[转】:HTTP请求流程(一)----流程简介
http://www.cnblogs.com/stg609/archive/2008/07/06/1236966.html
HTTP请求流程(一)----流程简介
最近一直在研究如何让asp.net实现上传大文件的功能,所以都没怎么写技术类的文章了。可惜的是至今还没研究出来,惭愧~~~。不过因为这样,也了解了一下http消息请求的大致过程。我就先简单介绍下,然后再来讲如何利用Telnet来模拟Http请求。讲得不对的地方还希望大家给我指出来。因为内容比较多,所以分成两部分来写。
1、流程简介
2、Telnet模拟HTTP请求
这篇我们就来做一个简单介绍。
先提个问题:当我们在浏览器的地址栏中输入"http://www.baidu.com/",然后按"回车",这之后发生了什么事?这里先不回答 ,大家接着往下看先。
,大家接着往下看先。
我们来分析一下:
·HTTP请求流程
首先,http属于Tcp/Ip模型中的应用层协议,而两个应用程序(我们这里指的就是浏览器与服务器)之间要进行互相通信,首先得建立Tcp连接,然后浏览器才能向服务器发送请求信息,服务器在接受到请求信息后,返回相应的应答信息,浏览器接收到来自服务器的应答信息后,对这些数据进行解释执行。
在http 1.0的版本中,浏览器的每次请求(也就是对每一个页面的访问)都要求建立一次单独的连接,在处理完每一次的请求后,就自动释放连接。(这点我们应该都有感觉,比如我们访问一个页面,当该页面在浏览器中显示出来的时候,我们可以拔掉网线,此时该页面上的信息并不会丢失。)而当我们请求的网页文件中有很多图片、音乐、电影等信息时,服务器返回的信息中并不直接包含图片数据,而只是保存该图片的链接,当浏览器进行解释的时候,遇到图片的url时,才向服务器发出对图片的请求信息。可见如果一个网页中包含多个图片数据时,将会频繁的与服务器建立连接,与释放连接,这无疑会造成资源的浪费。

http 1.0 请求模式
而http 1.1则可以在一次连接中处理多个请求,并且多个请求可以重叠进行,不需要等待一个请求结束后再发送下一个请求。
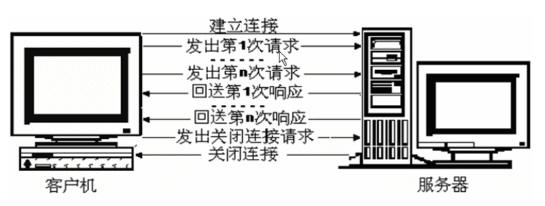
建立连接的方式
HTTP支持2中建立连接的方式:非持久连接和持久连接(HTTP1.1默认的连接方式为持久连接)。
1) 非持久连接
让我们查看一下非持久连接情况下从服务器到客户传送一个Web页面的步骤。假设该贝面由1个基本HTML文件和10个JPEG图像构成,而且所有这些对象都存放在同一台服务器主机中。再假设该基本HTML文件的URL为:gpcuster.cnblogs.com/index.html。
下面是具体步骡:
1.HTTP客户初始化一个与服务器主机gpcuster.cnblogs.com中的HTTP服务器的TCP连接。HTTP服务器使用默认端口号80监听来自HTTP客户的连接建立请求。2.HTTP客户经由与TCP连接相关联的本地套接字发出—个HTTP请求消息。这个消息中包含路径名/somepath/index.html。3.HTTP服务器经由与TCP连接相关联的本地套接字接收这个请求消息,再从服务器主机的内存或硬盘中取出对象/somepath/index.html,经由同一个套接字发出包含该对象的响应消息。
4.HTTP服务器告知TCP关闭这个TCP连接(不过TCP要到客户收到刚才这个响应消息之后才会真正终止这个连接)。
5.HTTP客户经由同一个套接字接收这个响应消息。TCP连接随后终止。该消息标明所封装的对象是一个HTML文件。客户从中取出这个文件,加以分析后发现其中有10个JPEG对象的引用。
6.给每一个引用到的JPEG对象重复步骡1-4。
上述步骤之所以称为使用非持久连接,原因是每次服务器发出一个对象后,相应的TCP连接就被关闭,也就是说每个连接都没有持续到可用于传送其他对象。每个TCP连接只用于传输一个请求消息和一个响应消息。就上述例子而言,用户每请求一次那个web页面,就产生11个TCP连接。
2) 持久连接
