NIO提升系统性能
- 前言
在软件系统中,I/O的速度要比内存的速度慢很多,因此I/O经常会称为系统的瓶颈。所有,提高I/O速度,对于提升系统的整体性能有很大的作用。
在java标准的I/O中,是基于流的I/O的实现,即InputStream和OutPutStream,这种基于流的实现以字节为基本单元,很容易实现各种过滤器。
NIO和new I/O的简称,在java1.4纳入JDK中,具有以下特征:
1、为所有的原始类型提供(buffer)缓存支持;
2、使用Charset作为字符集编码解码解决方案;
3、增加了通道(Channel)对象,作为新的原始I/O抽象;
4、支持锁和内存访问文件的文件访问接口;
5、提供了基于Selector的异步网络I/O;
NIO是基于块(Block)的,它以块为基本单位处理数据。在NIO中,最重要的两个组件是buffer缓冲和channel通道。缓冲是一块连续的内存区域,是NIO读写数据的中转站。通道表示缓冲数据的源头或目的地,它用于向缓冲读取或写入数据,是访问缓冲的接口。通道和缓冲的关系如图:
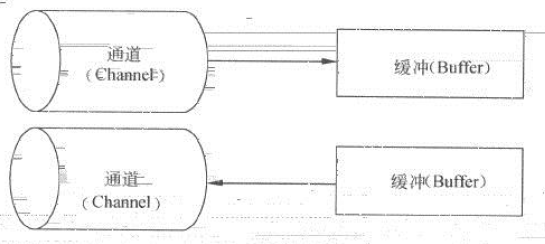
- NIO中的Buffer类和Channel
JDK为每一种java原生类型都提供了一种Buffer,除了ByteBuffer外,其他每一种Buffer都具有完全一样的操作,除了操作类型不一样以外。ByteBuffer可以用于绝大多数标准I/O操作的接口。
在NIO中和Buffer配合使用的还有Channel。Channel是一个双向通道,既可以读也可以写。有点类似Stream,但是Stream是单向的。应用程序不能直接对Channel进行读写操作,而必须通过Buffer来进行。
下面以一个文件复制为例,简单介绍NIO的Buffer和Channel的用法,代码如下:
- public class NioCopyFileTest {
- public static void main(String[] args) throws Exception {
- NioCopyFileTest.copy("test.txt", "test2.txt");
- }
- public static void copy(String resource,String destination) throws Exception{
- FileInputStream fis = new FileInputStream(resource);
- FileOutputStream fos = new FileOutputStream(destination);
- FileChannel inputFileChannel = fis.getChannel();//读文件通道
- FileChannel outputFileChannel = fos.getChannel();//写文件通道
- ByteBuffer byteBuffer = ByteBuffer.allocate(1024);//读写数据缓冲
- while(true){
- byteBuffer.clear();
- int length = inputFileChannel.read(byteBuffer);//读取数据
- if(length == -1){
- break;//读取完毕
- }
- byteBuffer.flip();
- outputFileChannel.write(byteBuffer);//写入数据
- }
- inputFileChannel.close();
- outputFileChannel.close();
- }
- }
代码中注释写的很详细了,输入流和输出流都对应一个Channel通道,将数据通过读文件channel读取到缓冲中,然后再通过写文件channel写入到缓冲中。这样就完成了文件复制。注意:缓冲在文件传输中起到的作用十分大,可以缓解内存和硬盘之间的性能差异,提升系统性能。
- Buffer的基本原理
Buffer有三个重要的参数:位置(position)、容量(capactiy)和上限(limit)。这三个参数的含义如下图:
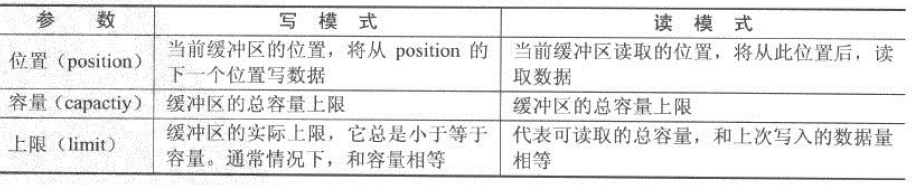
下面例子很好的解释了Buffer的工作原理:
- ByteBuffer buffer = ByteBuffer.allocate(15);//设置缓冲区大小为15
- System.out.println("position:"+buffer.position()+"limit:"+buffer.limit()+"capacity"+buffer.capacity());
- for (int i = 0; i < 10; i++) {
- buffer.put((byte) i);
- }
- System.out.println("position:"+buffer.position()+"limit:"+buffer.limit()+"capacity"+buffer.capacity());
- buffer.flip();//重置position
- for (int i = 0; i < 5; i++) {
