Python3爬虫之爬取某一路径的所有html文件
要离线下载易百教程网站中的所有关于Python的教程,需要将Python教程的首页作为种子url:http://www.yiibai.com/python/,然后按照广度优先(广度优先,使用队列;深度优先,使用栈),依次爬取每一篇关于Python的文章。为了防止同一个链接重复爬取,使用集合来限制同一个链接只处理一次。
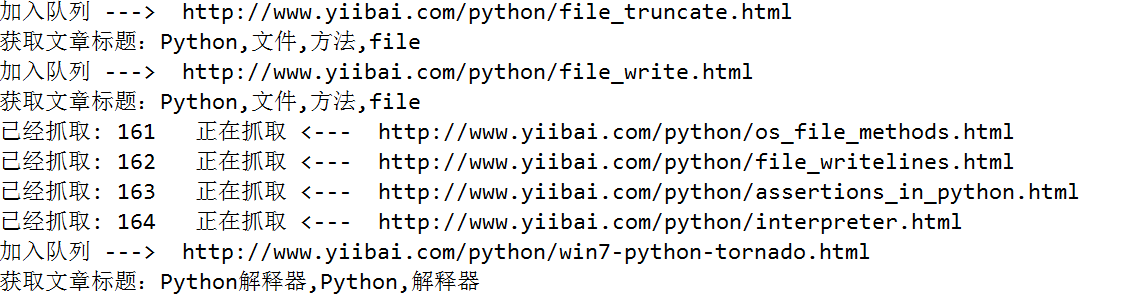
使用正则表达式提取网页源码里边的文章标题和文章url,获取到了文章的url,使用Python根据url生成html文件十分容易。
-
import re
-
import urllib.request
-
import urllib
-
from collections import deque
-
# 保存文件的后缀
-
SUFFIX='.html'
-
# 提取文章标题的正则表达式
-
REX_TITLE=r'<title>(.*?)</title>'
-
# 提取所需链接的正则表达式
-
REX_URL=r'/python/(.+?).html'
-
# 种子url,从这个url开始爬取
-
BASE_URL='http://www.yiibai.com/python/'
-
-
-
# 将获取到的文本保存为html文件
-
def saveHtml(file_name,file_content):
-
# 注意windows文件命名的禁用符,比如 /
-
with open (file_name.replace('/','_')+SUFFIX,"wb") as f:
-
# 写文件用bytes而不是str,所以要转码
-
f.write(bytes(file_content, encoding = "utf8"))
-
# 获取文章标题
-
def getTitle(file_content):
-
linkre = re.search(REX_TITLE,file_content)
-
if(linkre):
-
print('获取文章标题:'+linkre.group(1))
-
return linkre.group(1)
-
-
# 爬虫用到的两个数据结构,队列和集合
-
queue = deque()
-
visited = set()
-
# 初始化种子链接
-
queue.append(BASE_URL)
-
count = 0
-
-
while queue:
-
url = queue.popleft() # 队首元素出队
-
visited |= {url} # 标记为已访问
-
-
print('已经抓取: ' + str(count) + ' 正在抓取 <--- ' + url)
-
count += 1
-
urlop = urllib.request.urlopen(url)
-
# 只处理html链接
-
if 'html' not in urlop.getheader('Content-Type'):
-
continue
-
-
# 避免程序异常中止
-
try:
-
data = urlop.read().decode('utf-8')
-
title=getTitle(data);
-
# 保存文件
-
saveHtml(title,data)
-
except:
-
continue
-
-
# 正则表达式提取页面中所有链接, 并判断是否已经访问过, 然后加入待爬队列
-
linkre = re.compile(REX_URL)
-
for sub_link in linkre.findall(data):
-
sub_url=BASE_URL+sub_link+SUFFIX;
-
# 已经访问过,不再处理
-
if sub_url in visited:
-
pass
-
else:
-
# 设置已访问
-
visited |= {sub_url}
-
# 加入队列
-
queue.append(sub_url)
-
print('加入队列 ---> ' + sub_url)

Python3爬虫之爬取某一路径的所有html文件的更多相关文章
- 【Python3爬虫】爬取美女图新姿势--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- python3 爬虫之爬取安居客二手房资讯(第一版)
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author;Tsukasa import requests from bs4 import Beau ...
