大文件拆分问题的java实践(附源码)
引子
大文件拆分问题涉及到io处理、并发编程、生产者/消费者模式的理解,是一个很好的综合应用场景,为此,花点时间做一些实践,对相关的知识做一次梳理和集成,总结一些共性的处理方案和思路,以供后续工作中借鉴。
本文将尝试由浅入深的方式表述大文件拆分的问题及不同解决方案,给出的方案不一定是最优解,也并非线上环境论证过的靠谱方式,目的只是在于通过该问题融会贯通io、多线程等基础知识理论。生产环境请慎用。
本文不会逐行讲解代码实现,而注重在方案设计及思路探讨上,但会在文末附上源码demo git地址。
问题
假设一个CSV文件有8GB,里面有1亿条数据,每行数据最长不超过1KB,目前需要将这1亿条数据拆分为10MB一个的子CSV文件,写入到同目录下,要求每一个子CSV文件的数据必须是完整行,所有子文件不能大于10MB;
确保文件拆分后文件内容不会丢失;
使用java语言编程实现。
单线程读-多线程写的方案
设计思路
1、读写并行。源文件大小为:8G,太大,不能一次性读入内存,很大可能出现oom;
2、单线程读源文件,多线程写文件。原因:磁盘读快于磁盘写,且多线程读取文件的复杂度较大,舍弃;
3、使用字符流按行读取和写入,以满足‘数据是完整行’的需求;
4、通过比较读入源文件字节数和实际写入字节数是否相等来检查文件拆分写入是否成功。
5、写操作的多线程使用普通的ThreadPoolExcutor 或者 ForkJoinPool。
示意图

类图
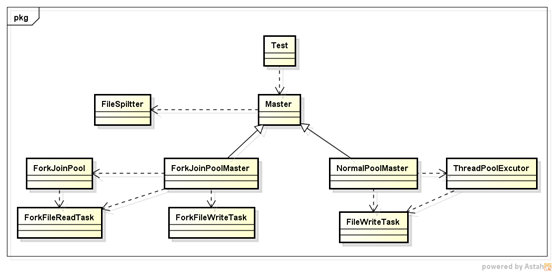
Master——负责协调读写任务,可以有普通线程池和ForkJoinPool的实现方式;
*Task —— 完成具体的读写任务,均为Thread实现类;
FileSpiltter —— 文件分割器,完成文件分割计算;
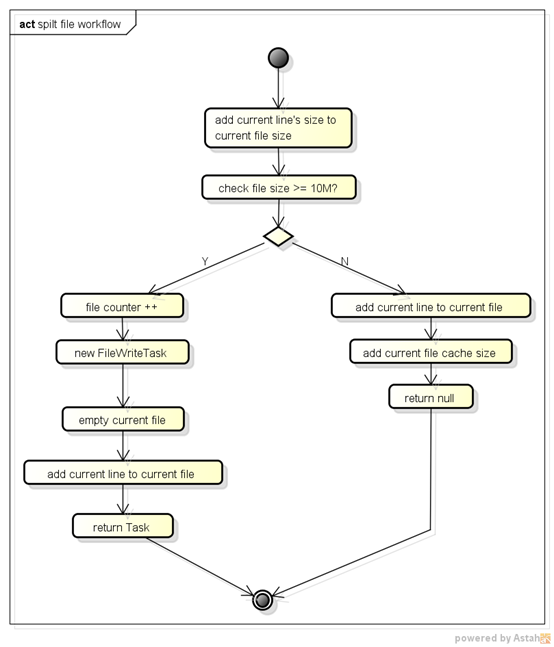
文件拆分的核心流程图
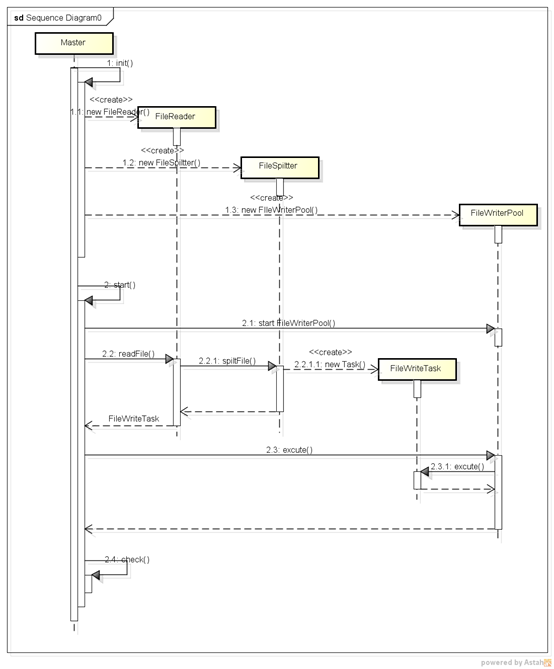
时序图
优劣势分析
优势
1、单线程读,程序时间和文件拆分逻辑控制简单;
2、确保文件拆分过程中,文件内容写入的有序性;FileSpiltter在积聚满一个子文件内容后,一次性写入磁盘。
3、鉴于2的有序写入,子文件大小分布均匀。
劣势
1、单线程读,效率不高,且在使用高效率写方式时,可能成为瓶颈;
2、内存增长不可控,易出现OMM。对于运行中的写文件任务不可控,内存使用不可控。详细分析如下:
使用普通ThreadPool时,任务队列实际上使用的是ThreadPool的queue,这里选择的有界的BlockingQueue,那么当任务数超负载了,线程池的拒绝策略有:异常停止、丢弃任务、使用调用者线程执行,前两种策略不能满足功能上的需求,后一种策略解决不了内存不可控的问题。考虑尝试线程池使用SychronizedQueue或者无界BlockingQueue,依然无法解决内存使用不可控的问题,因为读文件侧不能得到子文件写入任务的反馈,没法及时调整自己的进度。
