【ES】ElasticSearch初体验之使用Java进行最基本的增删改查~
好久没写博文了, 最近项目中使用到了ElaticSearch相关的一些内容, 刚好自己也来做个总结。
现在自己也只能算得上入门, 总结下自己在工作中使用Java操作ES的一些小经验吧。
本文总共分为三个部分:
一:ES相关基本概念及原理
二:ES使用场景介绍
三:使用Java进行ES的增删改查及代码讲解
一:ES相关基本概念:
ElasticSearch(简称ES)是一个基于Lucene构建的开源、分布式、RESTful的全文本搜索引擎。
不过,ElasticSearch却也不仅只是一个全文本搜索引擎,它还是一个分布式实时文档存储,其中每个field均是被索引的数据且可被搜索;也是一个带实时分析功能的分布式搜索引擎,并且能够扩展至数以百计的服务器存储及处理PB级的数据。
如前所述,ElasticSearch在底层利用Lucene完成其索引功能,因此其许多基本概念源于Lucene。
我们先说说ES的基本概念。
- 索引 Index:对数据的逻辑存储(倒排索引),不存储原
始值。 - 类型 Type:对索引的逻辑分类,可以有⼀个或多个分类。
- ⽂档 Document:基本数据单元,JSON。
- 字段 Filed
关系型数据与ES对比:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
这里再说下ES中很重要的概念--倒排索引。这同样也是solr,lucene中所使用的索引方式。
例如我们正常的索引:
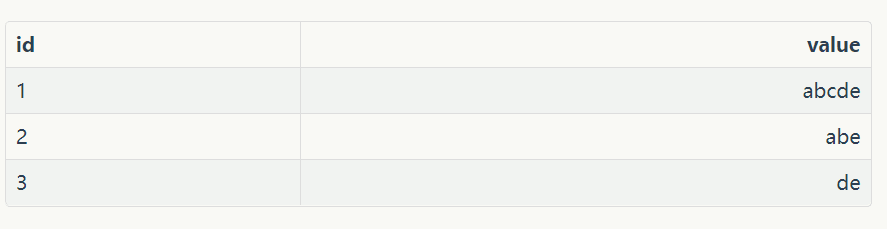
当我们在关系型数据库中,都是有id索引的, 我们通过id去查value速度是很快的。
但是如果我们想查value中包含字母b的值呢?特别是数据量很大的时候, 这种以id为索引的方式是不是就不适合了?
那么这里就适合使用倒排索引了:

这里将value进行分词, 然后将分词结果拿出来当做索引
跟正向的索引比较,也就是做了一个倒置,这就是倒排索引的思想
二,ES使用场景介绍
1、全文搜索(搜索引擎)
在一组文档中查找某一单词所在文档及位置
2、模糊匹配
通过用户的输入去匹配词库中符合条件的词条
3、商品搜索
通过商品的关键字去数据源中查找符合条件的商品
在我自己的项目中使用的情况是我有上百万的文章需要被通过各种条件检索到, 所以这里就直接使用ES, 现在线上检索速度都是10ms之内返回。
下面看看ES数据在浏览器的展示形式以及可视化界面的搜索:

三:使用Java进行ES的增删改查及代码讲解
1, 使用ES进行增加和更新操作。
//首先在项目启动的时候生成esClient, 这个我们公司自己封装好了的。
@PostConstruct
public void init() {
esClient = new ESClient<>(esConfig.getAddress(), esConfig.getCluster(), esConfig.getIndex(),
esConfig.getUsername(), esConfig.getPassword(), ES_TYPE_MIXEDDATA, EsMixedDataDto.class);
}上面EsMixedDataDto是自己构建的一个类, ES中保存的字段就是这个类中的所有字段。
接着是增加和更新操作了:
//同步到ES中
articleEsService.upsertDocument(esMixedDataDto);
/**
* 创建或更新索引
*
* @param esMixedDataDto
* @return
*/
public boolean upsertDocument(EsMixedDataDto esMixedDataDto) {
return esClient.upsertDocument(esMixedDataDto.getMixId(), esMixedDataDto);
}这个还是调用了系统封装好的esClient中的insertOrUpdate方法,最后我会把ESClient中所有封装的方法都贴出来, 其内部就是调用了ES原生的insert或者update方法的。
2,使用ES进行删除操作
/**
* 删除索引
*/
public void deleteIndex(String id) throws Exception{
esClient.deleteDocument(id);
}同上,也是使用了esClient中的delete方法,后面我会贴上esClient中所有方法。
3,使用ES进行查询
3.1 当然ES最重要的还是多维度的查询, 这里也是我要讲的重点。
首先来个最简单的搜索一篇文章的标题:
//通过关键词来查询文章集合
public PageResponse<EsMixedDataDto> queryForKeyword(String searchText, boolean highlight, PageRequest pageRequesto) {
SearchRequestBuilder searchRequestBuilder = esClient.prepareSearch()
.setTypes(ES_TYPE_MIXEDDATA)
.setSearchType(SearchType.QUERY_THEN_FETCH)
.setQuery(QueryBuilders.multiMatchQuery(searchText, "title").type(MultiMatchQueryBuilder.Type.BEST_FIELDS))
.setFrom(pageRequest.getOffset())
.setSize(pageRequest.getLimit())
.setExplain(false)
;
if (highlight) {
searchRequestBuilder.addHighlightedField("title", 100, 1)
.setHighlighterPreTags("<font color='red'>")
.setHighlighterPostTags("</font>");
}
try {
//这里就是给es发送搜索指令了
return getMixedData(searchRequestBuilder);
} catch (Exception e) {
log.error("ES搜索异常!", e.getMessage());
throw new RuntimeException(e);
}
}这里先说说search_type, 也就是上面setSearchType(SearchType.QUERY_THEN_FETCH)的内容:
- query_then_fetch:执⾏查询得到对⽂档进⾏排序的所需信息(在所
有分⽚上执⾏),然后在相关分⽚上查询⽂档实际内容。返回结果的
最⼤数量等于size参数的值。 - query_and_fetch:查询在所有分⽚上并⾏执⾏,所有分⽚返回等于
size值的结果数,最终返回结果的最⼤数量等于size的值乘以分⽚
