Hadoop MapReduce编程 API入门系列之wordcount版本2(六)
这篇博客,给大家,体会不一样的版本编程。

代码
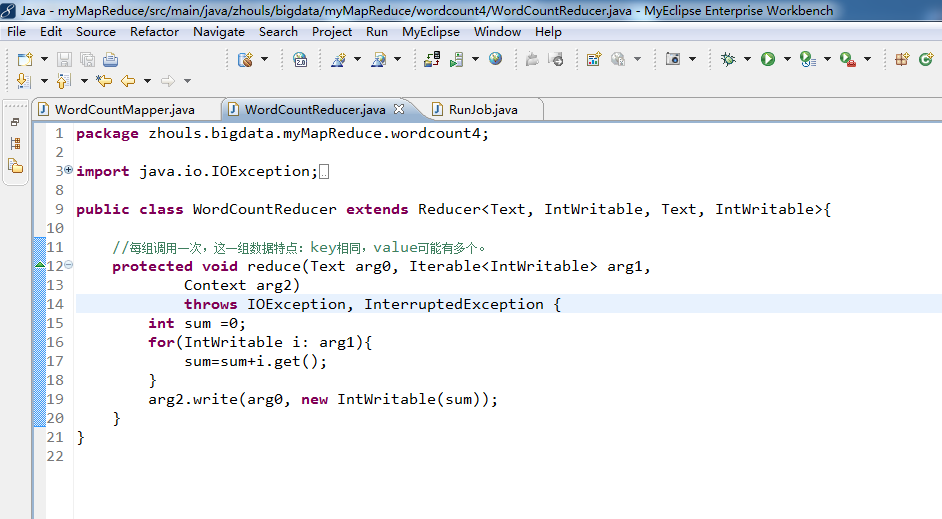
package zhouls.bigdata.myMapReduce.wordcount4; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils; public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ //该方法循环调用,从文件的split中读取每行调用一次,把该行所在的下标为key,该行的内容为value
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String[] words = StringUtils.split(value.toString(), ' ');
for(String w :words){
context.write(new Text(w), new IntWritable(1));
}
}
}
package zhouls.bigdata.myMapReduce.wordcount4; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ //每组调用一次,这一组数据特点:key相同,value可能有多个。
protected void reduce(Text arg0, Iterable<IntWritable> arg1,
Context arg2)
throws IOException, InterruptedException {
int sum =0;
for(IntWritable i: arg1){
sum=sum+i.get();
}
arg2.write(arg0, new IntWritable(sum));
}
}
//System.setProperty("HADOOP_USER_NAME", "root");
//
//1、MR执行环境有两种:本地测试环境,服务器环境
//
//本地测试环境(windows):(便于调试)
// 在windows的hadoop目录bin目录有一个winutils.exe
// 1、在windows下配置hadoop的环境变量
// 2、拷贝debug工具(winutils.exe)到HADOOP_HOME/bin
// 3、修改hadoop的源码 ,注意:确保项目的lib需要真实安装的jdk的lib
//
// 4、MR调用的代码需要改变:
// a、src不能有服务器的hadoop配置文件(因为,本地是调试,去服务器环境集群那边的)
// b、再调用是使用:
// Configuration config = new Configuration();
// config.set("fs.defaultFS", "hdfs://HadoopMaster:9000");
// config.set("yarn.resourcemanager.hostname", "HadoopMaster");
//服务器环境:(不便于调试),有两种方式。
//首先需要在src下放置服务器上的hadoop配置文件(都要这一步)
//1、在本地直接调用,执行过程在服务器上(真正企业运行环境)
// a、把MR程序打包(jar),直接放到本地
// b、修改hadoop的源码 ,注意:确保项目的lib需要真实安装的jdk的lib
// c、增加一个属性:
// config.set("mapred.jar", "C:\\Users\\Administrator\\Desktop\\wc.jar");
// d、本地执行main方法,servlet调用MR。
//
//
//2、直接在服务器上,使用命令的方式调用,执行过程也在服务器上
// a、把MR程序打包(jar),传送到服务器上
// b、通过: hadoop jar jar路径 类的全限定名
//
//
//
//
//a,1 b,1
//a,3 c,3
//a,2 d,2
//
//
//a,3 c,3
//a,2 d,2
//a,1 b,1
//
package zhouls.bigdata.myMapReduce.wordcount4; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class RunJob { public static void main(String[] args) {
Configuration config =new Configuration();
config.set("fs.defaultFS", "hdfs://HadoopMaster:9000");
config.set("yarn.resourcemanager.hostname", "HadoopMaster");
// config.set("mapred.jar", "C:\\Users\\Administrator\\Desktop\\wc.jar");//先打包好wc.jar
try {
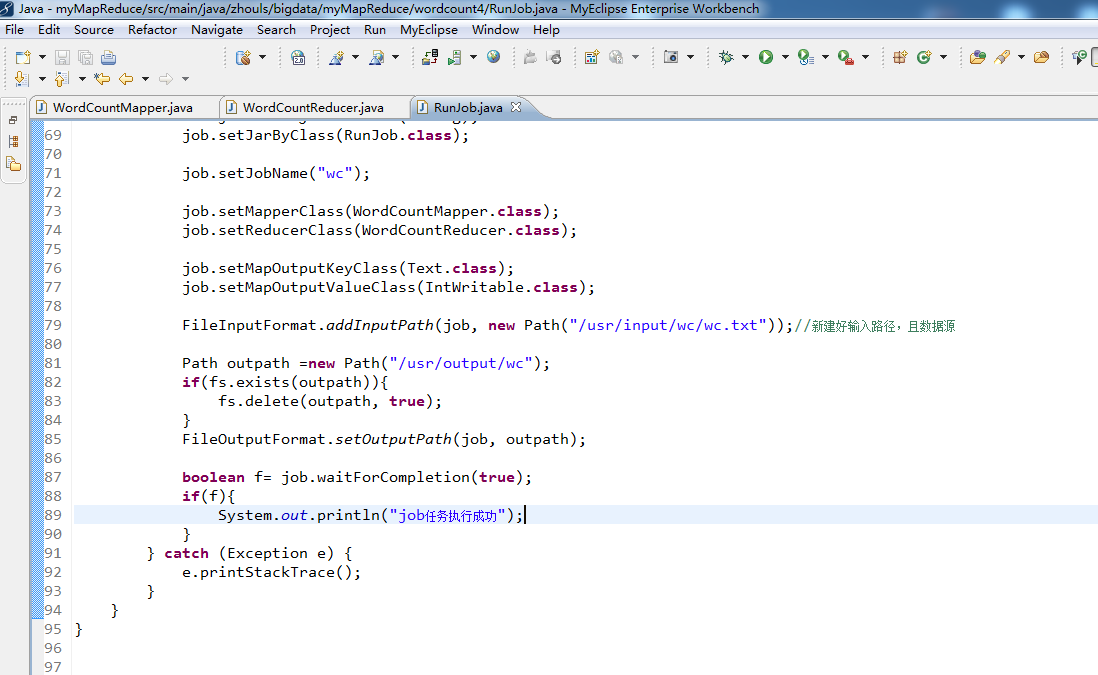
FileSystem fs =FileSystem.get(config); Job job =Job.getInstance(config);
