Python协程爬取妹子图(内有福利,你懂得~)
项目说明:
1、项目介绍
本项目使用Python提供的协程+scrapy中的选择器的使用(相当好用)实现爬取妹子图的(福利图)图片,这个学会了,某榴什么的、pow(2, 10)是吧!
2、用到的知识点
本项目中会用到以下知识点
① Python的编程(本人使用版本3.6.2)
② 使用scrapy中的css选择器
③ 使用async协程
④ 使用aiohttp异步访问url
⑤ 使用aiofiles异步保存文件
3、 项目效果图
项目实现:
我们最终的目的是把图片的标题替换成需要保存的目录,下面的图片呢,就按着网页上图片的名称保存~,有了这个需求以后,ok,社会我demon哥,人很话不多,开干!
我们需要网站的入口,入口如下~就爬取萌妹子吧!
妹子图中萌妹分类的网站入口:http://www.meizitu.com/a/cute.html
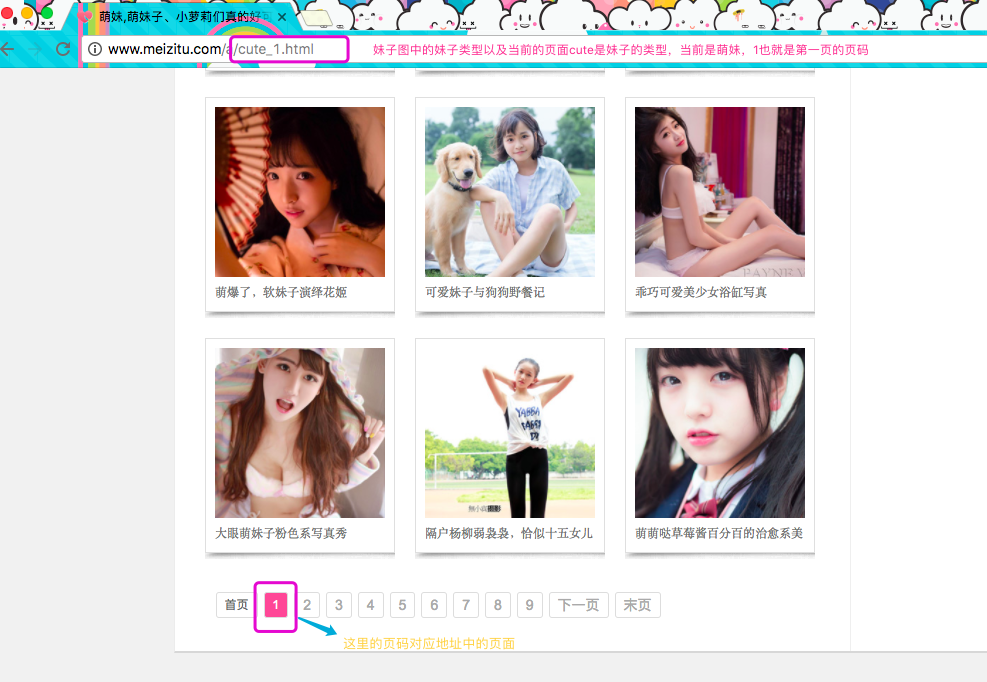
