Python爬取笔趣阁小说,有趣又实用
上班想摸鱼?为了摸鱼方便,今天自己写了个爬取笔阁小说的程序。好吧,其实就是找个目的学习python,分享一下。
1. 首先导入相关的模块
import os
import requests
from bs4 import BeautifulSoup
2. 向网站发送请求并获取网站数据
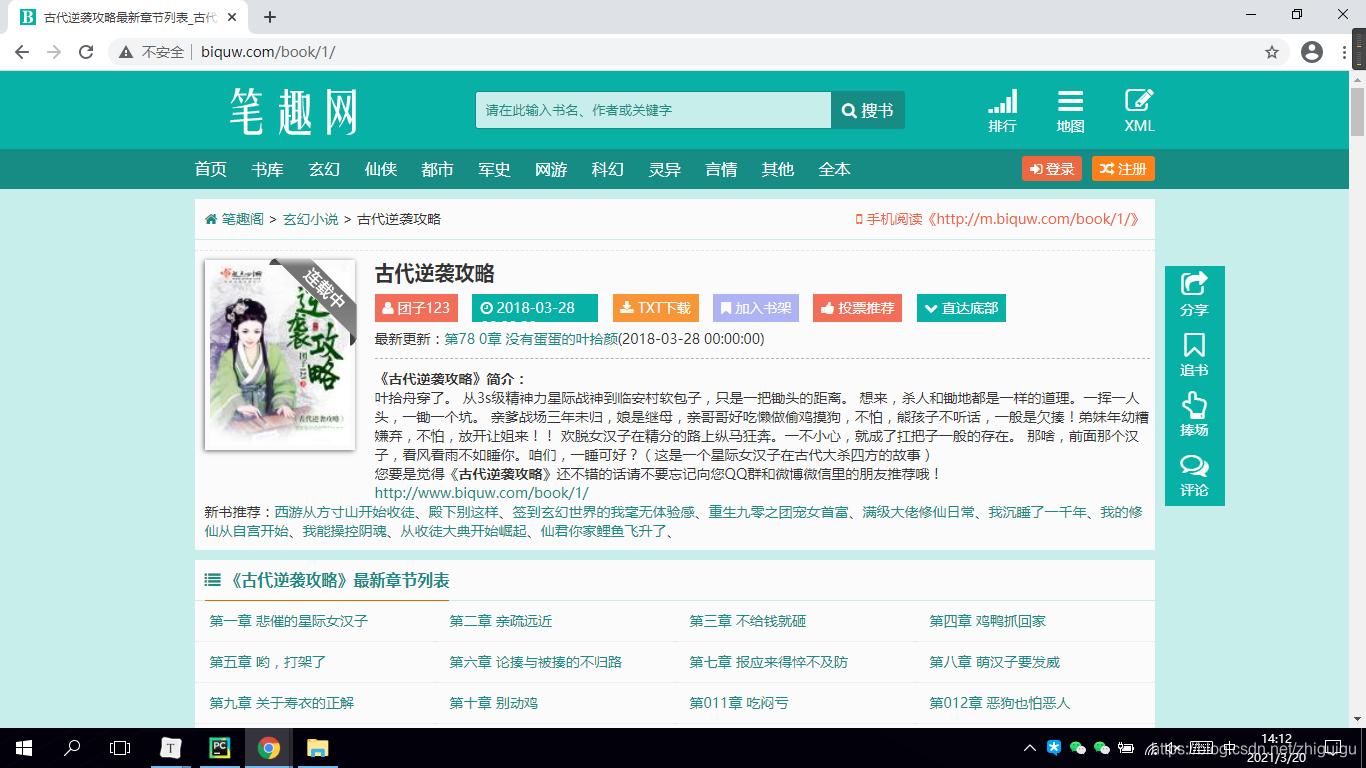
网站链接最后的一位数字为一本书的id值,一个数字对应一本小说,我们以id为1的小说为示例。
进入到网站之后,我们发现有一个章节列表,那么我们首先完成对小说列表名称的抓取
# 声明请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
}
# 创建保存小说文本的文件夹
if not os.path.exists('./小说'):
os.mkdir('./小说/')
# 访问网站并获取页面数据
response = requests.get('http://www.biquw.com/book/1/').text
print(response)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Uu2ddyQB-1618914957232)(.\素材图片\中文显示乱码.png)]
写到这个地方同学们可能会发现了一个问题,当我去正常访问网站的时候为什么返回回来的数据是乱码呢?
