QunInfo群数据库的还原与优化
一、 背景
这个数据库的数据文件mdf大概有8.5G左右,当还原数据库之后感觉可以做很多性能方面上的调优,合并数据后mdf数据文件大概有6.2G左右,行压缩后mdf数据文件大概有4.8G左右,页压缩后mdf数据文件大概有4.5G左右,这里处于技术研究的目的,讲讲研究的成果分析,不用于商业目的;
二、 优化项
我们可以从下面3个不同的方面来优化这两个数据库:
(一)对表进行分区;
(二)使用行压缩,压缩行数据;
(三)重新设计表结构,优化表空间;
三、 附加数据库
1.先把11个QunInfo(群信息)数据库附加到数据库,下面的导入SQL语句在原来的基础上做了些修改:统一数据库名,这样做的好处就是后面做处理的时候方便按照顺序执行数据库;
--附加数据库
EXEC sp_attach_db "QunInfo01", "D:\DBBackup\QunData\QunInfo1_Data.MDF"
EXEC sp_attach_db "QunInfo02", "D:\DBBackup\QunData\QunInfo2_Data.MDF"
EXEC sp_attach_db "QunInfo03", "D:\DBBackup\QunData\QunInfo3_Data.MDF"
EXEC sp_attach_db "QunInfo04", "D:\DBBackup\QunData\QunInfo4_Data.MDF"
EXEC sp_attach_db "QunInfo05", "D:\DBBackup\QunData\QunInfo5_Data.MDF"
EXEC sp_attach_db "QunInfo06", "D:\DBBackup\QunData\QunInfo6_Data.MDF"
EXEC sp_attach_db "QunInfo07", "D:\DBBackup\QunData\QunInfo7_Data.MDF"
EXEC sp_attach_db "QunInfo08", "D:\DBBackup\QunData\QunInfo8_Data.MDF"
EXEC sp_attach_db "QunInfo09", "D:\DBBackup\QunData\QunInfo9_Data.MDF"
EXEC sp_attach_db "QunInfo10", "D:\DBBackup\QunData\QunInfo10_Data.MDF"
EXEC sp_attach_db "QunInfo11",
"D:\DBBackup\QunData\QunInfo11_Data.MDF"
四、 合并数据库
2.修改各个数据库中表的名字:把QunList1统一修改为QunList01这样格式的,这样做的好处就是在合并数据的时候读取到的数据库的数据是按照顺序插入到表中的,不会造成数据页的拆分;
--格式化表名
USE QunInfo01
GO exec sp_rename 'QunList1','QunList01'
exec sp_rename 'QunList2','QunList02'
exec sp_rename 'QunList3','QunList03'
exec sp_rename 'QunList4','QunList04'
exec sp_rename 'QunList5','QunList05'
exec sp_rename 'QunList6','QunList06'
exec sp_rename 'QunList7','QunList07'
exec sp_rename 'QunList8','QunList08'
exec sp_rename 'QunList9','QunList09'
3.创建一个名为QunInfo的数据库,设置数据库为简单恢复模式;
4.在QunInfo数据库中创建一个临时表:tables,用来保存所有的数据库与表的信息,提供数据库合并用;
--创建临时表
CREATE TABLE [QunInfo].[dbo].[tables](
[db_name] [sysname] NULL,
[table_name] [sysname] NULL,
[status] [bit] default 0
) ON [PRIMARY] --生成数据库名称与表名称的对应列表
EXEC sp_MSForEachDB 'USE [?];
--插入表信息
INSERT INTO [QunInfo].[dbo].[tables]([table_name])
SELECT name from [?].sys.tables where name like ''QunList%'' order by name
--更新数据库名称
UPDATE [QunInfo].[dbo].[tables] SET [db_name] = ''?'' WHERE [db_name]
五、 优化数据库
