超详细kafka教程来啦
Kafka的概念和入门
Kafka是一个消息系统。由LinkedIn于2011年设计开发。
Kafka是一种分布式的,基于发布/订阅的消息系统。主要设计目标如下:
- 以时间复杂度O(1)的方式提供消息持久化能力,即使对TB级以上数据页能保证常数时间复杂度的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上的消息传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- 支持在线水平扩展。
消费者是采用pull模式从Broker订阅消息。
| 模式 | 优点 | 缺点 |
|---|---|---|
| pull模式 | 消费者可以根据自己的消费能力决定拉取的策略 | 没有消息的时候会空轮询(kafka为了避免,有个参数可以阻塞直到新消息到达) |
| push模式 | 及时性高 | 消费能力远低于生产能力时,就会导致客户端消息堆积,甚至服务崩溃。服务端需要维护每次传输状态,以防消息传递失败好进行重试。 |
Kafka的基本概念
- Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。
- Partition:Partition是物理上的概念,每个Topic包含一个或多个Partition
- Producer:负责发布消息到Kafka broker
- Consumer:消息消费者,向Kafka broker读取消息的客户端
- Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
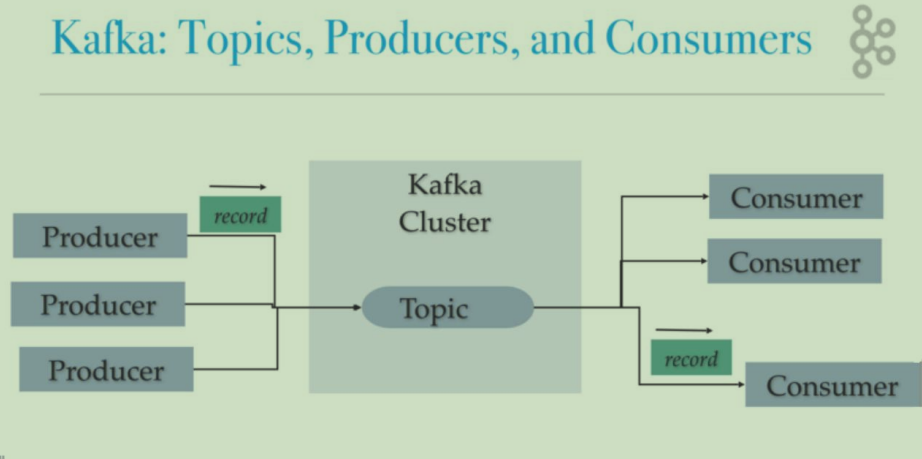
单机部署结构
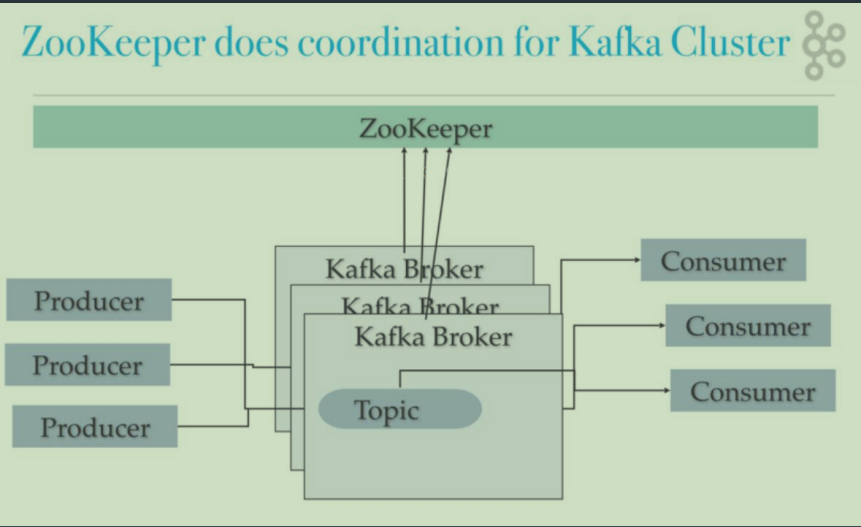
集群部署结构
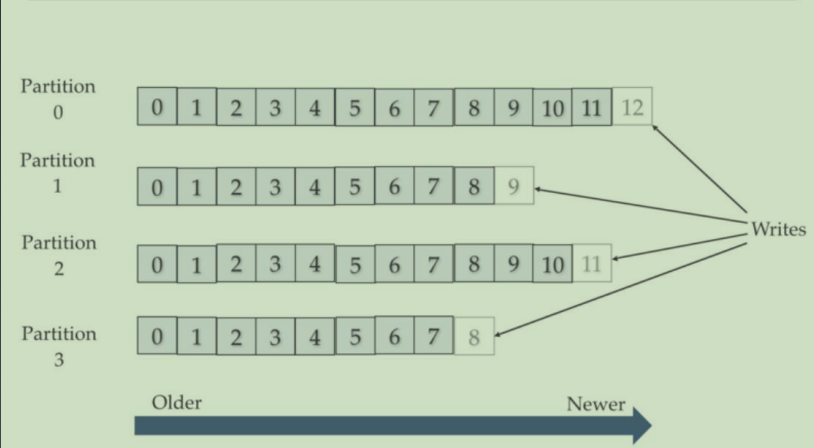
Topic和Partition
一个Topic可以包含一个或者多个Partition。因为一台机器的存储和性能是有限的,多个Partition是为了支持水平扩展和并行处理。
Partition和Replica
分为多个Partition可以将消息压力分到多个机器上,但是如果其中一个partition数据丢了,那总体数据就少了一块。所以又引入了Replica的概念。
每个partition都可以通过副本因子添加多个副本。这样就算有一台机器故障了,其他机器上也有备份的数据
集群环境下的3分区,3副本:

二、安装部署
我用的2.7.0版本,下载后解压
注意选择Binary downloads而不是Source download
2. 进入conf/server.properties文件,打开如下配置
listeners=PLAINTEXT://localhost:9092
- 启动zookeeper
自行安装,我用的3.7版本的zookeeper
4. 启动kafka
bin/kafka-server-start.sh config/server.properties
Kafka命令行
查看topic
bin/kafka-topics.sh --zookeeper localhost:2181 --list
创建topic
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic test1 --partitions 4 --replication-factor 1
查看topic信息
bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic test1
消费命令
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic test1
生产命令
