MapReduce和Tez对比
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)"。
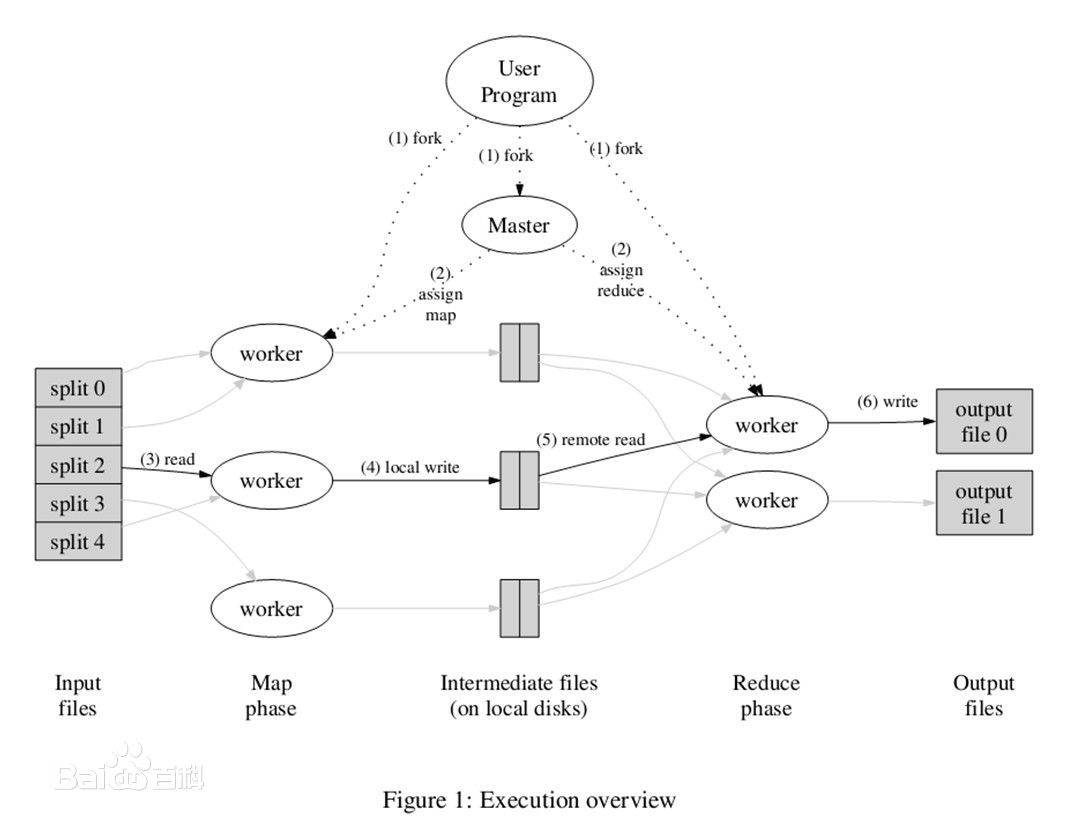
Tez是Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。总结起来,Tez有以下特点:
(1)Apache二级开源项目(源代码今天发布的)
(2)运行在YARN之上
(3) 适用于DAG(有向图)应用(同Impala、Dremel和Drill一样,可用于替换Hive/Pig等)
对比举例:
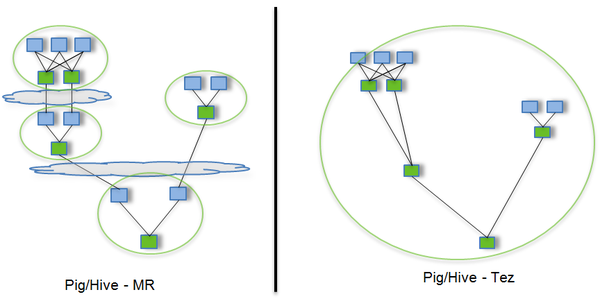
传统的MR(包括Hive,Pig和直接编写MR程序)。假设有四个有依赖关系的MR作业(1个较为复杂的Hive SQL语句或者Pig脚本可能被翻译成4个有依赖关系的MR作业)或者用Oozie描述的4个有依赖关系的作业,运行过程如下(其中,绿色是Reduce Task,需要写HDFS):
云状表示写屏蔽(write barrier,一种内核机制,持久写)
Tez可以将多个有依赖的作业转换为一个作业(这样只需写一次HDFS,且中间节点较少),从而大大提升DAG作业的性能
------------------------------
Hadoop是基础,其中的HDFS提供文件存储,Yarn进行资源管理。在这上面可以运行MapReduce、Spark、Tez等计算框架。
MapReduce:是一种离线计算框架,将一个算法抽象成Map和Reduce两个阶段进行处理,非常适合数据密集型计算。
Spark:Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
Storm:MapReduce也不适合进行流式计算、实时分析,比如广告点击计算等。Storm是一个免费开源、分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求。Storm经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域
Tez: 是基于Hadoop Yarn之上的DAG(有向无环图,Directed Acyclic Graph)计算框架。它把Map/Reduce过程拆分成若干个子过程,同时可以把多个Map/Reduce任务组合成一个较大的DAG任务,减少了Map/Reduce之间的文件存储。同时合理组合其子过程,也可以减少任务的运行时间
MapReduce和Tez对比的更多相关文章
- Spark的shuffle和MapReduce的shuffle对比
目录 MapperReduce的shuffle Spark的shuffle 总结 MapperReduce的shuffle shuffle阶段划分 Map阶段和Reduce阶段 任务 MapTask和 ...
