafka 中的数据导入到关系数据库、Hadoop、搜索引擎中。
可见 Kafka 的野心不仅仅是一个消息系统,它早就在往「实时流处理平台」方向发展了。
这时候,再回来看 Kafka 的官网介绍提到的 3 种能力,也不难理解了:
1、数据的发布和订阅能力(消息队列)
2、数据的分布式存储能力(存储系统)
3、数据的实时处理能力(流处理引擎)
这样,kafka 的发展历史和定义基本缕清了。当然,这个系列仅仅关注 Kafka 的前两种能力,因为这两种能力都和 MQ 强相关。
03 从 Kafka的消息模型说起
理解了 Kafka 的定位以及它的诞生背景,接着我们分析下 Kafka 的设计思想。
上篇文章中我提到过:要吃透一个MQ,建议从 「消息模型」 这种最核心的理论层面入手,而不是一上来就去看技术架构,更不要直接进入技术细节。
所谓消息模型,可以理解成一种逻辑结构,它是技术架构再往上的一层抽象,往往隐含了最核心的设计思想。
下面我们尝试分析下 Kafka 的消息模型,看看它究竟是如何演化来的?
首先,为了将一份消息数据分发给多个消费者,并且每个消费者都能收到全量的消息,很自然的想到了广播。

紧接着问题出现了:来一条消息,就广播给所有消费者,但并非每个消费者都想要全部的消息,比如消费者 A 只想要消息1、2、3,消费者 B 只想要消息4、5、6,这时候该怎么办呢?

这个问题的关键点在于:MQ 不理解消息的语义,它根本无法做到对消息进行分类投递。
此时,MQ 想到了一个很聪明的办法:它将难题直接抛给了生产者,要求生产者在发送消息时,对消息进行逻辑上的分类,因此就演进出了我们熟知的 Topic 以及发布-订阅模型。
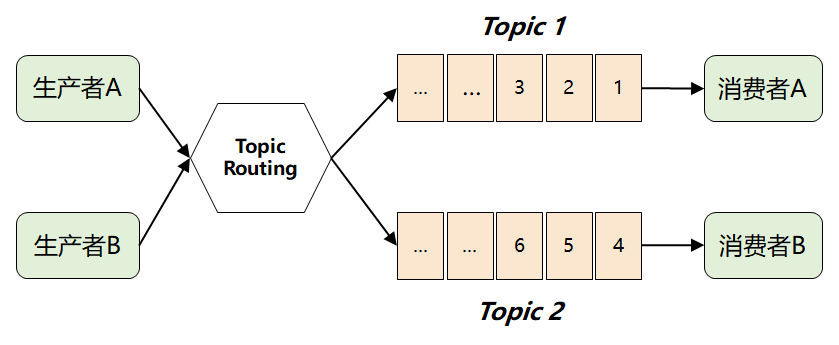
这样,消费者只需要订阅自己感兴趣的 Topic,然后从 Topic 中获取消息即可。
但是这样做了之后,仍然存在一个问题:假如 多个消费者都对同一个 Topic 感兴趣(如下图中的消费者 C),那又该如何解决呢?