数。分⽚较多时会消耗过多资源。 - count:只返回匹配查询的⽂档数量。
- scan:⼀般在需要返回⼤量结果时使⽤。在发送第⼀次请求后,ES
会返回⼀个滚动标识符,类似于数据库中的游标。
我这里使用的是query_then_fetch。
3.2 紧接着说个多条件复杂的查询:
/**
* @param jiaxiaoId: 驾校id
* @param title 文章的title关键词
* @param publishStatus 发布状态
* @param stickStatus 置顶状态
* @param pageRequest 请求的页码和条数
* @param highlight 搜索结果是否高亮显示
*/
public PageResponse<EsMixedDataDto> queryByConditions(Long jiaxiaoId, String title, PageRequest pageRequest, int publishStatus, int stickStatus, boolean highlight) {
BoolQueryBuilder booleanQueryBuilder = QueryBuilders.boolQuery();
booleanQueryBuilder.must(QueryBuilders.termQuery("jiaxiaoId", jiaxiaoId));
if (StringUtils.isNotBlank(title)) {
booleanQueryBuilder.must(QueryBuilders.multiMatchQuery(title, "title").type(MultiMatchQueryBuilder.Type.BEST_FIELDS));
}
//这里是添加是否发布的搜索条件, 默认是只展示已发布的文章
if (publishStatus == CommonConstants.DataStatus.INIT_STATUS) {
booleanQueryBuilder.must(QueryBuilders.termQuery("publishStatus", CommonConstants.DataStatus.INIT_STATUS));
} else {
booleanQueryBuilder.mustNot(QueryBuilders.termQuery("publishStatus", CommonConstants.DataStatus.INIT_STATUS));
}
//这里是添加是否置顶的搜索条件
if (stickStatus == CommonConstants.DataStatus.PUBLISH_STATUS) {
booleanQueryBuilder.must(QueryBuilders.termQuery("stickStatus", CommonConstants.DataStatus.PUBLISH_STATUS));
} else if(stickStatus == CommonConstants.DataStatus.INIT_STATUS){
booleanQueryBuilder.mustNot(QueryBuilders.termQuery("stickStatus", CommonConstants.DataStatus.PUBLISH_STATUS));
}
SearchRequestBuilder searchRequestBuilder = esClient.prepareSearch()
.setTypes(ES_TYPE_MIXEDDATA)
.setSearchType(SearchType.QUERY_THEN_FETCH)
.setQuery(booleanQueryBuilder)
.setFrom(pageRequest.getOffset())
.setSize(pageRequest.getLimit())
.addSort("stickStatus", SortOrder.DESC)
.setExplain(false)
;
if (jiaxiaoId == null) {
BoolFilterBuilder filterBuilder = FilterBuilders.boolFilter()
.must(FilterBuilders.missingFilter("jiaxiaoId"));
searchRequestBuilder.setPostFilter(filterBuilder);
}
if (highlight) {
searchRequestBuilder.addHighlightedField("title", 100, 1)
.setHighlighterPreTags("<font color='red'>")
.setHighlighterPostTags("</font>");
} else {
searchRequestBuilder.addSort("publishTime", SortOrder.DESC);
}
try {
return getMixedData(searchRequestBuilder);
} catch (Exception e) {
log.error("ES搜索异常!", e.getMessage());
throw new RuntimeException(e);
}
}这里不用的就是使用query和filterBuilder,searchRequestBuilder中可以设置query和postFilter。
Debug到这里, 其实写的查询语句最终还是拼接成了一个ES可读的结构化查询语句:
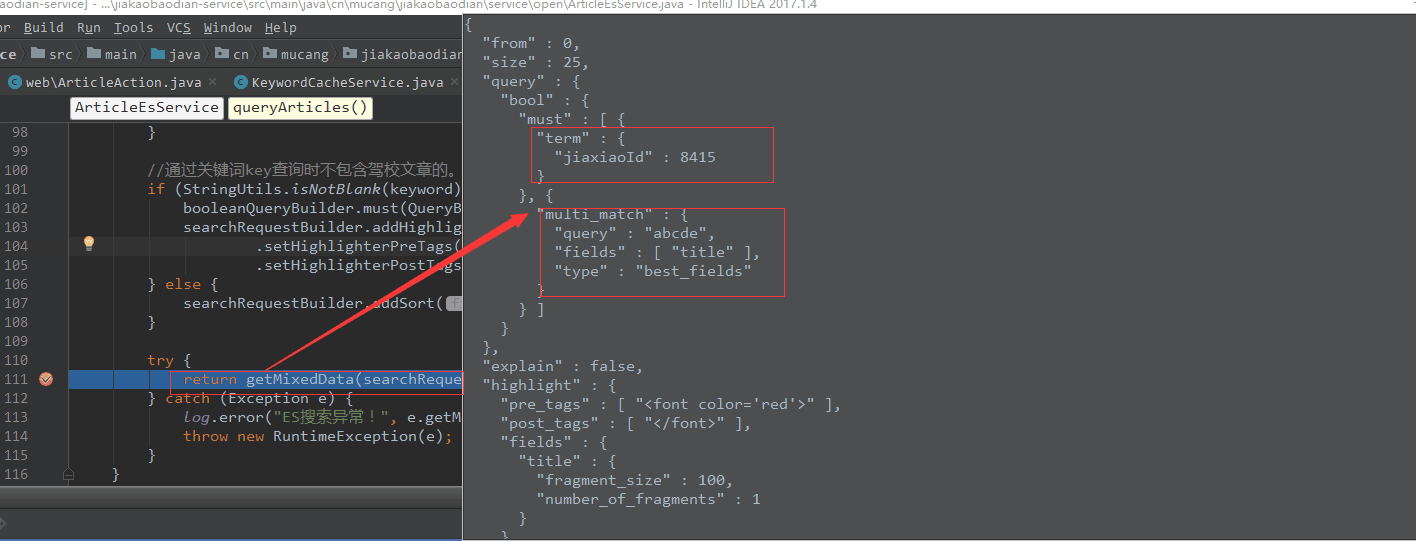
3.3 最后贴上最重要的一个类ESClient.java, 这是我们针对于ElasticSearch封装的一个类。
public class ESClient<T> {
private static final Logger LOG = LoggerFactory.getLogger(ESClient.class);
private static final String DEFAULT_ANALYZER = "ik_smart";
private static final DozerBeanMapper dozerBeanMapper = new DozerBeanMapper();
private final Client client;
private String index;
private Class<T> clazz;
private String type;
private BulkProcessor bulkProcessor;
private List<String> serverHttpAddressList = Lists.newArrayList();
private Map<String, JSONObject> sqlJsonMap = Maps.newHashMap();
/**