非持久连接有些缺点。首先,客户得为每个待请求的对象建立并维护一个新的连接。对于每个这样的连接,TCP得在客户端和服务器端分配TCP缓冲区,并维持TCP变量。对于有可能同时为来自数百个不同客户的请求提供服务的web服务器来说,这会严重增加其负担。其次,如前所述,每个对象都有2个RTT的响应延长——一个RTT用于建立TCP连接,另—个RTT用于请求和接收对象。最后,每个对象都遭受TCP缓启动,因为每个TCP连接都起始于缓启动阶段。不过并行TCP连接的使用能够部分减轻RTT延迟和缓启动延迟的影响。
在持久连接情况下,服务器在发出响应后让TCP连接继续打开着。同一对客户/服务器之间的后续请求和响应可以通过这个连接发送。整个Web页面(上例中为包含一个基本HTMLL文件和10个图像的页面)自不用说可以通过单个持久TCP连接发送:甚至存放在同一个服务器中的多个web页面也可以通过单个持久TCP连接发送。通常,HTTP服务器在某个连接闲置一段特定时间后关闭它,而这段时间通常是可以配置的。持久连接分为不带流水线(without pipelining)和带流水线(with pipelining)两个版本。如果是不带流水线的版本,那么客户只在收到前一个请求的响应后才发出新的请求。这种情况下,web页面所引用的每个对象(上例中的10个图像)都经历1个RTT的延迟,用于请求和接收该对象。与非持久连接2个RTT的延迟相比,不带流水线的持久连接已有所改善,不过带流水线的持久连接还能进一步降低响应延迟。不带流水线版本的另一个缺点是,服务器送出一个对象后开始等待下一个请求,而这个新请求却不能马上到达。这段时间服务器资源便闲置了。
HTTP/1.1的默认模式使用带流水线的持久连接。这种情况下,HTTP客户每碰到一个引用就立即发出一个请求,因而HTTP客户可以一个接一个紧挨着发出各个引用对象的请求。服务器收到这些请求后,也可以一个接一个紧挨着发出各个对象。如果所有的请求和响应都是紧挨着发送的,那么所有引用到的对象一共只经历1个RTT的延迟(而不是像不带流水线的版本那样,每个引用到的对象都各有1个RTT的延迟)。另外,带流水线的持久连接中服务器空等请求的时间比较少。与非持久连接相比,持久连接(不论是否带流水线)除降低了1个RTT的响应延迟外,缓启动延迟也比较小。其原因在于既然各个对象使用同一个TCP连接,服务器发出第一个对象后就不必再以一开始的缓慢速率发送后续对象。相反,服务器可以按照第一个对象发送完毕时的速率开始发送下一个对象。 ·
1次完整的http请求消息包括:一个请求行、若干消息头以及实体内容,而消息头和实体内容可以没有,消息头和实体内容间有一个空行。
我们来看一个例子(为了便于说明,我在每行前加了序号):
1 Get /mattmarg/ HTTP/1.0
2 User-Agent: Mozilla/2.0 (Macintosh; I; PPC)
3 Accept: text/html; */*
4 Cookie: name = value
5 Referer: http://www.XXX.com/a.html
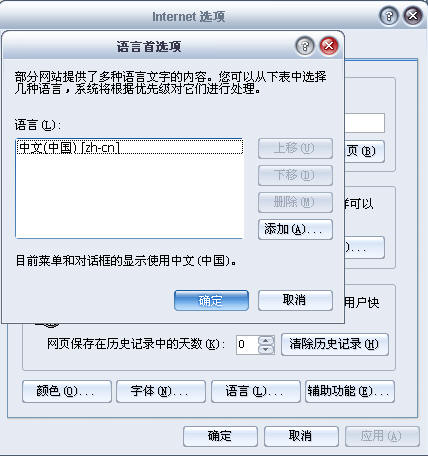
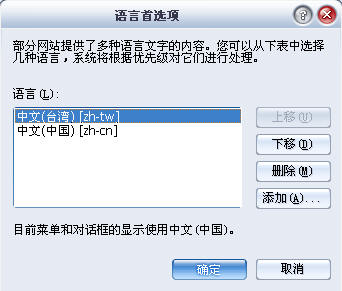
其中,第1行就是请求行:请求方式为Get(除了Get之外,还有Post、Put、Delete方式),请求的文件位于"根目录/mattmarg/"下,当然也可以直接给出需要的页面(如:/mattmarg/index.asp,也可以加上一些其它字段 如:/mattmarg/index.asp?id=1&uid=xxx。当我们通过Get请求时,提交给服务器的请求行长度不能超过1K,而如果利用Post方式,则是把所提交的信息以实体内容形式发送给服务器,所以如果服务器没有限制的话,原则上讲可以传输无限大的内容),HTTP/1.0 表示了http的版本为1.0。其余几行就是消息头了,消息头主要是用来向服务器传达某种信息或指示。如告诉服务器自己的终端(User-Agent)是什么(如果是浏览器则返回相应的浏览器型号),终端所可以解释的类型(Accept)是什么,是从哪个页面提交的请求(Referer),以及浏览器所能解释的语言(Accept-Language)等等。我们这里拿Accept-Language来举个例子,大家都知道google在中国大陆显示的是简体中文,而在其它的国家则显示对应的语言,这个是怎么做到的呢?其实就是浏览器向服务器递交的请求信息中包含了Accept-Language,而我们的浏览器默认是zh-cn,然后服务器在接受到该信息时返回对应的页面。
