LSTM网络(Long Short-Term Memory )
本文基于前两篇 1. 多层感知机及其BP算法(Multi-Layer Perceptron) 与 2. 递归神经网络(Recurrent Neural Networks,RNN)
RNN 有一个致命的缺陷,传统的 MLP 也有这个缺陷,看这个缺陷之前,先祭出 RNN 的 反向传导公式与 MLP 的反向传导公式:
\[RNN : \ \delta_h^t = f'(a_h^t) \left (\sum_k\delta_k^tw_{hk} + \sum_{h'} \delta^{t+1}_{h'}w_{hh'} \right )\]
\[MLP : \ \delta_h = f'(a_h) \sum_{h'=1}^{h_{l+1}} w_{hh'}\delta_{h'}\]
注意,残差在时间维度上反向传递时,每经过一个时刻,就会导致信号的大幅度衰减,为啥呢,就是因为这个非线性激活函数 $f$ ,一般这个函数的形状如下图:
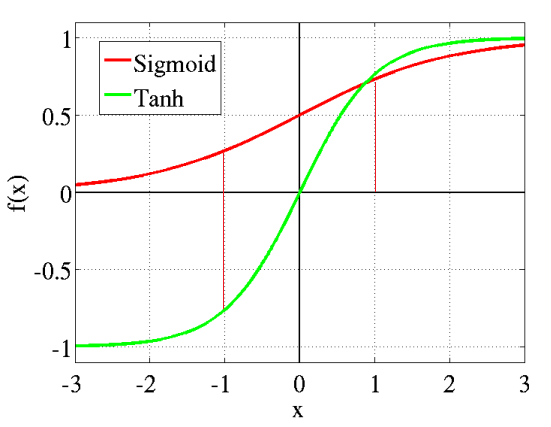
如上图所示,激活函数 $f$ 在在红线以外的斜度变化很小,所以函数 $f$ 的导数 $f'$ 取值很小,而经过以上列出的残差反向传递公式可以得出,每经过一个时刻,衰减 $f'$ 的数量级,所以经过多个时刻会导致时间维度上梯度呈指数级的衰减,即此刻的反馈信号不能影响太遥远的过去 。在 MLP 中,如果网络太深,这种梯度衰减会导致网络的前几层的残差趋近于 0 ,这意味着前面的隐藏层中的神经元学习速度要慢于后面的隐藏层。无论 RNN 还是 MLP ,对参数的导数都是这种形式(RNN需要在时间维度上求和):
\[\frac{\partial O}{\partial w_{ij}} = \frac{\partial O}{\partial a_{j}} \frac{\partial a_j}{\partial w_{ij}} = \delta_jb_i\]
残差衰减的太小导致参数的导数太小 ,从而梯度下降法中前几层的参数只有微乎其微的变化,对于深层的 MLP 由于梯度衰减导致效果不如浅层的网络,对于 RNN 就会导致不能处理长期依赖的问题,虽然 RNN 理论上可以处理任意长度的序列,但实习应用中,RNN 很难处理长度超过 10 的序列。这种现象叫做 gradient vanishing/exploding 。下图形象的描绘了这种现象:
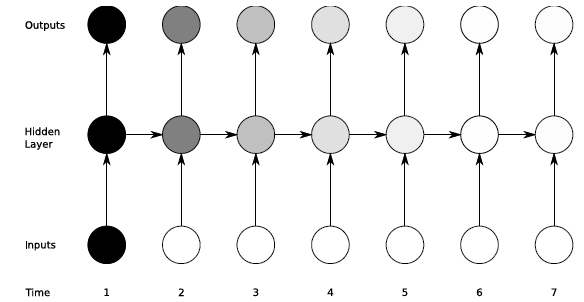
对于 $t=1$ 的输入,随着时间的推移,对于 $t >1$ 时刻的产生的影响会越来越小,由图中的颜色的深浅代表信号的大小。这种衰减会导致 RNN 无法处理长期依赖,举个例子,当有一句话“I grew up in France … I speak fluent French.” 在预测该人会将一口流利的 语时,会依赖之前他的长大的环境,而序列中两个词语的间隔太大,这便是所说的长期依赖问题。
对于长期以来问题,反向传播时,梯度也会呈指数倍数的衰减,这种衰减现象导致 RNN 无法处理长期依赖,为了克服 RNN 的这种缺陷,学者们研究了众多方法,其中 Long Short-Term Memory 表现最为出色。使用 LSTM 模块后,当误差从输出层反向传播回来时,可以使用模块的记忆元记下来。所以 LSTM 可以记住比较长时间内的信息。