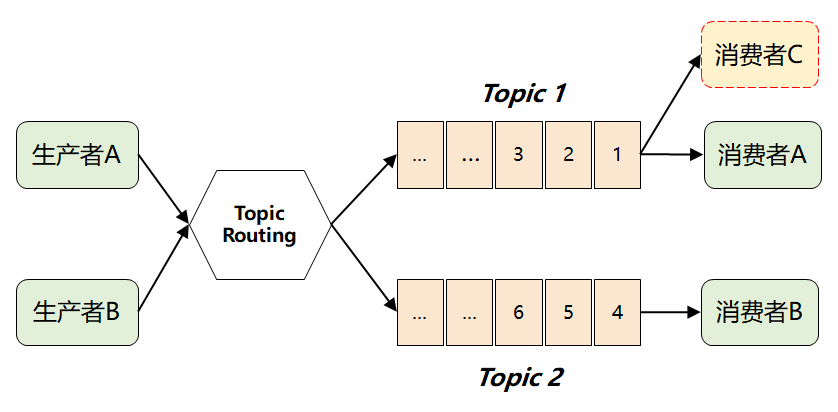
如果采用传统的队列模式(单播),那当一个消费者从队列中取走消息后,这条消息就会被删除,另外一个消费者就拿不到了。
这个时候,很自然又想到下面的解决方案:
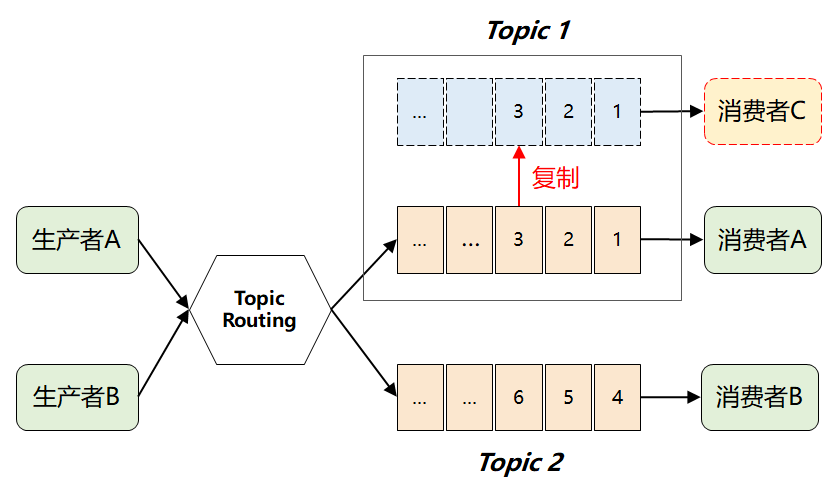
也就是:当 Topic 每增加一个新的消费者,就「复制」一个完全一样的数据队列。
这样问题是解决了,但是随着下游消费者数量变多,将引发 MQ 性能的快速退化。尤其对于 Kafka 来说,它在诞生之初就是处理大数据场景的,这种复制操作显然成本太高了。
这时候,就有了 Kafka 最画龙点睛的一个解法:它将所有消息进行了持久化存储,由消费者自己各取所需,想取哪个消息,想什么时候取都行,只需要传递一个消息的 offset 即可。
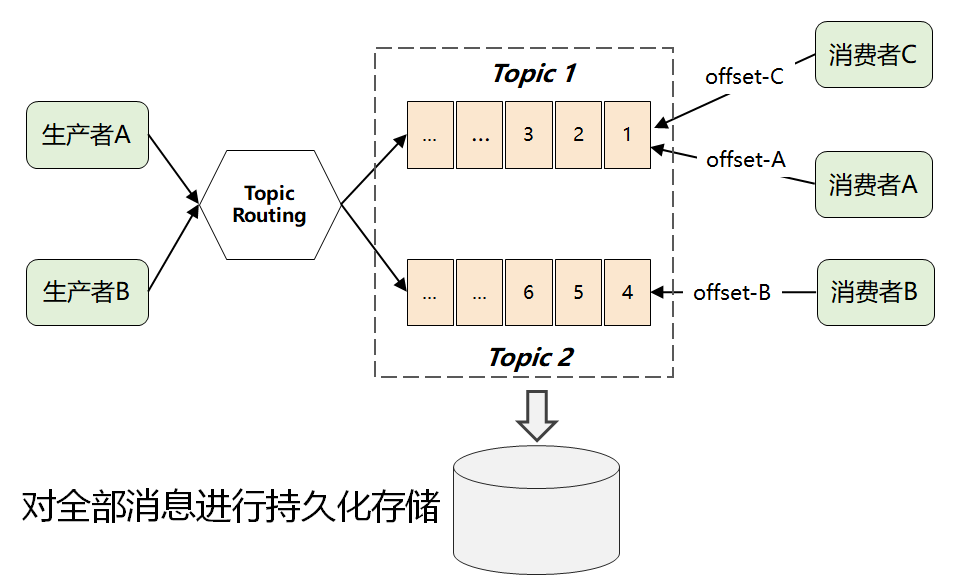
这样一个根本性改变,彻底将复杂的消费问题又转嫁给消费者了,这样使得 Kafka 本身的复杂度大大降低,从而为它的高性能和高扩展打下了良好的基础。(这是 Kafka 不同于 ActiveMQ 和 RabbitMQ 最核心的地方)
最后,简化一下,就是下面这张图:
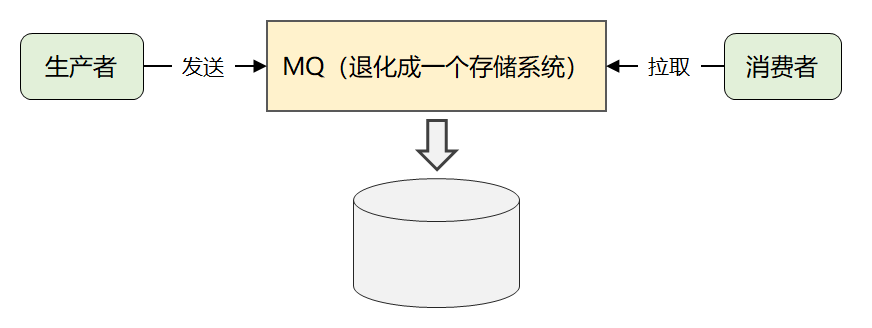
这就是 Kafka 最原始的消息模型。
这也间接解释了第二章节中:为什么官方会将 Kakfa 同时定义成存储系统的原因。
当然 Kafka 的精妙设计远非这些,由于篇幅原因,后面的文章再接着分析。
04 写在最后
这篇文章从 Kafka 的诞生背景讲起,带大家捋清了 Kafka 的定义和它要解决的问题。
另外,一步步分析了 Kafka 的消息模型和设计思想,这是 Kafka 最顶层的抽象。