* 初始化一个连接ElasticSearch的客户端
*
* @param addresses ES服务器的Transport地址和端口的列表,多个服务器用逗号分隔,例如 localhost:9300,localhost:9300,...
* @param clusterName 集群名称
* @param index 索引名称,这里应该使用项目名称
* @param username 用户名称
* @param password 用户密码
* @param type 索引类型
* @param clazz 存储类
*/
public ESClient(String addresses, String clusterName, String index,
String username, String password, String type, Class<T> clazz) {
if (StringUtils.isBlank(addresses)) {
throw new RuntimeException("没有给定的ES服务器地址。");
}
this.index = index;
this.type = type;
this.clazz = clazz;
// 获得链接地址对象列表
List<InetSocketTransportAddress> addressList = Lists.transform(
Splitter.on(",").trimResults().omitEmptyStrings().splitToList(addresses),
new Function<String, InetSocketTransportAddress>() {
@Override
public InetSocketTransportAddress apply(String input) {
String[] addressPort = input.split(":");
String address = addressPort[0];
Integer port = Integer.parseInt(addressPort[1]);
serverHttpAddressList.add(address + ":" + 9200);
return new InetSocketTransportAddress(address, port);
}
}
);
// 建立关于ES的配置
ImmutableSettings.Builder builder = ImmutableSettings.settingsBuilder()
.put("cluster.name", clusterName)
.put("client.transport.sniff", false);
if (StringUtils.isNotBlank(username)) {
builder.put("shield.user", username + ":" + password);
}
Settings settings = builder.build();
// 生成原生客户端
TransportClient transportClient = new TransportClient(settings);
for (InetSocketTransportAddress address : addressList) {
transportClient.addTransportAddress(address);
}
client = transportClient;
bulkProcessor = BulkProcessor.builder(
client, new BulkProcessor.Listener() {
@Override
public void beforeBulk(long executionId, BulkRequest request) {
}
@Override
public void afterBulk(long executionId, BulkRequest request, BulkResponse response) {
}
@Override
public void afterBulk(long executionId, BulkRequest request, Throwable failure) {
throw new RuntimeException(failure);
}
}).build();
}
/**
* 初始化连接ElasticSearch的客户端
*
* @param client 原生客户端
* @param index 索引名称
* @param type 类型
* @param clazz 存储类
*/
public ESClient(Client client, String index, String type, Class<T> clazz) {
this.client = client;
this.index = index;
this.type = type;
this.clazz = clazz;
}
/**
* 向ES发送存储请求,将一个对象存储到服务器。
*
* @param id 该对象的id
* @param t 存储实例
* @return 是否存储成功
*/
public boolean indexDocument(String id, T t) {
return indexDocument(id, type, t);
}
/**
* 向ES发送存储请求,将一个对象存储到服务器。
*
* @param t 存储实例
* @return 返回存储之后在ES服务器内生成的随机ID
*/
public String indexDocument(T t) {
IndexResponse indexResponse = client.prepareIndex(index, type)
.setSource(toJSONString(t))
.execute()
.actionGet();
return indexResponse.getId();
}
/**
* 向ES发送存储请求,将一个对象存储到服务器,这个方法允许用户手动指定该对象的存储类型名称
*
* @param id 对象id
* @param type 存储类型
* @param t 存储实例
* @return 是否存储成功
*/
public boolean indexDocument(String id, String type, T t) {
IndexResponse indexResponse = client.prepareIndex(index, type, id)
.setSource(toJSONString(t))
.execute()
.actionGet();
return true;
}
/**
* 向ES发送批量储存请求, 请求不会马上提交,而是会等待到达bulk设置的阈值后进行提交.<br/>
* 最后客户端需要调用{@link #flushBulk()}方法.
