DNA比对算法:BWT
DNA比对算法:BWT
BWT算法,实质上是前缀树的一种实现。那么什么是前缀树呢?
一、前缀树
对于问题p in S?如果S=rpq,那么p为S前缀rp的一个后缀。
于是,为了判断p in S 是否成立,我们找到S的所有前缀,然后逐一判断p是不是它们的后缀。为了加快效率,我们将所有的前缀建成一颗树,这棵树便是前缀树。下面,我们举例说明前缀树的建立过程和如何使用前缀树进行模式匹配。
前缀树的建立
假设S='acaacg',p='aac',那么我们首先找到S的所有前缀,如下
- a
- ac
- aca
- acaa
- acaac
- acaacg
于是,我们将这些前缀翻转过来,然后建立为一颗字典树,如下图
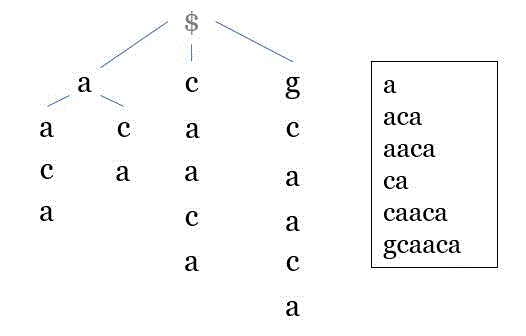
模式匹配
\(p='aac'\),令\(p'=caa\)(即p的翻转)。显然,现在只需进行一次树的搜索,即可完成匹配。
如果在判断p in S 的同时,还需要得到p 在S 中的位置,那么只需在建树的时候,将每个字符的索引加上,例如
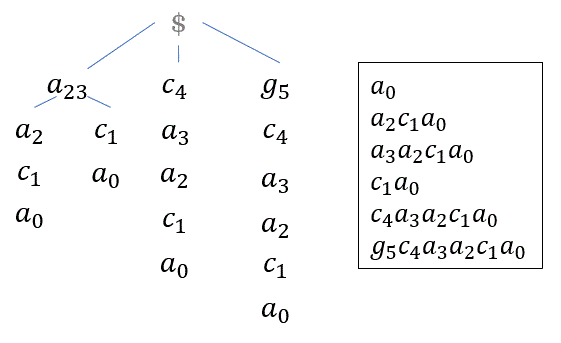
当然,也可以不保存索引,每次模式匹配结束时,沿着当前节点走下去,一直到为S[0]。
在节点中添加数字,有其他用处,详见我的另一篇博文广义后缀树的简介。
评价
我们可以看到,相对于常规的匹配算法,前缀树时间复杂度比较小,但占用空间较大。下面要说的BWT算法,就是解决这个问题的。
二、构建BWT(S)
仍然,以S='acaacg'为例。
- 令S1=S+'\$'='acaacg\$';
- 循环左移S1 6次,得到S2,S3,S4,S5,S6,S7;
- 'acaacg\$'
- 'caacg\$a'
- 'aacg\$ac'
- 'acg\$aca'
- 'cg\$acaa'
- 'g\$acaac'
- '\$acaacg'
- 对S1到S7按字典序排序(\$字符的字典序最小),取每个串的最后一个字符,连成一个序列'gc\$aaac'。于是为BWT(S)='gc\$aaac'。
- '\$acaacg'
- 'aacg\$ac'
- 'acaacg\$'
- 'acg\$aca'
- 'caacg\$a'
- 'cg\$acaa'
- 'g\$acaac'
也许,到这里,你还不清楚BWT变换和前缀树,有什么关系。那就接着往下看吧。
三、使用BWT,进行模式匹配
我们已经知道BWT(S)='gc\$aaac',对BWT(S)中的字符进行排序得到S'='\$aaaccg',得到下图形式的矩阵。

这个矩阵看起来,有些规律,但是又很奇怪。下面通过复原S的过程,我们来理解以下这个矩阵。
复原S
这个过程用语言描述比较麻烦,直接看图

按照图中(1)到(7)步,我们即可得到'$gcaaca',于是S='acaacg'。
其中,斜线表示是,我们找到最后一列的某个符号,然后跳至这个符号在第一列的位置。比如,在第(2)步中,最后一列为第2个c,我们跳到第一行中第2个c的位置。
模式匹配
p='aac',令\(p'='caa'\),选取c作为起点,由于S中有两个c,因此有两种可能 的匹配。
- 从第一个c出发

