C程序内存布局
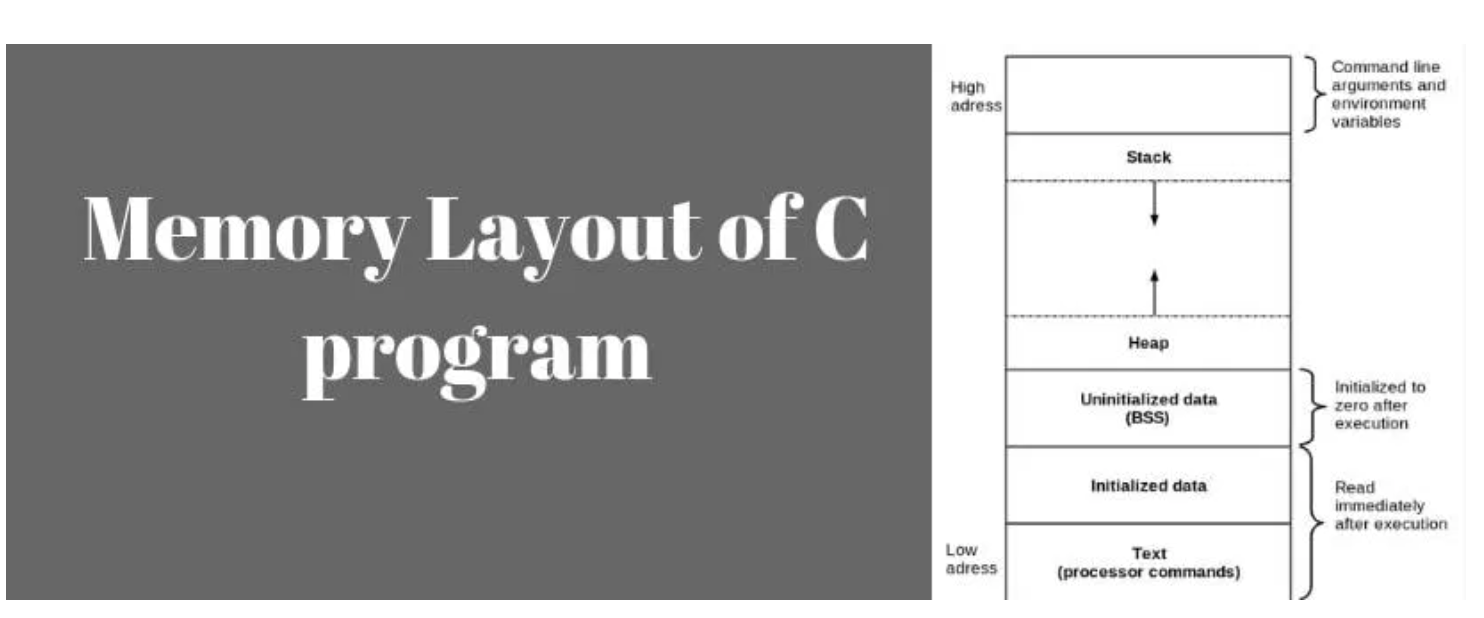
作为计算机专业的来说,程序入门基本都是从C语言开始的,了解C程序中的内存布局,对我们了解整个程序运行,分析程序出错原因,会起到事半功倍的作用 。
C程序的内存布局包含五个段,分别是STACK(栈段),HEAP(堆段),BSS(以符号开头的块),DS(数据段)和TEXT(文本段)。
每个段都有自己的读取,写入和可执行权限。如果程序尝试以不允许的方式访问内存,则会发生段错误,也就是我们常说的coredump。
段错误是导致程序崩溃的常见问题。核心文件(核心转储文件)也与段错误相关联,开发人员使用该文件来查找崩溃的根本原因(段错误)。
下面我们将深入这五个段,更加详细的讲解每个段在程序开发或者运行中的作用。
High Addresses ---> .----------------------.
| Environment |
|----------------------|
| | Functions and variable are declared
| STACK | on the stack.
base pointer -> | - - - - - - - - - - -|
| | |
| v |
: :
. . The stack grows down into unused space
. Empty . while the heap grows up.
. .