*
* @param id 对象id
* @param t 存储实例
* @return 成功表示放入到bulk成功, 可能会抛出runtimeException
*/
public boolean indexDocumentBulk(String id, T t) {
return indexDocumentBulk(id, type, t);
}
/**
* 向ES发送批量存储请求,将一个对象存储到服务器,这个方法允许用户手动指定该对象的存储类型名称
*
* @param id 对象id
* @param type 存储类型
* @param t 存储实例
* @return 成功表示放入到bulk成功, 可能会抛出runtimeException
* @see #indexDocument(String, Object)
*/
public boolean indexDocumentBulk(String id, String type, T t) {
IndexRequest indexRequest = new IndexRequest(index, type, id).source(toJSONString(t));
bulkProcessor.add(indexRequest);
return true;
}
/**
* 向ES发送批量存储请求, 请求不会马上提交,而是会等待到达bulk设置的阈值后进行提交.<br/>
* 最后客户端需要调用{@link #flushBulk()}方法.
*
* @param t 存储实例
* @return 成功表示放入到bulk成功, 可能会抛出runtimeException
*/
public boolean indexDocumentBulk(T t) {
IndexRequest indexRequest = new IndexRequest(index, type).source(toJSONString(t));
bulkProcessor.add(indexRequest);
return true;
}
public boolean indexDocumentBulk(List<T> list) {
for (T t : list) {
indexDocumentBulk(t);
}
return true;
}
/**
* 向ES发送批量存储请求, 允许传入一个Function, 用来从对象中获取ID.
*
* @param list 对象列表
* @param idFunction 获取ID
* @return 成功表示放入到bulk成功, 可能会抛出runtimeException
*/
public boolean indexDocumentBulk(List<T> list, Function<T, String> idFunction) {
for (T t : list) {
indexDocumentBulk(idFunction.apply(t), t);
}
return true;
}
/**
* 向ES发送更新文档请求,将一个对象更新到服务器,会替换原有对应ID的数据。
*
* @param id id
* @param t 存储对象
* @return 是否更新成功
*/
public boolean updateDocument(String id, T t) {
return updateDocument(id, type, t);
}
/**
* 向ES发送更新文档请求,将一个对象更新到服务器,会替换原有对应ID的数据。
*
* @param id id
* @param type 存储类型
* @param t 存储对象
* @return 是否更新成功
*/
public boolean updateDocument(String id, String type, T t) {
client.prepareUpdate(index, type, id).setDoc(toJSONString(t))
.execute().actionGet();
return true;
}
/**
* 向ES发送批量更新请求
*
* @param id 索引ID
* @param t 存储对象
* @return 成功表示放入到bulk成功, 可能会抛出runtimeException
*/
public boolean updateDocumentBulk(String id, T t) {
UpdateRequest updateRequest = new UpdateRequest(index, type, id).doc(toJSONString(t));
bulkProcessor.add(updateRequest);
return true;
}
/**
* 向ES发送upsert请求, 如果该document不存在将会新建这个document, 如果存在则更新.
*
* @param id id
* @param t 存储对象
* @return 是否执行成功
*/
public boolean upsertDocument(String id, T t) {
return upsertDocument(id, type, t);
}
/**
* 向ES发送upsert请求, 如果该document不存在将会新建这个document, 如果存在则更新.
*
* @param id id
* @param type 存储类型
* @param t 存储对象
* @return 是否执行成功
*/
public boolean upsertDocument(String id, String type, T t) {
client.prepareUpdate(index, type, id).setDocAsUpsert(true).setDoc(toJSONString(t))
.execute().actionGet();
return true;
}
/**
* 向ES发送批量upsert的请求.