- System.out.println(buffer.get());
- }
- System.out.println("position:"+buffer.position()+"limit:"+buffer.limit()+"capacity"+buffer.capacity());
- buffer.flip();
- System.out.println("position:"+buffer.position()+"limit:"+buffer.limit()+"capacity"+buffer.capacity());
以上代码,先分配了15个字节大小的缓冲区。在初始阶段,position为0,capacity为15,limit为15。注意,position是从0开始的,所以索引为15的位置实际上是不存在的。
接着往缓冲区放入10个元素,position始终指向下一个即将放入的位置,所有position为10,capacity和limit依然为15。
进行flip()操作,会重置position的位置,并且将limit设置到当前position的位置,这时Buffer从写模式进入读模式,这样就可以防止读操作读取到没有进行操作的位置。所有此时,position为0,limit为10,capacity为15。
接着进行五次读操作,读操作会设置position的位置,所以,position为5,limit为10,capacity为15。
在进行一次flip()操作,此时可想而知position为0,limit为5,capacity为15。
- Buffer的相关操作
Buffer是NIO中最核心的对象,它的一系列的操作和使用也需要重点掌握,这里简单概括一下,也可以参考相关API查看。
1、Buffer的创建:
buffer的常见有两种方式,使用静态方法allocate()从堆中分配缓冲区,或者从一个既有数组中创建缓冲区。
- ByteBuffer buffer = ByteBuffer.allocate(1024);//从堆中分配
- byte[] arrays = new byte[1024];//从既有数组中创建
- ByteBuffer buffer2 = ByteBuffer.wrap(arrays);
2、重置或清空缓冲区:
buffer还提供了一些用于重置和清空缓冲区的方法:rewind(),clear(),flip()。它们的作用如下:

3、读写缓冲区:
对Buffer对象进行读写操作是Buffer最重要的操作,buffer提供了许多读写操作的缓冲区。具体参考API。
4、标志缓冲区
标志(mark)缓冲区是一个在数据处理时很有用的功能,它就像书签一样,可以在数据处理中随时记录当前位置,然后再任意时刻回到这个位置,从而简化或加快数据处理的流程。相关函数为:mark()和reset()。mark()用于记录当前位置,reset()用于恢复到mark标记的位置。
代码如下:
- ByteBuffer buffer = ByteBuffer.allocate(15);//设置缓冲区大小为15
- for (int i = 0; i < 10; i++) {
- buffer.put((byte) i);
- }
- buffer.flip();//重置position
- for (int i = 0; i < buffer.limit(); i++) {
- System.out.print(buffer.get());
- if(i==4){
- buffer.mark();
- System.out.print("mark at"+i);
- }
- }
- System.out.println();
- buffer.reset();
- while(buffer.hasRemaining()){
- System.out.print(buffer.get());
- }
输出结果:
- 01234mark at456789
- 56789
5、复制缓冲区
复制缓冲区是以原缓冲区为基础,生成一个完全一样的缓冲区。方法为:duplicate()。这个函数对于处理复杂的Buffer数据很有好处。因为新生成的缓冲区和元缓冲区共享相同的内存数据。并且,任意一方的改动都是互相可见的,但是两者又各自维护者自己的position、limit和capacity。这大大增加了程序的灵活性,为多方同时处理数据提供了可能。
代码如下:
- ByteBuffer buffer = ByteBuffer.allocate(15);//设置缓冲区大小为15
- for (int i = 0; i < 10; i++) {
- buffer.put((byte) i);
- }
- ByteBuffer buffer2 = buffer.duplicate();//复制当前缓冲区
- System.out.println("after buffer duplicate");
- System.out.println(buffer);
- System.out.println(buffer2);
- buffer2.flip();
- System.out.println("after buffer2 flip");
