[笔记]GBDT理论知识总结
一. GBDT的经典paper:《Greedy Function Approximation:A Gradient Boosting Machine》
Abstract
Function approximation是从function space方面进行numerical optimization,其将stagewise additive expamsions和steepest-descent minimization结合起来。而由此而来的Gradient Boosting Decision Tree(GBDT)可以适用于regression和classification,都具有完整的,鲁棒性高,解释性好的优点。
1. Function estimation
在机器学习的任务中,我们一般面对的问题是构造loss function,并求解其最小值。可以写成如下形式:

通常的loss function有:
1. regression:均方误差(y-F)2,绝对误差|y-F|
2. classification:negative binomial log-likelihood log(1+e-2yF)
一般情况下,我们会把F(x)看做是一系列带参数的函数集合 F(x;P),于是进一步将其表示为“additive”的形式:

1.1 Numerical optimizatin
我们可以通过选取一个参数模型F(x;P),来将function optimization问题转化为一个parameter optimization问题:

进一步,我们可以把要优化的参数也表示为“additive”的形式:
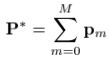
1.2 Steepest-descent
梯度下降是最简单,最常用的numerical optimization method之一。
首先,计算出当前的梯度:

where 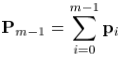
而梯度下降的步长为: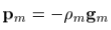
where  ,称为“line search”。
,称为“line search”。
2. Numerical optimization in function space
现在,我们考虑“无参数”模型,转而考虑直接在function space 进行numerical optimization。这时候,我们将在每个数据点x处的函数值F(x)看做是一个“参数”,仍然是来对loss funtion求解最小值。
在function space,为了表示一个函数F(x),理想状况下有无数个点,但在现实中,我们用有限个(N个)离散点来表示它: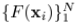 。
。
按照之前的numerical optimization的方式,我们需要求解:
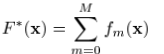
使用steepest-descent,有:

where  ,and
,and 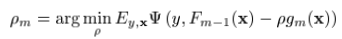
3. Finite data
当我们面对的情况为:用有限的数据集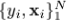 表示x,y的联合分布的时候,上述的方法就有点行不通了。我们可以试试“greedy-stagewise”的方法:
表示x,y的联合分布的时候,上述的方法就有点行不通了。我们可以试试“greedy-stagewise”的方法:
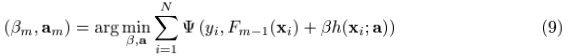
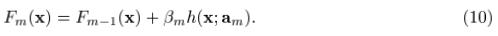
但是对于一般的loss function和base learner来说,(9)式是很难求解的。给定了m次迭代后的当前近似函数Fm-1(x),当步长的direction 是指数函数集合
是指数函数集合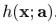 当中的一员时,
当中的一员时,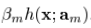 可以看做是在求解最优值上的greedy step,同样,它也可以被看做是相同限制下的steepest-descent step。作为比较,
可以看做是在求解最优值上的greedy step,同样,它也可以被看做是相同限制下的steepest-descent step。作为比较,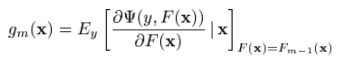 给出了在无限制条件下,在Fm-1(x)处的steepest-descent step direction。一种行之有效的方法就是在求解的时候,把它取为无限制条件下的负梯度方向
给出了在无限制条件下,在Fm-1(x)处的steepest-descent step direction。一种行之有效的方法就是在求解的时候,把它取为无限制条件下的负梯度方向 :
:
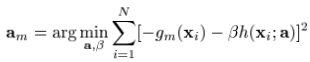
where 
这就把(9)式中较难求解的优化问题转化为了一个基于均方误差的拟合问题。
Gradient Boosting的通用解法如下:

二. 对于GBDT的一些理解
1. Boosting
GBDT的全称是Gradient Boosting Decision Tree,Gradient Boosting和Decision Tree是两个独立的概念。因此我们先说说Boosting。Boosting的概念很好理解,意思是用一些弱分类器的组合来构造一个强分类器。因此,它不是某个具体的算法,它说的是一种理念。和这个理念相对应的是一次性构造一个强分类器。像支持向量机,逻辑回归等都属于后者。通常,我们通过相加来组合分类器,形式如下:
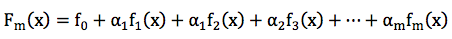
2. Gradient Boosting Modeling(GBM)
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 12.0px ".PingFang SC"; color: #454545 }
span.s1 { font: 12.0px "Helvetica Neue" }
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; text-align: justify; font: 14.0px SimSun }
span.s1 { font: 14.0px Cambria }
给定一个问题,我们如何构造这些弱分类器呢?Gradient Boosting Modeling (GBM) 就是构造 这些弱分类的一种方法。同样,它指的不是某个具体的算法,仍然只是一个理念。在理解 Gradient Boosting Modeling 之前,我们先看看一个典型的优化问题:
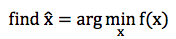
p.p1 { margin: 0.0px 0.0px 12.0px 0.0px; line-height: 17.0px; font: 18.0px SimSun; color: #000000 }
span.s1 { }
span.s2 { font: 18.0px Calibri }
针对这种优化问题,有一个经典的算法叫 Steepest Gradient Descent,也就是最深梯度下降法。 这个算法的过程大致如下:

