浅谈PipelineDB系列一: Stream数据是如何写到Continuous View中的
PipelineDB Version:0.9.7
PostgreSQL Version:9.5.3
PipelineDB的数据处理组件:
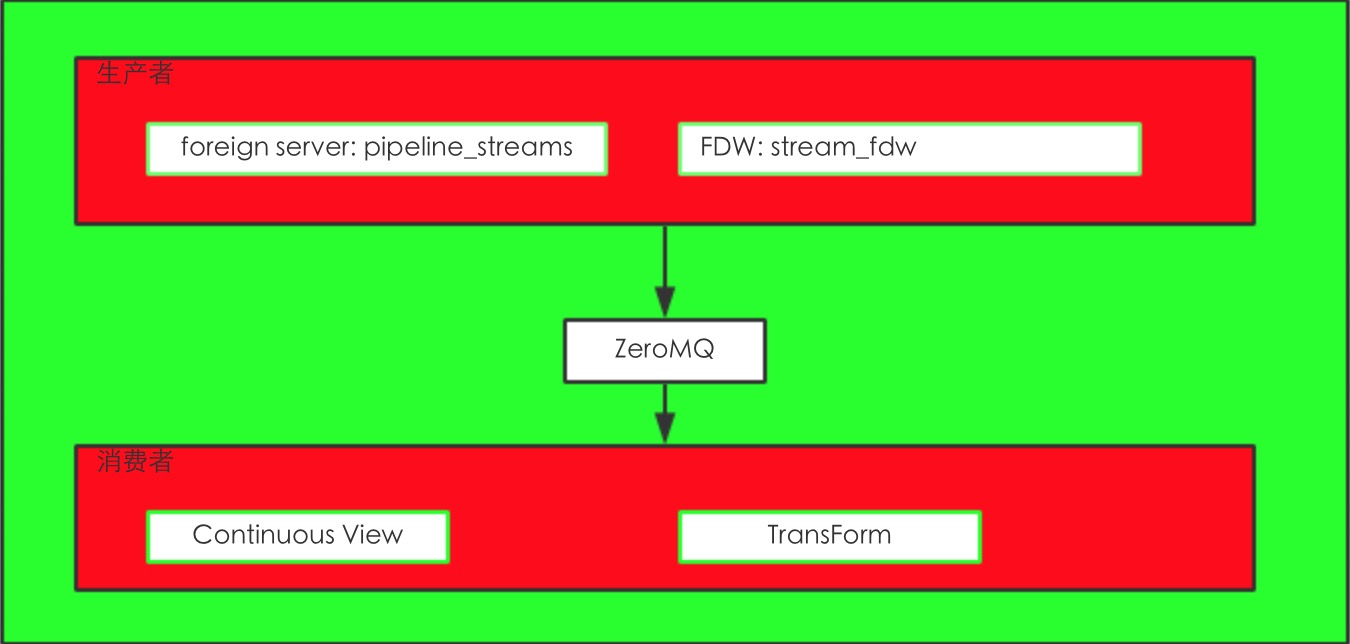
从上图来看主要就是pipeline_streams,stream_fdw,Continuous View,Transform。
其实就是运用了Postgres的FDW功能来实现的stream功能。
从数据库也能看到这个FDW
pipeline=# \des
List of foreign servers
Name | Owner | Foreign-data wrapper
------------------+-----------------+----------------------
pipeline_streams | unknown (OID=0) | stream_fdw
(1 row)
数据流转入下图
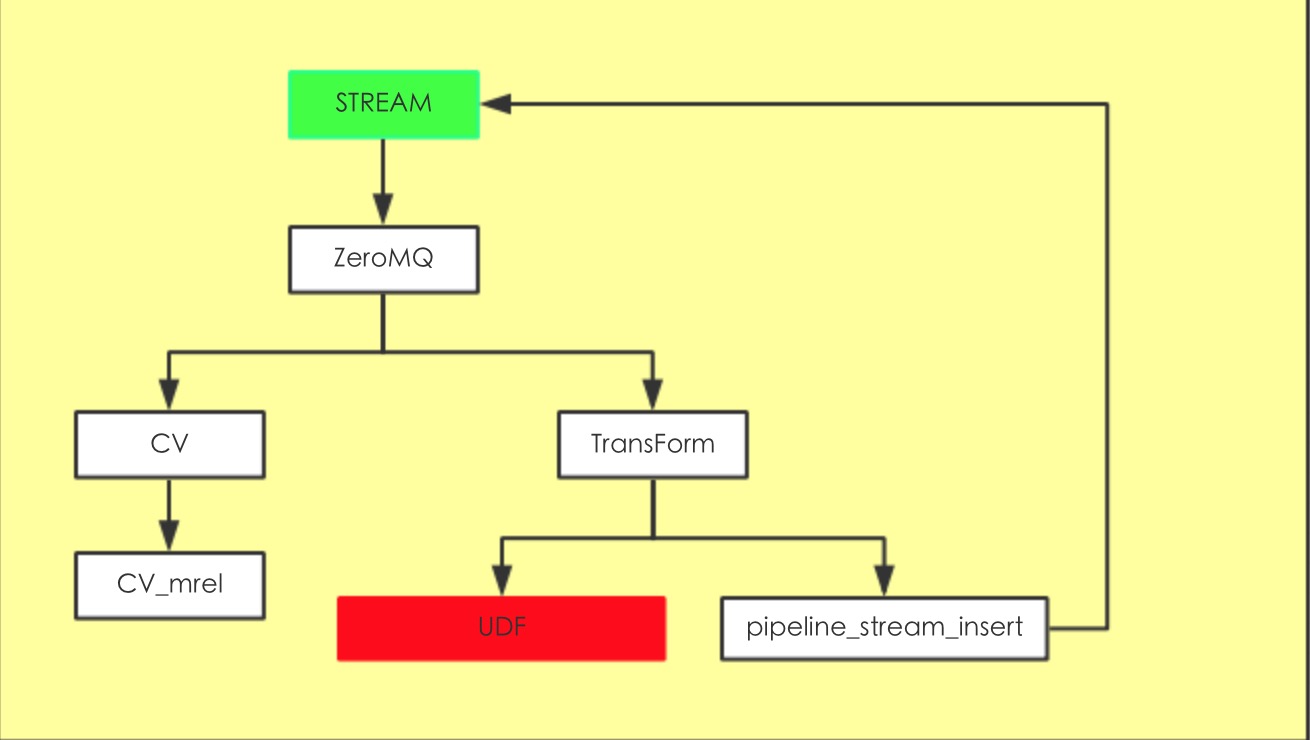
可以看到数据流转都是通过ZeroMQ来实现的(前面的版本0.8.2之前是通过TupleBuff来实现)
数据插入到Stream后然后调用ForiegnInsert,插入到初始化的IPC里面去,在数据库目录下面有个pipeline/zmq
TransForm其实就是把数据的dest指向了Stream,数据库默认有个pipeline_stream_insert其实这个是个Trigger,把tuple再扔到目标stream里面。
或者你可以自己写UDF,就是写个trigger,数据可以写到表或者别的FDW里面,或者是自己封装的消息队列IPC都没问题,这块自由发挥的空间就比较大。
首先我们来创建个STREAM跟CV
pipeline=# create stream my_stream(x bigint,y bigint,z bigint);
CREATE STREAM
pipeline=# create continuous view v_1 as select x,y,z from my_stream;
CREATE CONTINUOUS VIEW
pipeline=#
插入一条数据:
pipeline=# insert into my_stream(x,y,z) values(1,2,3);