- 从第二个c出发

因此,在方案2得到p',因此p in S是正确的。
几个问题
- 问题一:如何得到某个符号,在本列中是第几个?
显然,我们可以使用一个数组来保存。例如,对于'$gcaaca',数组a=[1,1,1,1,2,2,3]。
$ g c a a c a
[1,1,1,1,2,2,3]
但是,还有一种省空间的办法。我们只保存串'$gcaaca'中某些字符的位置,这些字符我们称为checkpoint。
- 问题二:如何得到模式p在S中的位置?
匹配模式串之后,继续运行,直至\$,但是这样比较耗时。
另一种办法,在BWT串中记录相应的偏移。这种办法空间开销比较大,也可以采取类似于checkpoint的方法,记录部分的偏移。
四、待研究的问题
- 如何快速得到一个串的BWT编码?
- 如何允许部分匹配?
题外话
DNA比对还有一类快速的办法——使用哈希。
DNA比对算法:BWT的更多相关文章
- LeetCode-Repeated DNA Sequences (位图算法减少内存)
Repeated DNA Sequences All DNA is composed of a series of nucleotides abbreviated as A, C, G, and T, ...
- 51nod 1445 变色DNA ( Bellman-Ford算法求单源最短路径)
1445 变色DNA 基准时间限制:1 秒 空间限制:131072 KB 分值: 40 难度:4级算法题 有一只特别的狼,它在每个夜晚会进行变色,研究发现它可以变成N种颜色之一,将这些颜色标号为0,1 ...
- HDU1560 DNA sequence —— IDA*算法
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1560 DNA sequence Time Limit: 15000/5000 MS (Java/Oth ...
- 算法 - DNA搜索 - Ako Corasick
场景:从很长的字符串(输入字符串.DNA)中搜索大量固定字符串(字典.基因) 题目:Determining DNA Health | HackerRank 算法:Aho–Corasick algori ...
- 字符串与模式匹配算法(六):Needleman–Wunsch算法
一.Needleman-Wunsch 算法 尼德曼-翁施算法(英语:Needleman-Wunsch Algorithm)是基于生物信息学的知识来匹配蛋白序列或者DNA序列的算法.这是将动态算法应用于 ...
- 一个简单算法题引发的思考<DNA sorting>(about cin/template/new etc)
首先是昨天在北京大学oj网上看到一个简单的算法题目,虽然简单,但是如何完成一段高效.简洁.让人容易看懂的代码对于我这个基础不好,刚刚进入计算机行业的小白来说还是有意义的.而且在写代码的过程中,会发现自 ...
- 利用Needleman–Wunsch算法进行DNA序列全局比对
生物信息学原理作业第二弹:利用Needleman–Wunsch算法进行DNA序列全局比对. 具体原理:https://en.wikipedia.org/wiki/Needleman%E2%80%93W ...
- DNA binding motif比对算法
DNA binding motif比对算法 2012-08-31 ~ ADMIN 之前介绍了序列比对的一些算法.本节主要讲述motif(有人翻译成结构模式,但本文一律使用基模)的比对算法. 那么什么是 ...
- 算法:POJ1007 DNA sorting
这题比较简单,重点应该在如何减少循环次数. package practice; import java.io.BufferedInputStream; import java.util.Map; im ...
随机推荐
- instance 怎么获得自己的 Metadata - 每天5分钟玩转 OpenStack(169)
要想从 nova-api-metadata 获得 metadata,需要指定 instance 的 id.但 instance 刚启动时无法知道自己的 id,所以 http 请求中不会有 instan ...
- ES6 学习笔记(一)let,const和解构赋值
let和const let和const是es6新增的两个变量声明关键字,与var的不同点在于: (1)let和const都是块级作用域,在{}内有效,这点在for循环中非常有用,只在循环体内有效.va ...
- 【笔记】归纳js getcomputedStyle, currentStyle 以及其相关用法
好吧,鉴于前端则个行业知识宽度广而深,早期看过高程介绍过的获取元素计算后的最终样式(浏览器显示的最终样式)的方法现在也忘得七七八八了 于是百度了一下,看了一下大神张鑫旭的博客,这里写个随笔记录一下 ...
- 程序员的基本功之Java集合的实现细节
1.Set集合与Map 仔细对比观察上面Set下和Map下的接口名,不难发现它们如此的相似,必有原因 如果只考察Map的Key会发现,它们不可以重复,没有顺序,也就是说把Map的所有的Key集中起来就 ...
- javascript执行顺序小结
作为web开发人员,一定要对js的执行顺序,解析原理有一定了解,否则无法掌控这门小巧好用的语言 javascript是一门实现网页动态效果的语言,也是主要负责和服务端的交互,他抛弃了像java中类的束 ...
- mysql笔记一——安装和设置root密码
1. mysql 5.6安装包下载. MySQL安装文件分为两种,一种是msi格式的,一种是zip格式的.如果是msi格式的可以直接点击安装,按照它给出的安装提示进行安装(相信大家的英文可以看懂英文提 ...
- 如何掌握并提高linux运维技能
初中级Linux运维人员们系统学习并迅速掌握Linux的运维实战技能.学习路线大纲如下: 入门基础篇 系统运维篇 Web运维篇 数据库运维篇 集群实战篇 运维监控篇 第一篇:Linux入门(安装.配置 ...
- java 基础知识八 正则表达式
java 基础知识八 正则表达式 正则表达式是一种可以用于模式匹配和替换的规范,一个正则表达式就是由普通的字符(例如字符a到z)以及特殊字符(元字符)组成的文字模式,它 用以描述在查找文字主体时待 ...
- sublime text3 在ubutun下的下载和配置
最近在学习 Javascript,在 w3c school 上把教程看完了,也算个刚刚入门的水平,一直都是在 win 系统 上练习. 但是因为写 python 代码的 pycharm 和 git 配置 ...
- sublime-text-3设置输入中文方法
sublime-text-3 编辑器性感而敏捷,却让人感慨有其长必有其短. 有些缺点都可以通过插件解决.但是要解决输入中文问题却很复杂,不能输入中文实在是太痛苦了. 我在做一个有很多文字的html页面 ...