打开萌妹子的入口链接以后,我们需要分析下网页中结构,然后通过分析页面,获取我们有用的内容:
通过入口我们得知,url地址中,有两个我们需要关系的点,一个是妹子图的妹子类型,一个是要获取页面的页码,如果获取多页的话,也就是替换成不同的页码即可(图如下)
分析完上面的页面以后,我们在来分析当前页中需要提取的信息 ,使用Chrome浏览器打开开发者模式(windows是F12,MacOS是command+option+i)
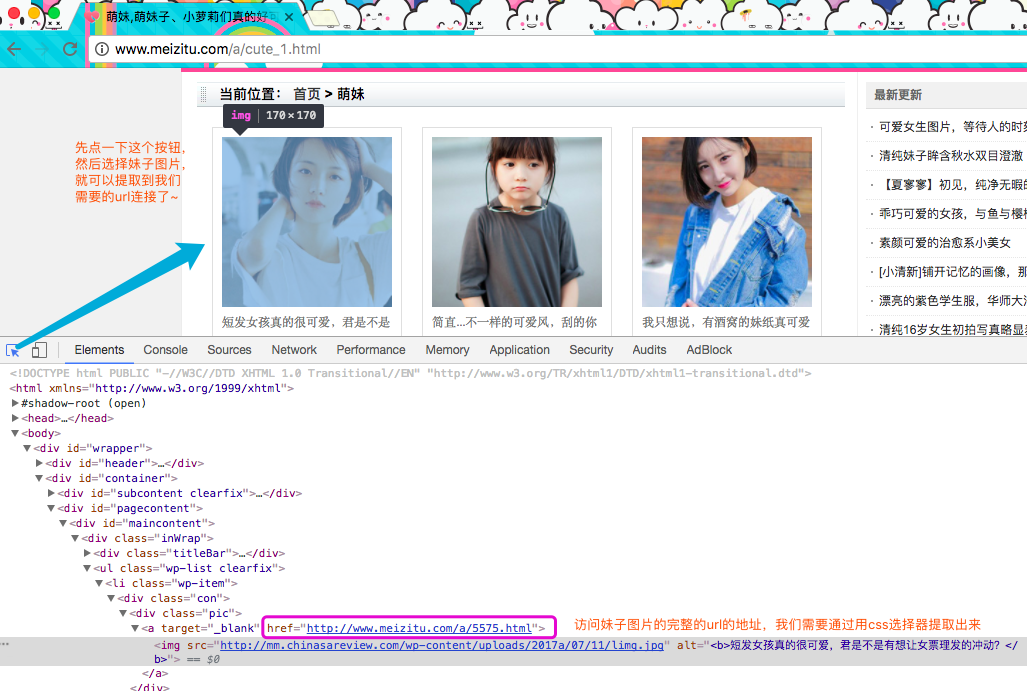
点击刚刚选中妹子的url的地址,我们在来分析这里面的有用信息
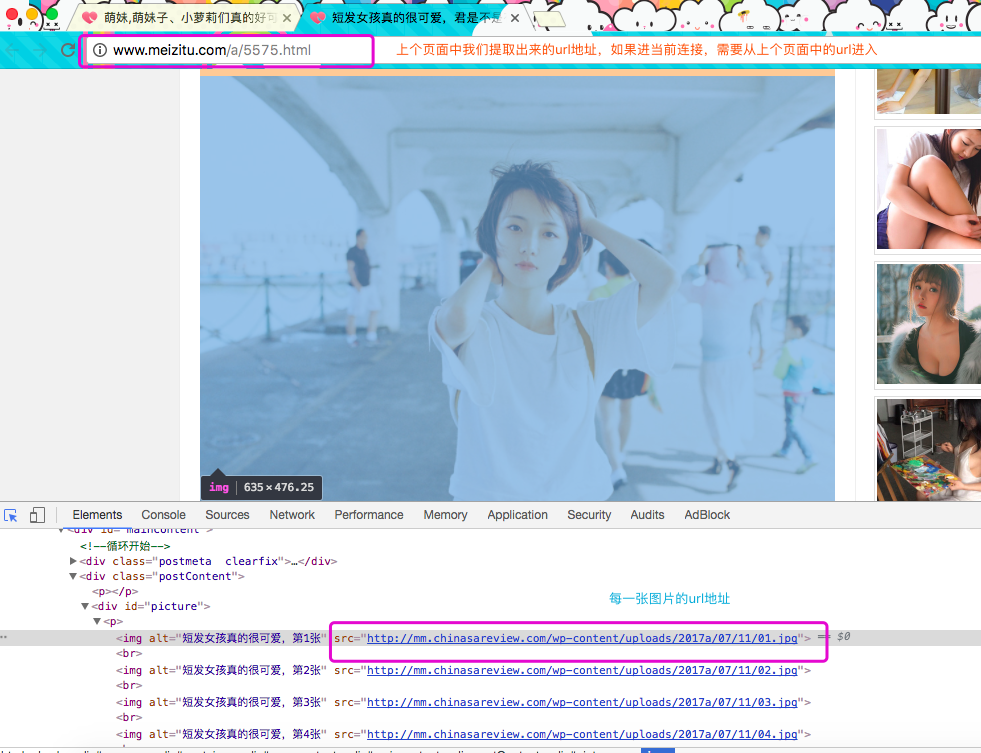
信息提取就到这里,我们下面需要使用css选择器,提取url然后开始写方法,来下载这些图片
没有安装的scrapy的赶紧去pip3 install scrapy一下,要么您老就右上角的小叉叉退出吧~ 不然没办法进行了!