. . (other memory maps do occur here, such
. . as dynamic libraries, and different memory
: : allocate)
| ^ |
| | |
brk point -> | - - - - - - - - - - -| Dynamic memory is declared on the heap
| HEAP |
| |
|----------------------|
| BSS | Uninitialized data (BSS)
|----------------------|
| Data | Initialized data (DS)
|----------------------|
| Text | Binary code
Low Addresses ----> '----------------------'
栈
- 它位于较高的地址,与堆段的增长和收缩方向正好相反。
- 函数的局部变量存在于栈上
- 调用函数时,将在栈中创建一个栈帧。
- 每个函数都有一个栈帧。
- 栈帧包含函数的局部变量参数和返回值。
- 栈包含一个LIFO结构。函数变量在调用时被压入栈,返回时将函数变量从栈弹出。
- SP(栈指针)寄存器跟踪栈的顶部。
#include
int main(void) {
int data; // 局部变量,存储在栈上
return 0;
}
堆
- 用于在运行时分配内存。
- 由内存管理函数(如malloc、calloc、free等)管理的堆区域,这些函数可以在内部使用brk和sbrk系统调用来调整其大小。
- 堆区域由进程中的所有共享库和动态加载的模块共享。
- 它在堆栈的相反方向上增长和收缩。
#include
int main(void) {
char *pStr = malloc(sizeof(char)*4); //pStr指向堆地址
return 0;
}
BSS(未初始化的数据块)
- 包含所有未初始化的全局和静态变量。
- 此段中的所有变量都由零或者空指针初始化。
- 程序加载器在加载程序时为BSS节分配内存。
#include
int data1; // 未初始化的全局变量存储在BSS段
int main(void) {
static int data2; // 未初始化的静态变量存储在BSS段
return 0;
}
DS(初始化的数据块)
- 包含显式初始化的全局变量和静态变量。
- 此段的大小由程序源代码中值的大小决定,在运行时不会更改。
- 它具有读写权限,因此可以在运行时更改此段的变量值。
- 该段可进一步分为初始化只读区和初始化读写区。
#include
int data1 = 10 ; //初始化的全局变量存储在DS段
int main(void) {
static int data2 = 3; //初始化的静态变量存储在DS段
return 0;
}
TEXT
- 该段包含已编译程序的二进制文件。
- 该段是一个只读段,用于防止程序被意外修改。
- 该段是可共享的,因此对于文本编辑器等频繁执行的程序,内存中只需要一个副本。
深入
现在有一个简单的程序,代码如下:
#include
int main(void) {
return 0;
}
我们通过如下命令进行编译
gcc -g a.cc -o a
然后通过size命令,可以看到各个段的大小
[root@build src]# gcc a.c -o a
[root@build src]# size a
text data bss dec hex filename
1040 484 16 1540 604 a
其中前三列分别为可执行程序a的text、data以及bss段的大小,第四列为该三段大小之和,第四列为该大小的十六进制表示,最后一列是文件名。
增加一个未初始化的静态变量
#include
int main(void) {
static int data;
return 0;
}
通过size命令
[root@build src]# size a
text data bss dec hex filename
1040 484 24 1548 60c a
从上面可以看出,bss段size变大
增加一个初始化的静态变量
#include
int main(void) {
static int data = 10;
return 0;
}
通过size命令
[root@build src]# size a
text data bss dec hex filename
1040 488 16 1544 608 a
从上面可以看出,data段size变大
增加一个未初始化的全局变量
#include
int data;
int main(void) {
return 0;
}
通过size命令
[root@build src]# size a
text data bss dec hex filename
1040 484 24 1548 60c a
从上面可以看出,bss段size变大
数据段的只读区域和读写区域
#include
char str[]= "Hello world";
int main(void) {
printf("%s\n",str);
str[0]='K';
printf("%s\n",str);
return 0;
}
输出
Hello world
Kello world
可以看到上面的示例str是一个全局数组,因此它将进入数据段。 还可以看到能够更改该值,因此它具有读取和写入权限。
现在查看其他示例代码
#include
char *str= "Hello world";
int main(void) {
str[0]='K';
printf("%s\n",str);
return 0;
}
在上面的示例中,我们无法更改数组字符是因为它是文字字符串。常量字符串不仅会出现在数据部分,而且所有类型的const全局数据都将进入该部分。
数据块只读部分,通常除了const变量和常量字符串外,程序的文本部分(通常是.rodata段)也存在于数据块的只读部分,因为通常无法通过程序进行修改。
C程序内存布局的更多相关文章
- C语言程序内存布局
C语言程序内存布局 如有转载,请注明出处:http://blog.csdn.net/embedded_sky/article/details/44457453 作者:super_bert@csdn 一 ...