5.经过评估,11个QunInfo数据库的QunList表数据的总和大概有9千万,QunList表中QunNum(群号)字段的最大值为100219998(可以通过QunInfo11数据库的QunList110表查询到:SELECT MAX(QunNum) FROM [QunInfo11].[dbo].[QunList110]),从业务的角度,可能需要查询某群的信息,所以这里就以QunNum作为分区,每1千万个群作为一个分区,这样计算那就需要11个文件组,如果你希望和GroupData数据库的Group表对齐的话,也可以按照5百万个群作为一个分区;
6.下面是一个创建分区脚本的SQL脚本,执行下面的SQL会生成一个新的脚本,执行那个脚本就可以创建11个文件组、分区函数和分区方案;
--生成分区脚本
DECLARE @DataBaseName NVARCHAR(50)--数据库名称
DECLARE @TableName NVARCHAR(50)--表名称
DECLARE @ColumnName NVARCHAR(50)--字段名称
DECLARE @PartNumber INT--分区最大编号
DECLARE @PartNumberBegin INT--分区编号开始值
DECLARE @PartNumberBeginTemp INT--分区编号开始值临时值
DECLARE @PartNumberStr NVARCHAR(50)--分区值字符串
DECLARE @Location NVARCHAR(50)--保存分区文件的路径
DECLARE @Size NVARCHAR(50)--分区初始化大小
DECLARE @FileGrowth NVARCHAR(50)--分区文件增量
DECLARE @FunValue INT--分区分段值增量
DECLARE @FunValueBegin INT--分区分段值开始值
DECLARE @i INT--临时变量
DECLARE @sql NVARCHAR(max) --设置下面变量
SET @DataBaseName = 'QunInfo'
SET @TableName = 'QunList'
SET @ColumnName = 'QunNum'
SET @PartNumber = 11
SET @PartNumberBegin = 1
SET @Location = 'D:\DBBackup\FG_QunList\'
SET @Size = '1024MB'
SET @FileGrowth = '1024MB'
SET @FunValueBegin = 10000000
SET @FunValue = 10000000 SET @sql = 'USE ['+@DataBaseName +']
GO'
PRINT @sql + CHAR(13) --1.创建文件组
SET @i = 1
SET @PartNumberBeginTemp = @PartNumberBegin
PRINT '--1.创建文件组'
WHILE @i <= @PartNumber
BEGIN
SET @PartNumberStr = RIGHT('' + CONVERT(NVARCHAR,@PartNumberBeginTemp),2)
SET @sql = 'ALTER DATABASE ['+@DataBaseName +']
ADD FILEGROUP [FG_'+@TableName+'_'+@ColumnName+'_'+@PartNumberStr+']'
PRINT @sql + CHAR(13)
SET @i=@i+1
SET @PartNumberBeginTemp = @PartNumberBeginTemp+1
END --2.创建文件
SET @i = 1
SET @PartNumberBeginTemp = @PartNumberBegin
PRINT CHAR(13)+'--2.创建文件'
WHILE @i <= @PartNumber
BEGIN
SET @PartNumberStr = RIGHT('' + CONVERT(NVARCHAR,@PartNumberBeginTemp),2)
SET @sql = 'ALTER DATABASE ['+@DataBaseName +']
ADD FILE
(NAME = N''FG_'+@TableName+'_'+@ColumnName+'_'+@PartNumberStr+'_data'',FILENAME = N'''+@Location+'FG_'+@TableName+'_'+@ColumnName+'_'+@PartNumberStr+'_data.ndf'',SIZE = '+@Size+', FILEGROWTH = '+@FileGrowth+' )
TO FILEGROUP [FG_'+@TableName+'_'+@ColumnName+'_'+@PartNumberStr+'];'