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test1
简单性能测试:
bin/kafka-producer-perf-test.sh --topic test1 --num-records 100000 --record-size 1000 --throughput 2000 --producer-props bootstrap.servers=localhost:9092
bin/kafka-consumer-perf-test.sh --bootstrap-server localhost:9092 --topic test1 -- fetch-size 1048576 --messages 100000 --threads 1
Java客户端
生产者:
public class SimpleKafkaProducer {public static void main(String[] args) {Properties properties=new Properties();properties.setProperty("key.serializer","org.apache.kafka.common.serialization.StringSerializer");properties.setProperty("value.serializer","org.apache.kafka.common.serialization.StringSerializer");properties.setProperty("bootstrap.servers","192.168.157.200:9092");KafkaProducer producer=new KafkaProducer(properties);ProducerRecord record=new ProducerRecord("test1","这是一条消息");producer.send(record);producer.close();}}
消费者
public class SimpleKafkaConsumer {public static void main(String[] args) {Properties properties=new Properties();properties.setProperty("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");properties.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");properties.setProperty("bootstrap.servers","192.168.157.200:9092");//消费者组properties.setProperty("group.id","group1");KafkaConsumer consumer=new KafkaConsumer(properties);//订阅topicconsumer.subscribe(Arrays.asList("test1"));while (true){//拉取数据ConsumerRecords poll=consumer.poll(100);((ConsumerRecords) poll).forEach(data->{System.out.println(((ConsumerRecord)data).value());});}}}
三、高级特性
生产者特性
生产者-确认模式
- acks=0 :只发送不管有没有写入到broker
- acks=1:只写入到leader就认为成功
- acks=-1/all:要求ISR列表里所有follower都同步过去,才算成功
将acks设置为-1就一定能保证消息不丢吗?