INSERT 0 1
pipeline=# select * from v_1;
x | y | z
---+---+---
1 | 2 | 3
(1 row) pipeline=#
数据插入到CV中了,我们现在来看看PipelineDB是如何插入的。
上面有介绍了Stream就是个FDW。我们来看看他的handler(source:src/backend/pipeline/stream_fdw.c)
/*
* stream_fdw_handler
*/
Datum
stream_fdw_handler(PG_FUNCTION_ARGS)
{
FdwRoutine *routine = makeNode(FdwRoutine); /* Stream SELECTS (only used by continuous query procs) */
routine->GetForeignRelSize = GetStreamSize;
routine->GetForeignPaths = GetStreamPaths;
routine->GetForeignPlan = GetStreamScanPlan;
routine->BeginForeignScan = BeginStreamScan;
routine->IterateForeignScan = IterateStreamScan;
routine->ReScanForeignScan = ReScanStreamScan;
routine->EndForeignScan = EndStreamScan; /* Streams INSERTs */
routine->PlanForeignModify = PlanStreamModify;
routine->BeginForeignModify = BeginStreamModify;
routine->ExecForeignInsert = ExecStreamInsert;
routine->EndForeignModify = EndStreamModify; routine->ExplainForeignScan = NULL;
routine->ExplainForeignModify = NULL; PG_RETURN_POINTER(routine);
}
主要是关注Streams Inserts这几个函数.
