资深实践篇 | 基于Kubernetes 1.61的Kubernetes Scheduler 调度详解
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~
作者:腾讯云容器服务团队
源码为 k8s v1.6.1 版本,github 上对应的 commit id 为 b0b7a323cc5a4a2019b2e9520c21c7830b7f708e
本文将对 Scheduler 的调度算法原理和执行过程进行分析,重点介绍 Scheduler 算法中预选和优选的相关内容。
Kubernetes Scheduler的基本功能
Kubernetes Scheduler 的作用是根据特定的调度算法将pod调度到指定的工作节点(Node)上,这一过程也叫绑定(bind)。Scheduler 的输入为需要调度的 Pod 和可以被调度的节点(Node)的信息,输出为调度算法选择的 Node,并将该 pod bind 到这个 Node 。
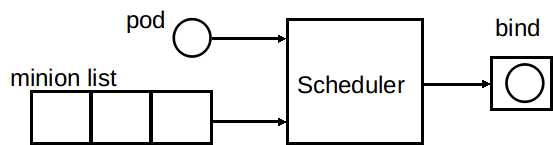
Kubernetes Scheduler中调度算法分为两个阶段:
预选 : 根据配置的 Predicates Policies(默认为 DefaultProvider 中定义的 default predicates policies 集合)过滤掉那些不满足Policies的的Nodes,剩下的Nodes作为优选的输入。
优选 : 根据配置的 Priorities Policies(默认为 DefaultProvider 中定义的 default priorities policies 集合)给预选后的Nodes进行打分排名,得分最高的Node即作为最适合的Node,该Pod就Bind到这个Node。

预选规则详细说明
预先规则主要用于过滤出不符合规则的Node节点,剩下的节点作为优选的输入。在1.6.1版本中预选规则包括:
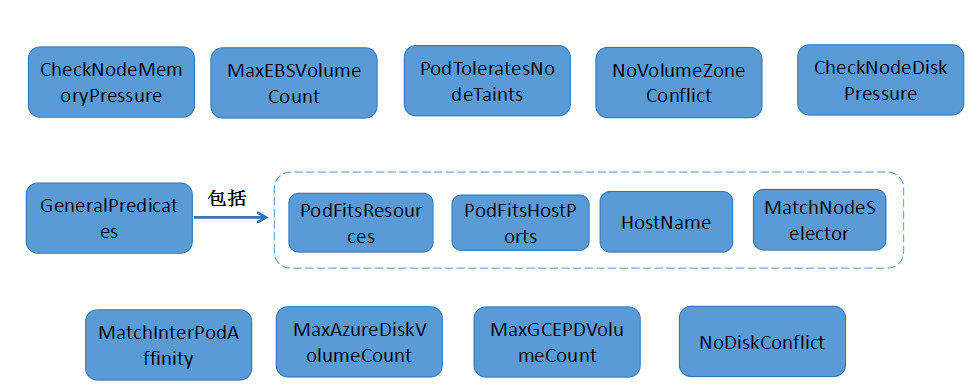
详细的规则说明:
(1) NoDiskConflict : 检查在此主机上是否存在卷冲突。如果这个主机已经挂载了卷,其它使用这个卷的Pod不能调度到这个主机上。GCE 、Amazon EBS 和 Ceph RBD 使用的规则如下:
- GCE 允许同时挂载多个卷,只要这些卷都是只读的。
- Amazon EBS 不允许不同的 Pod 挂载同一个卷。
- Ceph RBD 不允许任何两个 pods 分享相同的 monitor,match pool 和 image。
注:ISCSI 与 GCE 一样,在卷都是只读的情况下,允许挂载两个 IQN 相同的卷。
(2) NoVolumeZoneConflict : 检查在给定的 zone 限制前提下,检查在此主机上部署 Pod 是否存在卷冲突,目前指对 PV 资源进行检查(NewVolumeZonePredicate对象predicate函数)。
(3) MaxEBSVolumeCount : 确保已挂载的 EBS 存储卷不超过设置的最大值。默认值是39。它会检查直接使用的存储卷,和间接使用这种类型存储的 PVC 。计算不同卷的总目,如果新的 Pod 部署上去后卷的数目会超过设置的最大值,那么 Pod 就不能调度到这个主机上。
(4) MaxGCEPDVolumeCount : 确保已挂载的 GCE 存储卷不超过设置的最大值。默认值是16。规则同MaxEBSVolumeCount。
(5) MaxAzureDiskVolumeCount : 确保已挂载的Azure存储卷不超过设置的最大值。默认值是16。规则同MaxEBSVolumeCount。
(6) CheckNodeMemoryPressure : 判断节点是否已经进入到内存压力状态,如果是则只允许调度内存为0标记的 Pod。
(7) CheckNodeDiskPressure : 判断节点是否已经进入到磁盘压力状态,如果是则不调度新的Pod。
(8) PodToleratesNodeTaints : Pod 是否满足节点容忍的一些条件。
(9) MatchInterPodAffinity : 节点亲和性筛选。