p.p1 { margin: 0.0px 0.0px 12.0px 0.0px; line-height: 17.0px; font: 14.7px SimSun; color: #000000 }
span.s1 { }
以上迭代过程可以这么理解:整个寻优的过程就是个小步快跑的过程,每跑一小步,都往函数当前下降最快的那个方向走一点。
这样寻优得到的结果可以表示成加和形式,即:
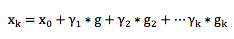
这个形式和以上Fm(x)是不是非常相似? Gradient Boosting 正是由此启发而来。 构造Fm(x)本身也是一个寻优的过程,只不过我们寻找的不是一个最优点,而是一个最优的函数。优化的目标通常都是通过一个损失函数来定义,即:

其中Loss(F(xi), yi)表示损失函数Loss在第i个样本上的损失值,xi和yi分别表示第 i 个样本的特征和目标值。常见的损失函数如平方差函数:
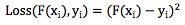
类似最深梯度下降法,我们可以通过梯度下降法来构造弱分类器f1, f2, ... , fm,只不过每次迭代时,令
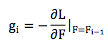
即对损失函数L,以 F 为参考求取梯度。
这里有个小问题,一个函数对函数的求导不好理解,而且通常都无法通过上述公式直接求解 到梯度函数gi。为此,采取一个近似的方法,把函数Fi−1理解成在所有样本上的离散的函数值,即:

不难理解,这是一个 N 维向量,然后计算
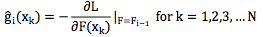
这是一个函数对向量的求导,得到的也是一个梯度向量。注意,这里求导时的变量还是函数F,不是样本xk。
严格来说 ĝi(xk) for k = 1,2, ... , N 只是描述了gi在某些个别点上的值,并不足以表达gi,但我们可以通过函数拟合的方法从ĝi(xk) for k = 1,2, ... , N 构造gi,这样我们就通过近似的方法得到了函数对函数的梯度求导。
因此 GBM 的过程可以总结为如下:

常量函数f0通常取样本目标值的均值,即
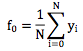
3. Gradient Boosting Decision Tree
以上 Gradient Boosting Modeling 的过程中,还没有说清楚如何通过离散值 ĝi−1(xj) for j = 1,2,3,...N 构造拟合函数gi−1。函数拟合是个比较熟知的概念,有很多现成的方法,不过有一种拟合方法广为应用,那就是决策树 Decision Tree,有关决策树的概念,理解GBDT重点首先是Gradient Boosting,其次才是 Decision Tree。GBDT 是 Gradient Boosting 的一种具体实例,只不过这里的弱分类器是决策树。如果你改用其他弱分类器 XYZ,你也可以称之为 Gradient Boosting XYZ。只不过 Decision Tree 很好用,GBDT 才如此引人注目。
4. 损失函数
谈到 GBDT,常听到一种简单的描述方式:“先构造一个(决策)树,然后不断在已有模型和实际样本输出的残差上再构造一颗树,依次迭代”。其实这个说法不全面,它只是 GBDT 的一种特殊情况,为了看清这个问题,需要对损失函数的选择做一些解释。
从对GBM的描述里可以看到Gradient Boosting过程和具体用什么样的弱分类器是完全独立的,可以任意组合,因此这里不再刻意强调用决策树来构造弱分类器,转而我们来仔细看看弱分类器拟合的目标值,即梯度ĝi−1(xj ),之前我们已经提到过

5. GBDT 和 AdaBoost
Boosting 是一类机器学习算法,在这个家族中还有一种非常著名的算法叫 AdaBoost,是 Adaptive Boosting 的简称,AdaBoost 在人脸检测问题上尤其出名。既然也是 Boosting,可以想象它的构造过程也是通过多个弱分类器来构造一个强分类器。那 AdaBoost 和 GBDT 有什么区别呢?
两者最大的区别在于,AdaBoost 不属于 Gradient Boosting,即它在构造弱分类器时并没有利用到梯度下降法的思想,而是用的Forward Stagewise Additive Modeling (FSAM)。为了理解 FSAM,在回过头来看看之前的优化问题。
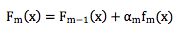
严格来说之前描述的优化问题要求我们同时找出α1, α2, ... , αm和f1, f2, f3 ... , fm,这个问题很 难。为此我们把问题简化为分阶段优化,每个阶段找出一个合适的α 和f 。假设我们已经 得到前 m-1 个弱分类器,即Fm−1(x),下一步在保证Fm−1(x)不变的前提下,寻找合适的 αmfm(x)。按照损失函数的定义,我们可以得到