- System.out.println(buffer);
- System.out.println(buffer2);
- buffer2.put((byte)100);
- System.out.println("after buffer2 put");
- System.out.println(buffer.get(0));
- System.out.println(buffer2.get(0));
输出结果如下:
- after buffer duplicate
- java.nio.HeapByteBuffer[pos=10 lim=15 cap=15]
- java.nio.HeapByteBuffer[pos=10 lim=15 cap=15]
- after buffer2 flip
- java.nio.HeapByteBuffer[pos=10 lim=15 cap=15]
- java.nio.HeapByteBuffer[pos=0 lim=10 cap=15]
- after buffer2 put
- 100
- 100
6、缓冲区分片
缓冲区分片使用slice()方法,它将现有的缓冲区创建新的子缓冲区,子缓冲区和父缓冲区共享数据,子缓冲区具有完整的缓冲区模型结构。当处理一个buffer的一个片段时,可以使用一个slice()方法取得一个子缓冲区,然后就像处理普通缓冲区一样处理这个子缓冲区,而无需考虑边界问题,这样有助于系统模块化。
- ByteBuffer buffer = ByteBuffer.allocate(15);//设置缓冲区大小为15
- for (int i = 0; i < 10; i++) {
- buffer.put((byte) i);
- }
- buffer.position(2);
- buffer.limit(6);
- ByteBuffer subBuffer = buffer.slice();//复制缓冲区
- for (int i = 0; i < subBuffer.limit(); i++) {
- byte b = subBuffer.get(i);
- b=(byte) (b*10);
- subBuffer.put(i, b);
- }
- buffer.limit(buffer.capacity());
- buffer.position(0);
- for (int i = 0; i < buffer.limit(); i++) {
- System.out.print(buffer.get(i)+" ");
- }
输出结果:
- 0 1 20 30 40 50 6 7 8 9 0 0 0 0 0
7、只读缓冲区
可以使用缓冲区对象的asReadOnlyBuffer()方法得到一个与当前缓冲区一致的,并且共享内存数据的只读缓冲区,只读缓冲区对于数据安全非常有用。使用只读缓冲区可以保证数据不被修改,同时,只读缓冲区和原始缓冲区是共享内存块的,因此,对于原始缓冲区的修改,只读缓冲区也是可见的。
代码如下:
- ByteBuffer buffer = ByteBuffer.allocate(15);//设置缓冲区大小为15
- for (int i = 0; i < 10; i++) {
- buffer.put((byte) i);
- }
- ByteBuffer readBuffer = buffer.asReadOnlyBuffer();
- for (int i = 0; i < readBuffer.limit(); i++) {
- System.out.print(readBuffer.get(i)+" ");
- }
- System.out.println();
- buffer.put(2, (byte)20);
- for (int i = 0; i < readBuffer.limit(); i++) {
- System.out.print(readBuffer.get(i)+" ");
- }
结果:
- 0 1 2 3 4 5 6 7 8 9 0 0 0 0 0
- 0 1 20 3 4 5 6 7 8 9 0 0 0 0 0
由此可见,只读缓冲区并不是原始缓冲区在某一时刻的快照,而是和原始缓冲区共享内存数据的。当修改只读缓冲区时,会报ReadOnlyBufferException异常。
8、文件映射到内存:
NIO提供了一种将文件映射到内存的方法进行I/O操作,它可以比常规的基于流的I/O快很多。这个操作主要是由FileChannel.map()方法实现的。
使用文件映射的方式,将文本文件通过FileChannel映射到内存中。然后在内存中读取文件内容。还可以修改Buffer,将实际数据写到对应的硬盘中。
- RandomAccessFile raf = new RandomAccessFile("D:\\test.txt", "rw");
- FileChannel fc = raf.getChannel();
- MappedByteBuffer mbf = fc.map(MapMode.READ_WRITE, 0, raf.length());//将文件映射到内存
- while(mbf.hasRemaining()){