(10) GeneralPredicates : 包含一些基本的筛选规则(PodFitsResources、PodFitsHostPorts、HostName、MatchNodeSelector)。
(11) PodFitsResources : 检查节点上的空闲资源(CPU、Memory、GPU资源)是否满足 Pod 的需求。
(12) PodFitsHostPorts : 检查 Pod 内每一个容器所需的 HostPort 是否已被其它容器占用。如果有所需的HostPort不满足要求,那么 Pod 不能调度到这个主机上。
(13) 检查主机名称是不是 Pod 指定的 HostName。
(14) 检查主机的标签是否满足 Pod 的 nodeSelector 属性需求。
优选规则详细说明
优选规则对符合需求的主机列表进行打分,最终选择一个分值最高的主机部署 Pod。kubernetes 用一组优先级函数处理每一个待选的主机。每一个优先级函数会返回一个0-10的分数,分数越高表示主机越“好”,同时每一个函数也会对应一个表示权重的值。最终主机的得分用以下公式计算得出:
finalScoreNode = (weight1 priorityFunc1) + (weight2 priorityFunc2) + … + (weightn * priorityFuncn)

详细的规则说明:
(1) SelectorSpreadPriority : 对于属于同一个 service、replication controller 的 Pod,尽量分散在不同的主机上。如果指定了区域,则会尽量把 Pod 分散在不同区域的不同主机上。调度一个 Pod 的时候,先查找 Pod 对于的 service或者 replication controller,然后查找 service 或 replication controller 中已存在的 Pod,主机上运行的已存在的 Pod 越少,主机的打分越高。
(2) LeastRequestedPriority : 如果新的 pod 要分配一个节点,这个节点的优先级就由节点空闲的那部分与总容量的比值((总容量-节点上pod的容量总和-新pod的容量)/总容量)来决定。CPU 和 memory 权重相当,比值最大的节点的得分最高。需要注意的是,这个优先级函数起到了按照资源消耗来跨节点分配 pods 的作用。计算公式如下:
cpu((capacity – sum(requested)) 10 / capacity) + memory((capacity – sum(requested)) 10 / capacity) / 2
(3) BalancedResourceAllocation : 尽量选择在部署 Pod 后各项资源更均衡的机器。BalancedResourceAllocation 不能单独使用,而且必须和 LeastRequestedPriority 同时使用,它分别计算主机上的 cpu 和 memory 的比重,主机的分值由 cpu 比重和 memory 比重的“距离”决定。计算公式如下:score = 10 – abs(cpuFraction-memoryFraction)*10
(4) NodeAffinityPriority : Kubernetes 调度中的亲和性机制。Node Selectors(调度时将 pod 限定在指定节点上),支持多种操作符(In、 NotIn、 Exists、DoesNotExist、 Gt、 Lt),而不限于对节点 labels 的精确匹配。另外,Kubernetes 支持两种类型的选择器,一种是 “ hard(requiredDuringSchedulingIgnoredDuringExecution)” 选择器,它保证所选的主机满足所有Pod对主机的规则要求。这种选择器更像是之前的 nodeselector,在 nodeselector 的基础上增加了更合适的表现语法。另一种 “ soft(preferresDuringSchedulingIgnoredDuringExecution)” 选择器,它作为对调度器的提示,调度器会尽量但不保证满足 NodeSelector 的所有要求。