希望大家有所收获,下篇文章将会深入分析 Kafka 的架构设计,我们下期见!
- End -
作者简介:985硕士,前亚马逊工程师,现58转转技术总监
欢迎扫描下方的二维码,关注我的个人公众号:武哥漫谈IT,精彩原创不断!

《吃透MQ系列》之扒开Kafka的神秘面纱的更多相关文章
- 《吃透MQ系列》核心基础全在这里了
这是<吃透XXX>技术系列的开篇,这个系列的思路是:先找到每个技术栈最本质的东西,然后以此为出发点,逐渐延伸出其他核心知识.所以,整个系列侧重于思考力的训练,不仅仅是讲清楚 What,而是 ...
- 揭开Future的神秘面纱——结果获取
前言 在前面的两篇博文中,已经介绍利用FutureTask任务的执行流程,以及利用其实现的cancel方法取消任务的情况.本篇就来介绍下,线程任务的结果获取. 系列目录 揭开Future的神秘面纱—— ...
- 揭开Future的神秘面纱——任务执行
前言 此文承接之前的博文 解开Future的神秘面纱之取消任务 补充一些任务执行的一些细节,并从全局介绍程序的运行情况. 系列目录 揭开Future的神秘面纱——任务取消 揭开Future的神秘面纱— ...
- 朱晔和你聊Spring系列S1E2:SpringBoot并不神秘
朱晔和你聊Spring系列S1E2:SpringBoot并不神秘 [编辑器丢失了所有代码的高亮,建议查看PDF格式文档] 文本我们会一步一步做一个例子来看看SpringBoot的自动配置是如何实现的, ...
- Kafka系列1:Kafka概况
Kafka系列1:Kafka概况 Kafka是当前分布式系统中最流行的消息中间件之一,凭借着其高吞吐量的设计,在日志收集系统和消息系统的应用场景中深得开发者喜爱.本篇就聊聊Kafka相关的一些知识点. ...