这是因为页面html的编码格式与我们python访问并拿到数据的解码格式不一致导致的,python默认的解码方式为utf-8,但是页面编码可能是GBK或者是GB2312等,所以我们需要让python代码很具页面的解码方式自动变化
#### 重新编写访问代码
```python
response = requests.get('http://www.biquw.com/book/1/')
response.encoding = response.apparent_encoding
print(response.text)
'''
这种方式返回的中文数据才是正确的
'''
3. 拿到页面数据之后对数据进行提取
当大家通过正确的解码方式拿到页面数据之后,接下来需要完成静态页面分析了。我们需要从整个网页数据中拿到我们想要的数据(章节列表数据)
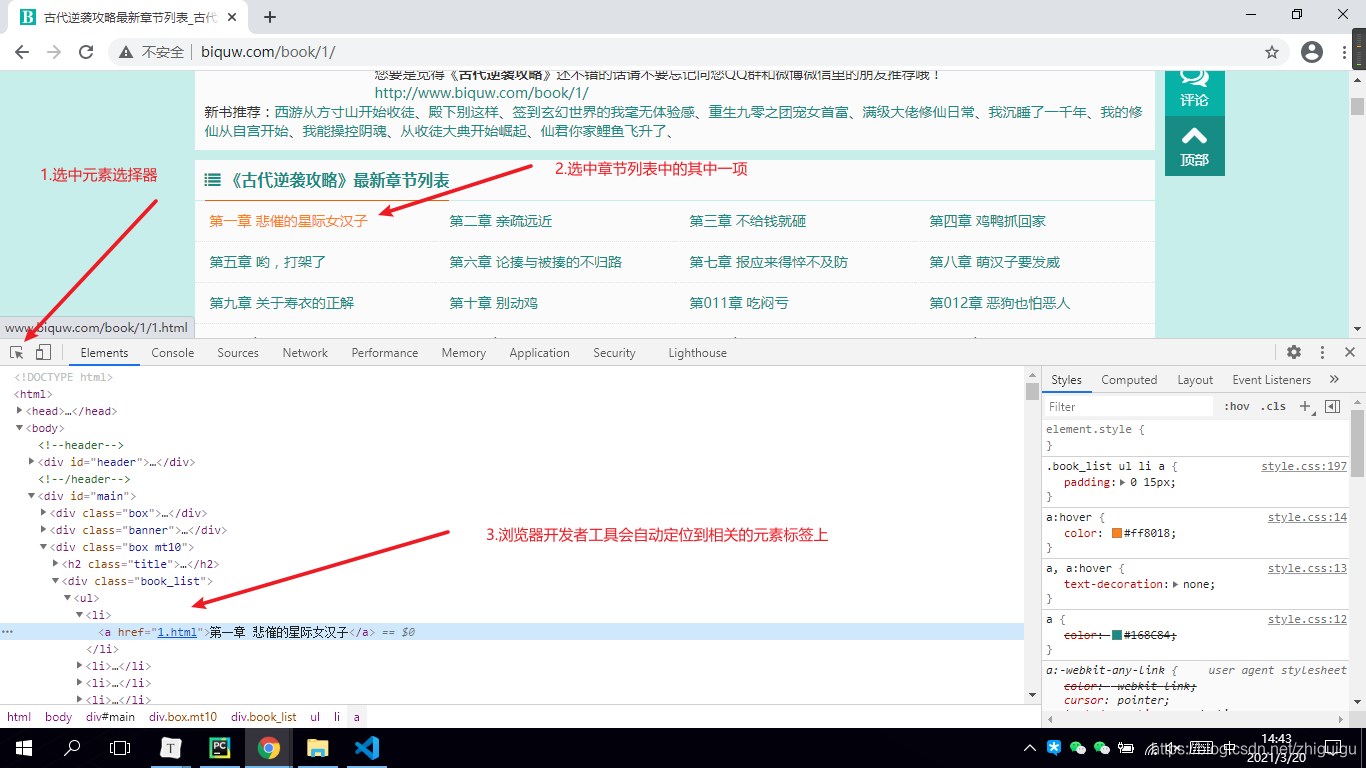
- 首先打开浏览器
- 按F12调出开发者工具
- 选中元素选择器
- 在页面中选中我们想要的数据并定位元素
- 观察数据所存在的元素标签
'''
根据上图所示,数据是保存在a标签当中的。a的父标签为li,li的父标签为ul标签,ul标签之上为div标签。所以如果想要获取整个页面的小说章节数据,那么需要先获取div标签。并且div标签中包含了class属性,我们可以通过class属性获取指定的div标签,详情看代码~