答:不是的。如果partition只有一个副本,也就是光有leader没有follower,那么宕机了消息一样会丢失。所以至少也要设置2个及以上的副本才行。
另外,要提高数据可靠性,设置acks=-1的同时,也要设置min.insync.replicas(最小副本数,默认1)
生产者-同步发送
public void syncSend() throws ExecutionException, InterruptedException {Properties properties=new Properties();properties.setProperty("key.serializer","org.apache.kafka.common.serialization.StringSerializer");properties.setProperty("value.serializer","org.apache.kafka.common.serialization.StringSerializer");properties.setProperty("bootstrap.servers","192.168.157.200:9092");KafkaProducer producer=new KafkaProducer(properties);ProducerRecord record=new ProducerRecord("test1","这是一条消息");Future future = producer.send(record);//同步发送消息方法1Object o = future.get();//同步发送消息方法2producer.send(record);producer.flush();producer.close();}
生产者-异步发送
public void asyncSend(){Properties properties=new Properties();properties.setProperty("key.serializer","org.apache.kafka.common.serialization.StringSerializer");properties.setProperty("value.serializer","org.apache.kafka.common.serialization.StringSerializer");properties.setProperty("bootstrap.servers","192.168.157.200:9092");//生产者在发送批次之前等待更多消息加入批次的时间properties.setProperty("linger.ms","1");properties.setProperty("batch.size","20240");KafkaProducer producer=new KafkaProducer(properties);ProducerRecord record=new ProducerRecord("test1","这是一条消息");//异步发送方法1producer.send(record);//异步发送方法2producer.send(record,((metadata, exception) -> {if(exception==null){System.out.println("record="+record.value());}}));}
生产者-顺序保证
同步请求发送+broker只能一个请求一个请求的接
public void sequenceGuarantee(){Properties properties=new Properties();properties.setProperty("key.serializer","org.apache.kafka.common.serialization.StringSerializer");properties.setProperty("value.serializer","org.apache.kafka.common.serialization.StringSerializer");properties.setProperty("bootstrap.servers","192.168.157.200:9092");//生产者在收到服务器响应之前可以发送多少个消息,保证一个一个的发properties.setProperty("max.in.flight.requests.per.connection","1");KafkaProducer producer=new KafkaProducer(properties);ProducerRecord record=new ProducerRecord("test1","这是一条消息");//同步发送producer.send(record);producer.flush();producer.close();}
生产者-消息可靠性传递
事务+幂等
这里的事务就是,发送100条消息,如果其中报错了,那么所有的消息都不能被消费者读取。
public static void transaction(){Properties properties=new Properties();properties.setProperty("key.serializer","org.apache.kafka.common.serialization.StringSerializer");properties.setProperty("value.serializer","org.apache.kafka.common.serialization.StringSerializer");//重试次数properties.setProperty("retries","3");properties.setProperty("bootstrap.servers","192.168.157.200:9092");//生产者发送消息幂等,此时会默认把acks设置为allproperties.setProperty("enable.idempotence","true");//事务idproperties.setProperty("transactional.id","tx0001");ProducerRecord record=new ProducerRecord("test1","这是一条消息");KafkaProducer producer=new KafkaProducer(properties);try {producer.initTransactions();producer.beginTransaction();for (int i = 0; i < 100; i++) {producer.send(record,(recordMetadata, e) -> {if(e!=null){producer.abortTransaction();throw new KafkaException("send error"+e.getMessage());}});}producer.commitTransaction();} catch (ProducerFencedException e) {producer.abortTransaction();e.printStackTrace();}producer.close();}