*
* @param id id
* @param t 储存对象
* @return 是否执行成功
*/
public boolean upsertDocumentBulk(String id, T t) {
UpdateRequest updateRequest = new UpdateRequest(index, type, id)
.doc(toJSONString(t));
updateRequest.docAsUpsert(true);
bulkProcessor.add(updateRequest);
return true;
}
/**
* 向ES发送获取指定ID文档的请求
*
* @param id id
* @return 搜索引擎实例
* @throws Exception
*/
public T getDocument(String id) throws Exception {
try {
GetResponse getResponse = client.prepareGet(index, type, id)
.execute().actionGet();
if (getResponse.getSource() == null) {
return null;
}
JSONObject jsonObject = new JSONObject(getResponse.getSource());
T t = clazz.newInstance();
toObject(t, jsonObject);
return t;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* 向ES发送删除指定ID文档的请求
*
* @param id id
* @return 是否删除成功
* @throws Exception
*/
public boolean deleteDocument(String id) throws Exception {
return deleteDocument(id, type);
}
/**
* 向ES发送删除指定ID文档的请求
*
* @param id id
* @param type 存储类型
* @return 是否删除成功
* @throws Exception
*/
public boolean deleteDocument(String id, String type) throws Exception {
DeleteResponse deleteResponse = client.prepareDelete(index, type, id)
.execute().actionGet();
return deleteResponse.isFound();
}
/**
* 向ES发送搜索文档的请求,返回分页结果
*
* @param searchText 搜索内容
* @return 分页结果
* @throws Exception
*/
public PageResponse<T> searchDocument(String searchText) throws Exception {
PageRequest pageRequest = WebContext.get().page();
SearchRequestBuilder searchRequestBuilder = client.prepareSearch(index)
.setTypes(type)
.setQuery(QueryBuilders.matchQuery("_all", searchText))
.setFrom(pageRequest.getOffset())
.setSize(pageRequest.getLimit())
.setFetchSource(true);
return searchDocument(searchRequestBuilder);
}
/**
* 向ES发送搜索文档的请求,返回列表结果
*
* @param searchText 搜索内容
* @param start 起始位置
* @param size 获取数据大小
* @return 返回数据列表
* @throws Exception
*/
public List<T> searchDocument(String searchText, int start, int size) throws Exception {
SearchRequestBuilder searchRequestBuilder = client.prepareSearch(index)
.setTypes(type)
.setQuery(QueryBuilders.matchQuery("_all", searchText))
.setFrom(start)
.setSize(size)
.setFetchSource(true);
PageResponse<T> pageResponse = searchDocument(searchRequestBuilder);
return pageResponse.getItemList();
}
/**
* 向ES发送搜索文档的请求,返回列表结果
*
* @param searchText 搜索内容
* @param type 类型
* @param start 起始位置
* @param size 数据大小
* @return 返回数据列表
* @throws Exception
*/
public List<T> searchDocument(String searchText, String type, int start, int size) throws Exception {
SearchRequestBuilder searchRequestBuilder = client.prepareSearch(index)
.setTypes(type)
.setQuery(QueryBuilders.matchQuery("_all", searchText))
.setFrom(start)
.setSize(size)
.setFetchSource(true);
PageResponse<T> pageResponse = searchDocument(searchRequestBuilder);
return pageResponse.getItemList();
}
/**
* 向ES发送搜索文档的请求,返回分页结果
*
* @param searchRequestBuilder 搜索构造器
* @return 分页结果
* @throws Exception
*/
public PageResponse<T> searchDocument(SearchRequestBuilder searchRequestBuilder) throws Exception {
SearchResponse searchResponse = search(searchRequestBuilder);
return searchResponseToPageResponse(searchResponse);
}
/**
* 获得scrollId对应的数据. 请查看{@link #getScrollId(SearchRequestBuilder, int, int)}.<br/>
* 可以反复调用该方法, 直到返回数据为0.
*
* @param scrollId 给定的scrollId
* @param keepSeconds scroll数据保留时间
* @return 分页结果
* @throws Exception
*/
public PageResponse<T> scrollSearchDocument(String scrollId, int keepSeconds) throws Exception {
return searchResponseToPageResponse(scrollSearch(scrollId, keepSeconds));
}
/**
* 向ES发送搜索请求,然后直接返回原始结果。
*
* @param searchRequestBuilder 搜索构造器
* @return 返回结果
*/
public SearchResponse search(SearchRequestBuilder searchRequestBuilder) {
return searchRequestBuilder.setTypes(type).execute().actionGet();
}
/**
* 向ES发送搜索请求,然后直接返回原始结果。
*
* @param searchRequestBuilder 搜索构造器
* @param type 类型
* @return 返回结果
*/
@Deprecated
public SearchResponse search(SearchRequestBuilder searchRequestBuilder, String type) {
return searchRequestBuilder.setTypes(type).execute().actionGet();
}
/**
* 通过scrollId获得数据.请查看{@link #getScrollId(SearchRequestBuilder, int, int)}.<br/>
* 可以反复调用该方法, 直到返回数据为0.