每个worker process启动的时候都会初始化一个recv_id,其实这个就是ZeroMQ的ID
数据会发送到对应的队列里面去,worker process就去这个IPC里面去获取数据
source:src/backend/pipeline/ipc/microbath.c
void
microbatch_send_to_worker(microbatch_t *mb, int worker_id)
{
...... worker_id = rand() % continuous_query_num_workers;
}
} recv_id = db_meta->db_procs[worker_id].pzmq_id; microbatch_send(mb, recv_id, async, db_meta);
microbatch_reset(mb);
}
首先是获取worker_id 这个是随机获取的一个worker进程。stream数据随机发到一worker process里面去了
recv_id这个就是从初始化的IPC队列获取ID,数据就发送到该队列里面
最后就调用
pzmq_send(recv_id, buf, len, true)
数据就推送到了IPC中了。
(gdb) p recv_id
$12 = 1404688165
(gdb)
这部分就是数据生产者部分。
下面就是数据消费者CV
数据接受还是通过ZMQ的API来接受的
这个主要是worker process来干活的
srouce:src/backend/pipeline/ipc/pzmq.c&reader.c
(gdb) p *zmq_state->me
$8 = {id = 1404688165, type = 7 '\a', sock = 0x1139ba0, addr = "ipc:///home/pipeline/db_0.9.7/pipeline/zmq/1404688165.sock", '\000' <repeats 965 times>}
(gdb)
可以看到这个数据是从1404688165里面获取的 ,并且把IPC的addr也给出来了,这个就是我数据库目录
获取到是个buf,然后unpack,从消息里面获取到对应的Tuple.
获取到了tuple后,然后就找所有的CV跟这个stream相关的target。遍历他们,然后执行CV中对应的SQL。
执行流程跟标准SQL差不多也是初始化执行计划然后ExecutePlan然后endplan 。
数据会到Combiner里面,如果是AGG还会有一系列操作的。
如果数据符合CV的SQL逻辑,那么数据就插入到对应的物理表。
这就是Stream的一个简单的工作原理。
谢谢
浅谈PipelineDB系列一: Stream数据是如何写到Continuous View中的的更多相关文章
- 浅谈POSIX线程的私有数据
当线程中的一个函数需要创建私有数据时,该私有数据在对函数的调用之间保持一致,数据能静态地分配在存储器中,当我们采用命名范围也许可以实现它使用在函数或是文件(静态),或是全局(EXTERN).但是当涉及 ...
- 浅谈c#的三个高级参数ref out 和Params C#中is与as的区别分析 “登陆”与“登录”有何区别 经典SQL语句大全(绝对的经典)
浅谈c#的三个高级参数ref out 和Params c#的三个高级参数ref out 和Params 前言:在我们学习c#基础的时候,我们会学习到c#的三个高级的参数,分别是out .ref 和 ...
- 浅谈ASP.net处理XML数据
XML是一种可扩展的标记语言,比之之前谈到的html有着很大的灵活性,虽然它只是与HTML仅有一个字母只差,但两者有很大的区别. XML也是标记语言,所以它每个标签必须要闭合,而HTML偶尔忘了闭合也 ...