job.setJarByClass(RunJob.class); job.setJobName("wc"); job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path("/usr/input/wc/wc.txt"));//新建好输入路径,且数据源 Path outpath =new Path("/usr/output/wc");
if(fs.exists(outpath)){
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath); boolean f= job.waitForCompletion(true);
if(f){
System.out.println("job任务执行成功");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
Hadoop MapReduce编程 API入门系列之wordcount版本2(六)的更多相关文章
- Hadoop MapReduce编程 API入门系列之wordcount版本1(五)
这个很简单哈,编程的版本很多种. 代码版本1 package zhouls.bigdata.myMapReduce.wordcount5; import java.io.IOException; im ...
- Hadoop MapReduce编程 API入门系列之wordcount版本4(八)
这篇博客,给大家,体会不一样的版本编程. 是将map.combiner.shuffle.reduce等分开放一个.java里.则需要实现Tool. 代码 package zhouls.bigdata. ...
- Hadoop MapReduce编程 API入门系列之wordcount版本5(九)
这篇博客,给大家,体会不一样的版本编程. 代码 package zhouls.bigdata.myMapReduce.wordcount1; import java.io.IOException; i ...
- Hadoop MapReduce编程 API入门系列之wordcount版本3(七)
这篇博客,给大家,体会不一样的版本编程. 代码 package zhouls.bigdata.myMapReduce.wordcount3; import java.io.IOException; i ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
随机推荐
- <转>c++引用与指针的区别(着重理解)
★ 相同点: 1. 都是地址的概念: 指针指向一块内存,它的内容是所指内存的地址:引用是某块内存的别名. ★ 区别: 1. 指针是一个实体,而引用仅是个别名: 2. 引用使用时无需解引用(*),指 ...
- Luogu P1365 WJMZBMR打osu! / Easy
概率期望专题首杀-- 毒瘤dp 首先根据数据范围推断出复杂度在O(n)左右 但不管怎么想都是n^2-- 晚上躺在床上吃东西的时候(误)想到之前有几道dp题是通过前缀和优化的 而期望的可加性又似乎为此创 ...
- c# md5加密封装
/// <summary> /// md5加密字符串 /// </summary> /// <param name="str">需要加密的字符串 ...
- Django逻辑关系
title: Django学习笔记 subtitle: 1. Django逻辑关系 date: 2018-12-14 10:17:28 --- Django逻辑关系 本文档主要基于Django2.2官 ...
- Java JPA通过hql语句查询数据
import javax.persistence.PersistenceContext; import javax.persistence.Query; public class StudentSer ...
- CF482D Random Function and Tree 树形DP + 思维 + 神题
Code: #include<bits/stdc++.h> #define ull unsigned long long #define MOD 1000000007 #define ll ...
- 【转载】java文件路径问题及getResource和getClassLoader().getResource的区别
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/u012572955/article/details/52880520我们经常在java的io操作中读 ...
- linux 中,mysql数据库备份操作
1.新建一个sh脚本(可以先建一个txt文本,然后改为sh文件). 代码如下: #!/bin/bash #设置mysql备份目录 folder=/**/** cd $folder day=`date ...
- mysql 基础教程
创建数据库: CREATE DATABASE --DATABASE 或者 SCHEMA数据库集合 IF NOT EXISTS db_name CHARACTER SET utf8 COLLATE ut ...
- 修改layui的后台模板的左侧导航栏可以伸缩
原生的左侧导航栏代码: <div class="layui-side layui-bg-black"> <div class="layui-side-s ...