如果 Loss 是平方差函数,则我们有

这里yi − Fm−1(xi)就是当前模型在数据上的残差,可以看出,求解合适的αmfm(x)就是在这 当前的残差上拟合一个弱分类器,且损失函数还是平方差函数。这和 GBDT 选择平方差损失 函数时构造弱分类器的方法恰好一致。
(1)拟合的是“残差”,对应于GBDT中的梯度方向。
(2)损失函数是平方差函数,对应于GBDT中用Decision Tree来拟合“残差”。
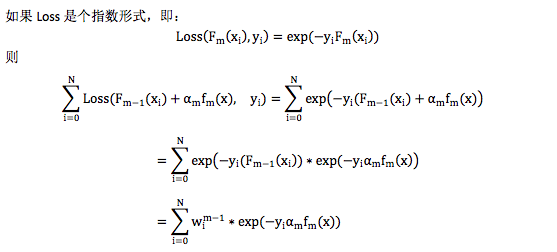
其中 wim−1= exp(−yi(Fm−1(xi))和要求解的αmfm(x)无关,可以当成样本的权重,因此在这种情况下,构造弱分类器就是在对样本设置权重后的数据上拟合,且损失函数还是指数形式。 这个就是 AdaBoost,不过 AdaBoost 最早并不是按这个思路推出来的,相反,是在 AdaBoost 提出 5 年后,人们才开始用 Forward Stagewise Additive Modeling 来解释 AdaBoost 背后的原理。
为什么要把平方差和指数形式 Loss 函数单独拿出来说呢?这是因为对这两个损失函数来说, 按照 Forward Stagewise Additive Modeling 的思路构造弱分类器时比较方便。如果是平方差损 失函数,就在残差上做平方差拟合构造弱分类器; 如果是指数形式的损失函数,就在带权 重的样本上构造弱分类器。但损失函数如果不是这两种,问题就没那么简单,比如绝对差值 函数,虽然构造弱分类器也可以表示成在残差上做绝对差值拟合,但这个子问题本身也不容 易解,因为我们是要构造多个弱分类器的,所以我们当然希望构造弱分类器这个子问题比较 好解。因此 FSAM 思路无法推广到其他一些实用的损失函数上。相比而言,Gradient Boosting Modeling (GBM) 有什么优势呢?GBM 每次迭代时,只需要计算当前的梯度,并在平方差损 失函数的基础上拟合梯度。虽然梯度的计算依赖原始问题的损失函数形式,但这不是问题, 只要损失函数是连续可微的,梯度就可以计算。至于拟合梯度这个子问题,我们总是可以选 择平方差函数作为这个子问题的损失函数,因为这个子问题是一个独立的回归问题。
因此 FSAM 和 GBM 得到的模型虽然从形式上是一样的,都是若干弱模型相加,但是他们求 解弱分类器的思路和方法有很大的差别。只有当选择平方差函数为损失函数时,这两种方法 等同。
6. 为何GBDT受人青睐
以上比较了 GBM 和 FSAM,可以看到 GBM 在损失函数的选择上有更大的灵活性,但这不足以解释GBDT的全部优势。GBDT是拿Decision Tree作为GBM里的弱分类器,GBDT的优势 首先得益于 Decision Tree 本身的一些良好特性,具体可以列举如下:
Decision Tree 可以很好的处理 missing feature,这是他的天然特性,因为决策树的每个节点只依赖一个 feature,如果某个 feature 不存在,这颗树依然可以拿来做决策,只是少一些路径。像逻辑回归,SVM 就没这个好处。
Decision Tree 可以很好的处理各种类型的 feature,也是天然特性,很好理解,同样逻辑回归和 SVM 没这样的天然特性。
对特征空间的 outlier 有鲁棒性,因为每个节点都是 x <
[笔记]GBDT理论知识总结的更多相关文章
- GBDT理论知识总结
一. GBDT的经典paper:<Greedy Function Approximation:A Gradient Boosting Machine> Abstract Function ...
- grunt学习笔记1 理论知识
你需要检查js语法错误,然后再去压缩js代码.如果这两步你都去手动操作,会耗费很多成本.Grunt就能让你省去这些手动操作的成本. “—save-dev”的意思是,在当前目录安装grunt的同时,顺便 ...
- 大数据学习笔记——HDFS理论知识之编辑日志与镜像文件
HDFS文件系统——编辑日志和镜像文件详细介绍 我们知道,启动Hadoop之后,在主节点下会产生Namenode,即名称节点进程,该节点的目录下会保存一份元数据,用来记录文件的索引,而在从节点上即Da ...
- Winsock网络编程笔记(4)----基本的理论知识
前面的笔记记录了Winsock的入门编程,领略了Winsock编程的乐趣..但这并不能算是掌握了Winsock,加深理论知识的理解才会让后续学习更加得心应手..因此,这篇笔记将记录一些有关Winsoc ...
