python pandas 合并数据函数merge join concat combine_first 区分
pandas对象中的数据可以通过一些内置的方法进行合并:pandas.merge,pandas.concat,实例方法join,combine_first,它们的使用对象和效果都是不同的,下面进行区分和比较。
数据的合并可以在列方向和行方向上进行,即下图所示的两种方式:

pandas.merge和实例方法join实现的是图2列之间的连接,以DataFrame数据结构为例讲解,DataFrame1和DataFrame2必须要在至少一列上内容有重叠,index也好,columns也好,只要是有内容重叠的列即可,指定其中一列或几列作为连接的键,然后按照键,索引DataFrame2其他列上的的数据,添加DataFrame1中。例,以columns内容作为连接键:
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df1 = DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1': range(7)})
df2 = DataFrame({ 'key': ['a', 'b', 'd'],
'data2': range(3),
'data3':range(3,6)})
DF1=pd.merge(df1, df2)
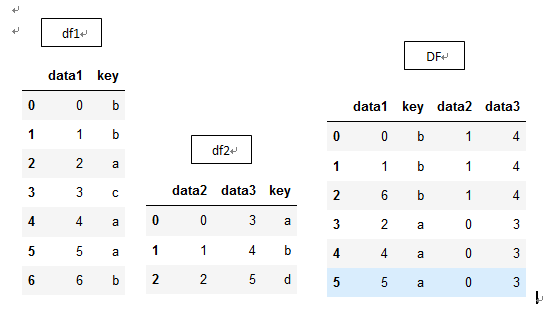
通过设置merge参数'on','left_on','right_on'可以指定用来连接的列(即关键的重复内容列),也可以将index作为连接键,只要传入left_index=True或right_index=True(或两个都传)来说明索引被用作连接键,例:
left1 = DataFrame({'key': ['a', 'b', 'a', 'a', 'b', 'c'],
'value': range(6)})
right1 = DataFrame({'group_val': [3.5, 7]}, index=['a', 'b'])
lr=pd.merge(left1, right1, left_on='key', right_index=True)
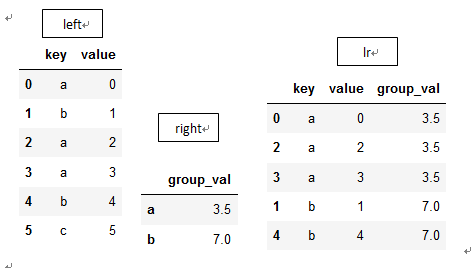
而实例方法join默认通过index来进行连接,例:
left2 = DataFrame([[1., 2.], [3., 4.], [5., 6.]], index=['a', 'c', 'e'],
columns=['Ohio', 'Nevada'])
right2 = DataFrame([[7., 8.], [9., 10.], [11., 12.], [13, 14]],
index=['b', 'c', 'd', 'e'], columns=['Missouri', 'Alabama'])
lr2=left2.join(right2, how='outer')
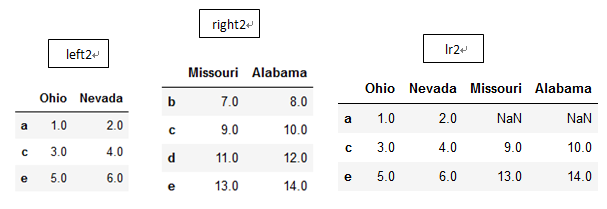
join方法也可以通过列来连接,同样设置参数‘on’即可。
上面介绍的函数实现的均是列之间的连接,要实现行之间的连接,要使用pd.concat方法,例:
s1 = Series([0, 1], index=['a', 'b'])
s2 = Series([2, 3, 4], index=['c', 'd', 'e'])
s3 = Series([5, 6], index=['f', 'g'])
ss=pd.concat([s1, s2, s3])
st=pd.concat([s1,s2,s3],axis=1)
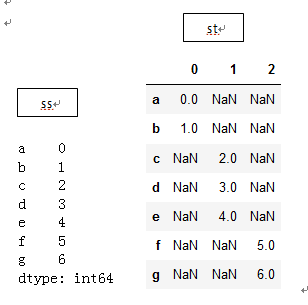
concat默认在axis=0上工作(沿着负y轴的方向),当设置axis=1时(沿着x轴的方向),它同时也可以实现列之间的连接,产生一个DataFrame。
最后一个实例方法combine_first,它实现既不是行之间的连接,也不是列之间的连接,它在为数据“打补丁”:用参数对象中的数据为调用者对象的缺失数据“打补丁”。例:
a = Series([np.nan, 2.5, np.nan, 3.5, 4.5, np.nan],
index=['f', 'e', 'd', 'c', 'b', 'a'])
b = Series(np.arange(len(a), dtype=np.float64),
index=['f', 'e', 'd', 'c', 'b', 'a'])
b[-1] = np.nan
c=b[:-2].combine_first(a[2:])
df1 = DataFrame({'a': [1., np.nan, 5., np.nan],
'b': [np.nan, 2., np.nan, 6.],
'c': range(2, 18, 4)})
df2 = DataFrame({'a': [5., 4., np.nan, 3., 7.],
'b': [np.nan, 3., 4., 6., 8.]})
df=df1.combine_first(df2)

简单总结来说,通过merge和join合并的数据后数据的列变多,通过concat合并后的数据行列都可以变多(axis=1),而combine_first可以用一个数据填充另一个数据的缺失数据。
注:以上所有实验都是默认的“inner”连接方式(交集),可以通过“how”参数改变。
python pandas 合并数据函数merge join concat combine_first 区分的更多相关文章
- 排序合并连接(sort merge join)的原理
排序合并连接(sort merge join)的原理 排序合并连接(sort merge join)的原理 排序合并连接(sort merge join) 访问次数:两张表都只会访 ...