- 一起talk C栗子吧(第一百三十一回:C语言实例--C程序内存布局三)
各位看官们,大家好.上一回中咱们说的是C程序内存布局的样例,这一回咱们继续说该样例.闲话休提,言归正转.让我们一起talk C栗子吧. 看官们,关于C程序内存布局的样例,我们在前面的两个章回都介绍过了 ...
- 用一个词(TASPK)牢记C程序内存布局
一个典型的C程序内存布局,从低地址到高地址分别为: 1. text (正文段,即代码段 Code Segment) 2. data (已经初始化的数据段) 3. bss (未被初始化的数据段 Bloc ...
- C++程序内存布局
代码区(code area) 程序内存空间 全局数据区(data area) 堆区(heap area) 栈区(stack area) 一个由C/C++编译的程序占用的内存分为以下几个部分, 1) ...
- linux C 程序内存布局
参考: 1. http://www.cnblogs.com/clover-toeic/p/3754433.html 2. http://www.cnblogs.com/jacksu-tencent/p ...
- ESP32应用程序的内存布局
应用程序内存布局 ESP32芯片具有灵活的内存映射功能.本节介绍ESP-IDF在默认情况下如何使用这些功能. ESP-IDF中的应用程序代码可以放置在以下内存区域之一中. IRAM(指令RAM) ES ...
- c++内存布局与c程序的内存布局
c/c++的内存布局:堆,栈,自由存储区(与堆的区别),全局/静态存储区,常量存储区(字符串常量,const常量) http://www.cnblogs.com/QG-whz/p/5060894.ht ...
- UNIX高级环境编程(8)进程环境(Process Environment)- 进程的启动和退出、内存布局、环境变量列表
在学习进程控制相关知识之前,我们需要了解一个单进程的运行环境. 本章我们将了解一下的内容: 程序运行时,main函数是如何被调用的: 命令行参数是如何被传入到程序中的: 一个典型的内存布局是怎样的: ...
- 探讨C++ 变量生命周期、栈分配方式、类内存布局、Debug和Release程序的区别
探讨C++ 变量生命周期.栈分配方式.类内存布局.Debug和Release程序的区别(一) 今天看博客园的文章,发现博问栏目中有一个网友的问题挺有趣的,就点进去看了下,标题是“C++生存期问题”,给 ...
随机推荐
- Three.js 中 相机的常用参数含义
Three.js 中相机常用的参数有up.position和lookAt. position是指相机所在的位置,将人头比作相机的话,那么position就是人头的中心的位置: up类似于人的脖子可以调 ...
- You have mail in /var/mail/xxx
因为配置 DDNS, 我添加了个 crontab 定时任务,每隔 1 分钟执行一段 python 脚本 然后就发现 terminal 经常提示 'You have mail in /var/mail/ ...
- Excel 快速跳转到工作表
新建 vba 模块 Sub GotoSheet() tname = InputBox("input table name") If StrPtr(tname) = 0 Then E ...
- JDK1.8源码阅读笔记(1)Object类
JDK1.8源码阅读笔记(1)Object类 Object 类属于 java.lang 包,此包下的所有类在使⽤时⽆需⼿动导⼊,系统会在程序编译期间⾃动 导⼊.Object 类是所有类的基类,当⼀ ...
- 查看elasticsearch版本的方法
查看elasticsearch版本的方法: 1.elasticsearch已经启动的情况下 使用curl -XGET localhost:9200命令查看: "version" : ...
- python中dump与dumps的区别
刚写了一个代吗,没有搞懂dump和dumps的区别,现在搞懂了,下班后在来整理import pickleq = [1,2,3,4]pickle.dump(q,open("cb1.txt&qu ...
- 树莓派OLED模块的使用教程大量例程详解
简介 Python有两个可以用的OLED库 [Adafruit_Python_SSD1306库]->只支持SSD1306 [Luma.oled库]->支持SSD1306 / SSD1309 ...
- 浅谈 Xamarin Community Toolkit 的未来发展
.NET MAUI会在今年晚些时候发布,我们也很高兴和大家一起分享我们对Xamarin Community Toolkit的计划! 这包括 .NET MAUI Community Toolkit.Xa ...
- [Python]爬虫获取知乎某个问题下所有图片并去除水印
获取URL 进入某个知乎问题的主页下,按F12打开开发者工具后查看network面板. network面板可以查看页面向服务器请求的资源.资源的大小.加载资源花费的时间以及哪些资源加载失败等信息.还可 ...
- TP5数据库数据变动日志记录设计
根据网友的设计进行了部分调整: 用户分为管理员admin表和用户user表 记录操作表数据 增删改: insert/delete/update <?php /** * OperateLog.ph ...