记一个男默女泪的 BUG
姗姗来迟的词频统计代码 BUG 的发现
1. 此前提交的第一次代码作业总结博客
http://www.cnblogs.com/ustczwq/p/8680704.html
2. BUG 本天成,妙手偶得之
虽然代码已经提交,但总是感觉哪个地方不太对,bug 存在得过于莫名其妙。然后,随手打开代码,稍微调试了一下,当我发现 bug 的时候,不知道该说些什么好,只想讲脏话。
出现 bug 的地方:

改过之后:
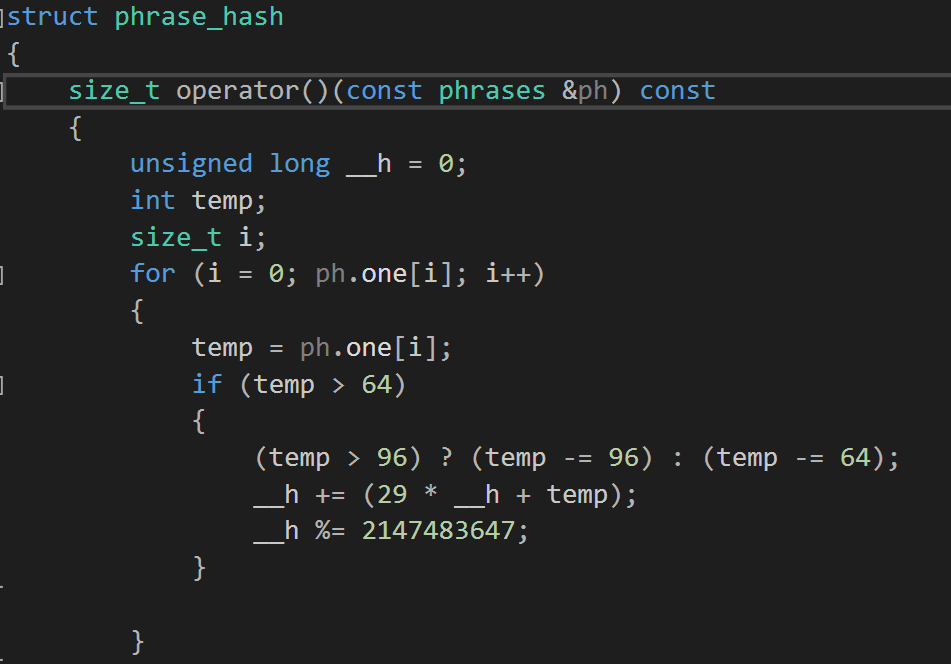
看出来了吧,妈卖批,三目运算符没赋值。改完之后,输出结果立马正确。怪不得用 unordered_map 的时候哈希表的查询出问题了,我 TM 定义的哈希函数有问题。虽然迟了,但那种优化是对的,简单补一篇,算是对原博客的完善。
3. 加了几个等于号之后的源代码
#include "io.h"
#include "math.h"
#include "stdio.h"
#include "string.h"
#include "stdlib.h"
#include "unordered_map" using namespace std; #define small 2 int wordnum = ;
int charnum = ;
int linenum = ; struct wordsdata //存放单词信息
{
char words[]; //单词字符串
int number; //出现次数
wordsdata *next;
};
struct phrases
{
char *one;
char *two;
int num;
}; int wordcmp(char *str1, char *str2);
int gettop(struct wordsdata **word);
int getwords(char *path, struct wordsdata **word);
int getfiles(char *path, struct _finddata_t *fileinfo, long handle); struct phrase_cmp
{
bool operator()(const phrases &p1, const phrases &p2) const
{
return ((wordcmp(p1.one, p2.one) < ) && (wordcmp(p1.two, p2.two) < ));
} };
struct phrase_hash
{
size_t operator()(const phrases &ph) const
{
unsigned long __h = ;
int temp;
size_t i;
for (i = ; ph.one[i]; i++)
{
temp = ph.one[i];
if (temp > )
{
(temp > ) ? (temp -= ) : (temp -= );
__h += ( * __h + temp);
__h %= ;
} }
for (i = ; ph.two[i]; i++)
{
temp = ph.two[i];
if (temp > )
{
(temp > ) ? (temp -= ) : (temp -= );
__h += ( * __h + temp);
__h %= ;
}
} return size_t(__h);
} }; typedef unordered_map<phrases, int, phrase_hash, phrase_cmp> Char_Phrase;
Char_Phrase phrasemap;
struct wordsdata *fourletter[ * * * ] = {}; //按首四字母排序 int main()
{
int j = ;
long handle = ; // 用于查找的句柄
struct _finddata_t fileinfo; // 文件信息的结构体
char *path = __argv[]; getfiles(path, &fileinfo, handle); gettop(fourletter); system("pause");
return ;
} int getfiles(char *path, struct _finddata_t *fileinfo, long handle)
{
handle = _findfirst(path, fileinfo); //第一次打开父目录
if (handle == -)
return -; do
{
//printf("> %s\n", path); //显示目录名 if (fileinfo->attrib & _A_SUBDIR) //如果读取到子目录
{
if (strcmp(fileinfo->name, ".") != && strcmp(fileinfo->name, "..") != )
{
char temppath[] = ""; //记录子目录路径
long temphandle = ;
struct _finddata_t tempfileinfo;
strcpy(temppath, path);
strcat(temppath, "/*"); temphandle = _findfirst(temppath, &tempfileinfo); //第一次打开子目录
if (temphandle == -)
return -; do //对子目录所有文件递归
{