使用ForkJoinPool时,同样存在这个问题,读文件侧无法感知到写文件侧的进度,一股脑傻乎乎地写。
ThreadPoolExcutor vs ForkJoinPool
本方案中使用了两种线程池实现,理论上,ForkJoinPool在线程利用率上会好于普通线程池,因为,它会在内存协调各个线程池的任务,互帮互助,提高处理效率。那么是否ForkJoinPool的性能会好过普通的ThreadPoolExutor呢?且看下面的测试数据:
|
序号 |
Pool |
Worker Threads |
-Xms |
-Xmx |
Jvm_cpu(%) |
Jvm_mem |
Duration(ms) |
Remark |
|
1 |
ThreadPoolExutor |
4write+1main |
2048m |
2048m |
10 |
500m |
94534 |
|
|
2 |
ForkJoinPool |
4worker |
2048m |
2048m |
10~50 |
500m |
91036 |
|
|
3 |
ForkJoinPool |
5worker |
2048m |
2048m |
10~50 |
500m |
89493 |
1、 ThreadPoolExcutor main线程负责读取源文件,可以看到block在BufferedReader.readLine()上,FileWrite线程block在BufferedWriter.flush()方法上。
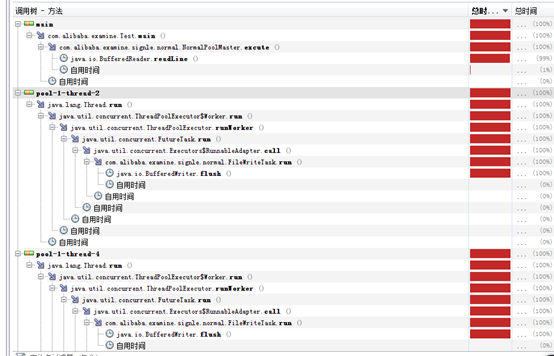
2、 ForkJoinPool,默认4个worker线程工作,发现jvm cpu使用率波动很大,10%~50%,且worker线程block在BufferedReader.readLine()或者BufferedWriter.flush()上。
仔细观察发现,FileRead和FileWrite的task都是由ForkJoinPool的4个默认worker完成的,也就是说相对与实验1,少了一个worker线程,实验1的main作为FileRead的worker线程存在。
尝试将ForkJoinPool的worker线程设置为5,以求和实验1保持相同的worker线程数。
3、 ForkJoinPool,5个worker线程工作。
负责read的线程100%忙,其他4个负责write的worker则大部分时间在等待,所以可以看出瓶颈实际在FileRead上,所以即使增大了worker数量也解决不了问题。

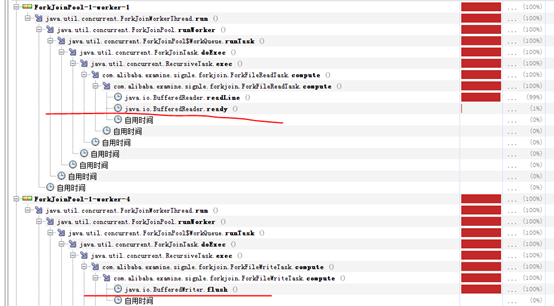
通过实验发现,两种方式在性能上并无多大差异。在字符流按行读写文件的场景下,读写worker均block在文件的读/写上,不论是使用普通的ThreadPoolExutor或者是ForkJoinPool线程池,性能上没有大的区别。
但是ForkJoinPool线程池的分而治之的思想值得学习,在并行排序、并行计算的场景非常适用,比如如果这里不是文件拆分,而是读取大文件中的1亿个数字,找出其中最大的top100,那么这时候适用ForkJoinPool将会非常合适。