(5) InterPodAffinityPriority : 通过迭代 weightedPodAffinityTerm 的元素计算和,并且如果对该节点满足相应的PodAffinityTerm,则将 “weight” 加到和中,具有最高和的节点是最优选的。
(6) NodePreferAvoidPodsPriority(权重1W) : 如果 Node 的 Anotation 没有设置 key-value:scheduler. alpha.kubernetes.io/ preferAvoidPods = "...",则该 node 对该 policy 的得分就是10分,加上权重10000,那么该node对该policy的得分至少10W分。如果Node的Anotation设置了,scheduler.alpha.kubernetes.io/preferAvoidPods = "..." ,如果该 pod 对应的 Controller 是 ReplicationController 或 ReplicaSet,则该 node 对该 policy 的得分就是0分。
(7) TaintTolerationPriority : 使用 Pod 中 tolerationList 与 Node 节点 Taint 进行匹配,配对成功的项越多,则得分越低。
另外在优选的调度规则中,有几个未被默认使用的规则:
(1) ImageLocalityPriority : 据主机上是否已具备 Pod 运行的环境来打分。ImageLocalityPriority 会判断主机上是否已存在 Pod 运行所需的镜像,根据已有镜像的大小返回一个0-10的打分。如果主机上不存在 Pod 所需的镜像,返回0;如果主机上存在部分所需镜像,则根据这些镜像的大小来决定分值,镜像越大,打分就越高。
(2) EqualPriority : EqualPriority 是一个优先级函数,它给予所有节点一个相等的权重。
(3) ServiceSpreadingPriority : 作用与 SelectorSpreadPriority 相同,已经被 SelectorSpreadPriority 替换。
(4) MostRequestedPriority : 在 ClusterAutoscalerProvider 中,替换 LeastRequestedPriority,给使用多资源的节点,更高的优先级。计算公式为:(cpu(10 sum(requested) / capacity) + memory(10 sum(requested) / capacity)) / 2
相关阅读
td { border: 1px solid #ccc }
br { }
老司机和你深聊Kubenertes 资源分配之 Request 和 Limit 解析
此文已由作者授权腾讯云技术社区发布,转载请注明文章出处
原文链接:https://cloud.tencent.com/community/article/339740
资深实践篇 | 基于Kubernetes 1.61的Kubernetes Scheduler 调度详解的更多相关文章
- Kubernetes K8S之固定节点nodeName和nodeSelector调度详解
Kubernetes K8S之固定节点nodeName和nodeSelector调度详解与示例 主机配置规划 服务器名称(hostname) 系统版本 配置 内网IP 外网IP(模拟) k8s-mas ...
- 基于python中staticmethod和classmethod的区别(详解)
例子 ? 1 2 3 4 5 6 7 8 9 10 11 12 13 class A(object): def foo(self,x): print "executing foo ...
- 基于Python对象引用、可变性和垃圾回收详解
基于Python对象引用.可变性和垃圾回收详解 下面小编就为大家带来一篇基于Python对象引用.可变性和垃圾回收详解.小编觉得挺不错的,现在就分享给大家,也给大家做个参考. 变量不是盒子 在示例所示 ...
- 基于Docker搭建Maven私服Nexus,Nexus详解
备注:首先在linux环境安装Java环境和Docker,私服需要的服务器性能和硬盘存储要高一点,内存不足可能到时启动失败,这里以4核8GLinux服务器做演示 一:基于Docker安装nexus3 ...
