深度学习网络层之 Batch Normalization
Batch Normalization
Ioffe 和 Szegedy 在2015年《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》论文中提出此方法来减缓网络参数初始化的难处.
Batch Norm优点
- 减轻过拟合
- 改善梯度传播(权重不会过高或过低)
- 容许较高的学习率,能够提高训练速度。
- 减轻对初始化权重的强依赖
- 作为一种正则化的方式,在某种程度上减少对dropout的使用。
Batch Norm层摆放位置
在激活层(如 ReLU )之前还是之后,没有一个统一的定论。在原论文中提出在非线性层之前(CONV_BN_RELU),而在实际编程中很多人可能放在激活层之后(BN_CONV_RELU)。
Batch Norm原理
内部协转移(Internal Covariate Shift):由于训练时网络参数的改变导致的网络层输出结果分布的不同。这正是导致网络训练困难的原因。
对输如进行白化(whiten:0均值,单位标准差,并且decorrelate去相关)已被证明能够加速收敛速度,参考Efficient backprop. (LeCun et al.1998b)和 A convergence anal-ysis of log-linear training.(Wiesler & Ney,2011)。由于白化中去除相关性类似PCA等操作,在特征维度较高时计算复杂度较高,因此提出了两种简化方式:1)对特征的每个维度进行归一化,忽略白化中的去除相关性 ;2)在每个mini-batch中计算均值和方差来替代整体训练集的计算.
batch normalization中即使不对每层的输入进行去相关,也能加速收敛。通俗的理解是在网络的每一层的输入都做了归一化预处理。
unit gaussian activations:
\[
\hat x^{(k)}=\frac{x^{(k)}-E[x^{(k)}]}{\sqrt{\operatorname{Var[x^{(k)}]}}}
\]
公式中k为通道channel数。
\[
\text{Batch Normalizing Transform} \\
\begin{align}
u &= \frac{1}{m}\sum_{i=1}^m x_i &\text{//mini-batch mean} \\
var &= \frac{1}{m} \sum_{i=1}^m (x_i - u)^2 &\text{//mini-batch variance} \\
\hat{x_i} &= \frac{x_i - u}{\sqrt{var + \epsilon}} &\text{//normalize} \\
y_i &= \gamma \hat{x_i} + \beta &\text{//scale and shift}
\end{align}
\]
其中ϵ是为了防止方差为0导致数值计算的不稳定而添加的一个小数,如1e−6。可以看做是在原网络中插入了一个
注意,在对每层的输入进行正则化之后会改变特征的表示,如对sigmoid输入进行正则化后将数据限制在进行线性的区域,这样改变了原始特征的分布。如下图所示:
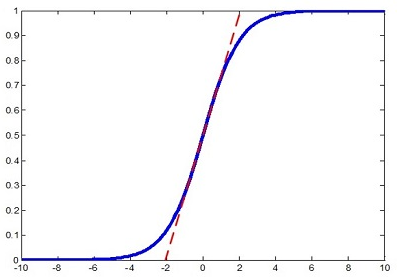
论文中引入了两个可学习的参数\(\gamma , \beta\)来还原原始特征分布。这两个参数学习的目标即为\(\gamma=\sqrt{\text{Var}[x]}、 \beta=\mathbb E[x]\).原来的分布方差和均值由前层的各种参数weight耦合控制,而现在仅由\(\gamma , \beta\)控制,这样在保留BN层足够的学习能力的同时,我们使得其学习更加容易。因此,加速收敛并非由于计算量减少(反而由于增加了参数增加了计算量)。梯度计算如下:

在训练时计算mini-batch的均值和标准差并进行反向传播训练,而测试时并没有batch的概念,训练完毕后需要提供固定的\(\bar\mu,\bar\sigma\)供测试时使用。论文中对所有的mini-batch的\(\mu_\mathcal B,\sigma^2_\mathcal B\)取了均值(m是mini-batch的大小,\(\bar\sigma^2\)采用的是无偏估计):
\[
\begin{align}
\bar\mu &=\mathbb E[\mu_\mathcal B] \\
\bar\sigma^2 &={m\over m-1}\mathbb E[\sigma^2_\mathcal B]
\end{align}
\]
测试阶段,同样要进行归一化和缩放平移操作,唯一不同之处是不计算均值和方差,而使用训练阶段记录下来的\(\bar\mu,\bar\sigma\)。
\[
\begin{align}