生产者-消费者模式(多线程读/写)
鉴于上述方案的劣势,我们提出使用生产者-消费者模式来实现,同时为了提高读效率,使用多线程读/写。
设计思路
1、采用生产者-消费者模式,对读写任务可控,从而读内存使用可控,防止出现omm;
2、使用多线程读/写,提高效率;
3、借助内存文件映射MappedByteBuffer,分段多线程读取文件;
示意图

类图

Master、*Task、FileSpiltter —— 和之前一样的职责;只是不同的实现方式;
*Pool —— 读/写线程池,使用ThreadPoolExcutor实现,使用有界队列、有界线程池;
TaskAllocater —— *Task任务初始化,填充*Pool;
Queue —— 生产者/消费者共享Blocking任务队列,有界,大小可配置;
FileLine —— 包装一行文件内容,这里的一行为csv文件内容的一行,同时出现\r和\n字节时任务换行;
时序图
优劣势
优势
1、内存使用可控,避免OMM问题;
2、读文件效率提高,整个文件拆分时延降低;
劣势
1、文件拆分逻辑和任务控制逻辑复杂,代码复杂度高;
2、文件内容的有序性无法保证;FileWriteTask从queue里获取FileLine是随机的,无法保证文件内容写入的有序性,这里的有序性是指相对于源文件的行位置;
3、文件拆分后子文件大小的均匀性无法保证;多线程之间互相不知道状态,因此在最后会出现不确定的小文件。
性能调优
生产者/消费者方式的实现,使得任务控制和文件拆分逻辑复杂,最初版本性能比‘单线程读-多线程写’的方案还要查,后来通过调优得到了比较满意的结果。
总结下来:需要针对几个关键性参数进行调节,以求得到最佳性能,这几个关键性的参数包括:FileReadTaskNum(生产者数量,源文件读取任务数量)、FileWriteTaskNum(消费者数量,子文件写入任务数量)、queueSize(任务队列大小)。
下面简单罗列下在测试机的调优过程:
测试环境
OS: windows 7 64bit
cpu: 4core, 主频:2.4GHZ
mem:6G
jdk version:Java HotSpot(TM) 64-Bit ,1.8.0_101
调优过程
先直观给出各个调优实验的结果数据,主要关注几个参数:jvm cpu使用率、jvm memory使用、物理内存使用(涉及到内存文件映射,这部分内存不受jvm管控):
|
序号 |
-Xms |
-Xmx |
readTaskNum |
writeTaskNum |
queueSize |
Durition |
jvm_ |
jvm_ |
Physics |
|
子文件一次性写+FileOutputStream |
|||||||||
|
1 |
512m |
512m |
4 |
4 |
1024 |
35752 |
80 |
400m |
4.2G |
|
2 |
512m |
512m |
4 |
4 |
4096 |
37878 |
80 |
400M |
4.2G |