初始的 LSTM (Hochreiter and Schmidhuber ,1997)网络结构类似于 RNN ,只是把 RNN 的隐层换成了存储块(memeory block),如下图左所示, memory block 中用记忆单元 (memory cell)来保存信息(类似于 RNN 中的隐藏节点),,每个存储块包含一个或多个memory cell ,如下图左中间的 “$\oslash$” 节点如下图所示,蓝色虚线为一条递归自连接的权值为 1 的边,保证梯度沿时间传播时不会损失,在时刻 $t$ 的输入如下图的 $g^t$ 所示,除接受本时刻的输入 $x^t$ 外,还接受上一时刻的输出 $h^{t-1}$ ,并且经过非线性激活函数 $\sigma$ ,LSTM 并不是接纳所有输入 $g^t$ ,而是在网络中加入两个门,输入门(input gate)、输出门(output gate), 门的节点数目与 memory cell 一一对应, input gate 如下图的 $i^t$ 所示,跟输入层一样,接受 $x^t$ 与 $h^{t-1}$ ,经过 $\sigma$ 后产生一个 0-1 向量(维度即为 memory cell 或者 input gate 的维度),0 代表关闭 、1 代表开启,这样来对输入进行控制,下图左中的 “$\prod$ ” 表示 input gate 的输出 $i^t$ 与本时刻输入 $g^t$ 的输出逐元素相乘,即 input gate 会对输入进行过滤 ,然后存放到 memory cell 里,现在memory cell 里既有上一时刻 $t-1$ 的状态,又添加了时刻 $t$ 的状态, 即
\[s^t = g^t \odot i^t + s^{t-1}\]
memory cell 有一个循环自连接的权值为 1 的边,这样 memory cell state 中梯度沿时间传播时不会导致不会 vanishing 或者 exploding ,output gate 类似于 input gate 会产生一个 0-1 向量来控制 memory cell 到输出层的输出。即
\[ v^t = s^t \odot o^t \]
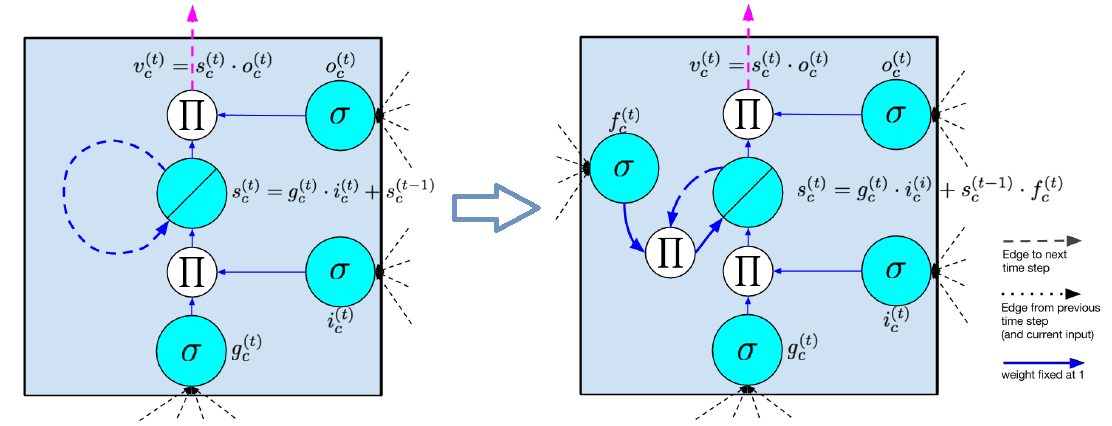
后来为了增强 LSTM 的处理能力, Gers et al. [2000] 引入了 forget gate, LSTM 的网络结构变成了如上图右所示,也就是说 forget gate 取代了之前权值为 1 的边,经过这样的改进,memory cell 可以遗忘之前的内容,只需将 memory cell 中的内容与 forget gate 逐元素相乘即可, forget gate 与 input/output gate 一样,接受 $x^t$ 与 $h^{t-1}$ 作为输入,现在的 LSTM memory cell 的更新公式为:
\[s^t = g^t \odot i^t + f^t \odot s^{t-1}\]
Gers & Schmidhuber [2000] 在以上结构的基础上又提出了 peephole connections ,将 $t-1$ 时刻没有经过 output gate 处理过的 memory cell 状态送到时刻 $t$ 作为 input gate 和 output gate 的输入,即三个门的输入增加了了 $s^ {t-1}$ ,现在流行的网络结构如下图所示:
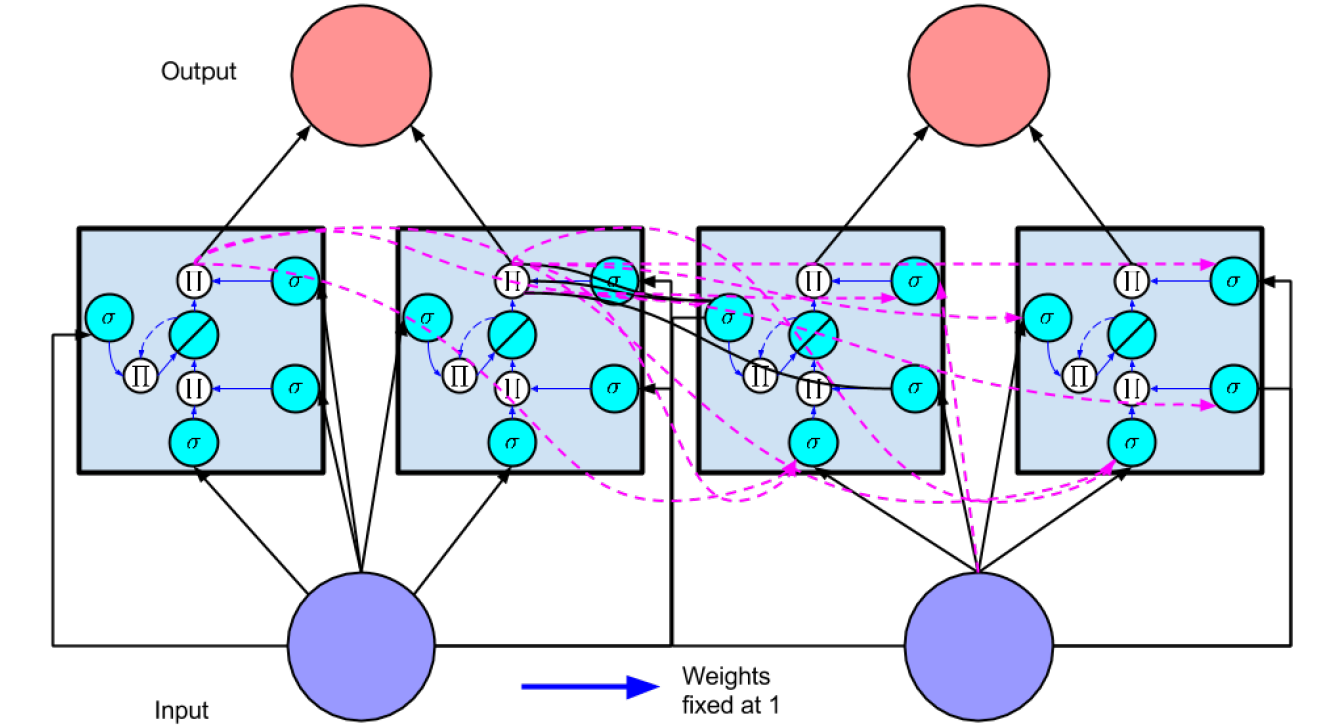
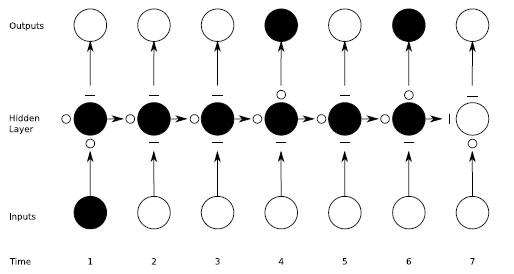
三个门协作使得 LSTM 存储块可以存取长期信息,比如说只要输入门保持关闭,记忆单元的信息就不会被之后时刻的输入所覆盖。下图形象的描述了这个过程,在 Hidden Layer 中每个节点都是一个 memeory block ,每个 memeory block 的包含三个门,左边为 forget gate ,下边尾 input gate ,上边为 output gate ,门有打开关闭两种状态,分别由 "$\bigcirc $" 与 "$-$" 来表示。可见对于时刻 1 的输入,只要之后时刻的 input gate 保持关闭,forget gate 保持打开,便可以在不影响 memory cell 的情况下随时开启 output gate 来获得 memory cell 的内容。对于梯度反向传播时,同样可以通过这种方式来保持残差不会过度衰减。