*
* @param scrollId 给定的scrollId
* @param keepSeconds scroll继续保留的时间, 建议60秒
* @return 返回获取的数据
*/
public SearchResponse scrollSearch(String scrollId, int keepSeconds) {
return client.prepareSearchScroll(scrollId).setScroll(new TimeValue(keepSeconds * 1000))
.execute().actionGet();
}
/**
* 提供搜索构造器来获得搜索scrollId, 这个scrollId用作{@link #scrollSearch(String, int)}
* 和{@link #scrollSearchDocument(String, int)}的参数. <br/>
* 当需要获取大量数据的时候, 请使用scrollSearch来进行.
*
* @param searchRequestBuilder 搜索构造器
* @param keepSeconds scroll搜索保留时间, 建议60秒
* @param sizePerShard 每次每个分片获取的尺寸
* @return 返回scrollId, 用于scrollSearch方法.
*/
public String getScrollId(SearchRequestBuilder searchRequestBuilder, int keepSeconds, int sizePerShard) {
SearchResponse searchResponse = searchRequestBuilder.setSearchType(SearchType.SCAN)
.setScroll(new TimeValue(keepSeconds * 1000))
.setSize(sizePerShard).execute().actionGet();
return searchResponse.getScrollId();
}
/**
* 返回搜索指定内容后,总共ES找到匹配的数据量。
*
* @param searchText 搜索内容
* @return 搜索结果数据量
*/
@Deprecated
public long countSearchResult(String searchText) {
CountRequestBuilder countRequestBuilder = client.prepareCount(index)
.setTypes(type)
.setQuery(QueryBuilders.matchQuery("_all", searchText));
return countSearchResult(countRequestBuilder);
}
/**
* 返回搜索指定内容后,总共ES找到匹配的数据量。
*
* @param searchText 搜索内容
* @param type 类型
* @return 搜索结果数据量
*/
@Deprecated
public long countSearchResult(String searchText, String type) {
CountRequestBuilder countRequestBuilder = client.prepareCount(index)
.setTypes(type)
.setQuery(QueryBuilders.matchQuery("_all", searchText));
return countSearchResult(countRequestBuilder);
}
/**
* 返回搜索指定内容后,总共ES找到匹配的数据量。
*
* @param countRequestBuilder 计数请求构造器实例
* @return 搜索结果数据量
* @see #prepareCount()
*/
@Deprecated
public long countSearchResult(CountRequestBuilder countRequestBuilder) {
return countRequestBuilder.execute().actionGet().getCount();
}
/**
* 用默认的分词器进行文本分词。
*
* @param docText 给定的文本
* @param order 是否使用排序,如果使用排序,则相同分词会被合并,并且出现次数最高的排在返回列表最头部。
* @return 分词器将文本分词之后的词语列表
*/
public List<String> analyzeDocument(String docText, boolean order) {
List<AnalyzeToken> tokenList = analyzeDocument(docText, DEFAULT_ANALYZER);
if (order) {
// 如果是使用排序,按照分词出现次数进行排序,并且会合并相同的分词。
// 构造分词Map,key为分词,value为出现次数。
Map<String, Integer> tokenMap = Maps.newHashMap();
for (AnalyzeToken token : tokenList) {
if (tokenMap.get(token.getTerm()) == null) {
tokenMap.put(token.getTerm(), 1);
} else {
tokenMap.put(token.getTerm(), tokenMap.get(token.getTerm()) + 1);
}
}
// 将分词Map进行排序
List<Map.Entry<String, Integer>> tokenSortList = Ordering.from(new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return o2.getValue().compareTo(o1.getValue());
}
}).sortedCopy(tokenMap.entrySet());
// 返回分词列表。
return Lists.transform(tokenSortList, new Function<Map.Entry<String, Integer>, String>() {
@Override
public String apply(Map.Entry<String, Integer> input) {
return input.getKey();
}
});
} else {
// 返回所有分词结果
return Lists.transform(tokenList, new Function<AnalyzeToken, String>() {
@Override
public String apply(AnalyzeToken input) {
return input.getTerm();
}
});
}
}
/**
* 用指定分词器来分析给定的文本
*
* @param docText 给定的文本
* @param analyzer 指定的分析器
* @return 分词器将文本分词之后的词语列表
*/
public List<AnalyzeToken> analyzeDocument(String docText, String analyzer) {
AnalyzeResponse analyzeResponse = client.admin().indices().prepareAnalyze(index, docText)
.setAnalyzer(analyzer)
.execute().actionGet();
return analyzeResponse.getTokens();
}
/**
* 获得一个搜索请求构造器的实例,通过这个实例,可以进行查询相关操作。<br/>
* 使用这个方法{@link ESClient#searchDocument(SearchRequestBuilder)}进行查询。
* <pre>
* prepareSearch("telepathy")
* .setTypes("article")
* .setSearchType(SearchType.QUERY_THEN_FETCH)
* .setQuery(QueryBuilders.matchQuery("_all", searchText))
* .setFrom(pageRequest.getLimit() * (pageRequest.getPage() - 1))
* .setSize(pageRequest.getLimit())
* .setExplain(true)
* .addHighlightedField("title", 100, 1)
* .setFetchSource(new String[]{}, new String[]{});
* </pre>
*
* @return 搜索请求构造器实例
*/
public SearchRequestBuilder prepareSearch() {
return client.prepareSearch(index);
}
/**
* 获得一个计数请求构造器的实例,通过这个实例可以进行查询选项的构造。
*
* @return 计数请求构造器实例
* @see #prepareSearch()
*/
@Deprecated
public CountRequestBuilder prepareCount() {
return client.prepareCount(index);
}
/**
* 获得一个Document的term vector (doc frequency, positions, offsets)
*
* @return TermVectorResponse
* @see #termVector()
*/
public ActionFuture<TermVectorResponse> termVector(TermVectorRequest request) {
return client.termVector(request);
}
/**
* 将SQL转换成ES的JSON查询对象.