PRINT @sql + CHAR(13)
SET @i=@i+1
SET @PartNumberBeginTemp = @PartNumberBeginTemp+1
END --3.创建分区函数
PRINT CHAR(13)+'--3.创建分区函数'
DECLARE @FunValueStr NVARCHAR(MAX)
DECLARE @PNB INT
SET @i = 1
SET @PNB = 1
SET @FunValueStr = convert(NVARCHAR(50),@FunValueBegin) + ','
WHILE @i < @PartNumber-1
BEGIN
SET @FunValueStr = @FunValueStr + convert(NVARCHAR(50),(@FunValueBegin+@PNB*@FunValue)) + ','
SET @i=@i+1
SET @PNB=@PNB+1
END
SET @FunValueStr = substring(@FunValueStr,1,len(@FunValueStr)-1)
SET @sql = 'CREATE PARTITION FUNCTION
[Fun_'+@TableName+'_'+@ColumnName+'](INT) AS
RANGE RIGHT
FOR VALUES('+@FunValueStr+')'
PRINT @sql + CHAR(13) --4.创建分区方案
PRINT CHAR(13)+'--4.创建分区方案'
DECLARE @FileGroupStr NVARCHAR(MAX)
SET @i = 1
SET @PartNumberBeginTemp = @PartNumberBegin
SET @FileGroupStr = ''
WHILE @i <= @PartNumber
BEGIN
SET @PartNumberStr = RIGHT('' + CONVERT(NVARCHAR,@PartNumberBeginTemp),2)
SET @FileGroupStr = @FileGroupStr + '[FG_'+@TableName+'_'+@ColumnName+'_'+@PartNumberStr+'],'
SET @i=@i+1
SET @PartNumberBeginTemp = @PartNumberBeginTemp+1
END
SET @FileGroupStr = substring(@FileGroupStr,1,len(@FileGroupStr)-1)
SET @sql = 'CREATE PARTITION SCHEME
[Sch_'+@TableName+'_'+@ColumnName+'] AS
PARTITION [Fun_'+@TableName+'_'+@ColumnName+']
TO('+@FileGroupStr+')'
PRINT @sql + CHAR(13) --5.分区函数的记录数
PRINT CHAR(13)+'--5.分区函数的记录数'
SET @sql = 'SELECT $PARTITION.[Fun_'+@TableName+'_'+@ColumnName+']('+@ColumnName+') AS Partition_num,
MIN('+@ColumnName+') AS Min_value,MAX('+@ColumnName+') AS Max_value,COUNT(1) AS Record_num
FROM dbo.['+@TableName+']
GROUP BY $PARTITION.[Fun_'+@TableName+'_'+@ColumnName+']('+@ColumnName+')
ORDER BY $PARTITION.[Fun_'+@TableName+'_'+@ColumnName+']('+@ColumnName+');'
PRINT @sql + CHAR(13)
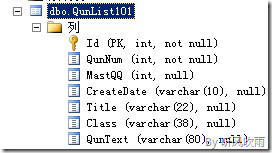
7.下面重新对QunList表进行设计,涉及的内容如下:
1) 在QunInfo数据库中创建分区表QunList,这里已经把原表的ID字段去掉了,这个字段并没有太大的意义;
2) 以[QunNum]作为聚集索引,而且是唯一的,这个需要开启IGNORE_DUP_KEY = ON选项,这样才可以在批量插入的时候忽略重复值;
3) 对原表的[MastQQ]字段从int类型变成smallint ,[CreateDate]字段从varchar(10)类型变为date,数据类型修改是为了减少表占用的空间,
4) 使用刚刚创建好的分区方案,之后创建的索引进行索引对齐;
5) 对表使用行压缩,减少数据库占用空间;
6) 对表进行页压缩会更节省空间?