接下来本文所涉及的将是详细 LSTM 的 BP 过程,网络结构采用的是 Gers & Schmidhuber [2000]所提出的 LSTM 结构,值得注意的是,这里对 memory cell 的输出增加了激活函数 $h$ , 之前的 $h$ 可以理解为线性的,这里先声明一些符号表示: $w_{ij}$ 表示 单元 $i$ 到单元 $j$ 的权值,$a_j^t$ 表示时刻 $t$ 单元 $j$ 的输入,$b_j^t = f(a_j^t)$ 表示对单元 $j$ 的输入做非线性映射,$\iota$ 、 $\phi$ 、 $\omega$ 分别代表 input gate 、forget gate、 output gate ,$C$ 用来表示 memroy cell 的数量, $s^t_c$ 表示 memeory cell $c$ 在时刻 $t$ 的状态, $f$ 表示门的激活函数(通常为 $sigmod$ 函数), $g$ 与 $h$ 分别表示 memory cell 输入与输出的激活函数,用 $I$ 表示输入层大小, $H$ 表示隐层 memory cell 的大小(其实 $H = C$,这里只是为了方便表示,因为 memory cell 的输出 $b_h^t$ 会往下个时刻传输,其权值可表示为 $w_{h.}$ , memrory cell 本身的权值可用 $w_ {c.}$ 来表示) , $K$ 表示输出层的大小。 待序列为 $t = 1...T$ ,时刻 $t$ 的输入为 $x^t$ ,注意 $b^0 = 0$ , 残差 $\delta ^{T+1} = 0$ 。
- forget gate : 在 LSTM 的 memory block 中,只有上一时刻 memory cell 的输出 $ b_h^t$ 会传送到本单元 ,其他数据比如 memory cell state 或者 memory cell input 等只在单元内部可见,forget gate 是用来控制上个时刻的 memory cell state 即 $s^{t-1}$ :
\[a^t_{\phi } = \sum_iw_{i \phi } x_i^t + \sum_hw_{h \phi}b_{h}^{t-1}+ \sum_cw_{c\phi}s_c^{t-1} \]
\[b_{\phi }^t = f(a_{\phi}^t)\]
- input gate : 这个门控制当前时刻 memory cell state 的输入:
\[a^t_{\iota } = \sum_iw_{i \iota } x_i^t + \sum_hw_{h \iota}b_{h}^{t-1}+ \sum_cw_{c\iota}s_c^{t-1} \]
\[b_{\iota }^t = f(a_{\iota}^t)\]
- memory cell : 对于时刻 $t-1 \rightarrow t$ , memroy cell 的信息是这样变化的 ,首先对 $t-1$ 时刻 memory cell 的状态用 forget gate 进行过滤($b_{\phi}^t s_c^{t-1}$),看要遗忘或者保存哪些信息,然后获取现在时刻 $t$ 的输入信息($g(a_c^t)$),用 input gate 进行过滤 ($b_{\iota }^tg(a_c^t)$),过滤完后相加就完成了$t-1 \rightarrow t$ 时刻的 memory cell 状态的转变 :