我们可以通过以下方法来验证一下:
1、打开浏览器->工具->internet选项->常规选项卡
·HTTP响应消息
Http响应消息的格式为:一个状态行、若干消息头和实体内容,其中消息头和实体内容可以没有,消息头和实体内容间有一个空行。
我们依旧先来看一个例子:
01 HTTP/1.1 200 OK
02 Server: Microsoft-IIS/5.1
03 X-Powered-By: ASP.NET
04 Date: Sun, 06 Jul 2008 11:01:21 GMT
05 Content-Type: text/html
06 Accept-Ranges: bytes
07 Last-Modified: Wed, 02 Jul 2008 01:01:26 GMT
08 ETag: "0f71527dfdbc81:ade"
09 Content-Length: 46
10
11 <html><head></head><body>adfasfa</body></html>
其中,01行是状态行,用于显示服务器响应的状态,HTTP/1.1显示了对应的http协议版本,200为状态数字,OK为状态信息用于解释状态数字(这里OK对应200,表示请求正常);02~09是消息头部分,10为空行,11为实体内容(也就是服务器返回的网页内容)。
好了,相信大家应该已经对这个http请求的流程有了一个大概的了解了吧,那么我们反过来回答下最初留下的问题:当我们在浏览器的地址栏中输入 " http://www.baidu.com/ " ,然后按"回车",这之后发生了什么事?。
首先,浏览器找到该网址所指向的IP,然后与其建立TCP连接,接着向百度服务器提出Get请求,当服务器接收到我们的请求后,向我们传送应答信息--百度的页面,然后断开连接。
[补充]以上文章中主要是描述HTTP请求的大致流程,至于HTTP之前所建立的一系列连接,只用了"浏览器找到该网址所指向的IP,然后与其建立TCP连接"这句话或类似的话来带过。根据朋友们的回复显得这个说法不是很恰当。所以我在这里再补充些东西。
1、获取IP。浏览器地址栏中输入"http://www.xxx.edu.cn/"并提交之后,首先它会在DNS本地缓存表中查找,如果有则直接告诉IP地址。如果没有则要求网关DNS进行查找,如此下去,当找到对应的ip后,则返回给浏览器。
2、建立TCP连接。当获取到IP之后,就开始与所请求的服务器建立TCP连接,你可以在下图中发现syn,ack,这些标识符就是用来同步用的。
3、连接建立后,就向服务器发出http请求(大家可以从图中看出来)。如果是HTTP1.0的版本则,每一次请求结束后,就释放TCP连接。
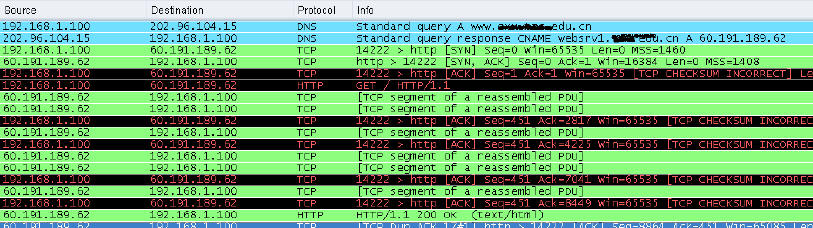

(短时间内,第二次访问同一网站)
参考:
1.张孝祥老师的HTTP协议详解
2.http://www.cnblogs.com/stg609/articles/1231832.html
[转】:HTTP请求流程(一)----流程简介的更多相关文章
- 图解 Spring:HTTP 请求的处理流程与机制【2】
2. HTTP 请求在 Web 容器中的处理流程 Web 容器以进程的方式在计算机上运行,我们知道进程是系统资源分配的最小单元,线程是系统任务执行的最小单元.从这个角度看,Web 容器就像是邮包收件人 ...
- 图解 Spring:HTTP 请求的处理流程与机制【3】
3. HTTP 请求在 Web 应用中的处理流程 在穿越了 Web 容器之后,HTTP 请求将被投送到 Web 应用,我们继续以 Tomcat 为例剖析后续流程.Web 容器与 Web 应用的衔接是通 ...
- 图解 Spring:HTTP 请求的处理流程与机制【4】
4. HTTP 请求在 Spring 框架中的处理流程 在穿越了 Web 容器和 Web 应用之后,HTTP 请求将被投送到 Spring 框架,我们继续剖析后续流程.Web 应用与 Spring M ...
- web请求的处理流程
web请求的处理流程如下: 1.客户发起请求到服务器网卡:2.服务器网卡接受到请求后转交给内核处理:3.内核根据请求对应的套接字,将请求交给工作在用户空间的Web服务器进程4.Web服务器进程根据用户 ...