Scrapy提供一个Shell的参数命令了,在这个参数后面加上你要提取页面中的url地址,就可以进入到scrapy shell中,在里面可以通过css xpath选择器调试提取信息,用法如下:
在终端输入: scrapy shell http://www.meizitu.com/a/cute.html
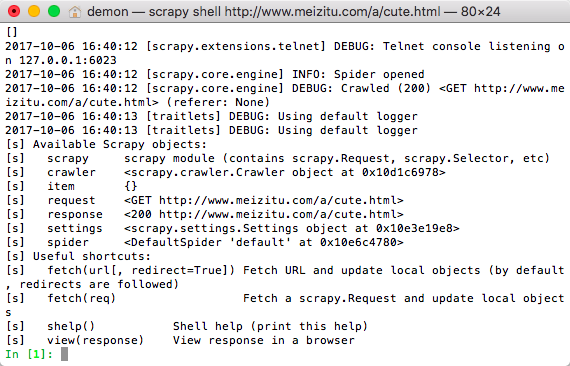
出现上面的即可,这里面有个response,我们可以通过response.css或者reponses.xpath获取url的数据,ok..我这里使用css来提取,为嘛?! 简单呗~
css的具体语法嘛~~大家不会的话,可以自行百度,或者去菜鸟站补一补知识,我这人比较懒,我就不讲了!直接告诉你们怎么提取吧~可以通过Chrome给我提供的开发者工具来获取css选择器的表达式,请看下图
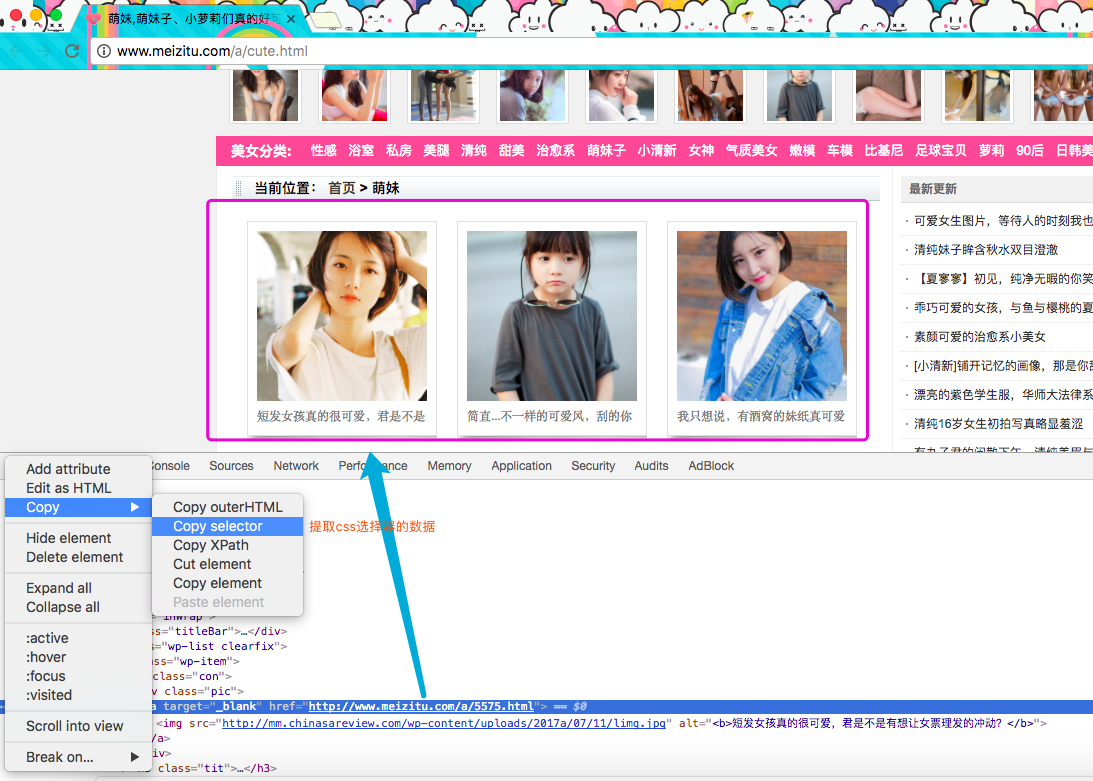
上面图的图很眼熟对吧,嗯,这是哪个主页图,我们需要在当前页面中获取所有妹子的url地址,然后在进入到每个妹子的url地址中获取这个妹子的所有图片!首先先来获取当前页面的所有妹子的url地址,切换到scrap shell中,通过response.css来提取信息
提取妹子的url地址: response.css('#maincontent a::attr(href)').extract()
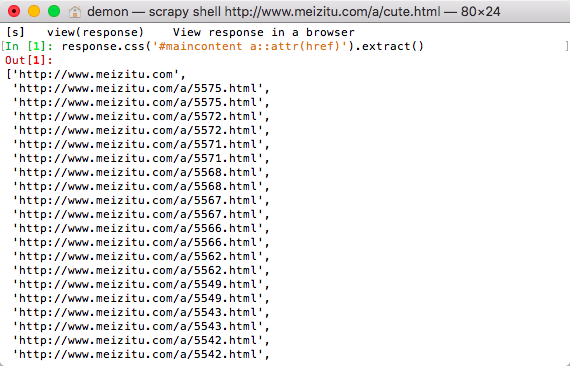
嘿~,当前页面的中的所有妹子的url都有了,那就好办了呀,在进入这些地址中逐个获取妹子独立页面中的url地址,然后下载就好咯!但是,大家有木有发现,这些页面中的url有重复的,怎么办呢,用set可以去重哦,先来写个获取当前页面的简单的方法,一会我们在修改这个方法。
import requests
from scrapy import Selector def get_page_items(*, start_page_num: int=1, end_page_num: int=2, step: int=1):
items = []
for page_num in range(start_page_num, end_page_num, step):
base_url = 'http://www.meizitu.com/a/{genre}_{page_num}.html'
req = requests.get(base_url.format(genre='cute', page_num=1))
content = req.content.decode('gbk')
selector = Selector(text=content)
item_urls = list(set(selector.css('#maincontent a::attr(href)').extract()))
items.extend(url for url in item_urls if url.startswith('http://www.meizitu.com/a/'))
return items print(get_page_items())
上面的代码可以供我们拿下指定页面中的所有漂亮小姐姐的url地址哦~,有了这些漂亮小姐姐的url,进入这个url以后,在提取小姐姐页面的所有url就可以下载啦~!
import requests
from scrapy import Selector def get_page_items(*, start_page_num: int=1, end_page_num: int=2, step: int=1):
items = []