- tez是什么?
[Apache Tez是什么?] http://dongxicheng.org/mapreduce-nextgen/apache-tez/ 浅谈Apache Tez中的优化技术 http://dong ...
- 重要 | Spark和MapReduce的对比,不仅仅是计算模型?
[前言:笔者将分上下篇文章进行阐述Spark和MapReduce的对比,首篇侧重于"宏观"上的对比,更多的是笔者总结的针对"相对于MapReduce我们为什么选择Spar ...
- 更快、更强——解析Hadoop新一代MapReduce框架Yarn(CSDN)
摘要:本文介绍了Hadoop 自0.23.0版本后新的MapReduce框架(Yarn)原理.优势.运作机制和配置方法等:着重介绍新的Yarn框架相对于原框架的差异及改进. 编者按:对于业界的大数据存 ...
- Spark环境搭建(五)-----------Spark生态圈概述与Hadoop对比
Spark:快速的通用的分布式计算框架 概述和特点: 1) Speed,(开发和执行)速度快.基于内存的计算:DAG(有向无环图)的计算引擎:基于线程模型: 2)Easy of use,易用 . 多语 ...
- Hadoop 新 MapReduce 框架 Yarn 详解【转】
[转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/] 简介: 本文介绍了 Hadoop 自 0.23.0 版本 ...
- MapReduce 人个理解
1.MapReduce 理解 拆分成 map 过程与 reduce 过程: map 可以理解为sql 中的 group by 操作, reduce相当于group by 后的聚合计算 : 一个map ...
- HIVE执行引擎TEZ学习以及实际使用
概述 最近公司在使用Tez,今天写一篇关于Tez的学习和使用随笔.Tez是Apache最新的支持DAG作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能.Tez并不 ...
- Flink 剖析
1.概述 在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷.今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一.那么,接下来,笔者为大家介绍Fl ...
随机推荐
- 什么是SQLCLR与使用
原帖地址:http://www.cnblogs.com/hsrzyn/archive/2013/05/28/1976555.html 什么是SQLCLR SQL CLR (SQL Common Lan ...
- Hadoop学习6--里程碑式的开始之执行第一个程序wordcount
一.先在HDFS文件系统创建对应的目录,具体如下: 1.待处理文件存放目录 /data/wordcount(之所以创建wordcount,是为了对文件分类,对应本次任务名) 命令:hadoop fs ...
- ExtJs4 SpringMvc3 实现Grid 分页
新建一个Maven webapp项目,webxml以及spring配置没什么需要注意的,不再赘述. Maven依赖:(个人习惯,有用没用的都加上...) <project xmlns=" ...
- (C/C++) 算法,编程题
注: 如下的题目皆来自互联网,答案是结合了自己的习惯稍作了修改. 1. 求一个数的二进制中的1的个数. int func(int x) { ; while (x) { count++; x = x&a ...
- 单点登录filter根据redis中的key判断是否退出
package com.ailk.biapp.ci.localization.cntv.filter; import java.io.IOException; import java.util.Has ...
- ylbtech-Unitity-CS:Delegates
ylbtech-Unitity-CS:Delegates 1.A,效果图返回顶部 Invoking delegate a: Hello, A! Invoking delegate b: Goodbye ...
- laravel5.2 移植到新服务器上除了“/”路由 ,其它路由对应的页面显示报404错误(Object not found!)———新装的LAMP没有加载Rewrite模块
Laravel 框架通过 public/.htaccess 文件来让网址不需要 index.php.如果你的服务器是使用 Apache,请确认是否有开启 mod_rewrite 模块.如果 Larav ...
- mysql事务与mysql储存引擎
事务概念及存储引擎 1.0 为何要事务? 先来看一个场景,银行转账汇款: 李彦宏和周鸿祎天天打架,现在让李彦宏给周鸿祎转款1000 元 设计如下表 account表 编号(id)用户名(user)金额 ...
- Bugtags:移动时代首选 Bug 管理系统
Bug 管理系统之重 回想我们每次开启一个新项目,筹备之初,首要之事就是选择一款 Bug 管理系统.市面上有诸多 Bug 管理系统可供选择:Jira.Redmine.Bugzilla 等.这些系统功能 ...
- 中文unicode范围及unicode编解码
中文unicode范围 : [\u4e00-\u9fa5] 普通字符串可以用多种方式编码成Unicode字符串,具体要看你究竟选择了哪种编码:unicodestring = u"Hello ...