|
3 |
512m |
512m |
8 |
4 |
4096 |
36507 |
80 |
350m |
4.2G |
|
4 |
512m |
512m |
8 |
8 |
4096 |
39566 |
80 |
350m |
4.3G |
|
5 |
512m |
512m |
8 |
12 |
4096 |
55879 |
80->60 |
400M |
4.3G |
|
子文件按行写+FileOutputStream |
|||||||||
|
6 |
512m |
512m |
8 |
12 |
4096 |
63245 |
60 |
100m |
4.9G |
|
7 |
512m |
512m |
8 |
12 |
10240 |
62421 |
60 |
100m |
4.7G |
|
9 |
512m |
512m |
8 |
4 |
10240 |
64342 |
60 |
100m |
4.9G |
|
子文件按行写+nio |
|||||||||
|
10 |
512m |
512m |
8 |
8 |
10240 |
123322 |
20 |
100m |
4.6G |
|
11 |
512m |
512m |
16 |
8 |
10240 |
17237 |
20 |
100m |
4.5G |
|
12 |
512m |
512m |
24 |
8 |
10240 |
6333 |
80 |
100m |
4.5G |
|
13 |
512m |
512m |
24 |
8 |
20480 |
6656 |
80 |
100m |
4.5G |
|
14 |
512m |
512m |
32 |
8 |
20480 |
7001 |
80 |
100m |
4.5G |
|
15 |
512m |
512m |
32 |
16 |
20490 |
7554 |
80 |
100m |
4.5G |
|
16 |
512m |
512m |
32 |
16 |
40960 |
8824 |
80 |
100m |
4.5G |
|
子文件一次性写入+nio |
|||||||||
|
17 |
512m |
512m |
24 |
8 |
10240 |
8158 |
80 |
100m |
4.6G |
表中第一列编号对应于下面描述中的编号,可以结合着看。
1、 read和write均block在queue的操作上
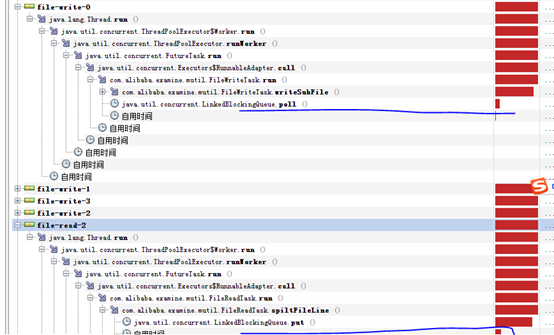
尝试增大queueSize
2、 read不在block在queue的put上,转而block在读入字节流的过滤上,但是由于read不够快,故而write仍然block在queue的take上。
性能和负载上没有大的变化

尝试增大read的线程数
3、 read 线程增加一倍后,read速度快于write速度,导致read block在queue的put,writeblock在写文件上。
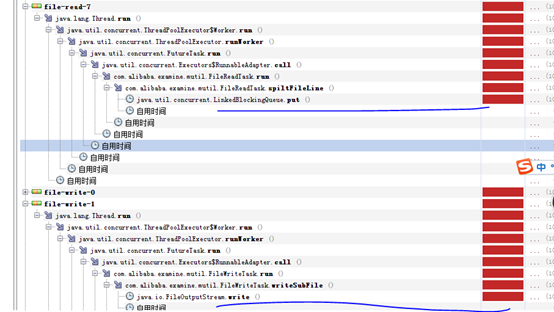