for page_num in range(start_page_num, end_page_num, step):
base_url = 'http://www.meizitu.com/a/{genre}_{page_num}.html'
req = requests.get(base_url.format(genre='cute', page_num=1))
content = req.content.decode('gbk')
selector = Selector(text=content)
item_urls = list(set(selector.css('#maincontent a::attr(href)').extract()))
items.extend(url for url in item_urls if url.startswith('http://www.meizitu.com/a/'))
return items def get_images(item):
req = requests.get(item)
content = req.content.decode('gbk')
selector = Selector(text=content)
image_urls = list(set(selector.css('#maincontent p img::attr(src)').extract()))
print(image_urls) for item in get_page_items():
get_images(item)
上面代码执行的结果为:
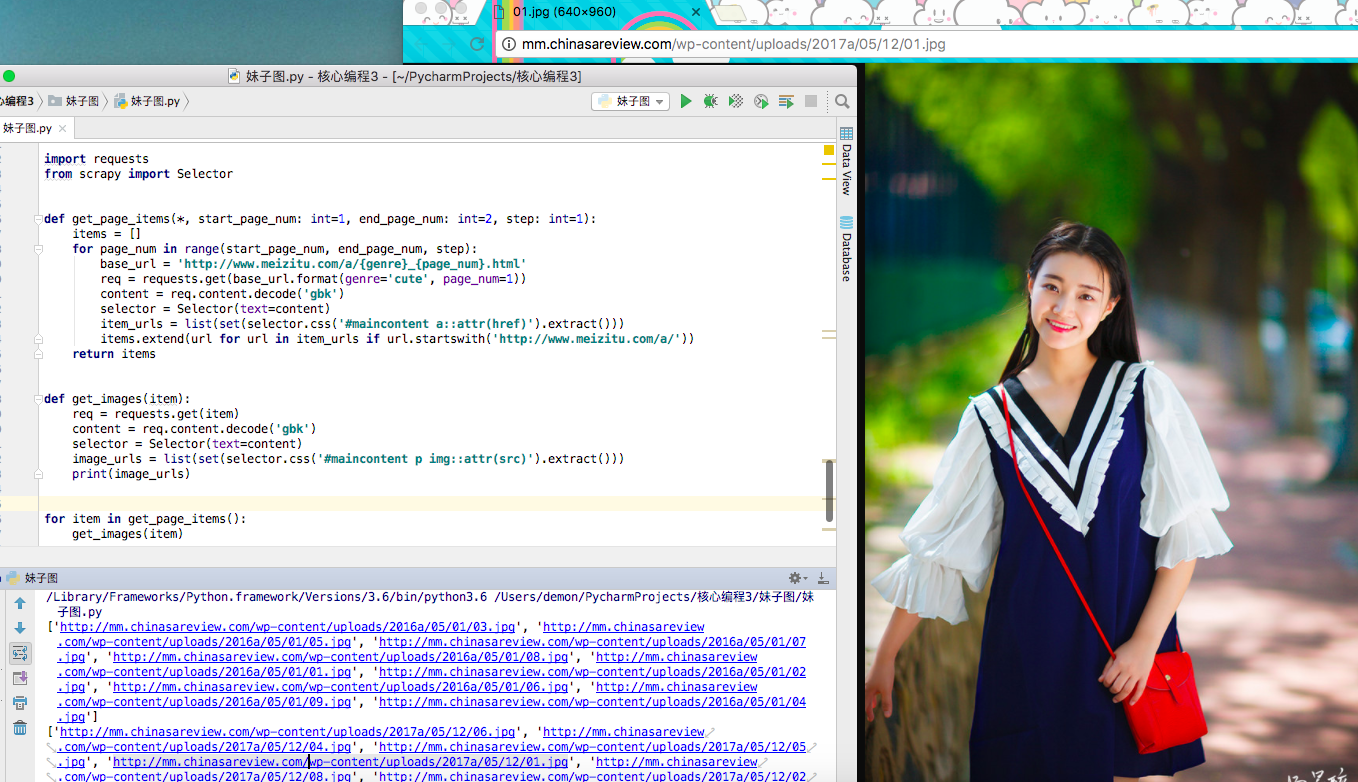
可以看到的效果,所有小姐姐的下载图片的地址都已经拿到了,但是上面的代码有两个问题,聪明的小伙伴,可能已经发现了,上面代码的重合性太高,那些获取url的咚咚,都可以整合,在下面的一版,我们来改写这个函数,有了这些图片的地址,我们只需要调取某个函数或者方法,来下载这些图片保存到本地即可,怎么玩?! 往下看.....
# _*_coding: utf-8_*_
import os
from time import perf_counter
from functools import wraps import requests
from scrapy import Selector
"""
-------------------------------------------------
File Name: 妹子图_串行
Description :
Author : demon
date: 06/10/2017
-------------------------------------------------
Change Activity:
06/10/2017:
-------------------------------------------------
"""
__author__ = 'demon' def timer(func):
"""
:param func: 装饰器的函数,记录方法所消耗的时间
:return:
"""
@wraps(func)
def wrapper(*args, **kwargs):
start_time = perf_counter()
result = func(*args, **kwargs)
end_time = perf_counter()
cls_name = func.__name__
fmt = '{cls_name} {args} spend time: {time:.5f}'
print(fmt.format(cls_name=cls_name, args=args, time=end_time - start_time))