'''
# lxml: html解析库 将html代码转成python对象,python可以对html代码进行控制
soup = BeautifulSoup(response.text, 'lxml')
book_list = soup.find('div', class_='book_list').find_all('a')
# soup对象获取批量数据后返回的是一个列表,我们可以对列表进行迭代提取
for book in book_list:
book_name = book.text
# 获取到列表数据之后,需要获取文章详情页的链接,链接在a标签的href属性中
book_url = book['href']
4. 获取到小说详情页链接之后进行详情页二次访问并获取文章数据
book_info_html = requests.get('http://www.biquw.com/book/1/' + book_url, headers=headers)
book_info_html.encoding = book_info_html.apparent_encoding
soup = BeautifulSoup(book_info_html.text, 'lxml')
5. 对小说详情页进行静态页面分析
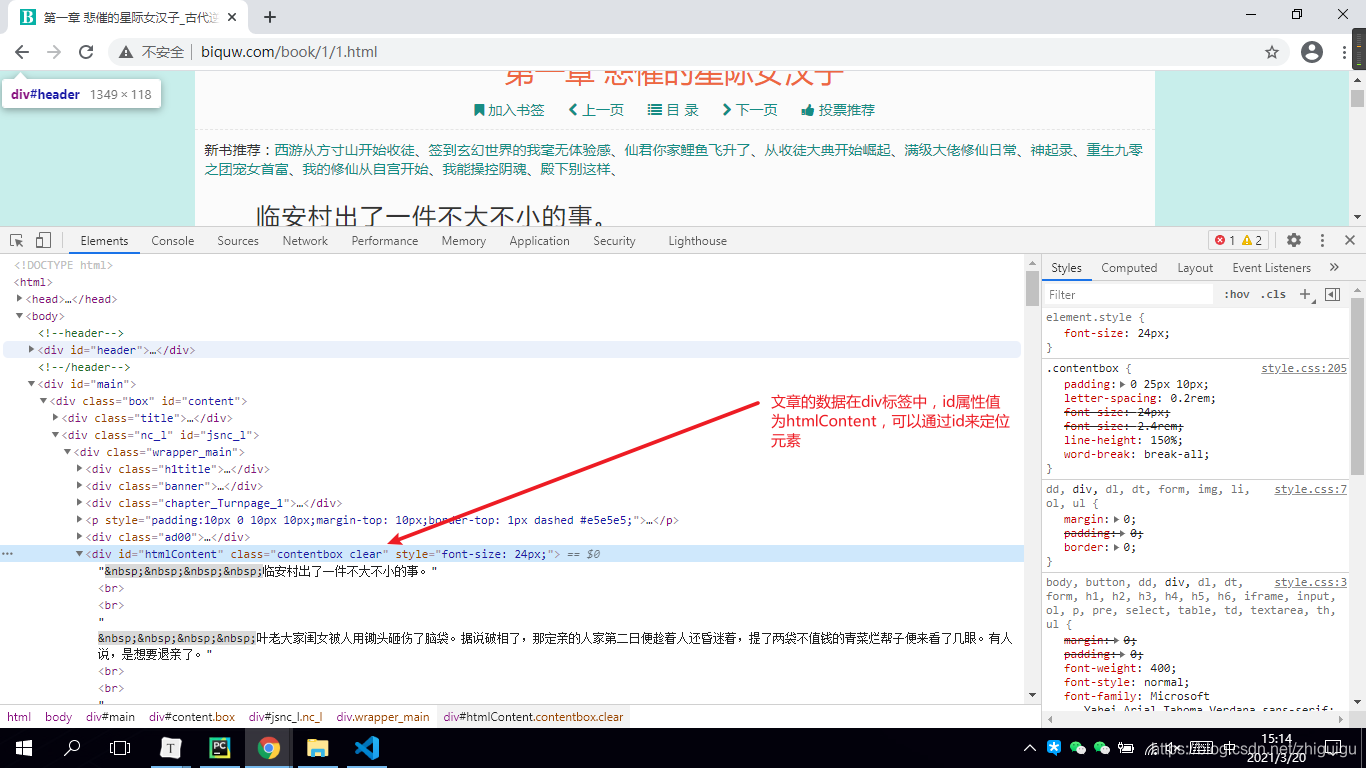
info = soup.find('div', id='htmlContent')
print(info.text)
6. 数据下载
with open('./小说/' + book_name + '.txt', 'a', encoding='utf-8') as f:
f.write(info.text)
最后让我们看一下代码效果吧~
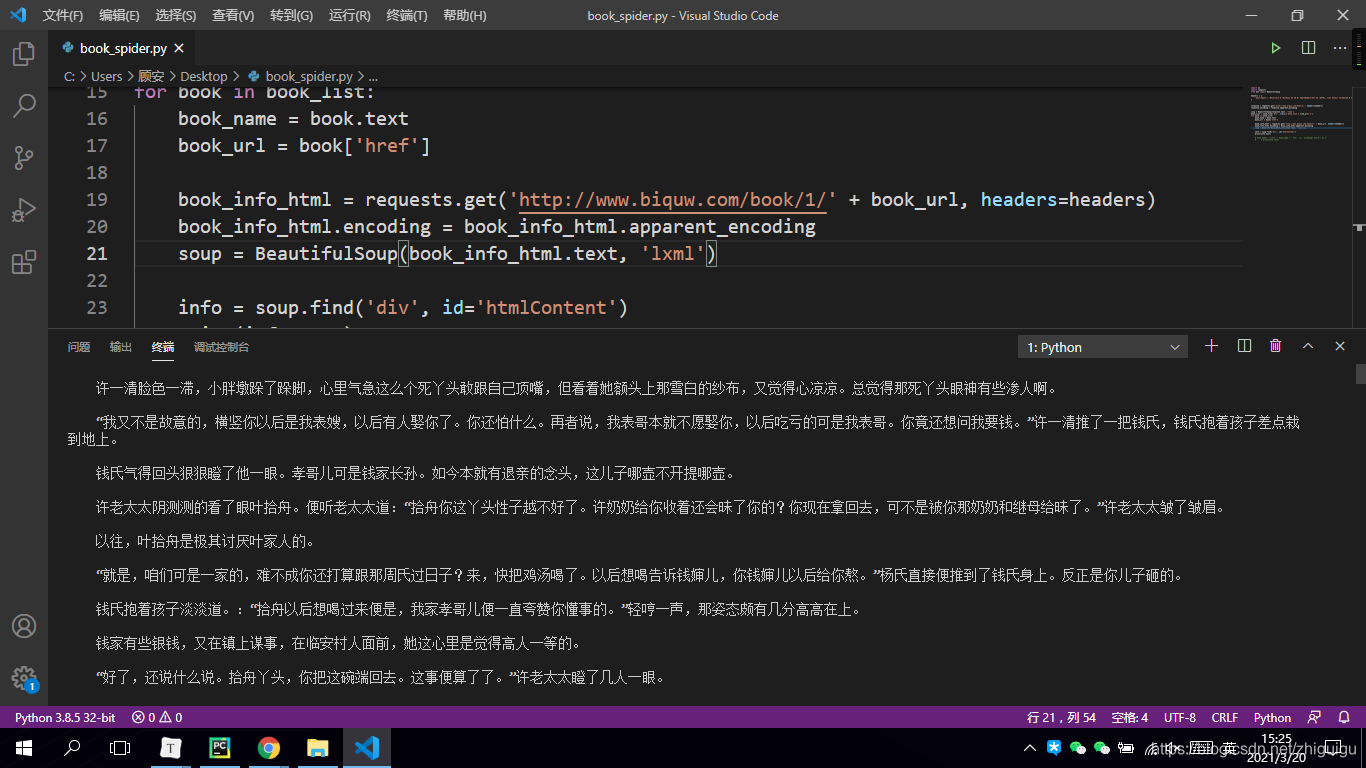
抓取的数据

文章正文到这里已经结束了,只是想感谢一些阅读我文章的人。
我退休后一直在学习如何写文章,说实在的,每次我在后台看到一些读者的回应就会觉得很欣慰,于是我想把我收藏的一些编程干货贡献给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门视频等等(适合小白学习)
*如果你用得到的话可以直接拿走,在我的QQ技术交流群里(广告勿入)可以自助拿走,群号是980758007。*

Python爬取笔趣阁小说,有趣又实用的更多相关文章
- bs4爬取笔趣阁小说
参考链接:https://www.cnblogs.com/wt714/p/11963497.html 模块:requests,bs4,queue,sys,time 步骤:给出URL--> 访问U ...