- [Kubernetes]PV,PVC,StorageClass之间的关系详解
在Kubernetes中,容器化一个应用比较麻烦的地方莫过于对其"状态"的管理,而最常见的"状态",莫过于存储状态. 在[Kubernetes]深入理解Stat ...
- kubernetes 亲和性调度详解
文章目录 1 概述: 2 场景一:调度到一组具有相同特性的主机上(label+nodeSelector) 3 场景二:部署的应用不想调度到某些节点上(nodeaffinity) 4 场景三:部署的应用 ...
- 基于PBOC电子钱包的圈存过程详解
基于pboc的电子钱包的圈存过程,供智能卡行业的开发人员参考 一. 圈存 首先终端和卡片有一个共同的密钥叫做圈存密钥:LoadKey (Load即圈存的意思,unLoad,是圈提的意思) 假设Lo ...
- 基于pytorch实现HighWay Networks之Highway Networks详解
(一)简述---承接上文---基于pytorch实现HighWay Networks之Train Deep Networks 上文已经介绍过Highway Netwotrks提出的目的就是解决深层神经 ...
- 基于 Web 的远程 Terminal 模拟器安装使用详解
http://lzw.me/a/shellinabox.html 一.Shellinabox 简介 Shellinabox 是一个基于 web 的终端模拟器,采用 C 语言编写,使用 Ajax 与后端 ...
随机推荐
- Docker简介和安装
1.Docker 和传统虚拟化方式的不同之处 传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程: 而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核 ...
- layui + jfinal 实现上传下载
1.需要把jfinal的环境配置好 2.导入相关的库文件 layui的库文件 就是这两个文件需要导入到自己的页面 注意:jfinal总会把路径拦截,所以需要静态文件处理.本人不太懂.就网上找了下,说w ...
- 浅谈JavaScript的apply和call语句
我们试图在回调函数中,用this表示oDiv对象,这样感觉爽. 1 animate(oDiv,{"left":600},2000,function(){ 2 t ...
- Celery 源码解析四: 定时任务的实现
在系列中的第二篇我们已经看过了 Celery 中的执行引擎是如何执行任务的,并且在第三篇中也介绍了任务的对象,但是,目前我们看到的都是被动的任务执行,也就是说目前执行的任务都是第三方调用发送过来的.可 ...
- 关于 ElesticSearch 安装
ElesticSearch windows 下安装步骤 1. 配置 JAVA_HOME 环境变量,因为作者是一个java开发人员,这是基本配置,就不多做赘述 2. 安装ElasticSearch 从官 ...
- SimpleMembership
最近2个月以来,一直在学习MVC,从最开始的2,一直到最新的4.从原来的aspx到现在的Razor引擎,越学越开心,越学越上瘾. 最近为新项目做准备,打算用MVC4,VS2012+SQL2012,反正 ...
- Gitpage + hexo(3.0以上)搭建博客
大半天,一边折腾,一边查找各种文档,写出的这篇文档,不知道有没有把程序表示得足够简明,有不足之处望指明. 前提:已安装好nodeJS和git. 桌面右击进入gitbash,输入npm install ...
- linux操作系统基础篇(七)
Linux服务篇(二) 1.nfs服务的搭建 安装: yum install rpcbind nfs-utils -y 配置: NFS服务的配置文件为 /etc/exports,这个文件是NFS的主要 ...
- MySQL执行一个查询的过程
总体流程 客户端发送一条查询给服务器: 服务器先会检查查询缓存,如果命中了缓存,则立即返回存储在缓存中的结果.否则进入下一阶段: 服务器端进行SQL解析.预处理,再由优化器生成对应的执行计划: MyS ...
- 如何实现 Service 伸缩?- 每天5分钟玩转 Docker 容器技术(97)
上一节部署了只有一个副本的 Service,不过对于 web 服务,我们通常会运行多个实例.这样可以负载均衡,同时也能提供高可用. swarm 要实现这个目标非常简单,增加 service 的副本数就 ...