消费者特性
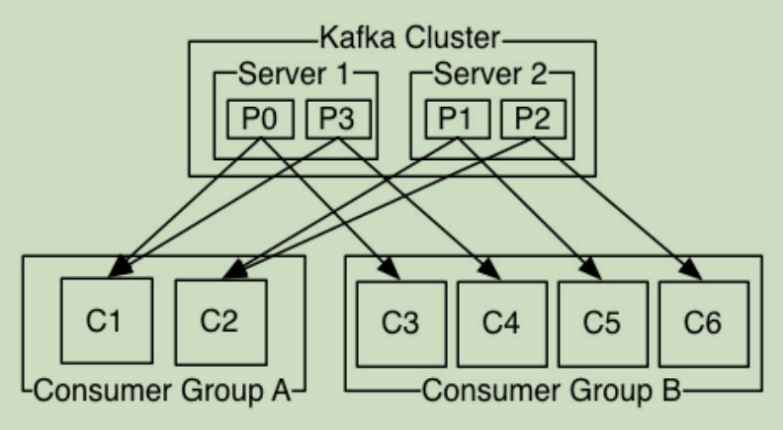
消费者-消费者组

每个消费者组都记录了一个patition的offset,一个partition只能被一个消费者组消费。
如图,一个Topic有4个partition,分别在两个broker上。
对于消费者组A来说,他有两个消费者,所以他里面一个消费者消费2个partition。而对于消费者组B,他有4个消费者,所以一个消费者消费1个partition.
消费者-offset同步提交
void commitSyncReceive() throws InterruptedException {Properties props = new Properties();props.put("bootstrap.servers", "49.234.77.60:9092");props.put("group.id", "group_id");//关闭自动提交props.put("enable.auto.commit", "false");props.put("auto.commit.interval.ms", "1000");props.put("session.timeout.ms", "30000");props.put("max.poll.records", 1000);props.put("auto.offset.reset", "earliest");props.put("key.deserializer", StringDeserializer.class.getName());props.put("value.deserializer", StringDeserializer.class.getName());KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);consumer.subscribe(Arrays.asList(TOPIC));while (true){ConsumerRecords<String, String> msgList=consumer.poll(1000);for (ConsumerRecord<String,String> record:msgList){System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}//同步提交,当前线程会阻塞直到 offset 提交成功consumer.commitSync();}}
消费者-异步提交
void commitAsyncReceive() throws InterruptedException {Properties props = new Properties();props.put("bootstrap.servers", "49.234.77.60:9092");props.put("group.id", "group_id");props.put("enable.auto.commit", "false");props.put("auto.commit.interval.ms", "1000");props.put("session.timeout.ms", "30000");props.put("max.poll.records", 1000);props.put("auto.offset.reset", "earliest");props.put("key.deserializer", StringDeserializer.class.getName());props.put("value.deserializer", StringDeserializer.class.getName());KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);consumer.subscribe(Arrays.asList(TOPIC));while (true){ConsumerRecords<String, String> msgList=consumer.poll(1000);for (ConsumerRecord<String,String> record:msgList){System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}//异步提交consumer.commitAsync(new OffsetCommitCallback() {@Overridepublic void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {if(e!=null){System.err.println("commit failed for "+map);}}});}}
消费者-自定义保存offset
void commitCustomSaveOffest() throws InterruptedException {Properties props = new Properties();props.put("bootstrap.servers", "49.234.77.60:9092");props.put("group.id", "group_id");props.put("enable.auto.commit", "false");props.put("auto.commit.interval.ms", "1000");props.put("session.timeout.ms", "30000");props.put("max.poll.records", 1000);props.put("auto.offset.reset", "earliest");props.put("key.deserializer", StringDeserializer.class.getName());props.put("value.deserializer", StringDeserializer.class.getName());KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);consumer.subscribe(Arrays.asList(TOPIC), new ConsumerRebalanceListener() {//调用时机是Consumer停止拉取数据后,Rebalance开始之前,我们可以手动提交offset@Overridepublic void onPartitionsRevoked(Collection<TopicPartition> collection) {}//调用时机是Rebalance之后,Consumer开始拉取数据之前,我们可以在此方法调整offset@Overridepublic void onPartitionsAssigned(Collection<TopicPartition> collection) {}});while (true){ConsumerRecords<String, String> msgList=consumer.poll(1000);for (ConsumerRecord<String,String> record:msgList){System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}consumer.commitAsync(new OffsetCommitCallback() {@Overridepublic void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {if(e!=null){System.err.println("commit failed for "+map);}}});}}
