python selenium 元素定位(三)
上两篇的博文中介绍了python selenium的环境搭建和编写的第一个自动化测试脚本,从第二篇的例子中看出来再做UI级别的自动化测试的时候,有一个至关重要的因素,那就是元素的定位,只有从页面上找到这个元素,我们从能对这个元素进行操作,那么我们下来看看如何来定位元素。
selenium 提供了8中元素定位的方法(大家要学习元素的定位,首先可以学习下前端的基础知识,这样有利于我们学习自动化测试,大家可以看一下:http://www.runoob.com/)
- find_element_by_id
- find_element_by_name
- find_element_by_xpath
- find_element_by_link_text
- find_element_by_partial_link_text
- find_element_by_tag_name
- find_element_by_class_name
- find_element_by_css_selector
下面我们详细的介绍一下,每个方法的含义以及每个方法的使用。
1.find_element_by_id 根据标签id定位
示例HTML代码:
<html>
<body>
<input id="kw" name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
</body>
<html>
网页需要通过开发者工具,打开浏览器按F12获取页面元素,我们已经看到上述的页面html代码,我们现在要查找id="kw"的元素
driver.find_element_by_id('kw') #通过id定位
2.find_element_by_name 根据标签的name定位
driver.find_element_by_name('username') #通过name定位
3.find_element_by_xpath 根据xpath定位
driver.find_element_by_xpath('//*[@id="kw"]')
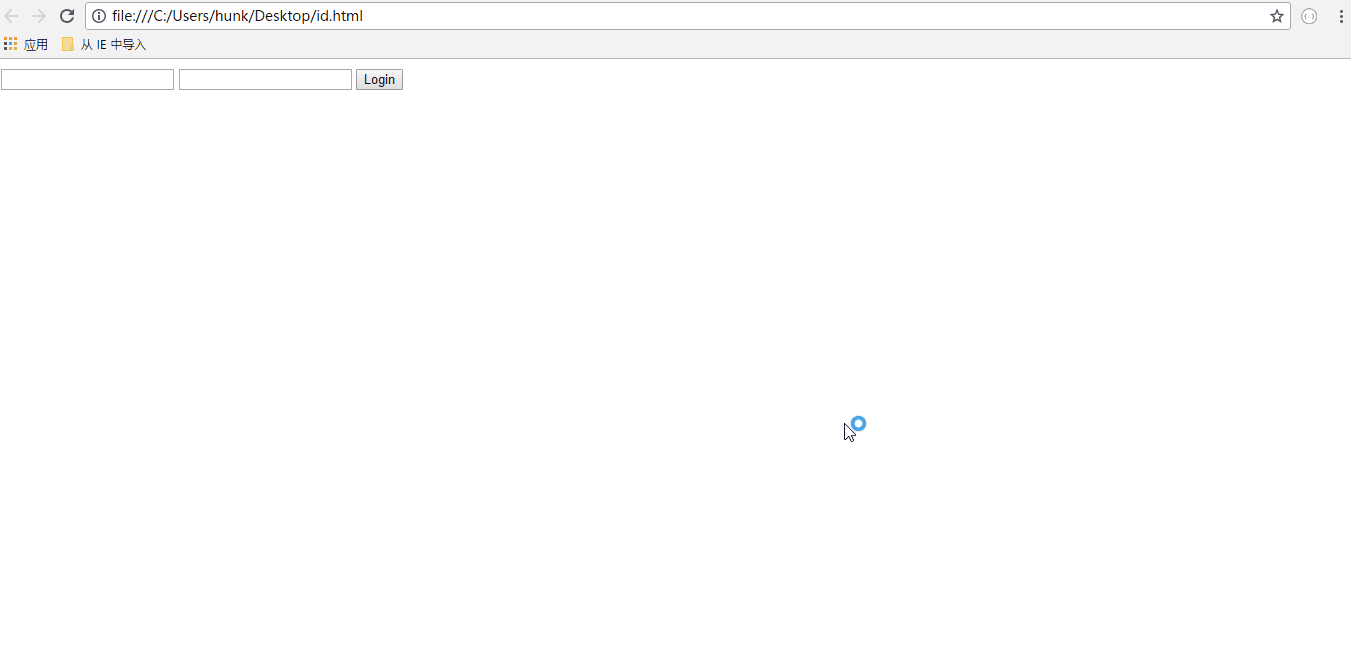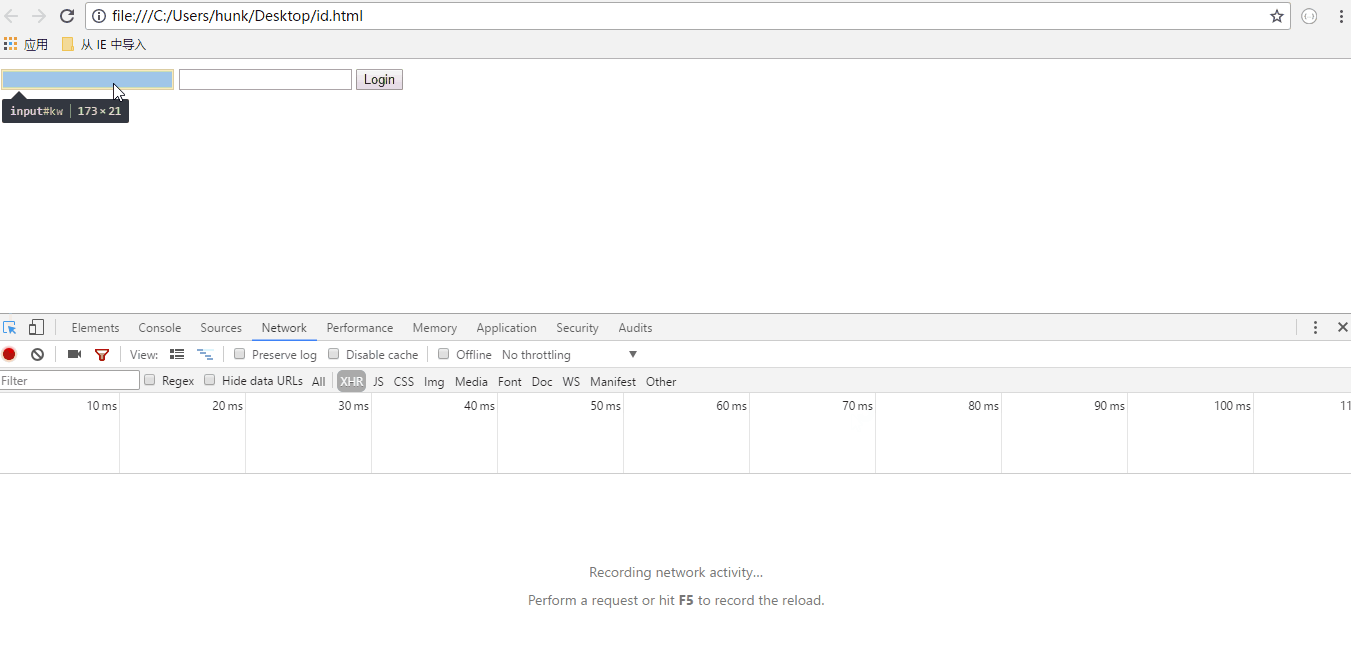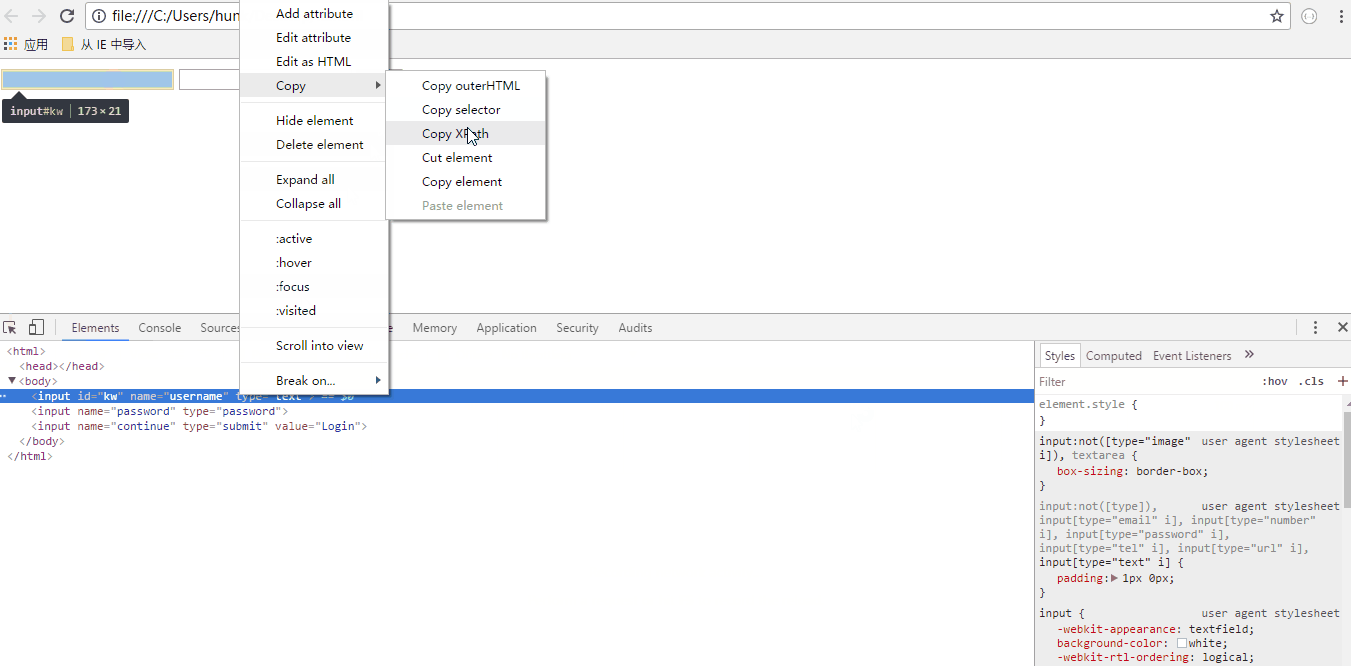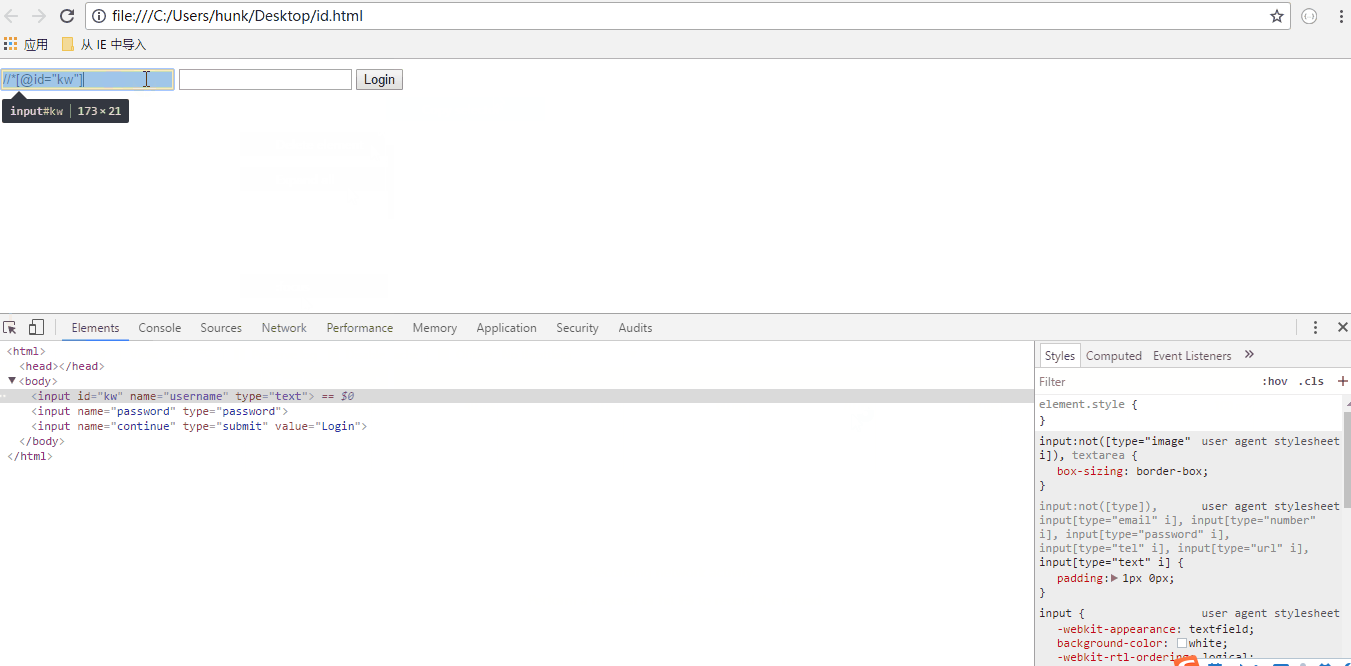