\[a^t_c = \sum_i w_{ic} x_i^t + \sum_h w_{hc}b_{h}^{t-1} \]
\[s_c^t = b_{\phi}^t s_c^{t-1} + b_{\iota }^tg(a_c^t)\]
- output gate : 这个门会控制 cell state 的输出:
\[a^t_{\omega } = \sum_iw_{i \omega } x_i^t + \sum_hw_{h \omega }b_{h}^{t-1}+ \sum_cw_{c\omega }s_c^{t} \]
\[b_{\omega }^t = f(a_{\omega }^t)\]
- memory cell output : 计算 memory cell 的输出 ,由 output gate 控制,这个输出也会作为下一时刻整个 memory block 的输入(类似于 RNN 的隐层传递)
\[b_c^t = b_{\omega}^t h(s_c^t)\]
接下来便是残差的反向传导,对于输出层,同 RNN 一般是 $softmax$ 或者 $logistic$ ,这里首先定义:
\[\epsilon_c^t=\frac{\partial O}{\partial b_c^t}=\sum_k\frac{\partial O}{\partial a_k^t} \frac{\partial a_k^t}{\partial b_c^t}+\sum_{h}\frac{\partial O}{\partial a_h^t} \frac{\partial a_h^t}{\partial b_c^t}=\sum_{k} w_{ck}\delta_k^t+\sum_hw_{ch}\delta_h^{t+1} \]
接下来,残差传导至 output gate :
\[\delta_\omega^t=\frac{\partial O}{\partial a_\omega^t}=\sum_c \frac{\partial O}{\partial b_c^t}\frac{\partial b_c^t}{\partial b_\omega^t}\frac{\partial b_\omega^t}{\partial a_\omega^t} =f'(a_\omega^t)\sum_c \epsilon_c^t h(s_c^t) \]
现在再定义一个辅助变量:
\[\epsilon_s^t=\frac{\partial \mathcal{L}}{\partial s_c^t}
=\frac{\partial O}{\partial b_c^t} \frac{\partial b_c^t}{\partial h(s_c^t)} \frac{\partial h(s_c^t)}{\partial s_c^t}
+\frac{\partial O}{\partial s_c^{t+1}} \frac{\partial s_c^{t+1}}{\partial s_c^t}
+\frac{\partial O}{\partial a_\omega^t} \frac{\partial a_\omega^t}{\partial s_c^t}
+\frac{\partial O}{\partial a_\iota^t} \frac{\partial a_\iota^t}{\partial s_c^t}
+\frac{\partial O}{\partial a_\phi^t} \frac{\partial a_\phi^t}{\partial s_c^t} \Rightarrow\]