- 线程概念( 线程的特点,进程与线程的关系, 线程和python理论知识,线程的创建)
参考博客: https://www.cnblogs.com/xiao987334176/p/9041318.html 线程概念的引入背景 进程 之前我们已经了解了操作系统中进程的概念,程序并不能单独运 ...
- python 全栈开发,Day41(线程概念,线程的特点,进程和线程的关系,线程和python 理论知识,线程的创建)
昨日内容回顾 队列 队列 : 先进先出.数据进程安全 队列实现方式: 管道 + 锁 生产者消费者模型 : 解决数据供需不平衡 管道 双向通信 数据进程不安全 EOFError: 管道是由操作系统进行引 ...
- 小D课堂 - 新版本微服务springcloud+Docker教程_3-02CAP理论知识
笔记 2.分布式应用知识CAP理论知识 简介:讲解分布式核心知识CAP理论 CAP定理: 指的是在一个分布式系统中,Consistency(一致性). Availabi ...
- js中函数的一些理论知识
函数的一些理论知识 1. 函数: 执行一个明确的动作并提供一个返回值的独立代码块.同时函数也是javascript中的一级公民(就是函数和其它变量一样). 2.函数的 ...
- 用VC进行COM编程所必须掌握的理论知识
一.为什么要用COM 软件工程发展到今天,从一开始的结构化编程,到面向对象编程,再到现在的COM编程,目标只有一个,就是希望软件能象积方块一样是累起来的,是组装起来的,而不是一点点编出来的.结构化编程 ...
随机推荐
- MVC和三层架构
从最开始写程序到现在,一路上听到架构这个词已经无数次了,在工作和圈子里也不停听到大家在讨论它,但是很多时候发现不少人对这个概念的理解都是很模糊的,无意间在知道上看到一个朋友的回答,感觉很不错,特转帖到 ...
- Bitmap的加载和Cache
由于Bitmap的特殊性以及Android对单个应用所施加的内存限制,比如16M,这导致加载Bitmap的时候很容易出现内存溢出.比如以下场景: java.lang.OutofMemoryError: ...
- 浅析NopCommerce的多语言方案
前言 这段时间在研究多语言的实现,就找了NopCommerce这个开源项目来研究了一下,并把自己对这个项目的粗浅认识与大家分享一下. 挺碰巧的是昨天收到了NopCommerce 3.90 发布测试版的 ...
- 在Eclipse上通过插件获取github上的spring源码
spring源码开始的时候是通过SVN来管理代码的,后来是转移到github上管理源码的,可以通过在github上直接下载spring的源码. 下面讲解如何通过在eclipse上的插件git来获取sp ...
- GitHub客户端Desktop的安装和使用总结
前言 这段时间想把我写的东西上传到GitHub上,所以开始收集资料学习,走了很多弯路( msysgit和极慢的FQ网速让我欲仙欲死),最后找到了比较好用的工具GitHub Desktop.在此做出自己 ...
- 每天一个linux命令(26)--用SecureCRT来上传和下载文件
用SSH管理Linux 服务器时经常需要远程与本地之间交互文件,而直接使用 SecureCRT 自带的上传下载功能无疑是最方便的,SecureCRT下的文件传输协议有ASCII.Xmodem.Zmod ...
- VUE2.0实现购物车和地址选配功能学习第二节
第二节 创建VUE实例 购物车项目计划: 1.创建一个vue实例 2.通过v-for指令渲染产品数据 3.使用filter对金额和图片进行格式化 4.使用v-on实现产品金额动态计算 5.综合演示 ① ...
- DAX/PowerBI系列 - 写在前面
今天讲的主角是: 不过,先上一个图--2017 Gartner商业智能和数据分析魔力象限 DAX关注这个玩意儿有好一段时间了,刚开始的时候(2014年?)是从Excel里面认识的.2014年当时公司用 ...
- 【经验】AngularJS
1.关于ng-model <textarea id="feature_name" class="col-sm-3" placeholder="软 ...
- Java代码块详解
Java中代码块指的是用 {} 包围的代码集合,分为4种:普通代码块,静态代码块,同步代码块,构造代码块 普通代码块: 定义:在方法.循环.判断等语句中出现的代码块 修饰:只能用标签修饰 位置:普通代 ...
- GBDT理论知识总结