return result
return wrapper def get_content_css(url):
req = requests.get(url)
content = req.content.decode('gbk')
selector = Selector(text=content)
return selector def get_page_items(*, start_page_num: int=1, end_page_num: int=2, step: int=1):
items = []
for page_num in range(start_page_num, end_page_num, step):
base_url = 'http://www.meizitu.com/a/{genre}_{page_num}.html'
selector = get_content_css(base_url.format(genre='cute', page_num=page_num))
item_urls = list(set(selector.css('#maincontent a::attr(href)').extract()))
items.extend(url for url in item_urls if url.startswith('http://www.meizitu.com/a/'))
return items def get_images(item):
selector = get_content_css(item)
image_urls = list(set(selector.css('#maincontent p img::attr(src)').extract()))
dir_name = selector.css('#maincontent div.metaRight h2 a::text').extract_first()
'ok' if os.path.exists(dir_name) else os.mkdir(dir_name)
for url in image_urls:
download_image(dir_name, url) @timer
def download_image(dir_name, image_url):
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'}
req = requests.get(image_url, headers=headers)
image = req.content
filename = image_url.rsplit('/', 1)[-1]
save_path = os.path.join(dir_name, filename)
with open(save_path, 'wb') as f:
f.write(image) if __name__ == "__main__":
start = perf_counter()
for item in get_page_items():
get_images(item)
end = perf_counter()
print(format('end', '*^100'))
print('download all images cost time:{:.3f}'.format(end - start))
上面的代码可以保证图片保存到本地,那么基本的代码逻辑没有问题了,保存文件(download_image)也实现了~, 但是 但是这不是我们想要的效果,这玩意很慢的,一个一个并行下来的,要TMD天荒地老呀!