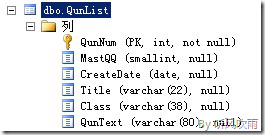
--创建优化后的QunList表
CREATE TABLE [dbo].[QunList](
[QunNum] [int] NOT NULL,
[MastQQ] [smallint] NULL,
[CreateDate] [date] NULL,
[Title] [varchar](22) NULL,
[Class] [varchar](38) NULL,
[QunText] [varchar](80) NULL,
CONSTRAINT [PK_QunList2] PRIMARY KEY CLUSTERED
(
[QunNum] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = ON, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, DATA_COMPRESSION = ROW) ON [Sch_QunList_QunNum]([QunNum])
) ON [Sch_QunList_QunNum]([QunNum])
GO
(Figure1:GroupData原表结构)
(Figure2:GroupData新表结构)
8.把11个数据库都合并到新创建的QunInfo的QunList表中;
--合并数据
DECLARE @tablename sysname
DECLARE @dbname sysname
DECLARE @sql NVARCHAR(max) --游标
DECLARE @itemCur CURSOR
SET @itemCur = CURSOR FOR
SELECT db_name,table_name from [QunInfo].[dbo].[tables] OPEN @itemCur
FETCH NEXT FROM @itemCur INTO @dbname,@tablename
WHILE @@FETCH_STATUS=0 BEGIN SET @sql = '
INSERT INTO [QunInfo].[dbo].[QunList]
([QunNum]
,[MastQQ]
,[CreateDate]
,[Title]
,[Class]
,[QunText])
SELECT [QunNum]
,[MastQQ]
,[CreateDate]
,[Title]
,[Class]
,[QunText]
FROM ['+@dbname+'].[dbo].['+@tablename+']' EXEC(@sql) UPDATE [QunInfo].[dbo].[tables] SET status = 1 WHERE db_name = @dbname AND table_name = @tablename --返回SQL
PRINT(@sql)PRINT('GO')+CHAR(13) FETCH NEXT FROM @itemCur INTO @dbname,@tablename
END CLOSE @itemCur
DEALLOCATE @itemCur
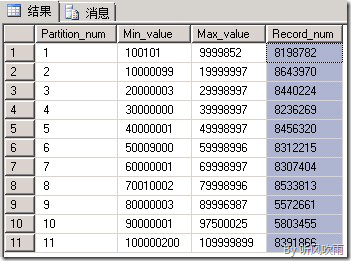
(Figure3:QunList表分区记录数)

(Figure4:QunList数据行压缩前)

(Figure5:QunList数据行压缩后)
我们使用页压缩修改表QunList,看看数据占用大小的情况:
--页压缩
ALTER TABLE [QunList]
REBUILD WITH (DATA_COMPRESSION = PAGE );

(Figure6:QunList数据页压缩后)
QunInfo群数据库的还原与优化的更多相关文章
- GroupData群数据库的还原与优化
一.背景 这个数据库的数据文件mdf大概有83G左右,当还原数据库之后感觉可以做很多性能方面上的调优,合并数据后mdf数据文件大概有59G左右,行压缩后mdf数据文件大概有39G左右,页压缩后mdf数 ...
- nbu还原集群数据库异常问题
集群数据库软件均已安装完毕,现在想从NBU上还原数据库,但在还原控制文件报错 [oracle@oracle-db1 ~]$ rman target / Recovery Manager: Releas ...
- DB2数据库性能调整和优化(第2版)
<DB2数据库性能调整和优化(第2版)> 基本信息 作者: 牛新庄 出版社:清华大学出版社 ISBN:9787302325260 上架时间:2013-7-3 出版日期:2013 年7月 开 ...
- 近千节点的Redis Cluster高可用集群案例:优酷蓝鲸优化实战(摘自高可用架构)
(原创)2016-07-26 吴建超 高可用架构导读:Redis Cluster 作者建议的最大集群规模 1,000 节点,目前优酷在蓝鲸项目中管理了超过 700 台节点,积累了 Redis Clus ...
- Thinkphp3.2 备份数据库和还原数据的方法
其实Thinkphp框架并没有自带备份数据库的功能,但是细心的朋友可能会发现Thinkphp的一套内容管理系统oneThink是有备份数据库和还原数据的功能的. 所以今天我就来聊一聊,oneThink ...