- System.out.println(mbf.get());
- }
- mbf.put(0,(byte)98);//修改文件
- raf.close();
9、处理结构化数据
NIO还提供了处理结构化数据的方法,称为散射和聚集。散射是将一组数据读入到一组buffer中,聚集是将数据写入到一组buffer中。聚集和散射的基本使用方法和对单个buffer操作的使用方法类似。这一组缓冲区类似于一个大的缓冲区。
散射/聚集IO对处理结构化数据非常有用。例如,对于一个具有固定格式的文件的读写,在已知文件具体结构的情况下,可以构造若干个符合文件结构的buffer,使得各个buffer的大小恰好符合文件各段结构的大小。
例如,将"姓名:张三,年龄:18",通过聚集写创建该文件,然后再通过散射都来解析。
- ByteBuffer nameBuffer = ByteBuffer.wrap("姓名:张三,".getBytes("utf-8"));
- ByteBuffer ageBuffer = ByteBuffer.wrap("年龄:18".getBytes("utf-8"));
- int nameLength = nameBuffer.limit();
- int ageLength = ageBuffer.limit();
- ByteBuffer[] bufs = new ByteBuffer[]{nameBuffer,ageBuffer};
- File file = new File("D:\\name.txt");
- if(!file.exists()){
- file.createNewFile();
- }
- FileOutputStream fos = new FileOutputStream(file);
- FileChannel channel = fos.getChannel();
- channel.write(bufs);
- channel.close();
- ByteBuffer nameBuffer2 = ByteBuffer.allocate(nameLength);
- ByteBuffer ageBuffer2 = ByteBuffer.allocate(ageLength);
- ByteBuffer[] bufs2 = new ByteBuffer[]{nameBuffer2,ageBuffer2};
- FileInputStream fis = new FileInputStream("D:\\name.txt");
- FileChannel channel2 = fis.getChannel();
- channel2.read(bufs2);
- String name = new String(bufs2[0].array(),"utf-8");
- String age = new String(bufs2[1].array(),"utf-8");
- System.out.println(name+age);
通过和通道的配合使用,可以简化Buffer对于结构化数据处理的难度。
注意,ByteBuffer是将文件一次性读入内存再做处理,而Stream方式则是边读取文件边处理数据,这也是两者性能差异的主要原因。
- 直接内存访问
NIO的Buffer还提供了一个可以直接访问系统物理内存的类--DirectBuffer。普通的ByteBuffer依然在JVM堆上分配空间,其最大内存,受最大堆的限制。而DirecBuffer直接分配在物理内存中,并不占用堆空间。创建DirectBuffer的方法是:ByteBuffer.allocateDirect(capacity)。
在对普通的ByteBuffer的访问,系统总会使用一个"内核缓冲区"进行间接操作。而ByteBuffer所处的位置,就相当于这个"内核缓冲区"。因此,DirecBuffer是一种更加接近底层的操作。
DirectBuffer的访问速度远高于ByteBuffer,但是其创建和销毁所消耗的时间却远大于ByteBuffer。在需要频繁创建和销毁Buffer的场合,显然不适合DirectBuffer的使用,但是如果能将DirectBuffer进行复用,那么在读写频繁的场合下,它完全可以大幅度改善系统性能。
NIO提升系统性能的更多相关文章
- Java性能优化之使用NIO提升性能(Buffer和Channel)
在软件系统中,由于IO的速度要比内存慢,因此,I/O读写在很多场合都会成为系统的瓶颈.提升I/O速度,对提升系统整体性能有着很大的好处. 在Java的标准I/O中,提供了基于流的I/O实现,即Inpu ...
- 使用NIO提升性能
NIO是New I/O的简称,与旧式的基于流的I/O方法相对,从名字看,它表示新的一套Java I/O标准. 具有以下特性: 传统Java IO,它是阻塞的,低效的.那么Java NIO和传统Java ...
- 使用 HTTP 缓存机制提升系统性能
摘要 HTTP缓存机制定义在HTTP协议标准中,被现代浏览器广泛支持,同时也是一个用于提升基于Web的系统性能的广泛使用的工具.本文讨论如何使用HTTP缓存机制提升基于Web的系统,以及如何避免误用. ...