四、SpringBoot整合Kafka
- 引入依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>
- 配置
#kafkaspring.kafka.bootstrap-servers=192.168.157.200:9092# 发生错误后,消息重发的次数spring.kafka.producer.retries=0spring.kafka.producer.batch-size=16384# 设置生产者内存缓冲区的大小。spring.kafka.producer.buffer-memory=33554432spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializerspring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializerspring.kafka.producer.acks=1#消费者#自动提交的时间间隔spring.kafka.consumer.auto-commit-interval=1S# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录spring.kafka.consumer.auto-offset-reset=earliestspring.kafka.consumer.enable-auto-commit=falsespring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializerspring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer# 在侦听器容器中运行的线程数。spring.kafka.listener.concurrency=5#listner负责ack,每调用一次,就立即commitspring.kafka.listener.ack-mode=manual_immediatespring.kafka.listener.missing-topics-fatal=false
- producer
@Componentpublic class MyKafkaProducer {@Autowiredprivate KafkaTemplate<String,Object> kafkaTemplate;public void send(String topic,Object object){ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, object);future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {@Overridepublic void onFailure(Throwable ex) {System.out.println("发送消息失败"+ex.getMessage());}@Overridepublic void onSuccess(SendResult<String, Object> result) {System.out.println("发送消息成功"+result);}});}
- consumer
@Componentpublic class MyKafkaConsumer {@KafkaListener(topics = "test1",groupId = "group_test")public void consumer(ConsumerRecord<?, ?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic){Optional message = Optional.ofNullable(record.value());if (message.isPresent()) {Object msg = message.get();System.out.println("group_test 消费了: Topic:" + topic + ",Message:" + msg);ack.acknowledge();}}@KafkaListener(topics = "test1",groupId = "group_test2")public void consumer2(ConsumerRecord<?, ?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic){Optional message = Optional.ofNullable(record.value());if (message.isPresent()) {Object msg = message.get();System.out.println("group_test2 消费了: Topic:" + topic + ",Message:" + msg);ack.acknowledge();}}}
- 测试

超详细kafka教程来啦的更多相关文章
- VMware虚拟机下安装CentOS7.0超详细图文教程
1.本文说明: 官方的第一个文本档案.也就是0_README.txt,大概意思是这样(渣翻译,但是大概意思还是有的). CentOS-7.0-1406-x86_64-DVD.iso:这个镜像(DVD ...
- MySql5.6 Window超详细安装教程
林炳文Evankaka原创作品.转载请注明出处http://blog.csdn.net/evankaka 目录 一.安装包准备二.开始安装三.验证安装四.客户端工具 一.安装包准备 1.下载MySql ...
- MySql5.6Window超详细安装教程(msi 格式的安装)
转自:红黑联盟 http://www.2cto.com/database/201506/409821.html 一.安装包准备 1.下载MySql5.6 http://www.mysql.com/ ...
- 在Ubuntu下进行XMR Monero(门罗币)挖矿的超详细图文教程
大家都知道,最近挖矿什么的非常流行,于是我也在网上看了一些大神写的教程,以及跟一些大神请教过如何挖矿,但是网上的教程都感觉写得不够详细,于是今天我这里整理一个教程,希望能够帮到想要挖矿的朋友. 首先, ...
- 超详细实战教程丨多场景解析如何迁移Rancher Server
本文转自Rancher Labs 作者介绍 王海龙,Rancher中国社区技术经理,负责Rancher中国技术社区的维护和运营.拥有6年的云计算领域经验,经历了OpenStack到Kubernetes ...