这里要介绍一下如何获取页面元素的xpath路径的方法,如果你是大神可以自己写,如果跟作者一样很喽,可以通过开发者工具获取,选择元素右击->Copy->Copy Xpath,可以直接拷贝到xpath路径.
4.find_element_by_link_text和find_element_by_partial_link_text 通过文字链接来定位元素,他们两个很相像,功能也很类似,但是他们一个是匹配全部,一个是匹配部分。
给我们之前的示例代码增加一段,我们来看看如何定位
<html>
<body>
<input id="kw" name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<div id="u1">
<a href="http://news.baidu.com" name="tj_trnews" class="mnav">新闻</a>
<a href="http://www.hao123.com" name="tj_trhao123" class="mnav">hao123</a>
<a href="http://map.baidu.com" name="tj_trmap" class="mnav">地图</a>
<a href="http://v.baidu.com" name="tj_trvideo" class="mnav">视频</a>
<a href="http://tieba.baidu.com" name="tj_trtieba" class="mnav">贴吧</a>
<a href="http://xueshu.baidu.com" name="tj_trxueshu" class="mnav">学术</a>
</body>
<html>
下面我们用两种方法来定位一下《新闻》这个元素
通过来find_element_by_link_text定位
#-*- coding:utf-8 -*-
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("file:///C:/Users/hunk/Desktop/id.html")
driver.find_element_by_link_text('新闻').click()
time.sleep(3)
driver.quit() #退出浏览器
定位效果:
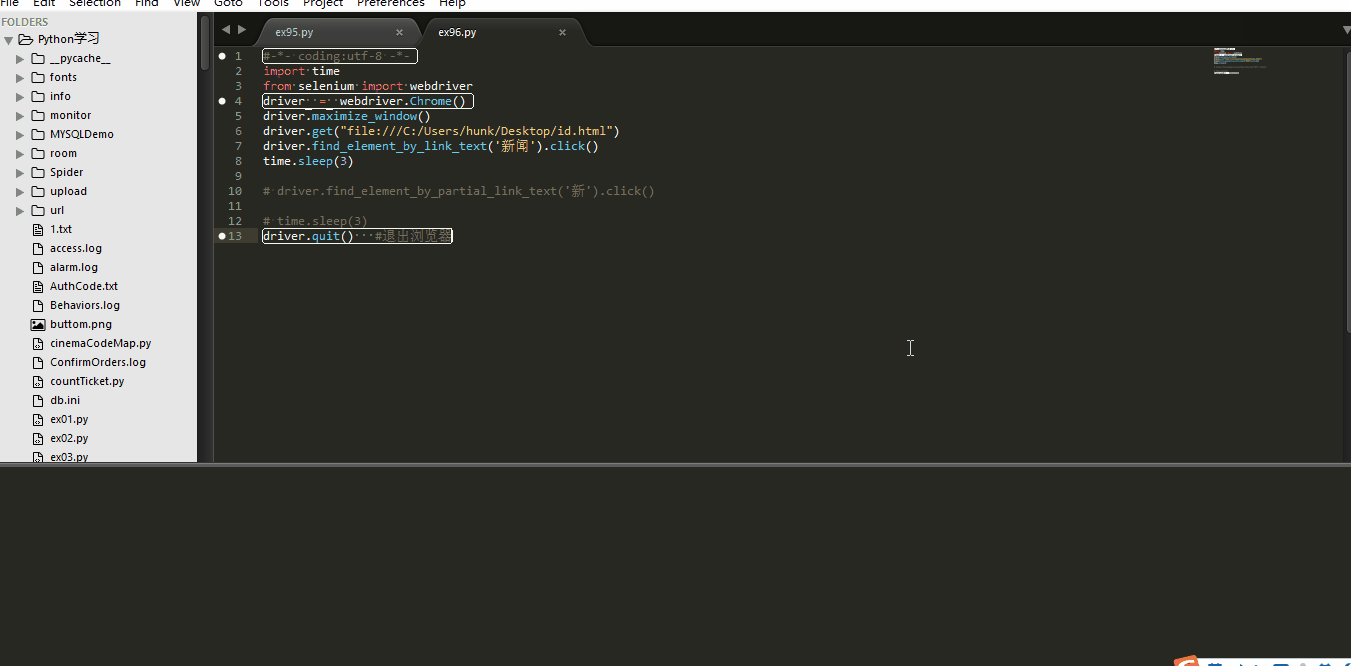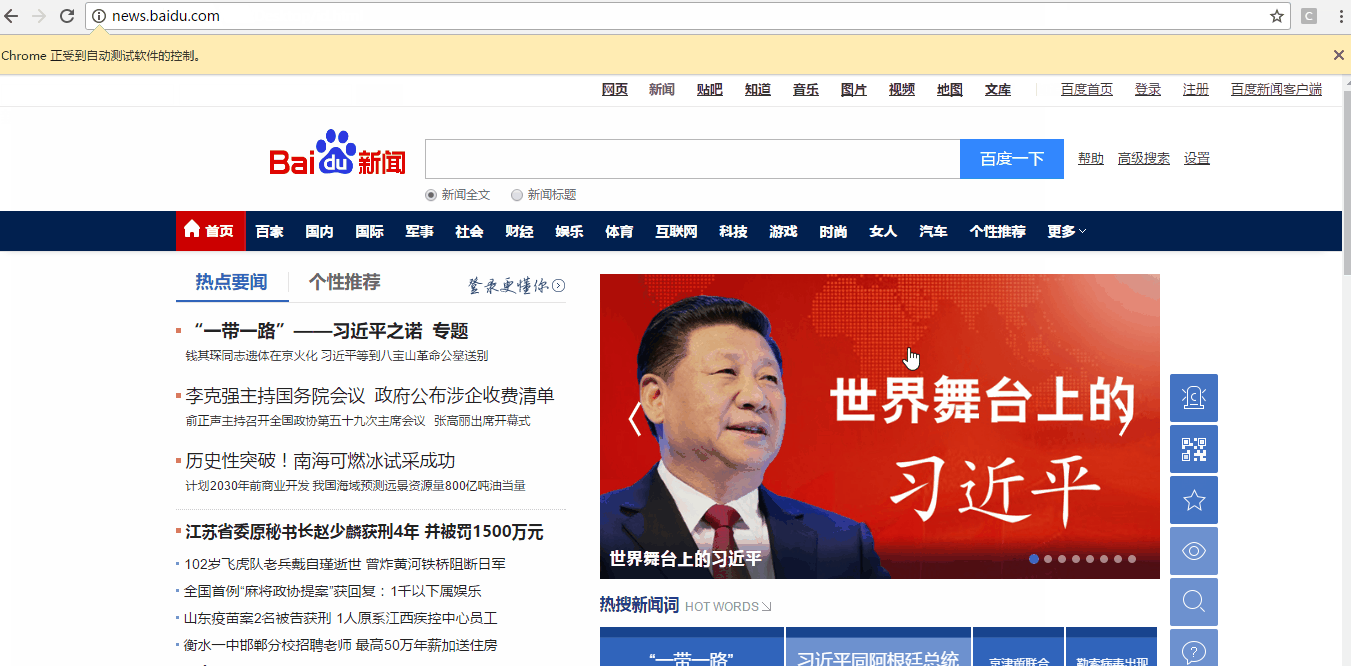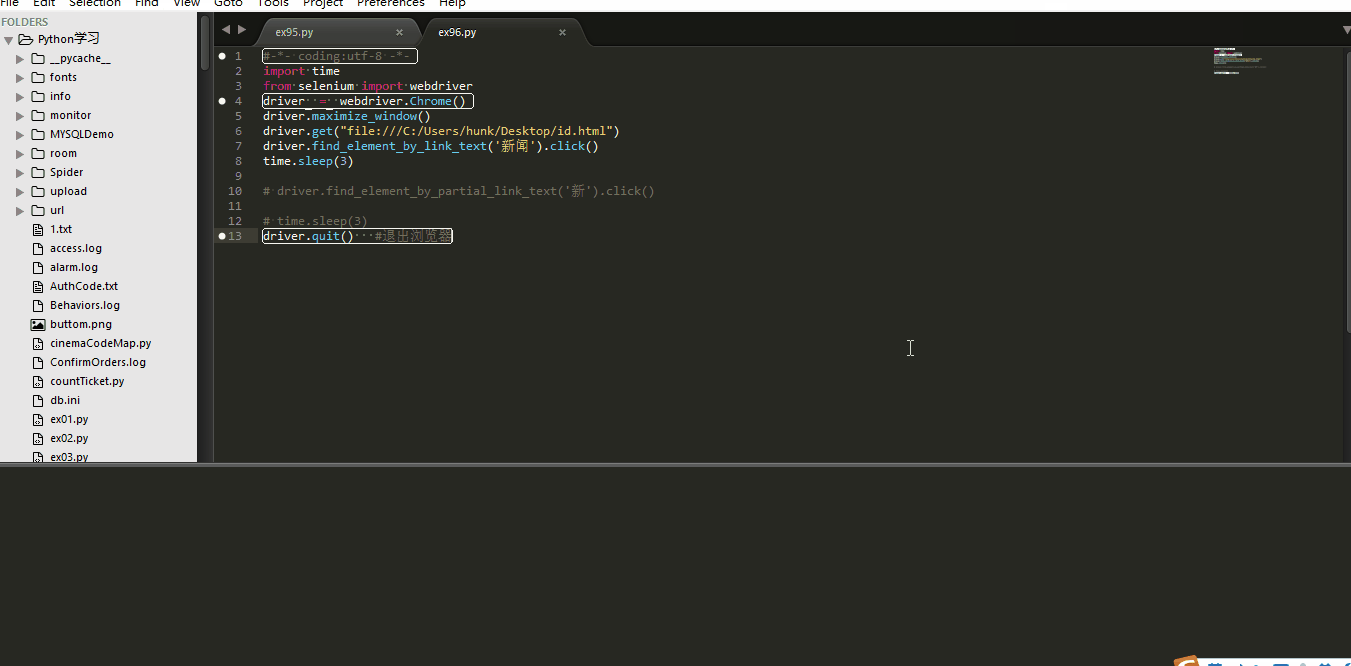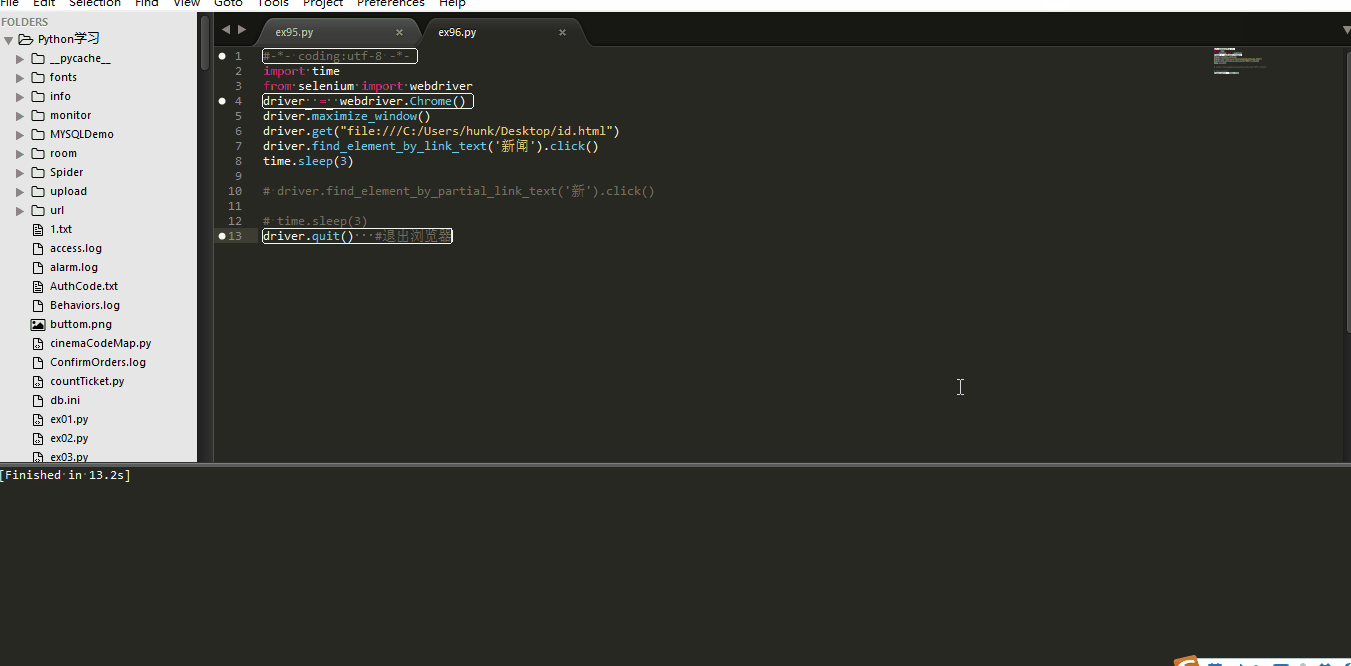
通过来find_element_by_partial_link_text定位

5.find_element_by_tag_name根据标签的名字定位,这种方法很不使用,因为一个页面的中的标签的名字重复度太早,定位起来太不容易。
driver.find_element_by_tag_name("input")
6.find_element_by_class_name通过class name 定位
<html>
<body>
<p class="content">Site content goes here.</p>
</body>
<html>
driver.find_element_by_class_name('content') #通过class name 定位