*
* @param sql 给定的SQL
* @return JSON对象
*/
public JSONObject convertSqlToJSON(String sql) {
if (sqlJsonMap.get(sql) != null) {
return sqlJsonMap.get(sql);
}
List<String> addresses = Lists.newArrayList(serverHttpAddressList);
while (addresses.size() > 0) {
String sqlPluginUrl = "http://" + addresses.remove(RandomUtils.nextInt(0, addresses.size())) + "/_sql/_explain";
try {
JSONObject json = JSONObject.parseObject(
MucangHttpClient.getDefault().httpPostBody(sqlPluginUrl, sql, "text/plain")
);
sqlJsonMap.put(sql, json);
return json;
} catch (Exception e) {
LOG.error("调用elasticsearch-sql插件时遇到错误, 原因:{}", e);
}
}
throw new RuntimeException("调用elasticsearch-sql插件多次失败, 请检查服务器或者插件功能是否正常.");
}
/**
* 用SQL语句进行搜索. 使用${keyName}的方式代表需要替换的字符串(需要替换的字符串请用双引号或者单引号引起来, 否则插件不能解析)<br/>
* 例如: select * from table where mediaId="${mediaId}"<br/>
*
* @param sql 指定的SQL
* @param kvPairs 替换键值对
* @return 搜索结果
* @throws Exception
*/
public SearchResponse searchSql(String sql, final Map<String, String> kvPairs) throws Exception {
JSONObject jsonQuery = convertSqlToJSON(sql);
PropertyPlaceholderHelper propertyPlaceholderHelper = new PropertyPlaceholderHelper("${", "}");
String queryString = propertyPlaceholderHelper.replacePlaceholders(
jsonQuery.toJSONString(),
new PropertyPlaceholderHelper.PlaceholderResolver() {
@Override
public String resolvePlaceholder(String placeholderName) {
if (StringUtils.isBlank(kvPairs.get(placeholderName))) {
return "";
} else {
return kvPairs.get(placeholderName);
}
}
});
SearchRequestBuilder searchRequestBuilder = prepareSearch()
.setSource(XContentFactory.jsonBuilder().value(JSONObject.parseObject(queryString)));
return search(searchRequestBuilder);
}
/**
* 将给定的对象转换成JSON字符串,如果有特殊需求,可以覆盖该方法。
*
* @param t 给定的对象
* @return JSON字符串
*/
public String toJSONString(T t) {
return JSON.toJSONString(t);
}
/**
* 将给定的Map里面的值注入到目标对象。如果有特殊需求,可以覆盖该方法。
*
* @param t 目标对象
* @param map 给定的map
* @throws Exception
*/
public void toObject(T t, Map<String, ?> map) throws Exception {
dozerBeanMapper.map(map, t);
}
/**
* 将BulkProcessor的缓冲内容进行立即提交.
*/
public void flushBulk() {
this.bulkProcessor.flush();
}
public BulkProcessor getBulkProcessor() {
return bulkProcessor;
}
public void setBulkProcessor(BulkProcessor bulkProcessor) {
this.bulkProcessor = bulkProcessor;
}
public PageResponse<T> searchResponseToPageResponse(SearchResponse searchResponse) throws Exception {
PageResponse<T> pageResponse = new PageResponse<>();
for (SearchHit searchHit : searchResponse.getHits().getHits()) {
// 将结果实例化成对应的类型实例
T t = this.clazz.newInstance();
Map<String, Object> hitMap;
if (searchHit.getSource() != null) {
hitMap = searchHit.getSource();
} else {
hitMap = Maps.newHashMap(Maps.transformValues(searchHit.getFields(),
new Function<SearchHitField, Object>() {
@Override
public Object apply(SearchHitField input) {
return input.getValues();
}
}
));
}
for (HighlightField highlightField : searchHit.getHighlightFields().values()) {
hitMap.put(highlightField.getName(),
StringUtils.join(highlightField.getFragments(), "..."));
}
// 将数据转换成对应的实例
toObject(t, hitMap);
pageResponse.getItemList().add(t);
}
pageResponse.setTotal(searchResponse.getHits().getTotalHits());
return pageResponse;
}
/**
* 关闭native的链接.