- Net 一个请求的处理流程
Net 一个请求的处理流程 1.浏览器请求 请求-准备环境-->处理请求 2.Aspnet 环境的创建 客户请求 IIS区分静态文件还是动态文件,静态文件直接文件返回,动态文件通过asp ...
- Glusterfs下读写请求的处理流程
Glusterfs基于内核的fuse模块,fuse模块除了创建fuse文件系统外,还提供了一个字符设备(/dev/fuse),通过这个字符设备,Glusterfs可以读取请求,并发送响应,并且可以发送 ...
- 图解 Spring:HTTP 请求的处理流程与机制【1】
2003 年,老兵哥初到中兴开始研究生实习,Spring 就是那年诞生的,2004 年 3 月发布了 1.0 版本,到现在已经超过 15 年了.从单体式分层架构到云原生微服务架构,它稳坐在 JAVA ...
- 图解 Spring:HTTP 请求的处理流程与机制【5】
5. HTTP 请求处理相关配置文件说明 HTTP 请求穿越的整个空间是分层的,包括:Web 容器.Web 应用.Spring 框架等,它们每层都是通过配置文件配置初始化的,这是一种松耦合的架构设计. ...
- Kafka处理请求的全流程分析
大家好,我是 yes. 这是我的第三篇Kafka源码分析文章,前两篇讲了日志段的读写和二分算法在kafka索引上的应用 今天来讲讲 Kafka Broker端处理请求的全流程,剖析下底层的网络通信是如 ...
- Gemini.Workflow 双子工作流入门教程三:定义流程:流程节点、迁移条件参数配置
简介: Gemini.Workflow 双子工作流,是一套功能强大,使用简单的工作流,简称双子流,目前配套集成在Aries框架中. 下面介绍本篇教程:定义流程:流程节点.迁移条件参数配置. 一.普通节 ...
随机推荐
- BZOJ2708 [Violet 1]木偶
首先想到的是贪心...肯定不对嘛...T T 然后发现其实是可以DP的...不过我们要先排序 令f[i]表示前i个木偶最坏要丢掉几个,则 f[i] = max(f[j] + calc(j + 1, i ...
- 关于python中的编码:unicode, utf-8, gb2312
计算机早期是只支持ASCII码的,经过long long的发展,出现了这些支持世界上各种语言字符的编码:unicode, utf-8, gb2312. 对于unicode, utf-8, gb2312 ...
- 【工具推荐】ELMAH——可插拔错误日志工具
今天看到一篇文章(构建ASP.NET网站十大必备工具(2)),里面介绍了一个ELMAH的错误日志工具,于是研究了一下. ELMAH 是 Error Logging Modules and Handle ...
- CNAPS Code 查询(招商银行)
招商银行的妹子实在太傻了,根本不知道什么是CNAPS Code.联行号,完全答非所问. 最后还是自己搞定了,如图: 最后再看看招行人员的英语水平,真是不知道什么是东西:
- ARM安装ROS- indigo
Ubuntu ARM install of ROS Indigo 溪西创客小屋 There are currently builds of ROS for Ubuntu Trusty armhf. T ...
- 学好C++必须要注意的十八个问题
转自 http://blog.chinaunix.net/uid-7396260-id-2056691.html 一.#include "filename.h"和#i nclud ...
- Java基础01 ------ 从HelloWorld到面向对象
Java是完全面向对象的语言.Java通过虚拟机的运行机制,实现“跨平台”的理念.我在这里想要呈现一个适合初学者的教程,希望对大家有用. "Hello World!" 先来看一个H ...
- SharePoint 2010 BCS - 简单实例(二)外部列表创建
博客地址 http://blog.csdn.net/foxdave 接上篇 由于图片稍多篇幅过长影响阅读,所以分段来写. 添加完数据源之后,我们需要为我们要放到SharePoint上的数据表定义操作, ...
- uitabbarcontroller中 在设置tab bar item的image属性后不显示问题
开始使用ios中的UITabBarController,在给Tab Bar Item设置自定义图片的时候,遇到了问题 按照如下配置: 出来的结果确是: 实际上test24.png应该是: 纠结了很久, ...
- 收藏的博客--PHP
32位Win7下安装与配置PHP环境(一至三) http://blog.csdn.net/yousuosi/article/details/9448903