- python pandas合并多个excel(xls和xlsx)文件(弹窗选择文件夹和保存文件)
# python pandas合并多个excel(xls和xlsx)文件(弹窗选择文件夹和保存文件) import tkinter as tk from tkinter import filedial ...
- pandas 合并数据
1. pandas 的merge,join 就不说了. 2. 神奇的: concat append 参考: PANDAS 数据合并与重塑(concat篇) 3.
- Python pandas检查数据中是否有NaN的几种方法
Python pandas: check if any value is NaN in DataFrame # 查看每一列是否有NaN: df.isnull().any(axis=0) # 查看每一行 ...
- Pandas合并数据集之merge、join方法
合并数据集 pandas.merge 可根据一个或多个键将不同DataFrame中的行连接起来. pandas.concat 可以沿着一条轴将多个对象堆叠到一起. combine_first merg ...
- [Python] Pandas 对数据进行查找、替换、筛选、排序、重复值和缺失值处理
目录 1. 数据文件 2. 读数据 3. 查找数据 4. 替换数据 4.1 一对一替换 4.2 多对一替换 4.3 多对多替换 5. 插入数据 6. 删除数据 6.1 删除列 6.2 删除行 7. 处 ...
- merge,join,concat
merge交集 join并集 concat axis=0 竖着连 axis=1 横着连
- python pandas使用数据透视表
1) 官网啰嗦这一堆, pandas.pivot_table函数中包含四个主要的变量,以及一些可选择使用的参数.四个主要的变量分别是数据源data,行索引index,列columns,和数值value ...
- python merge、concat合并数据集
数据规整化:合并.清理.过滤 pandas和python标准库提供了一整套高级.灵活的.高效的核心函数和算法将数据规整化为你想要的形式! 本篇博客主要介绍: 合并数据集:.merge()..conca ...
随机推荐
- 项目实战8—tomcat企业级Web应用服务器配置与会话保持
tomcat企业级Web应用服务器配置与实战 环境背景:公司业务经过长期发展,有了很大突破,已经实现盈利,现公司要求加强技术架构应用功能和安全性以及开始向企业应用.移动APP等领域延伸,此时原来开发w ...
- Postgres的tuple的组装
1.相关的数据类型 我们先看相关的数据类型: HeapTupleData(src/include/access/htup.h) typedef struct HeapTupleData { uint3 ...
- Jsoup(一)Jsoup详解(官方)
一.Jsoup概述 1.1.简介 jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API, 可通过DOM,CSS以及类似于jQu ...
- oracle恢复已删除的表
drop 误删除表之后使用flashback table tablename to before drop 可恢复或者使用flashback table "BIN$gcfME7ObTx+n0 ...
- eclipse中JDK、struts2、Spring、Hibernate源码查看
一般,我们导入的只有jar文件,所以看不到对于的java文件,如果需要看源码,必须下载对应开源包的源码,一般都是zip文件,比如Spring,下载spring-framework-2.0.8-with ...
- Unable to resolve persistence unit root URL
异常信息 时间:2017-03-07 11:46:05,516 - 级别:[ WARN] - 消息: [other] The web application [ROOT] appears to hav ...
- Android项目实战(三十六):给背景加上阴影效果
圆角背景大家应该经常用: 一个drawable资源文件 里面控制corner圆角 和solid填充色 <shape xmlns:android="http://schemas.and ...
- DotNetCore跨平台~System.DrawingCore部署Linux需要注意的
回到目录 你在windows上使用图像组件没有任务问题,但部署到linux之后,将注意以下几点: 安装nuget包ZKWeb.System.Drawing 项目里还是引用System.DrawingC ...
- 【ANT】java项目生成文件示例
<?xml version="1.0" ?> <project default="dist"> <property name=&q ...
- iOS voip电话和sip软电话 --网络电话
一|介绍1.两者区别: SIP软电话与IP电话在技术上属于同一类型,只是SIP软电话是使用电脑软件实现的,而IP电话有一部分是在话机中直接写入了程序,可以通过硬件直接使用.IP(简称VoIP,源自英语 ...