- python3爬虫应用--爬取网易云音乐(两种办法)
一.需求 好久没有碰爬虫了,竟不知道从何入手.偶然看到一篇知乎的评论(https://www.zhihu.com/question/20799742/answer/99491808),一时兴起就也照葫 ...
- 使用htmlparse爬虫技术爬取电影网页的全部下载链接
昨天,我们利用webcollector爬虫技术爬取了网易云音乐17万多首歌曲,而且还包括付费的在内,如果时间允许的话,可以获取更多的音乐下来,当然,也有小伙伴留言说这样会降低国人的知识产权保护意识,诚 ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- 使用htmlparser爬虫技术爬取电影网页的全部下载链接
昨天,我们利用webcollector爬虫技术爬取了网易云音乐17万多首歌曲,而且还包括付费的在内,如果时间允许的话,可以获取更多的音乐下来,当然,也有小伙伴留言说这样会降低国人的知识产权保护意识,诚 ...
- 【Python】【爬虫】爬取酷狗TOP500
好啦好啦,那我们来拉开我们的爬虫之旅吧~~~ 这一只小爬虫是爬取酷狗TOP500的,使用的爬取手法简单粗暴,目的是帮大家初步窥探爬虫长啥样,后期会慢慢变得健壮起来的. 环境配置 在此之前需要下载一个谷 ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
随机推荐
- matplotlib 可视化 —— 定制画布风格 Customizing plots with style sheets(plt.style)
Customizing plots with style sheets - Matplotlib 1.5.1 documentation 1. 使用和显示其他画布风格 >> import ...
- Maven项目:Plugin execution not covered by lifecycle configuration 解决方案
这个是eclipse中配置文件pom.xml报的错.具体错误信息: Plugin execution not covered by lifecycle configuration: org.apach ...
- 加载等待loading
自己写的一个小插件,还有很多需要完善... (function ($) { $.fn.StartLoading = function (option) { var defaultV ...
- vue中使用滚动效果
new Vue({ el: '#app', data: function data() { return { bottom: false, beers: [] }; }, watch: { botto ...
- OGG切换步骤
步骤描述 提前准备好切换方案:以及其他相关人员的配合 切换至容灾数据库: (1)停止前端业务,确认目标端数据已经追平 (2)数据校验,确认数据一致 (3)停止生产库OGG进程(停止后可以直接删除) ( ...
- linux上将另一个文件内容快速写入正在编辑的文件内
一.我们看到 www 目录下有两个文件.like.php 内有一行字母,而 loo.php 内什么也没有. 二 .我们来编辑 loo.php. 三.用下面的命令将 like.php 的内容复制到 lo ...
- PHP 数组转字符串,字符串转数组
explode将字符串分割为数组: $str = explode( ',',$str); 第一个参数为字符串的分界符,例如1,2,3,4. 第二个是需要分割的数组 分割后就是 array( 1 , 2 ...
- 《转载》编程入门指南 v1.4
编程入门指南 v1.4 Badger · 8 个月前 作者:@萧井陌, @Badger 自由转载-非商用-非衍生-保持署名 | Creative Commons BY-NC-ND 3.0 CoCode ...
- 数据库Flashback学习
最近更新时间:2018/12/18 适用场景 数据库升级.快速构建测试环境.DG中重建主库 前置条件 1. ARCHIVELOG 模式 数据库为 mount 状态下开启,最好指定archive log ...
- vue2.0学习教程
十分钟上手-搭建vue开发环境(新手教程)https://www.jianshu.com/p/0c6678671635 如何在本地运行查看github上的开源项目https://www.jianshu ...