- 【建议收藏】Redis超详细入门教程大杂烩
写在前边 Redis入门的整合篇.本篇也算是把2021年redis留下来的坑填上去,重新整合了一翻,点击这里,回顾我的2020与2021~一名大二后台练习生 NoSQL NoSQL(NoSQL = N ...
- 最新MATLAB R2021b超详细安装教程(附完整安装文件)
摘要:本文详细介绍Matlab R2021b的安装步骤,为方便安装这里提供了完整安装文件的百度网盘下载链接供大家使用.从文件下载到证书安装本文都给出了每个步骤的截图,按照图示进行即可轻松完成安装使用. ...
- 最新MATLAB R2020b超详细安装教程(附完整安装文件)
摘要:本文详细介绍Matlab R2020b的安装步骤,为方便安装这里提供了完整安装文件的百度网盘下载链接供大家使用.从文件下载到证书安装本文都给出了每个步骤的截图,按照图示进行即可轻松完成安装使用. ...
- MATLAB R2019b超详细安装教程(附完整安装文件)
摘要:本文详细介绍Matlab的安装步骤,为方便安装这里提供了完整安装文件的百度网盘下载链接供大家使用.从文件下载到证书安装本文都给出了每个步骤的截图,按照图示进行即可轻松完成安装使用.本文目录如首页 ...
随机推荐
- python中进程详解
1:pdb调试:基于命令行的调试工具,非常类似gnu和gdb调试,以下是常用的调试命令: 可以python -m pdb xxx.py(你的py文件名)进入命令行调试模式 命令 简写命令 作用 bea ...
- linux 20个常用命令
一.文件和目录 1. cd命令 (它用于切换当前目录,它的参数是要切换到的目录的路径,可以是绝对路径,也可以是相对路径) cd /home 进入 '/ home' 目录 cd .. ...
- selenium元素定位之 动态id, class元素定位
1.直接进入正题 如下图, 有些元素每次进入都会刷新, 造成元素无法重复定位 怎么办? "xpath部分属性值"定位方法可以帮到我们 1.包含属性定位 driver.find_el ...
- 第3篇-CallStub新栈帧的创建
在前一篇文章 第2篇-JVM虚拟机这样来调用Java主类的main()方法 中我们介绍了在call_helper()函数中通过函数指针的方式调用了一个函数,如下: StubRoutines::cal ...
- Golang语言系列-17-Gin框架
Gin框架 Gin框架简介 package main import ( "github.com/gin-gonic/gin" "io" "net/ht ...
- CVE-2021-21972 vSphere Client RCE复现,附POC & EXP
漏洞简介 vSphere 是 VMware 推出的虚拟化平台套件,包含 ESXi.vCenter Server 等一系列的软件.其中 vCenter Server 为 ESXi 的控制中心,可从单一控 ...
- 说说XXE漏洞那些事
想不起来写点啥了,又是摸鱼的一天,看了一些红队大佬们整理的资料,非常精彩,于是一个咸鱼翻身先选了一些简单的小点来写一写个人的感想(后续会继续更新其他内容) 不能说写的是技术分享,因为师傅们的文章珠玉在 ...
- 内网探测之SPN服务扫描及相关利用
在写下一个大块之前,补充一些小知识点,也没啥新东西 0x01简介 如果常规扫描服务,结果不理想,非常GG,可以考虑使用SPN进行服务扫描,这是为了借助Kerberos的正常查询行为(向域控发起LDAP ...
- SQL 练习40
按照出生日期来计算学生的年龄信息 IF OBJECT_ID('GetStudentAge','FN') IS NOT NULL DROP FUNCTION GetStudentAge GO CREAT ...
- Java小题,通过JNI调用本地C++共享库中的对应方法实现杨辉三角的绘制
1.在Eclipse中配置Javah,配置如下 位置是你javah.exe在你电脑磁盘上的路径 位置:C:\Program Files\Java\jdk1.8.0_112\bin\javah.exe ...