- Jsoup-基于Java实现网络爬虫-爬取笔趣阁小说
注意!仅供学习交流使用,请勿用在歪门邪道的地方!技术只是工具!关键在于用途! 今天接触了一款有意思的框架,作用是网络爬虫,他可以像操作JS一样对网页内容进行提取 初体验Jsoup <!-- Ma ...
- python应用:爬虫框架Scrapy系统学习第四篇——scrapy爬取笔趣阁小说
使用cmd创建一个scrapy项目: scrapy startproject project_name (project_name 必须以字母开头,只能包含字母.数字以及下划线<undersco ...
- scrapycrawl 爬取笔趣阁小说
前言 第一次发到博客上..不太会排版见谅 最近在看一些爬虫教学的视频,有感而发,大学的时候看盗版小说网站觉得很能赚钱,心想自己也要搞个,正好想爬点小说能不能试试做个网站(网站搭建啥的都不会...) 站 ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
- HttpClients+Jsoup抓取笔趣阁小说,并保存到本地TXT文件
前言 首先先介绍一下Jsoup:(摘自官网) jsoup is a Java library for working with real-world HTML. It provides a very ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
- 爬虫入门实例:利用requests库爬取笔趣小说网
w3cschool上的来练练手,爬取笔趣看小说http://www.biqukan.com/, 爬取<凡人修仙传仙界篇>的所有章节 1.利用requests访问目标网址,使用了get方法 ...
- python入门学习之Python爬取最新笔趣阁小说
Python爬取新笔趣阁小说,并保存到TXT文件中 我写的这篇文章,是利用Python爬取小说编写的程序,这是我学习Python爬虫当中自己独立写的第一个程序,中途也遇到了一些困难,但是最后 ...
随机推荐
- JAVA中枚举Enum详解
1.关键字:enum.枚举可以定义成单独的文件,也可以定义在其他类内部. 枚举在类内部的示例: public class EnumInner { public static void main(Str ...
- 在C++中实现aligned_malloc
malloc的默认行为 大家都知道C++中可以直接调用malloc请求内存被返回分配成功的内存指针,该指针指向的地址就是分配得到的内存的起始地址.比如下面的代码 int main() { void * ...
- NewSQL分布式数据库,例如TIDB用K/V的底层逻辑
内容参考 对分布式对定义参考这篇文章: 微服务都想用,先把分布式和微服务之间的关系说清楚 对分布式架构中心或无中心对比参考这篇文章: 分布式存储单主.多主和无中心架构的特征与趋势 对HDFS对内部机制 ...
- POJ_2828 Buy Tickets 【线段树】
一.题目 Buy Tickets 二.分析 首先可以明确的是每个人的位置都是定的,那么如果从输入数据从后往前看,最后面的人进来的时候,他前面的人数肯定是定的. 那么可以考虑,当从后往前推时,这个人插入 ...
- Aibabelx-shop 大型微服务架构系列实战之技术选型
一.本项目涉及编程语言java,scala,python,涉及的技术如下: 1.微服务架构: springboot springcloud mybatisplus shiro 2.全文检索技术 sol ...
- protobuf基于java和javascript的使用
目录 ProtoBuf介绍 整理下java和JavaScript的例子 demo测试 java作为服务端+客户端测试 客户端前端调用示例 项目地址 参考 ProtoBuf介绍 ProtoBuf 是go ...
- 攻防世界 reverse 进阶 16-zorropub
16.zorropub nullcon-hackim-2016 (linux平台以后整理) https://github.com/ctfs/write-ups-2016/tree/master/nu ...
- Android studio 简易登录界面
•参考资料 [1]:视频资源 [2]:Android TextView设置图标,调整图标大小 •效果展示图 •前置知识 TextView EditText Button 以及按压效果,点击事件 •出现 ...
- 冒泡算法(BubbleSort)
/*冒泡排序原理 比较相邻的元素.如果前一个元素比后一个元素大,就交换这两个元素的位置. 对每一对相邻元素做同样的工作,从开始第一对元素到结尾的最后一对元素.最终最后位置的元素就是最大值.实现步骤 1 ...
- 迷宫问题(BFS)
给定一个n* m大小的迷宫,其中* 代表不可通过的墙壁,而"."代表平地,S表示起点,T代表终点.移动过程中,如果当前位置是(x, y)(下标从0开始),且每次只能前往上下左右.( ...