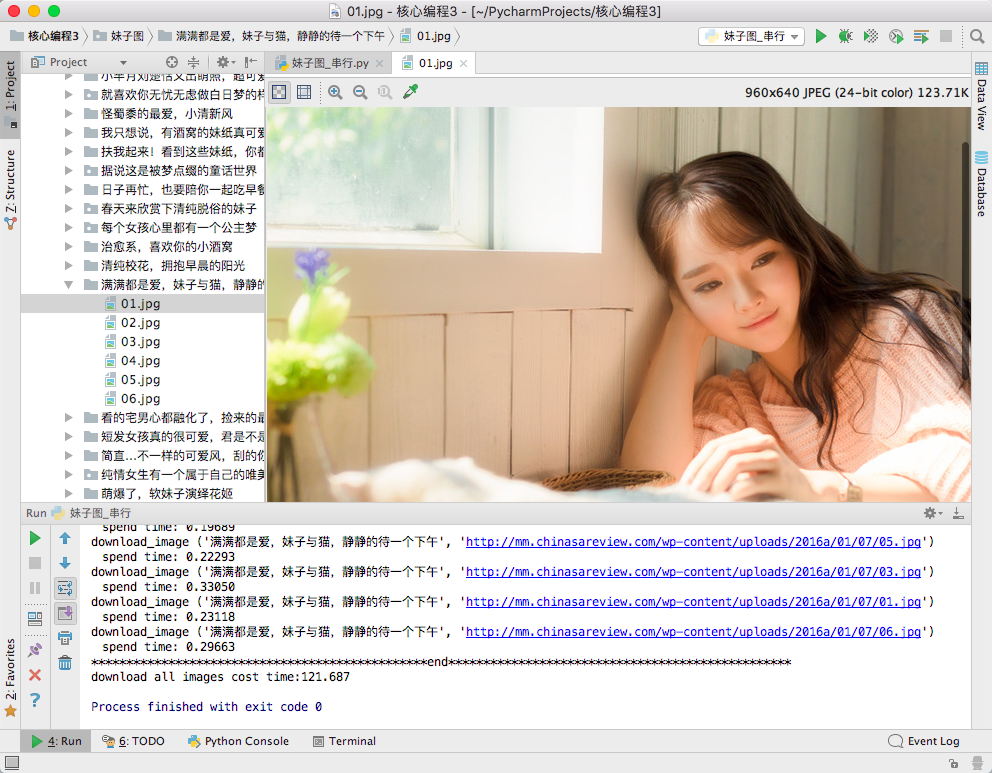
卧槽,不能忍受呀,一个页面就要用121秒的时间,这尼玛的要是10页20页的不得疯了呀!一定要改,改代码,改成协程~,以下是三页的数据才用时190秒呀,提升了不是一点半点呀!
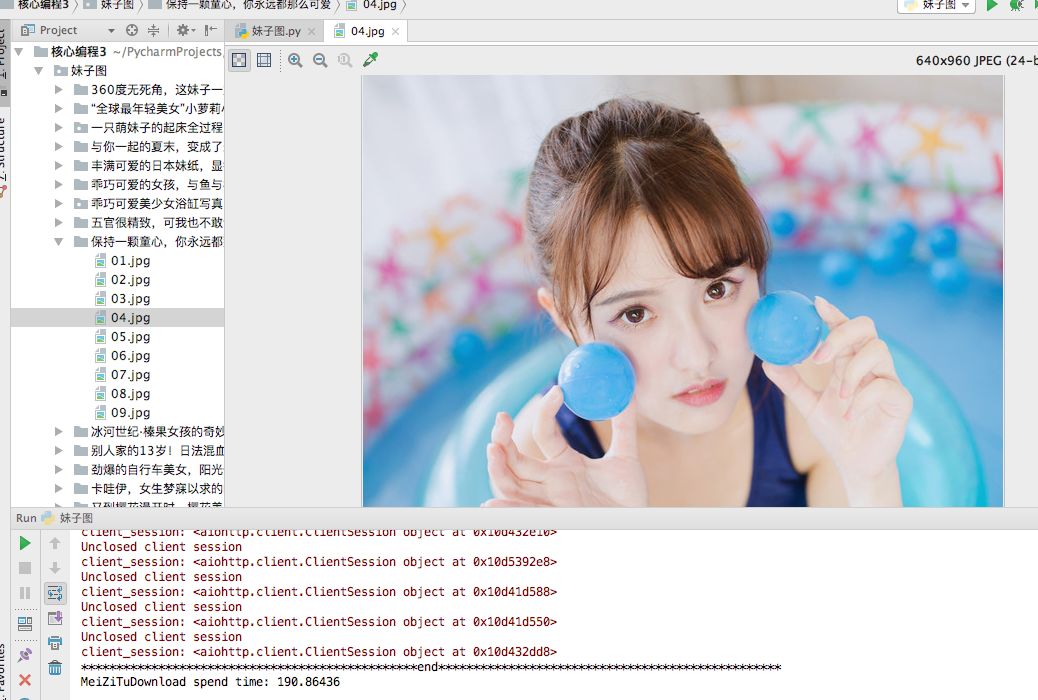
说干就干,改成协程,直接上全部代码吧!因为...我懒得...写了,这篇博客...写了将近五个小时了...卧槽!要疯了~
# _*_coding: utf-8_*_
import os
import asyncio
from functools import wraps
from time import perf_counter import aiohttp
import aiofiles
from scrapy import Selector
"""
-------------------------------------------------
File Name: 妹子图
Description :
Author : demon
date: 06/10/2017
-------------------------------------------------
Change Activity:
06/10/2017:
-------------------------------------------------
"""
__author__ = 'demon' def timer(func):
"""
:param func: 装饰器的函数,记录方法所消耗的时间
:return:
"""
@wraps(func)
def wrapper(*args, **kwargs):
start_time = perf_counter()
result = func(*args, **kwargs)
end_time = perf_counter()
cls_name = func.__name__
print('{cls_name} spend time: {time:.5f}'.format(cls_name=cls_name, time=end_time - start_time))
return result
return wrapper class MeiZiTuDownload:
def __init__(self, *, genre: str='cute', start_page_num: int=1, end_page_num: int=5, step: int=1):
self.base_url = 'http://www.meizitu.com/a/{genre}_{page_num}.html'
self.start_num = start_page_num
self.end_num = end_page_num
self.step = step
self.genre = genre
self.headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'} async def get_html_content(self, url: str):
"""
:param url: 网页的url地址
:return: 网页的html源码
"""
req = await aiohttp.request('GET', url, headers=self.headers)
content = await req.read()
content = content.decode('gbk')
return content async def get_page_item(self, page_num: int):
"""
:param page_num: 获取网页中的每一页中的具体的url地址
:return:
"""
item_url = self.base_url.format(genre=self.genre, page_num=page_num)
content = await self.get_html_content(item_url)
selector = Selector(text=content)
urls = list(set(selector.css('#maincontent a::attr(href)').extract()))