- mysql数据库 ,java 代码巧妙结合提升系统性能。
查询频繁的表t_yh_transport_task 保证数据量最少,增加查询效率, 常用于查询的字段增加索引, 每日定时移动数据 <!-- 医院系统预约任务历史删除定时器 --> & ...
- Linux新内核:提升系统性能 --Linux运维的博客
http://blog.csdn.net/linuxnews/article/details/52864182
- 异步并发利器:实际项目中使用CompletionService提升系统性能的一次实践
场景 随着互联网应用的深入,很多传统行业也都需要接入到互联网.我们公司也是这样,保险核心需要和很多保险中介对接,比如阿里.京东等等.这些公司对于接口服务的性能有些比较高的要求,传统的核心无法满足要求, ...
- 实际项目中使用CompletionService提升系统性能的一次实践
随着互联网应用的深入,很多传统行业也都需要接入到互联网.我们公司也是这样,保险核心需要和很多保险中介对接,比如阿里.京东等等.这些公司对于接口服务的性能有些比较高的要求,传统的核心无法满足要求,所以信 ...
- 从 Linux 内核角度探秘 JDK NIO 文件读写本质
1. 前言 笔者在 <从 Linux 内核角度看 IO 模型的演变>一文中曾对 Socket 文件在内核中的相关数据结构为大家做了详尽的阐述. 又在此基础之上介绍了针对 socket 文件 ...
- 5种调优Java NIO和NIO.2的方式
Java NIO(New Input/Output)——新的输入/输出API包——是2002年引入到J2SE 1.4里的.Java NIO的目标是提高Java平台上的I/O密集型任务的性能.过了十年, ...
随机推荐
- AngularJS跨域请求
本文主要针对网上各种跨域请求的总结,并加入自己的验证判断,实现工作中遇到的跨域问题.所涉及到的领域很小,仅仅局限于:AngularJS CORS post 并同时需要实现json数据传送给服务器. 首 ...
- display:-webkit-box
Flexbox 为 display 属性赋予了一个新的值(即 box 值), flexbox的属性有很多,记录一些比较常用的属性: 用于父元素的样式: display: box; 该属性会将此元素及其 ...
- shell script 学习笔记-----标准输出
1.将标准输出(stdout)和标准错误输出(stderr)分别重定向到两个不同的文件 其中符号'>'默认将标准输出重定向,意思和'1>'相同,‘2>'表示重定向标准错误输出,数字1 ...
- 边工作边刷题:70天一遍leetcode: day 82
Closest Binary Search Tree Value 要点: https://repl.it/CfhL/1 # Definition for a binary tree node. # c ...
- 一个CentOS7的开发环境部署,包括防火墙|VPN|多IP多网关|HTTP代理服务器设置等
http://www.lenggirl.com/code/centos7.html layout: post title: "一个CentOS7的开发环境部署,包括防火墙|VPN|HTTP代 ...
- HDU 3081 最大流+并查集
题意:有n个男生和n个女生,玩结婚游戏,由女生选择男生:女生可以选择不会和她吵架的男生以及不会和她闺蜜吵架的男生,闺蜜的闺蜜也是闺蜜.问你最多可以进行多少轮,每一轮每个女生只能选择一个之前她没选过的男 ...
- XUtils===XUtils3框架的基本使用方法
转载自:http://blog.csdn.NET/a1002450926/article/details/50341173 今天给大家带来XUtils3的基本介绍,本文章的案例都是基于XUtils3的 ...
- mysql学习书籍推荐
1.<MySQL技术内幕:SQL编程>2.<高性能MySQL>3.<MySQL技术内幕>4. mysql技术内幕.innodb存储引擎
- Java中是否可以继承String类,为什么
Java中,是否可以继承String类?为什么? 答案: 不可以,因为String类有final修饰符,而final修饰的类是不能被继承的,实现细节不允许改变. public final class ...
- [转]World Wind学习总结一
WW的纹理,DEM数据,及LOD模型 以earth为例 1. 地形数据: 默认浏览器纹理数据存放在/Cache/Earth/Images/NASA Landsat Imagery/NLT Landsa ...