尝试增大write一倍的话,很有可能write等待read的任务产生,再次让write block在queue的tack上? 接下来验证下。
4、 增大write线程数后,并未出现write等待read的情况,和3一样,read 在等待write消费任务,block在了queue 的put上,这说明write文件到磁盘成为了瓶颈。
在IO写成为瓶颈的情况下,增大write的线程数,反而雪上加霜,使得时延增加。
为了验证这个结论,我们继续加大write的线程数,看看时延的变化情况。
5、 在IO写成为瓶颈的情况下,增大write的线程数,反而雪上加霜,使得时延增加。多个write不断地争抢io资源,Cpu利用率降低。
Review代码发现,现在的write是在收集满一个子文件后才一次性向外面写,多个线程可能同一时刻都要去申请io写,这时候等待时间会很长,尝试将一次性写整个子文件,更改为每次写一行。
6、 将写文件动作分散化后,时延没有什么好转,但是带来了如下好处:
A、 性能表现稳定,多次试验时延、cpu负载均表现平稳,没有大起大落。之前等凑齐一个文件再写时,很容易产生io阻塞,多个线程阻塞在io上,导致性能表现不稳定。
B、 Jvm内存使用降低。读一行写一行,使得内存中缓存的文件内容降低。
也带了一个不好的变化:物理内存使用增加。怀疑和时延增大,read使用MappedByteBuffer读取文件时,直接使用了物理内存作为缓存,时延增大,导致缓存驻留时间更长。
接下来尝试调大queueSize,以便能缓解物理内存的占用。
7、 调大queueSize未能解决问题,瓶颈仍然在write文件上。根本问题不解决,处理效率上不来,导致read进物理内存的缓存内容长期占用,物理内存居高。
8、 反向思维,将write线程调低呢?也没有好转。
接下来还是着手从根本上解决write性能地下的问题。
通过实验发现,对于10M左右的文件,使用FileChannel的nio模式效率最高。详细见:java中多种写文件方式的效率对比实验
9、 使用FileChannel+MappedByteBuffer写入文件后,时延没有提升,但是可以看到write的效率大大高于了read。
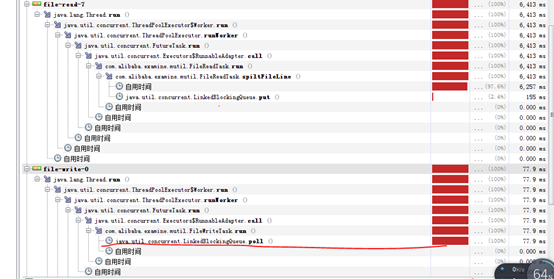
接下来,增加read的线程数。
10-16、 调整readtaskNum、writeTaskNum、queueSize发现在readtaskNum=24, writeTaskNum=8, queueSize=10240时时延最低,且cpu使用率已经接近100%,为最优点。
‘子文件按行写+NIO’存在一个功能性的问题:由于预先分配好了ByteBuffer的大小,当文件内容不足时,会存在很多空NUL的字节,使得文件内容失真。

17、将逐行写入更改为子文件一次性写入,可以解决上面的功能性问题,且时延并未增加太多。
调优结果
最后选择了第17步得到的方案:子文件一次性写入+nio处理,readtaskNum=24, writeTaskNum=8, queueSize=10240。
如何更完美?