if (strcmp(tempfileinfo.name, ".") != && strcmp(tempfileinfo.name, "..") != )
{
strcpy(temppath, path);
strcat(temppath, "/");
strcat(temppath, tempfileinfo.name);
getfiles(temppath, &tempfileinfo, temphandle);
}
} while (_findnext(temphandle, &tempfileinfo) != -); _findclose(temphandle);
}//递归完毕 } //子目录读取完毕
else
getwords(path, fourletter); } while (_findnext(handle, fileinfo) != -); _findclose(handle); //关闭句柄 return ; } int getwords(char *path, struct wordsdata **word)
{
FILE *fp;
int j = ;
int cmp = ;
int num = ; //计算首四位地址
char temp = ; //读取一个字符 ACSII 码值
int length = ; char present[] = ""; //存储当前单词 char address[] = "";
struct wordsdata *q = NULL;
struct wordsdata *pre = NULL;
struct wordsdata *neword = NULL;
struct wordsdata *now = NULL;
struct wordsdata *previous = NULL;
struct phrases *newphrase = NULL; if ((fp = fopen(path, "r")) == NULL)
{
//printf("error!!! \n", path);
return ;
}
linenum++;
while (temp != -)
{
//读取字符串
temp = fgetc(fp);
if (temp > && temp < )
charnum++;
if (temp == '\n' || temp == '\r')
linenum++; while ((temp >= '' && temp <= '') || (temp >= 'a' && temp <= 'z') || (temp >= 'A' && temp <= 'Z'))
{
if (length != - && length < )
{
if (temp >= 'A') //是字母
{
present[length] = temp;
address[length] = (temp >= 'a' ? (temp - 'a') : (temp - 'A'));
length++;
}
else //不是字母
length = -;
}
else if (length >= )
{
present[length] = temp;
length++;
}
temp = fgetc(fp);
if (temp > && temp < )
charnum++;
if (temp == '\n' || temp == '\r')
linenum++;
} // end while //判断是否为单词
if (length >= )
{
wordnum++; //计算首四位代表地址
num = address[] * + address[] * + address[] * + address[]; //插入当前单词
if (word[num] == NULL)
{
word[num] = new wordsdata;
neword = new wordsdata;
neword->number = ;
neword->next = NULL;
strcpy(neword->words, present);
word[num]->next = neword;
now = neword;
}
else
{
pre = word[num];
q = pre->next;
cmp = wordcmp(q->words, present); while (cmp == small)
{
pre = q;
q = q->next;
if (q != NULL)
cmp = wordcmp(q->words, present);
else
break;
}
if (q != NULL && cmp <= )
{
now = q;
q->number++;
if (cmp == )
strcpy(q->words, present);
} else
{
neword = new wordsdata;
neword->number = ;
strcpy(neword->words, present);
pre->next = neword;
neword->next = q;
now = neword;
}
} if (previous != NULL)
{
newphrase = new phrases; newphrase->one = previous->words;
newphrase->two = now->words; unordered_map<phrases, int>::const_iterator got = phrasemap.find( *newphrase);