*/
public void close() {
IOUtils.closeQuietly(bulkProcessor);
this.client.close();
}
}如果有问题大家可以留言一起交流, 我也是一个es初学者。
【ES】ElasticSearch初体验之使用Java进行最基本的增删改查~的更多相关文章
- java对xml文件做增删改查------摘录
java对xml文件做增删改查 package com.wss; import java.io.File;import java.util.ArrayList;import java.util.Lis ...
- 使用java对sql server进行增删改查
import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import ...
- Java API实现Hadoop文件系统增删改查
Java API实现Hadoop文件系统增删改查 Hadoop文件系统可以通过shell命令hadoop fs -xx进行操作,同时也提供了Java编程接口 maven配置 <project x ...
- Es图形化软件使用之ElasticSearch-head、Kibana,Elasticsearch之-倒排索引操作、映射管理、文档增删改查
今日内容概要 ElasticSearch之-ElasticSearch-head ElasticSearch之-安装Kibana Elasticsearch之-倒排索引 Elasticsearch之- ...
- ElasticSearch6(三)-- Java API实现简单的增删改查
基于ElasticSearch6.2.4, Java API创建索引.查询.修改.删除,pom依赖和获取es连接 可查看此文章. package com.xsjt.learn; import java ...
- Java项目——模拟电话薄联系人增删改查
该项目模拟了电话本记录联系人的业务功能,用来练习对数据库的增删改查等操作. 菜单类:Menu -- 用来封装主菜单和个选项的子菜单 Person类: Person--联系人的实体类 TelNoteRe ...
- Java Web(十) JDBC的增删改查,C3P0等连接池,dbutils框架的使用
前面做了一个非常垃圾的小demo,真的无法直面它,菜的抠脚啊,真的菜,好好努力把.菜鸡. --WH 一.JDBC是什么? Java Data Base Connectivity,java数据库连接,在 ...
- java对sql server的增删改查
package Database; import java.sql.*; public class DBUtil { //这里可以设置数据库名称 private final static String ...
- Java连接GBase并封装增删改查
1.介绍 GBase 是南大通用数据技术有限公司推出的自主品牌的数据库产品,目前在国内数据库市场具有较高的品牌知名度;GBase品牌的系列数据库都具有自己鲜明的特点和优势:GBase 8a 是国内第一 ...
随机推荐
- JMS 之 Active MQ 消息存储
一.消息的存储方式 ActiveMQ支持JMS规范中的持久化消息与非持久化消息 持久化消息通常用于不管是否消费者在线,它们都会保证消息会被消费者消费.当消息被确认消费后,会从存储中删除 非持久化消息通 ...
- springmvc 之 SpringMVC视图解析器
当我们对SpringMVC控制的资源发起请求时,这些请求都会被SpringMVC的DispatcherServlet处理,接着Spring会分析看哪一个HandlerMapping定义的所有请求映射中 ...
- An internal error occurred during: "Launching New_configuration"
问题: 点击运行时eclipse报错如下: An internal error occurred during: "Launching New_configuration". Pa ...
- 使用CSS3动画实现绚丽的照片墙效果
临近毕业了,一大波毕业照又要来袭了!如何使用CSS3属性制作出自己的网页版照片墙呢? 闲话少说,先来看看效果图 效果要求: 1,照片要求有一定的白色边框. 2,照片都要有一定的倾斜角度. 3,鼠标移动 ...
- js实现htmlToWordDemo
之前由于工作需要,需要实现将html内的一部分内容直接转为word和pdf的功能.就研究了一下方法并且实现了两个demo.今天先说一下html to word(才疏学浅,仅供交流,如有错误,请指出). ...
- ionic结合HTML5实现打电话功能
HTML5中这样子可以实现打电话的功能,但是在ionic实际项目中,并不是直接就可以这样子用,需要配置一下config.xml文件就可以在手机上调用到自己的联系人打电话页面了, 因为项目是引用的Cor ...
- 解决安卓手机input获取焦点时会将底部固定定位按钮顶起的问题
一个页面上有个固定在底部的按钮,页面中有个input框,点击input框获取焦点时,在苹果手机上没事,但在安卓手机上弹出的键盘会将按钮顶起来,这就很不好看了,想了个办法解决一下.之前一直觉得用inpu ...
- 【分享】我们用了不到200行代码实现的文件日志系统,极佳的IO性能和高并发支持,附压力测试数据
很多项目都配置了日志记录的功能,但是,却只有很少的项目组会经常去看日志.原因就是日志文件生成规则设置不合理,将严重的错误日志跟普通的错误日志混在一起,分析起来很麻烦. 其实,我们想要的一个日志系统核心 ...
- jquery里的attr()方法和prop()方法的区别
在jq的高版本里出现了prop()方法,那么attr()和prop()的区别在哪呢?这两者分别在什么情况用呢? 对于HTML元素本身就带有的固有属性,在处理时,使用prop方法. 对于HTML元素我们 ...
- MySQL left join操作中 on与where放置条件的区别
优先级 两者放置相同条件,之所以可能会导致结果集不同,就是因为优先级.on的优先级是高于where的. 1 1 首先明确两个概念: LEFT JOIN 关键字会从左表 (table_name1) 那里 ...