- sqlite升级--浅谈Android数据库版本升级及数据的迁移
Android开发涉及到的数据库采用的是轻量级的SQLite3,而在实际开发中,在存储一些简单的数据,使用SharedPreferences就足够了,只有在存储数据结构稍微复杂的时候,才会使用数据库来 ...
- 浅谈c语言代码段 数据段 bss段
代码段.数据段.bss段 (1)编译器在编译程序的时候,将程序中的所有的元素分成了一些组成部分,各部分构成一个段,所以说段是可执行程序的组成部分. (2)代码段:代码段就是程序中的可执行部分,直观理解 ...
- 浅谈Xcode5和Xcode7在系统创建的文件夹和文件中的区别
*:first-child { margin-top: 0 !important; } body > *:last-child { margin-bottom: 0 !important; } ...
- 【WebApi系列】浅谈HTTP
[01]浅谈HTTP在WebApi开发中的运用 [02]聊聊WebApi体系结构 [03]详解WebApi如何传递参数 [04]详解WebApi测试和PostMan [05]浅谈WebApi Core ...
- 【WebApi系列】浅谈HTTP在WebApi开发中的运用
WebApi系列文章 [01]浅谈HTTP在WebApi开发中的运用 [02]聊聊WebApi体系结构 [03]详解WebApi参数的传递 [04]详解WebApi测试和PostMan [05]浅谈W ...
- 浅谈如何使用python抓取网页中的动态数据
我们经常会发现网页中的许多数据并不是写死在HTML中的,而是通过js动态载入的.所以也就引出了什么是动态数据的概念, 动态数据在这里指的是网页中由Javascript动态生成的页面内容,是在页面加载到 ...
随机推荐
- Java中的类变量、实例变量、类方法、实例方法的区别
类变量:形如static int a; 顾名思义,类变量可以理解为类的变量,类变量在类加载的时候就已经给它分配了内存空间,不同于实例变量(int a; ),实例变量是在该类创建对象的时候分配内存的.并 ...
- runtime--小白看过来
目录 RunTime 概述 RunTime消息机制 RunTime交换方法 RunTime消息转发 RunTime关联对象 RunTime实现字典与模型互转 1.RunTime 概述 我们在面试的时候 ...
- C++ new 解析重载
C++ new 解析重载 new的三种形式: (1)operator new(运算符new) (2)new operator(new 操作) (3)placement new(特殊的new操作)(不分 ...
- 基于winsocket的框体Server和Client
前面学了一点Winsock的知识,会编写简单的Server和Client,现在就想通过VS2008编写框体的Server和Client,而不是在控制台上的操作了,毕竟学编程就是要多加练习,在实践中发现 ...
- The Euler function(线性筛欧拉函数)
/* 题意:(n)表示小于n与n互质的数有多少个,给你两个数a,b让你计算a+(a+1)+(a+2)+......+b; 初步思路:暴力搞一下,打表 #放弃:打了十几分钟没打完 #改进:欧拉函数:具体 ...
- rsync远程数据同步工具的使用
准备工作 虚拟机1: 192.168.24.41, 用于搭建rsync服务器 虚拟机2: 192.168.26.68, 用于搭建rsync客户端 虚拟机1和虚拟机2均为centos7; 1. 检查虚拟 ...
- 强大又简单的响应式框架——Foundation 网格系统
前端框架——Foundation 简介 Foundation 用于开发响应式的 HTML, CSS and JavaScript 框架. Foundation 是一个易用.强大而且 ...
- JSON相关知识整理
JSON 全称:JavaScript Object Notation ,一种轻量级的数据交换格式 示例:{"name":"eric","age&q ...
- VUE父子组件传值问题
一.父组件向子组件传递数据 组件实例的作用域是孤立的.这意味着不能(也不应该)在子组件的模板内直接引用父组件的数据.要让子组件使用父组件的数据,我们需要通过子组件的props选项. 1.静态props ...
- Centos下配置tomcat7的https证书
近期搞定了HTTPS配置,特此记录. 1.把下载的文件拷贝到cert文件夹,然后放在tomcat根目录下(与conf同一级目录).2.配置conf下的server.xml,修改下面3个节点,如下: & ...