if (got != phrasemap.end())
{
phrasemap[*newphrase]++;
}
else
{
phrasemap.insert(pair<phrases, int>(*newphrase, ));
}
}
previous = now; //当前单词置空
for (int j = ; present[j] && j < ; j++)
present[j] = ;
}
length = ;
} fclose(fp);
return ;
} int wordcmp(char *str1, char *str2)
{
char *p1 = str1;
char *p2 = str2;
char q1 = *p1;
char q2 = *p2; if (q1 >= 'a' && q1 <= 'z')
q1 -= ; if (q2 >= 'a' && q2 <= 'z')
q2 -= ; while (q1 && q2 && q1 == q2)
{
p1++;
p2++; q1 = *p1;
q2 = *p2; if (q1 >= 'a' && q1 <= 'z')
q1 -= ; if (q2 >= 'a' && q2 <= 'z')
q2 -= ;
} while (*p1 >= '' && *p1 <= '')
p1++;
while (*p2 >= '' && *p2 <= '')
p2++; if (*p1 == && *p2 == ) //两单词等价
return strcmp(str1, str2); //等价前者字典顺序小返回-1,大返回1,完全相等返回0 if (q1 < q2) //前者小
return ; if (q1 > q2) //后者小
return ; return ;
} int gettop(struct wordsdata **word)
{
int i = , j = ;
struct wordsdata *topw[] = {};
struct phrases *toph[] = {};
struct wordsdata *w = NULL;
FILE *fp;
fp = fopen("result.txt", "w");
fprintf(fp,"characters:%d \nwords:%d \nlines:%d\n", charnum,wordnum, linenum); for (j = ; j < ; j++)
{
toph[j] = new struct phrases;
toph[j]->num = ;
topw[j] = new struct wordsdata;
topw[j]->number = ;
}
for (i = ; i < ; i++)
{
if (word[i] != NULL)
{
w = word[i]->next;
while (w != NULL)
{
topw[]->number = w->number;
topw[]->next = w;
j = ;
while (j > && topw[j]->number > topw[j - ]->number)
{
topw[] = topw[j];
topw[j] = topw[j - ];
topw[j - ] = topw[];
j--;
}
w = w->next;
}
}
}
for (j = ; j < ; j++)
{
if (topw[j]->number)
fprintf(fp,"\n%s :%d", topw[j]->next->words, topw[j]->number);
}
for (Char_Phrase::iterator it = phrasemap.begin(); it != phrasemap.end(); it++)
{
toph[]->one = it->first.one;
toph[]->two = it->first.two;
toph[]->num = it->second;
j = ;
while (j > && toph[j]->num > toph[j - ]->num)
{
toph[] = toph[j];
toph[j] = toph[j - ];
toph[j - ] = toph[];
j--;
}
}
fprintf(fp, "\n");
for (j = ; j < ; j++)
{
if (toph[j]->num)
fprintf(fp,"\n%s %s :%d", toph[j]->one, toph[j]->two, toph[j]->num);
}
fclose(fp);
return ;
}
记一个男默女泪的 BUG的更多相关文章
- salesforce零基础学习(一百一十五)记一个有趣的bug
本篇参考:https://help.salesforce.com/s/articleView?language=en_US&type=1&id=000319486 page layou ...
- 记一个神奇的Bug
多年以后,当Abraham凝视着一行行新时代的代码在屏幕上川流不息的时候,他会想起2019年4月17日那个不平凡夜晚,以及在那个夜晚他发现的那个不可思议的Bug. 虽然像无数个普普通通的夜晚一样,我在 ...
- 【bug】记一个有趣的“bug”
产品经理在使用我们用户功能的是,需要查询一个用户,知道这个用户的id,我说支持模糊查询的. 他输入"余XX",点击查询,怎么都查不出这个用户. 我到用户表里确认,确实有这个ID的用 ...