\[\epsilon_s^t=b_w^th'(s_c^t)\epsilon_c^t+b_\phi^{t+1}\epsilon_s^{t+1}+w_{c\omega}\delta_\omega^t+w_{c\iota}\delta_\iota^{t+1} +w_{c\phi}\delta_\phi^{t+1}\]
这就是 bp 中最复杂的公式了,依次解释下各项。首先,看memory block的图,查看该单元指向输出单元的所有路径,没有一条不同的路径就代表一项;然后运用链式法则展开每个路径;就得到后向传播中该单元的梯度$\delta$。这个辅助变量中可以看到后三项来自于cell state 对三个 gate 的监督,即 peephole ,所以若不采用 peephole 的方式就可以省略。第二项来自于下一时刻的状态误差,其实是 forget gate 对当前状态的调节作用。
接下来误差传播到 memory cell :
\[\delta_c^t =\frac{\partial O}{\partial a_c^t}=\frac{\partial O}{\partial s_c^t}\frac{\partial s_c^t}{\partial g(a_c^t)}\frac{\partial g(a_c^t)}{\partial a_c^t}=\epsilon_c^t b_\iota^t g'(a_c^t)\]
最后分别传导至 forget gate $\phi$ 与 输入门 $\iota$:
\[\delta_\phi^t =\frac{\partial O}{\partial a_\phi^t}=\sum_c\frac{\partial O}{\partial s_c^t}\frac{\partial s_c^t}{\partial b_\phi^t}\frac{\partial b_\phi^t}{\partial a_\phi^t}=f'(a_\phi^t)\sum_c s_c^{t-1}\epsilon_s^t \]
\[\delta_\iota^t =\frac{\partial O}{\partial a_\iota^t}=\sum_c\frac{\partial O}{\partial s_c^t}\frac{\partial s_c^t}{\partial b_\iota^t}\frac{\partial b_\iota^t}{\partial a_\iota^t}=f'(a_\iota^t)\sum_c g(a_c^{t-1})\epsilon_s^t\]
残差传导完成后,直接用残差对权重 $w_{ij}$ 进行求导即可 (这里 $b_i^t$ 可代表输入 $x_i^t$、$b_h^{t-1}$、$s_c^{t-1}$):
\[\frac{\partial O}{\partial w_{ij}} = \sum_t \frac{\partial O}{\partial a_j^t}\frac{\partial a_j^t}{\partial w_{ij}} = \sum_t \delta_j^tb_i^t\]
参考:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Supervised Sequence Labelling with Recurrent Neural Networks
http://ethancao.cn/2015/12/07/learning-LSTM.html
LSTM网络(Long Short-Term Memory )的更多相关文章
- LSTM学习—Long Short Term Memory networks
原文链接:https://colah.github.io/posts/2015-08-Understanding-LSTMs/ Understanding LSTM Networks Recurren ...
