自然语言处理3.3——使用Unicode进行文字处理
全世界有多种语言,经常需要应用程序处理不同的语言和字符集。下面将介绍如何利用Unicode处理使用非ASCII字符集文字。
1.什么是Unicode
Unicode支持一百万种以上的字符,每一个字符分配一个编号,称为编码点。在Python中编码点写作\uXXXX,其中XXXX是四位十六进制数。
在一段程序中,可以像普通字符串那样操纵Unicode字符串。然而,当Unicode字符被存储在文件里或者终端上显示时候,必须编码为字节流。由于一些编码的每个编码点都使用单字节,所以他们只需要支持Unicode中的一个小子集就足够一种语言使用了,但是其他编码(UTF-8)使用多个字节,可以表示全部的Unicode字符。
注意:将文本翻译成Unicode叫做解码,相对的,将Unicode转化为合适的编码称为编码。如下图:
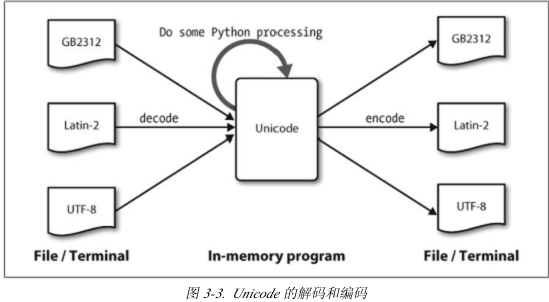
2,从文件中提取已经编码文本。
假设有一个小的文本文件,并且知道他是怎么编码的,例如:polish-lat2.txt是波兰语的文本片段。为Latin-2编码。下面首先使用nltk.data.find()函数定位文件
path=nltk.data.find('corpora/unicode_samples/polish-lat2.txt')
Python的codecs模块提供了将编码数据读入为Unicode字符串和将Unicode字符串以编码的形式输出的函数。codecs.open()函数有一个encoding参数来制定被读取或者写入的文件的编码。我们导入codecs模块,以‘Latin-2’为encoding的参数,打开制定的波兰语文件
>>>import codecs
>>>f=codecs.open(path,encoding='latin2')
从文件对象f读出的文本将会以Unicode返回。为了能在终端上查看这个文本我们需要使用合适的编码对它进行编码。Python特定的unicode_escape是一个虚拟的编码,他把所有的非ASCII字符转换成\uXXXX形式。编码点在ASCII码0~127的范围以外但是低于256的,使用两位数字的形式表示。
>>>for line in f:
line=line.strip()
print(line.encode('unicode_escape'))
b'Pruska Biblioteka Pa\\u0144stwowa. Jej dawne zbiory znane pod nazw\\u0105'
b'"Berlinka" to skarb kultury i sztuki niemieckiej. Przewiezione przez'
b'Niemc\\xf3w pod koniec II wojny \\u015bwiatowej na Dolny \\u015al\\u0105sk, zosta\\u0142y'
b'odnalezione po 1945 r. na terytorium Polski. Trafi\\u0142y do Biblioteki'
b'Jagiello\\u0144skiej w Krakowie, obejmuj\\u0105 ponad 500 tys. zabytkowych'
b'archiwali\\xf3w, m.in. manuskrypty Goethego, Mozarta, Beethovena, Bacha.'
可以看到在输出文本的第一行有一个以\u转义字符串开始的Unicode转义字符串。即\u0144。
在Python中,一个Unicode字符串常量可以通过在字符串前面加一个u也就是例如u‘hello’来制定。
>>>print(u'\u0061')
a
>>>nacute=u'\u0144'
>>>print(nacute)
ń
Python在指定print使用repr()转化字符串,repr()输出UTF-8转义字符,而不是试图显示字形。
>>>nacute_utf=nacute.encode('utf-8')
>>>print(repr(nacute_utf))
b'\xc5\x84'
unicodedata模块使我们可以检查Unicode字符的属性。
>>> import unicodedata
>>> unicodedata.lookup('LEFT CURLY BRACKET')
'{'
>>> unicodedata.name('/')
'SOLIDUS'
>>> unicodedata.decimal('9')
9
>>> unicodedata.decimal('a')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ValueError: not a decimal
>>> unicodedata.category('A') # 'L'etter, 'u'ppercase
'Lu'
>>> unicodedata.bidirectional('\u0660') # 'A'rabic, 'N'umber
'AN'
自然语言处理3.3——使用Unicode进行文字处理的更多相关文章
- 文字编码和Unicode
文字编码和Unicode 说明文字: https://blog.csdn.net/fengzhishang2019/article/details/7859064 Java 程序: https://w ...