7.find_element_by_css_selector 根据元素属性来定位,这个方法在实际过程中比较实用,而且很简单,下面我们先看一下语法,这里有一个比较关键点就是,在这个定位的方法是可以写正则表达式来定位元素,然后在写一个实例来定位,实例我们采用百度网站来定位,然后搜索selenium关键字。
<html>
<body>
<p class="content">Site content goes here.</p>
</body>
<html>
定位语法
driver.find_element_by_css_selector("p[class=\"content\"]") #根据元素属性
示例:
#-*- coding:utf-8 -*-
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("http://www.baidu.com")
driver.find_element_by_css_selector("input[id=\"kw\"]").send_keys('selenium') #定位输入框输入selenium
driver.find_element_by_css_selector("input[type=\"submit\"]").click() #定位搜索按钮点击按钮,属性选择type
time.sleep(5)
driver.quit() #退出浏览器
来看一下动画效果吧
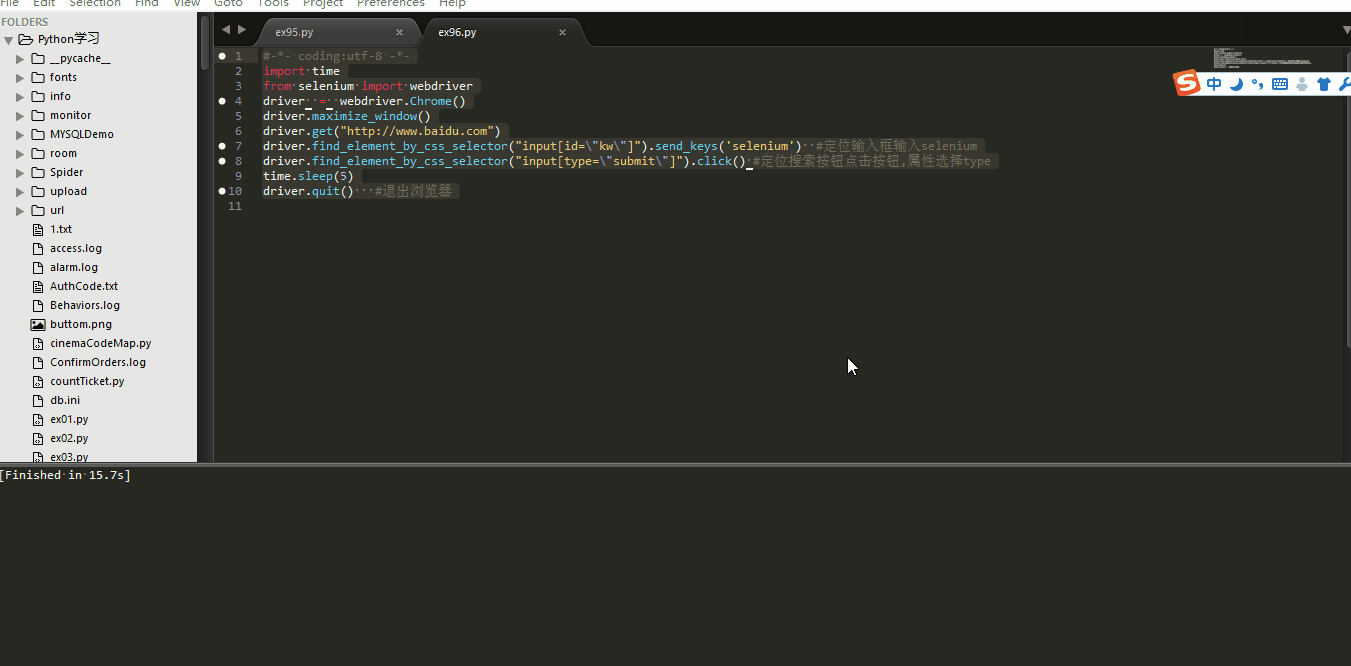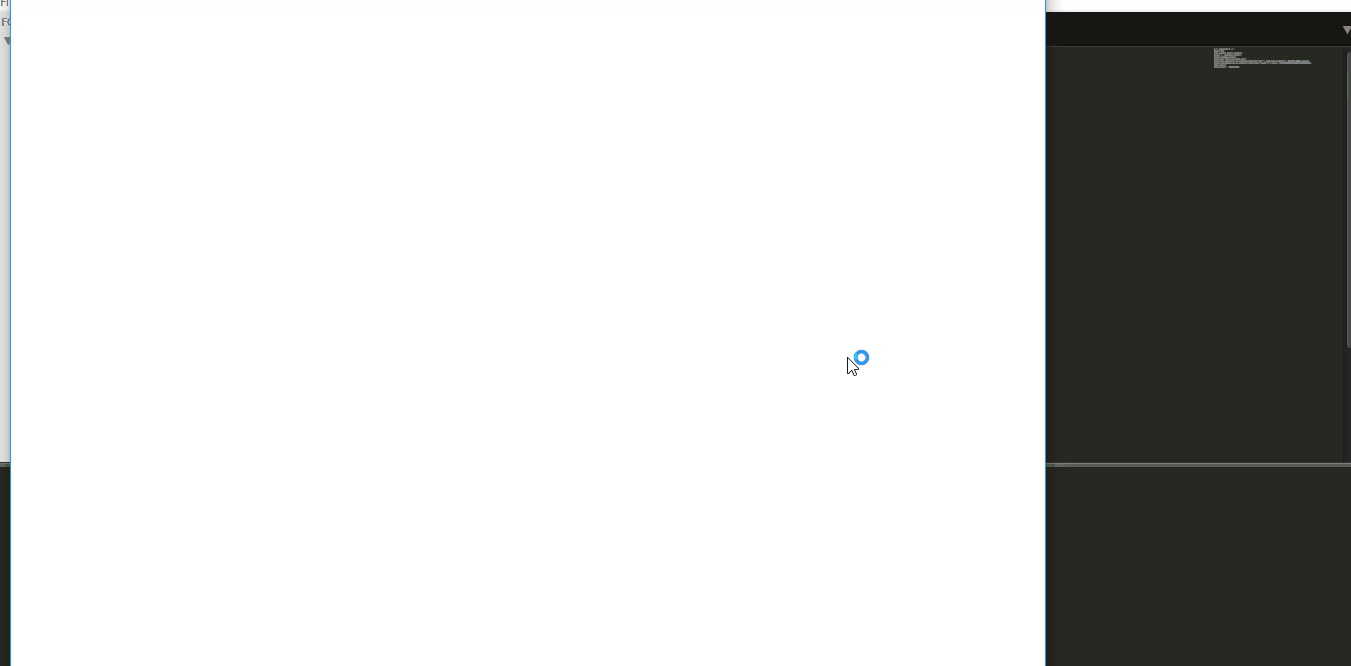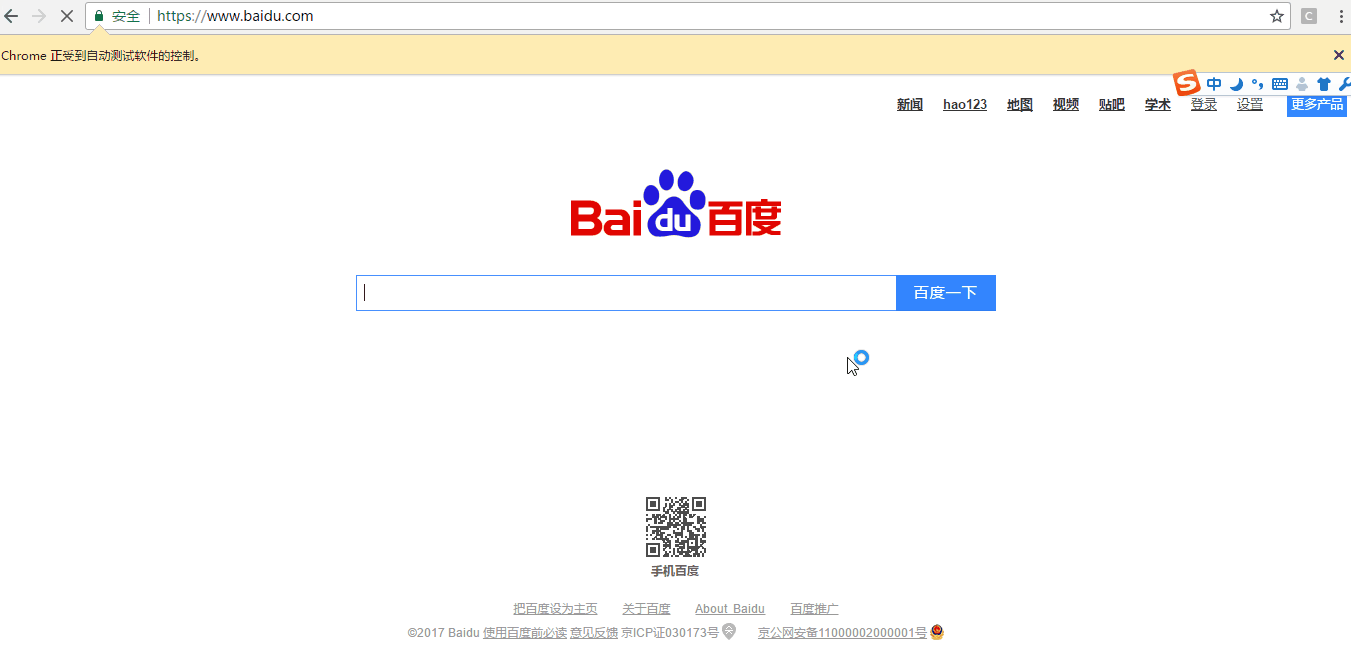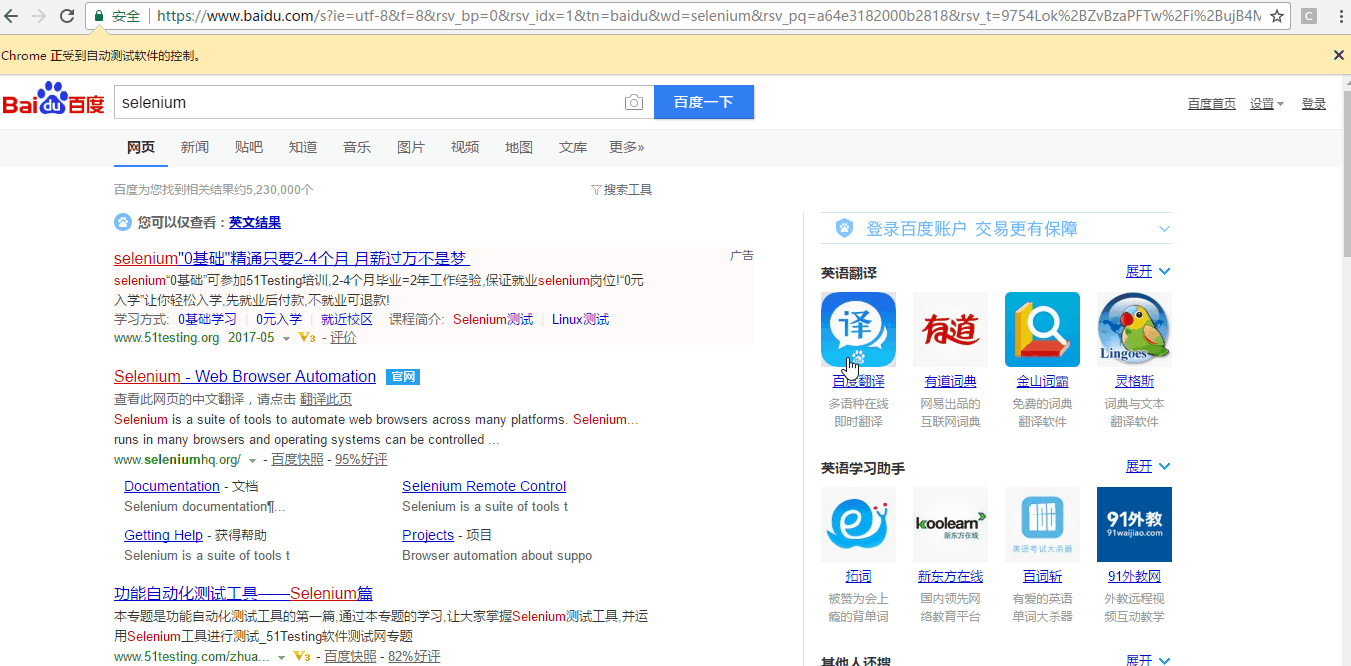
其实元素的定位很简单,只是实际过程中定位的html页面有一些特殊的地方,只要我们拆解分析,自然也难不倒我们。
下面这几个方法返回的结果是列表,跟单个元素定位一样,只是返回的结果不同,这里就不详细介绍了。
- find_elements_by_id
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
python selenium 元素定位(三)的更多相关文章
- python+selenium元素定位——8种方法
定位元素,selenium提供了8中元素定位方法: (1)find_element_by_id() :html规定,id在html中必须是唯一的,有点类似于身份证号 (2)find_element_b ...