针对‘生产者-消费者模式’的方案,存在如下两个功能性相关的不足,我们如何设计能让这个方案更加完美呢? 我们可以尝试去想一下:
文件内容写入的有序性保证
这里的有序性是指拆分后的行的前后行和源文件中的一致,如果是跨子文件,那么子文件编号小的在前,编号大的行在后。由于FileWriteTask从queue里获取FileLine是随机的,无法保证文件内容写入的有序性,因此,这里可以考虑对FileLine增加一个lineSeq的属性,这个属性由FileReadTask赋值,形如:taskSeq+lineSeqInSubFile,taskSeq为FileReadTask的任务编号,lineSeqInSubFile为特定子文件内部唯一有序编号;FileWriteTask仍然随机从queue中读取FileLine,但是写入时需要判定FileLine的lineSeq是否为当前需要写入的seq,如果不是则舍弃。这样的方案会急剧降低写入性能,同时可能出现假死现象,queue中不包含任何writeTask需要的正确顺序的FileLine,所有writeTask等待下一个正确顺序的FileLine出现,queue中的任务无法继续被消费,进而导致FileWriteTask也被block,整个任务处理假死。
在多线程读写模式下,我还未找到一个有效的方法来保证文件内容写入的有序性,如果要保证文件内容写入的有序性,只能使用单线程写 或者 单线程读,舍弃高性能。
拆分后子文件大小的均匀性保证
当前实现中,FileWriteTask从queue中获取FileLine,并完成写入,由于FileLine是无序的,且各个fileWriteTask实例之间不能通信,因此,可能出现还剩下最后几个文件的大小很小,使得文件大小的均匀性收到破坏。例如,当总共有8个FileWriteTask在工作,在最后时刻,所有8个task都已经完成了上一个文件的写入,queue里还剩下8条FileLine,这时候发现queue还有FileLine任务没有处理,于是纷纷新建一个子文件,开始写入,最后的结果可能是:8个task分别写入最后一个子文件,但是每个子文件中只有一条FileLine,大小和之前的问题件差别很大。
我们希望的是最后的8条FileLine都被写入了同一个子文件。
可以想到如下解决办法:在所有子文件写入结束后,再做一次文件合并,对文件过小的子文件合并至一个文件,这个方法会损害一定的性能,但应当是可以实现功能的,应当还有其他方法,可以思考下。
总结
1、使用‘生产者-消费者’模式可以很好地控制内存中存在的任务数,从而有效控制jvm内存大小,防止omm出现;
2、使用内存文件映射完成读/写文件,能够获得最高的效率;
3、ForkJoinPool适合于并行计算(如并行排序)场景,其分而治之的思想值得学习,但在大文件拆分场景并无优势;
4、‘生产者-消费者’模式的性能调优中涉及到:生产者任务数量、消费者任务数量、任务队列大小的协同调整;
TODO
1、拆分后文件写入的有序性保证问题
2、拆分后子文件大小的均匀性保证问题
3、内存映射文件占据内存的回收问题
源码demo
github地址:https://github.com/daoqidelv/filespilt-demo
大文件拆分问题的java实践(附源码)的更多相关文章
- 大文件拆分方案的java实践(附源码)
引子 大文件拆分问题涉及到io处理.并发编程.生产者/消费者模式的理解,是一个很好的综合应用场景,为此,花点时间做一些实践,对相关的知识做一次梳理和集成,总结一些共性的处理方案和思路,以供后续工作中借 ...
- Lazy<T>在Entity Framework中的性能优化实践(附源码)
在使用EF的过程中,导航属性的lazy load机制,能够减少对数据库的不必要的访问.只有当你使用到导航属性的时候,才会访问数据库.但是这个只是对于单个实体而言,而不适用于显示列表数据的情况. 这篇文 ...
- Disruptor的应用示例——大文件拆分
结合最近Disruptor的学习,和之前一直思考解决的大文件拆分问题,想到是否可以使用Disruptor作为生产者/消费者传递数据的通道呢?借助其高效的传递,理论上应当可以提升性能.此文便是此想法的落 ...