- 《Python自然语言处理》
<Python自然语言处理> 基本信息 作者: (美)Steven Bird Ewan Klein Edward Loper 出版社:人民邮电出版社 ISBN:97871153 ...
- 【NLP】Python NLTK处理原始文本
Python NLTK 处理原始文本 作者:白宁超 2016年11月8日22:45:44 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公开 ...
- OpenCascade Chinese Text Rendering
OpenCascade Chinese Text Rendering eryar@163.com Abstract. OpenCascade uses advanced text rendering ...
- ASP 编码转换(乱码问题解决)
ASP 编码转换(乱码问题解决) 输出前先调用Conversion函数进行编码转换,可以解决乱码问题. 注,“&参数&”为ASP的连接符,这里面很多是直接调用的数据库表字段,实际使用请 ...
- 字符流和字节流(FileReader类和FileWriter类)
字符流主要用于支持Unicode的文字内容,绝大多数在字节流中所提供的类,都可在此找到对应的类.其中,输入流Reader抽象类帮助用户在Unicode流内获得字符数据,而Writer类则实现了输出.可 ...
- python 处理中文文件时的编码问题,尤其是utf-8和gbk
python代码文件的编码 py文件默认是ASCII编码,中文在显示时会做一个ASCII到系统默认编码的转换,这时就会出错:SyntaxError: Non-ASCII character.需要在代码 ...
- python 读写文件和设置文件的字符编码
一. python打开文件代码如下: f = open("d:\test.txt", "w") 说明:第一个参数是文件名称,包括路径:第二个参数是打开的模式mo ...
- C++历史(The History of C++)
C++历史 早期C++ •1979: 首次实现引入类的C(C with Classes first implemented) 1.新特性:类.成员函数.继承类.独立编译.公共和私有访问控制.友元.函数 ...
随机推荐
- resolve some fragment exception
1.android fragment not attached to activity http://blog.csdn.net/walker02/article/details/7995407 if ...
- 使用HackRF+GNU Radio 破解吉普车钥匙信号
引文 我最近对软件定义的无线电技术(SDR)产生了浓厚的兴趣,而我对其中一款流行的SDR平台(HackRF)也产生了兴趣,而其频率接收的范围也在1MHz ~6GHz之间(范围较广).而这里也需要提及一 ...
- iOS 开发之重力动画效果
步骤:1.使用single view application创建新的项目 2.在viewcontroller.h文件中创建一个图片实例并与相关图片相连,然后创建一个UIDynamicAnimator ...
- 解决:Android4.3锁屏界面Emergency calls only - China Unicom与EMERGENCY CALL语义重复
从图片中我们可以看到,这里在语义上有一定的重复,当然这是谷歌的原始设计.这个问题在博客上进行共享从表面上来看着实没有什么太大的意义,不过由于Android4.3在锁屏功能上比起老版本做了很大的改动,而 ...
- Supermarket_贪心
Description A supermarket has a set Prod of products on sale. It earns a profit px for each product ...
- Java 集合深入理解(3):Collection
点击查看 Java 集合框架深入理解 系列, - ( ゜- ゜)つロ 乾杯~ 今天心情有点粉,来学学 Collection 吧! 什么是集合? 集合,或者叫容器,是一个包含多个元素的对象: 集合可以对 ...
- Android Material Design : Ripple Effect水波波纹荡漾的视觉交互设计
Android Material Design : Ripple Effect水波波纹荡漾的视觉交互设计 Android Ripple Effect波纹荡漾效果,是Android Materia ...
- JS删除HTML元素问题
<div id='one'> <div>1</div> <div>2</div> </div> <div id=" ...
- 转:去掉DataTable重复数据(程序示例比较)
using System; using System.Collections.Generic; using System.Data; using System.Linq; using System.T ...
- Debian下安装Firefox与flash简介
Debian下安装Firefox与flash简介 由于Debian在Firefox的版权上出现了问题,导致官方发布的Debian系统不能使用默认的Firefox浏览器,最后官方重编的Firefox改名 ...