page_items = (url for url in urls if url.startswith('http://www.meizitu.com/a/'))
for item in page_items:
await self.get_item(item) async def get_item(self, item: str):
"""
:param item: 单独的下载页面
:return:
"""
item_content = await self.get_html_content(item)
selector = Selector(text=item_content)
dir_name = selector.css('#maincontent div.metaRight h2 a::text').extract_first()
image_urls = selector.css('#picture p img::attr(src)').extract()
'ok' if os.path.exists(dir_name) else os.mkdir(dir_name)
for image_url in image_urls:
image_name = image_url.rsplit('/', 1)[-1]
save_path = os.path.join(dir_name, image_name)
await self.download_images(save_path, image_url) async def download_images(self, save_path: str, image_url: str):
"""
:param save_path: 保存图片的路径
:param image_url: 图片的下载的url地址
:return:
"""
req = await aiohttp.request('GET', image_url, headers=self.headers)
image = await req.read()
fp = await aiofiles.open(save_path, 'wb')
await fp.write(image) async def __call__(self, page_num: int):
await self.get_page_item(page_num) def __repr__(self):
cls_name = type(self).__name__
return '{cls_name}{args}'.format(cls_name=cls_name, args=(self.genre, self.start_num, self.end_num, self.step)) if __name__ == "__main__":
start = perf_counter()
download = MeiZiTuDownload(genre='cute')
loop = asyncio.get_event_loop()
to_do = [download(num) for num in range(1, 4)]
wait_future = asyncio.wait(to_do)
resp, _ = loop.run_until_complete(wait_future)
loop.close()
end = perf_counter()
func_name = download.__class__.__name__
spend_time = end - start
print(format('end', '*^100'))
print('{func_name} spend time: {time:.5f}'.format(func_name=func_name, time=spend_time))
协程的使用,大家移步到廖大神的哪里学习下吧~~~,我就不讲了...不然我要疯了...我要看会电影,缓一会。
Python协程爬取妹子图(内有福利,你懂得~)的更多相关文章
- python协程爬取某网站的老赖数据
import re import json import aiohttp import asyncio import time import pymysql from asyncio.locks im ...