- LSTM(Long Short Term Memory)
长时依赖是这样的一个问题,当预测点与依赖的相关信息距离比较远的时候,就难以学到该相关信息.例如在句子”我出生在法国,……,我会说法语“中,若要预测末尾”法语“,我们需要用到上下文”法国“.理论上,递归 ...
- [译] 理解 LSTM(Long Short-Term Memory, LSTM) 网络
本文译自 Christopher Olah 的博文 Recurrent Neural Networks 人类并不是每时每刻都从一片空白的大脑开始他们的思考.在你阅读这篇文章时候,你都是基于自己已经拥有 ...
- [深度学习]理解RNN, GRU, LSTM 网络
Recurrent Neural Networks(RNN) 人类并不是每时每刻都从一片空白的大脑开始他们的思考.在你阅读这篇文章时候,你都是基于自己已经拥有的对先前所见词的理解来推断当前词的真实含义 ...
- Deep Learning基础--理解LSTM网络
循环神经网络(RNN) 人们的每次思考并不都是从零开始的.比如说你在阅读这篇文章时,你基于对前面的文字的理解来理解你目前阅读到的文字,而不是每读到一个文字时,都抛弃掉前面的思考,从头开始.你的记忆是有 ...
- 理解LSTM网络--Understanding LSTM Networks(翻译一篇colah's blog)
colah的一篇讲解LSTM比较好的文章,翻译过来一起学习,原文地址:http://colah.github.io/posts/2015-08-Understanding-LSTMs/ ,Posted ...
- RNN与 LSTM 网络
循环神经网络(RNN) 人们的每次思考并不都是从零开始的.比如说你在阅读这篇文章时,你基于对前面的文字的理解来理解你目前阅读到的文字,而不是每读到一个文字时,都抛弃掉前面的思考,从头开始.你的记忆是有 ...
- [译] 理解 LSTM 网络
原文链接:http://colah.github.io/posts/2015-08-Understanding-LSTMs/ 吴恩达版:http://www.ai-start.com/dl2017/h ...
- [转] 理解 LSTM 网络
[译] 理解 LSTM 网络 http://www.jianshu.com/p/9dc9f41f0b29 Recurrent Neural Networks 人类并不是每时每刻都从一片空白的大脑开始他 ...
随机推荐
- C# 中Newtonsoft.Json的安装和使用
官网参考:http://json.codeplex.com/ 在程序包管理控制台,键入NuGet命令 install-package Newtonsoft.Json 安装Newtonsoft.Js ...
- 初学Ajax(三)
$.ajax() $.ajax()是所有ajax方法中最底层的方法,所有其他方法都是基于$.ajax()方法的封装.这个方法只有一个参数,传递一个各个功能键值对的对象. $.ajax()方法对象参数表 ...
- jmeter中线程之间传递参数
JMeter 变量作用域局限于所属线程.这样设计是经过深思熟虑的,目的是让测试线程能够独立运转.有时候用户可能需要在不同线程间(可能属于同一个线程组,也可能不属于同一个线程组)传递变量. 其中一种方法 ...
- sql 数据库换行
制表符 CHAR(9) 换行符 CHAR(10) 回车 CHAR(13)
- Protobuf动态解析那些事儿
需求背景 在接收到 protobuf 数据之后,如何自动创建具体的 Protobuf Message 对象,再做反序列化.“自动”的意思主要有两个方面:(1)当程序中新增一个 protobuf Mes ...
- Android笔记——四大组件详解与总结
android四大组件分别为activity.service.content provider.broadcast receiver. ------------------------------- ...
- JavaWeb笔记——三大组件之监听器
1 JavaWeb监听器概述 在JavaWeb被监听的事件源为:ServletContext.HttpSession.ServletRequest,即三大域对象. l 监听域对象“创建”与“销毁”的 ...
- Android:开发环境
一.JAVA SDK(JDK)的安装 http://www.cnblogs.com/tinyphp/p/3664598.html 二.ADT-Bundle 包含了Eclipse.ADT插件和SDK T ...
- jsp中的out对象 和 servlet中的response.getOutputStream()
web容器生成的servlet代码中有out.write(””),这个和JSP中调用的response.getOutputStream()产生冲突. 即Servlet规范说明,不能既调用 respon ...
- Java 类加载器(转)
java虚拟机中可以安装多个类加载,系统默认三个主要类加载器,每个类负责加载特定位置的类:BootStrap(内嵌在java虚拟机中由C++编写),ExtClassLoader,AppClassLoa ...