- Java:大文件拆分工具
java大文件拆分工具(过滤掉表头) import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File ...
- 【转】.NET(C#):浅谈程序集清单资源和RESX资源 关于单元测试的思考--Asp.Net Core单元测试最佳实践 封装自己的dapper lambda扩展-设计篇 编写自己的dapper lambda扩展-使用篇 正确理解CAP定理 Quartz.NET的使用(附源码) 整理自己的.net工具库 GC的前世与今生 Visual Studio Package 插件开发之自动生
[转].NET(C#):浅谈程序集清单资源和RESX资源 目录 程序集清单资源 RESX资源文件 使用ResourceReader和ResourceSet解析二进制资源文件 使用ResourceM ...
- 构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(32)-swfupload多文件上传[附源码]
原文:构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(32)-swfupload多文件上传[附源码] 文件上传这东西说到底有时候很痛,原来的asp.net服务器 ...
- 读取xml文件转成List<T>对象的两种方法(附源码)
读取xml文件转成List<T>对象的两种方法(附源码) 读取xml文件,是项目中经常要用到的,所以就总结一下,最近项目中用到的读取xml文件并且转成List<T>对象的方法, ...
- swfupload多文件上传[附源码]
swfupload多文件上传[附源码] 文件上传这东西说到底有时候很痛,原来的asp.net服务器控件提供了很简单的上传,但是有回传,还没有进度条提示.这次我们演示利用swfupload多文件上传,项 ...
- 聊天系统Demo,增加文件传送功能(附源码)-- ESFramework 4.0 快速上手(14)
本文我们将介绍在ESFramework 4.0 快速上手(08) -- 入门Demo,一个简单的IM系统(附源码)的基础上,增加文件传送的功能.如果不了解如何使用ESFramework提供的文件传送功 ...
随机推荐
- setInterval定时器
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...
- Java基础学习(三)—面向对象(上)
一.理解面向对象 面向对象是一种思想,是基于面向过程而言的,就是说面向对象是将功能等通过对象来实现,将功能封装进对象之中,让对象去实现具体的细节:这种思想是将数据作为第一位,而方法或者说是 ...
- Jmeter的逻辑控制器——Controller
逻辑控制器(Logic Controller) --贯穿整个Test Plan中,与各组件执行顺序没关系:目的是用于控制采样器的执行顺序. Simple Controller Simple Contr ...
- 树状数组 && 线段树
树状数组 支持单点修改 #include <cstdio> using namespace std; int n, m; ], c[]; int lowbit(int x) { retur ...
- angular 过滤排序
<table class="table"> <thead> <tr> <th ng-click="changeOrder('id ...
- 在Oracle中添加用户登录名称
第一步,打开Oracle客户端单击 “帮助”-->"支持信息"-->”TNS名“,加入红色部分.页面如下: 第二步,再次打开Oracle客户端时,就会显示数据库了,只需 ...
- UITableView grouped样式使用探索
UITableView的style有plain和grouped两种样式,两种样式各有不同的风格和功能,plain样式已经封装好了悬停功能,gouped样式则为我们在区头和区尾在实际项目开发中需要我们选 ...
- Eclipse导入Android签名
本篇主要参照http://blog.csdn.net/wuxy_shenzhen/article/details/20946839 在安装安卓apk时经常会出现类似INSTALL_FAILED_SHA ...
- 杜教筛 && bzoj3944 Sum
Description Input 一共T+1行 第1行为数据组数T(T<=10) 第2~T+1行每行一个非负整数N,代表一组询问 Output 一共T行,每行两个用空格分隔的数ans1,ans ...
- [Git]03 如何查看提交历史
在提交了若干更新之后,又或者克隆了某个项目,想回顾下提交历史,可以使用 gitlog 命令查看. 常用命令 1.查看提交历史 $ git log 2.查看某个文件或者某个目录的递交历史 $ gi ...