- python+selenium 元素定位--iframe
1. 一般webdriver要操作页面元素需要在Top Window的状态下,如下: 2.当浏览器显示iframe时,用正常的元素定位是没有效果的,需要将页面装换到iframe下再对页面元素进行操作 ...
- python+selenium元素定位之XPath学习02
XPath 语法 XPath 使用路径表达式来选取 XML 文档中的节点或节点集.节点是通过沿着路径 (path) 或者步 (steps) 来选取的. XML 实例文档 我们将在下面的例子中使用这个 ...
- python+selenium元素定位之XPath学习01
参考文档1:https://www.w3school.com.cn/xpath/xpath_syntax.asp 参考文档2:https://www.runoob.com/xpath/xpath-tu ...
- python+selenium元素定位之CSS学习02
参考文档:https://www.runoob.com/cssref/css-selectors.html CSS选择器用于选择你想要的元素的样式的模式. "CSS"列表示在CSS ...
- python+selenium元素定位之CSS学习01
参考文档:https://www.w3school.com.cn/cssref/css_selectors.asp 选择器 例子 例子描述 CSS .class .intro 选择 class=&qu ...
- python+selenium 元素被定位到而且click()也提示执行成功,但是页面就是没有变化和跳转。
python+selenium 元素被定位到而且click()也提示执行成功,但是页面就是没有变化和跳转. 如果多次定位和click(),有时候会跳转. 我遇到很多次就是很郁闷,有人说,操作太快的,页 ...
- Python+Selenium自动化-定位一组元素,单选框、复选框的选中方法
Python+Selenium自动化-定位一组元素,单选框.复选框的选中方法 之前学习了8种定位单个元素的方法,同时webdriver还提供了8种定位一组元素的方法.唯一区别就是在单词elemen ...
- Python+Selenium自动化-定位页面元素的八种方法
Python+Selenium自动化-定位页面元素的八种方法 本篇文字主要学习selenium定位页面元素的集中方法,以百度首页为例子. 0.元素定位方法主要有: id定位:find_elemen ...
随机推荐
- java 8 Hashmap深入解析 —— put get 方法源码
每个java程序员都知道,HashMap是java中最重要的集合类之一,也是找工作面试中非常常见的考点,因为HashMap的实现本身确实蕴含了很多精妙的代码设计. 对于普通的程序员,可能仅仅能说出Ha ...
- iOS 开发遇到 调不起相机问题
在iOS 开发中 使用html 中的input 标签调起工程里面的相机,手机无反应 1.先看看info.plist 加没加相机的权限,添加Privacy - Camera Usage Descript ...
- thinkphp3.2.x多图上传并且生成多张缩略图
html部分 <!DOCTYPE html><html><head><meta http-equiv="Content-Type" con ...
- Android 开发之错误整理java.lang.SecurityException: Requires READ_PHONE_STATE: Neither user 10088 nor current process has android.permission.READ_PHONE_STATE.
java.lang.SecurityException: Requires READ_PHONE_STATE: Neither user 10088 nor current process has a ...
- jquery template.js前端模板引擎
作为现代应用,ajax的大量使用,使得前端工程师们日常的开发少不了拼装模板,渲染模板 在刚有web的时候,前端与后端的交互,非常直白,浏览器端发出URL,后端返回一张拼好了的HTML串.浏览器对其进行 ...
- [原创] IAR7.10安装注册教程
代码开发简单化的趋势势不可挡,TI 公司推出的 IAR7.10 以上版本,集成代码库,方便初学者进行学习移植.本教程详细列出IAR7.10安装以及注册步骤,不足之处望多多交流. 好了进入正题. 第一, ...
- Coordinator节点
Coordinator节点 Coordinator 节点主要负责segment 的管理和分配.更具体的说,它同通过配置往historical 节点 load 或者 drop segment .Coo ...
- struts2之拦截器
1. 为什么需要拦截器 早期MVC框架将一些通用操作写死在核心控制器中,致使框架灵活性不足.可扩展性降低, Struts 2将核心功能放到多个拦截器中实现,拦截器可自由选择和组合,增强了灵活性,有利于 ...
- C语言基础知识点整理(函数/变量/常量/指针/数组/结构体)
函数 - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - ...
- STM32学习笔记(五)——通用定时器计数延时
STM32定时器概述 STM32F40x系列总共最多有14个定时器,定时器分为三类:基本定时器.通用定时器和高级定时器.它们的都是通过计数来达到定时的目的,和51的定时器差不多,基本原理都是一样的,就 ...