- DM8数据库备份还原的原理及应用
(本文部分内容摘自DM产品技术支持培训文档,如需要更详细的文档,请查询官方操作手册,谢谢) 一.原理 1.DM8备份还原简介 1.1.基本概念 (1)表空间与数据文件 ▷ DM8表空间类型: ▷ SY ...
- SQL Server 数据库备份还原和数据恢复
认识数据库备份和事务日志备份 数据库备份与日志备份是数据库维护的日常工作,备份的目的是在于当数据库出现故障或者遭到破坏时可以根据备份的数据库及事务日志文件还原到最近的时间点将损失降到最低点. 数据 ...
- 如何用Dummy实例执行数据库的还原和恢复
今天实验了一下,如何在所有文件,包括数据文件,在线日志文件,控制文件都丢失的情况下,利用RMAN备份恢复和还原数据库.该实验的重点是用到了Dummy实例. 具体步骤如下: 备份数据库 [oracle@ ...
- 《SQL Server企业级平台管理实践》读书笔记——关于SQL Server数据库的还原方式
本篇是继上篇的备份方式,本篇介绍的是还原方案,在SQL Server在2005以上现有的还原方案一般分为以下4个级别的数据还原: 1.数据库完整还原级别: 还原和恢复整个数据库.数据库在还原和恢复操作 ...
随机推荐
- JavaScript自定义浏览器滚动条兼容IE、 火狐和chrome
今天为大家分享一下我自己制作的浏览器滚动条,我们知道用css来自定义滚动条也是挺好的方式,css虽然能够改变chrome浏览器的滚动条样式可以自定义,css也能够改变IE浏览器滚动条的颜色.但是css ...
- Golang, 以17个简短代码片段,切底弄懂 channel 基础
(原创出处为本博客:http://www.cnblogs.com/linguanh/) 前序: 因为打算自己搞个基于Golang的IM服务器,所以复习了下之前一直没怎么使用的协程.管道等高并发编程知识 ...
- python核心编程第二版练习题答案
2-5 #写一个while循环,输出整型为0~10 a=0while a<11: print a a+=1 #写一个for循环重复以上操作 for i in range(11): print i ...
- Oracle 数据库知识汇总篇
Oracle 数据库知识汇总篇(更新中..) 1.安装部署篇 2.管理维护篇 3.数据迁移篇 4.故障处理篇 5.性能调优篇 6.SQL PL/SQL篇 7.考试认证篇 8.原理体系篇 9.架构设计篇 ...
- Effective java笔记(二),所有对象的通用方法
Object类的所有非final方法(equals.hashCode.toString.clone.finalize)都要遵守通用约定(general contract),否则其它依赖于这些约定的类( ...
- PAT练习题目录
点题号就能查看题解了,另外代码也放在了开源中国码云上: 甲级:代码集合:https://git.oschina.net/firstmiki/PAT-Advanced-Level-Practise 10 ...
- bzoj1723--前缀和(水题)
题目大意: 你难以想象贝茜看到一只妖精在牧场出现时是多么的惊讶.她不是傻瓜,立即猛扑过去,用她那灵活的牛蹄抓住了那只妖精. "你可以许一个愿望,傻大个儿!"妖精说. ...
- 程序员必须要知道的Hadoop的一些事实
程序员必须要知道的Hadoop的一些事实.现如今,Apache Hadoop已经无人不知无人不晓.当年雅虎搜索工程师Doug Cutting开发出这个用以创建分布式计算机环境的开源软...... 1: ...
- error C4430:missing type specifier 解决错误
错误 3 error C4430: missing type specifier - int assumed. Note: C++ does not support default-int ...
- JavaScript学习笔记(二)——闭包、IIFE、apply、函数与对象
一.闭包(Closure) 1.1.闭包相关的问题 请在页面中放10个div,每个div中放入字母a-j,当点击每一个div时显示索引号,如第1个div显示0,第10个显示9:方法:找到所有的div, ...