- MQ系列3:RocketMQ 架构分析
MQ系列1:消息中间件执行原理 MQ系列2:消息中间件的技术选型 1 背景 我们前面两篇对主流消息队列的基本构成和技术选型做了详细的分析.从本篇开始,我们会专注当下主流MQ之一的RocketMQ. 从 ...
- MQ系列4:NameServer 原理解析
MQ系列1:消息中间件执行原理 MQ系列2:消息中间件的技术选型 MQ系列3:RocketMQ 架构分析 1 关于NameServer 上一节的 MQ系列3:RocketMQ 架构分析,我们大致介绍了 ...
- IM系统的MQ消息中间件选型:Kafka还是RabbitMQ?
1.前言 在IM这种讲究高并发.高消息吞吐的互联网场景下,MQ消息中间件是个很重要的基础设施,它在IM系统的服务端架构中担当消息中转.消息削峰.消息交换异步化等等角色,当然MQ消息中间件的作用远不止于 ...
- 【SpringBoot MQ 系列】RabbitMq 核心知识点小结
[MQ 系列]RabbitMq 核心知识点小结 以下内容,部分取材于官方教程,部分来源网络博主的分享,如有兴趣了解更多详细的知识点,可以在本文最后的文章列表中获取原地址 RabbitMQ 是一个基于 ...
随机推荐
- 【实用小技巧】spring springmvc集成shiro时报 No bean named 'shiroFilter' available
查了网上的,很多情况,不同的解决办法,总归一点就是配置文件加载的问题. 先看下配置文件中的配置 web.xml中的主要配置(这是修改后不在报错的:仅仅修改了一个位置:[classpath:spring ...
- linux中定时运行php(每分钟执行一次为例)
注:使用Crontab定时执行php脚本文件 1. 安装crontab yum install crontabs 说明:/sbin/service crond start //启动服务/sbin/se ...
- 初步了解web
------------------------1.Web应用程序的main方法在哪里------------------------Tomcat:从启动到运行首先,我们是通过执行 Tomcat 的s ...
- ecl函数的用法
相关函数 fork, execle, execlp, execv, execve, execvp Windows下头文件 #include <process.h> Linux下头文件 #i ...
- 设了padding要减去盒高 和 line-height 行高
增加了padding 一定要减去相应的高度,不然整个元素的高度会增高(原高+padding) line-height:行高 1.行高要比字体大,不然字体会挤到一块去 2.若父盒子没有设置高度,则行高会 ...
- java基础——创建对象与内部分布
类与对象的关系 类是一种抽象的数据类型,它是对某一类事物整体描述和定义,但是不能代表某一个具体的事物 动物.植物.手机.电脑... Person类,Pet类,Car类,这些类都是用来描述和定义某一类具 ...
- Win10屏幕亮度不能调节,调节无效怎么办?
Win10屏幕亮度不能调节,调节无效怎么办? 听语音 浏览:1027 | 更新:2019-11-22 11:43 1 2 3 4 5 6 7 分步阅读 一些用户在使用win10系统之后,出现了电脑屏幕 ...
- Could not open device at /dev/ipmi0
Could not open device at /dev/ipmi0 分类: LINUX 2013-09-02 17:01:37 Could not open device at /dev/ip ...
- shell基础之EOF的用法
一.EOF的用法 EOF是(END Of File)的缩写,表示自定义终止符.既然自定义,那么EOF就不是固定的,可以随意设置别名,在linux按ctrl-d 就代表EOF. EOF一般会配合cat能 ...
- JavaEE 前后端分离以及优缺点
前端概念 前端是一切直接与用户交互的页面或软件(用户看得见.摸得着)的统称,比如各种网站网页.andorid 手机各种 App.苹果手机各种 app.微信小程序.网络游戏客户端等.所以,普通人使用计算 ...