- 记一个深层的bug
1. 业务场景 产品需要每隔几天进行一次组件的更新,在自动化测试中,每隔30s检测一次更新源上的某个文件MD5值是否与本地一致,不一致代表有更新的版本,开始更新. 2. 问题出现 一个再平常不过的繁忙 ...
- 记一个社交APP的开发过程——基础架构选型(转自一位大哥)
记一个社交APP的开发过程——基础架构选型 目录[-] 基本产品形态 技术选型 最近两周在忙于开发一个社交App,因为之前做过一点儿社交方面的东西,就被拉去做API后端了,一个人头一次完整的去搭这么一 ...
- 一个iOS6系统bug+一个iOS7系统bug
先看实际工作中遇到的两个bug:(1)iPhone Qzone有一个导航栏背景随着页面滑动而渐变的体验,当页面滑动到一定距离时,会改变导航栏上title文本的颜色,但是有一个莫名其妙的bug,如下:
- FIREDAC(DELPHI10 or 10.1)提交数据给ORACLE数据库的一个不是BUG的BUG
发现FIREDAC(DELPHI10 or 10.1)提交数据给ORACLE数据库的一个不是BUG的BUG,提交的表名大小写是敏感的. 只要有一个表名字母的大小写不匹配,ORACLE就会认为是一个不认 ...
- pycharm下: conda installation is not found ----一个公开的bug的解决方案
pycharm conda installation is not found ----一个公开的bug的解决方案 pycharm+anaconda 是当前的主流的搭建方案,但是常出现上述问题. ...
- 一个神奇的bug:OOM?优雅终止线程?系统内存占用较高?
摘要:该项目是DAYU平台的数据开发(DLF),数据开发中一个重要的功能就是ETL(数据清洗).ETL由源端到目的端,中间的业务逻辑一般由用户自己编写的SQL模板实现,velocity是其中涉及的一种 ...
随机推荐
- 关于vcruntime140D.dll丢失问题
电脑磁盘占用率100%,又检测出硬盘磁道坏了,要么装win7,要么换个SSD,无奈重装环境. 遇到这个问题,之前的电脑就遇到过,网上交的下载这个文件装到C盘Windows的SysWOW64,对于实验室 ...
- php第二节课
基础语法 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3 ...
- 填坑...P1546 最短网络 Agri-Net
P1546 最短网络 Agri-Net 难度普及/提高- 时空限制1s / 128MB 题目背景 农民约翰被选为他们镇的镇长!他其中一个竞选承诺就是在镇上建立起互联网,并连接到所有的农场.当然,他需要 ...
- 进程(day09)
进程的管理 一.进程的基础 进程和程序的区别 每个进程有自己的pid.PCB 操作系统上运行的所有进程构成一颗树. 如何查看这颗树? pstree() 树根进程是init pid是 进程间的亲缘关系两 ...
- 如何使用qtp12 utf进行功能测试
首先,按照本博客的安装教程走的,右键管理员运行 接下来点击继续,这个界面只需要勾选到web即可 点击ok,开始运行 进入到主界面之后,file新建一个测试. 可以修改路径等等 点击create之后,出 ...
- Python中的sorted() 和 list.sort() 的用法总结
只要是可迭代对象都可以用sorted . sorted(itrearble, cmp=None, key=None, reverse=False) =号后面是默认值 默认是升序排序的, 如果想让结果降 ...
- Tomcat日志配置远程Syslog采集
http://blog.csdn.net/leizi191110211/article/details/51593748
- Java设计模式菜鸟系列(十五)建造者模式建模与实现
转载请注明出处:http://blog.csdn.net/lhy_ycu/article/details/39863125 建造者模式(Builder):工厂类模式提供的是创建单个类的模式.而建造者模 ...
- php 在同一个表单中加入和改动
大家写站点的时候可能都会遇到这样的情况,就是写一个表单,这个表单是用来加入一篇文章的,我们屁颠屁颠的在后台接收数据,然后存入数据库.如今有个问题.当你要对该文章进行改动的时候,你是怎么处理的? 我的方 ...
- Qt5.8 提供 Apple tvOS,watchOS的技术预览版
New Platforms Apple tvOS (technology preview) Apple watchOS (technology preview) https://wiki.qt.io/ ...