- Python 2.7_爬取妹子图网站单页测试图片_20170114
1.url= http://www.mzitu.com/74100/x,2为1到23的值 2.用到模块 os 创建文件目录; re模块正则匹配目录名 图片下载地址; time模块 限制下载时间;req ...
- Python3爬虫系列:理论+实验+爬取妹子图实战
Github: https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎star 爬虫系列: (1) 理论 Python3爬虫系列01 ...
- python爬取妹子图全站全部图片-可自行添加-线程-进程爬取,图片去重
from bs4 import BeautifulSoupimport sys,os,requests,pymongo,timefrom lxml import etreedef get_fenlei ...
- Python网络爬虫 | Scrapy爬取妹子图网站全站照片
根据现有的知识,写了一个下载妹子图(meizitu.com)Scrapy脚本,把全站两万多张照片下载到了本地. 网站的分析 网页的网址分析 打开网站,发现网页的网址都是以 http://www.mei ...
- python+selenium+bs4爬取百度文库内文字 && selenium 元素可以定位到,但是无法点击问题 && pycharm多行缩进、左移
先说一下可能用到的一些python知识 一.python中使用的是unicode编码, 而日常文本使用各类编码如:gbk utf-8 等等所以使用python进行文字读写操作时候经常会出现各种错误, ...
- 使用requests+BeaBeautiful Soup爬取妹子图图片
1. Requests:让 HTTP 服务人类 Requests 继承了urllib2的所有特性.Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定 ...
- Python 2.7和3.6爬取妹子图网站单页测试图片
1.url= http://www.mzitu.com/74100/x,2为1到23的值 2.用到模块 os 创建文件目录; re模块正则匹配目录名 图片下载地址; time模块 限制下载时间;req ...
- Python 爬取 妹子图(技术是无罪的)
... #!/usr/bin/env python import urllib.request from bs4 import BeautifulSoup def crawl(url): header ...
随机推荐
- TC358743XBG:HDMI转MIPI CSI参考设计
TC358743XBG参考设计电路图如下, 功能HDMI转MIPI CSI ,通信方式:IIC,分辨率1920*1080,封装形式BGA64.
- 读取Execl表 导入数据库
不知不觉博客园园林都两年多了,我是今年毕业的应届生,最近公司项目需要改动,很多的数据需要导入,很多的实体类需要些.考虑到这些问题自己写了两个winform版的小工具,一个是读取Execl数据导入数据库 ...
- DES加密:8051实现(C语言) & FPGA实现(VHDL+NIOS II)
本文将利用C语言和VHDL语言分别实现DES加密,并在8051和FPGA上测试. 终于有机会阅读<深入浅出密码学一书>,趁此机会深入研究了DES加密的思想与实现.本文将分为两部分,第一部分 ...
- Cousera课程Learning How to Learn学习报告
花了三天完成了Cousera上的Learning how to learn的课程,由于未完成批阅他人作业,所以分不是很高,但是老师讲的课程非常的好,值得一听: 课程的笔记: 我们的一生是一个不断接触和 ...
- Python中os和shutil模块实用方法集锦
Python中os和shutil模块实用方法集锦 类型:转载 时间:2014-05-13 这篇文章主要介绍了Python中os和shutil模块实用方法集锦,需要的朋友可以参考下 复制代码代码如下: ...
- 【★】Web精彩实战之
JS精彩实战之<智能迷宫> ---宝贵编程经验分享会--- hello大家好,这里是Web云课堂,之前的一年里我们经历了Html和CSS的系统攻城,此时的你们已经是做静态(动静结 ...
- 201521123084 《Java程序设计》第11周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多线程相关内容. 2. 书面作业 本次PTA作业题集多线程 1. 互斥访问与同步访问 完成题集4-4(互斥访问)与4-5(同步访问) ...
- 第二次项目冲刺(Beta阶段)5.21
1.提供当天站立式会议照片一张 会议内容: ①检查前一天的任务情况,做出自我反省. ②制定新一轮的任务计划. 2.每个人的工作 (1)工作安排 队员 今日进展 明日安排 王婧 #53实现多对多查重 # ...
- 团队作业10——项目复审与事后分析(Beta版本)
油炸咸鱼24点APP 团队作业10--事后诸葛亮分析; 团队作业10--Beta阶段项目复审;
- spring 注入使用注解(不用xml)
(一):导入spring4的jar包 (二):在xml中配置扫描的包 <context:component-scan base-package="entity">< ...