y&=γ({x-\bar\mu\over\sqrt{\bar\sigma^2+ϵ}})+ β \\
&={γ\over\sqrt{\bar\sigma^2+ϵ}}\cdot x+(β-{γ\bar\mu\over\sqrt{\bar\sigma^2+ϵ}})
\end{align}
\]
caffe框架中该层全局均值和方差的实现
与论文计算 global 均值和 global 方差的方式不同之处在于,Caffe 中的 global 均值和 global 方差采用的是滑动衰减平均的更新方式,设滑动衰减系数moving_average_fraction 为 λ,当前的 mini-batch 的均值和方差分别为 \(\mu_B,\sigma_B^2\):
\[
\mu_{new} = \lambda \mu_{old} + \mu_B \\
\sigma_{new}^2 =
\begin{cases}
\lambda \sigma_{old}^2 + \frac{m - 1}{m} \sigma_B^2 & m > 1 \\
\lambda \sigma_{old}^2 & m = 1
\end{cases}
\]
Batch Norm在卷积层的应用
前边提到的mini-batch说的是神经元的个数,而卷积层中是堆叠的多个特征图,共享卷积参数。如果每个神经元使用一对\(\gamma , \beta\)参数,那么不仅多,而且冗余。可以在channel方向上取m个特征图作为mini-batch,对每一个特征图计算一对参数。这样减少了参数的数量。
应用举例-VGG16
为VGG16结构模型添加Batch Normalization。
- 重新完全训练.如果想将BN添加到卷基层,通常要重新训练整个模型,大概花费一周时间。
- finetune.只将BN添加到最后的几层全连接层,这样可以在训练好的VGG16模型上进行微调。采用ImageNet的全部或部分数据按batch计算均值和方差作为BN的初始\(\beta,\gamma\)参数。
深度学习网络层之 Batch Normalization的更多相关文章
- 深度解析Droupout与Batch Normalization
Droupout与Batch Normalization都是深度学习常用且基础的训练技巧了.本文将从理论和实践两个角度分布其特点和细节. Droupout 2012年,Hinton在其论文中提出Dro ...
- 深度学习中优化【Normalization】
深度学习中优化操作: dropout l1, l2正则化 momentum normalization 1.为什么Normalization? 深度神经网络模型的训练为什么会很困难?其中一个重 ...
- 深度学习中的batch、epoch、iteration的含义
深度学习的优化算法,说白了就是梯度下降.每次的参数更新有两种方式. 第一种,遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度.这种方法每更新一次参数都要把数据集里的所有样本都看一遍, ...
- 深度学习中的batch的大小对学习效果的影响
Batch_size参数的作用:决定了下降的方向 极端一: batch_size为全数据集(Full Batch Learning): 好处: 1.由全数据集确定的方向能够更好地代表样本总体,从而更准 ...
- 深度学习网络层之 Pooling
pooling 是仿照人的视觉系统进行降维(降采样),用更高层的抽象表示图像特征,这一部分内容从Hubel&wiesel视觉神经研究到Fukushima提出,再到LeCun的LeNet5首次采 ...
- 深度学习(二十九)Batch Normalization 学习笔记
Batch Normalization 学习笔记 原文地址:http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce 一.背景意义 ...
- 【深度学习】批归一化(Batch Normalization)
BN是由Google于2015年提出,这是一个深度神经网络训练的技巧,它不仅可以加快了模型的收敛速度,而且更重要的是在一定程度缓解了深层网络中"梯度弥散"的问题,从而使得训练深层网 ...
- caffe︱深度学习参数调优杂记+caffe训练时的问题+dropout/batch Normalization
一.深度学习中常用的调节参数 本节为笔者上课笔记(CDA深度学习实战课程第一期) 1.学习率 步长的选择:你走的距离长短,越短当然不会错过,但是耗时间.步长的选择比较麻烦.步长越小,越容易得到局部最优 ...
- 【深度学习】深入理解Batch Normalization批标准化
这几天面试经常被问到BN层的原理,虽然回答上来了,但还是感觉答得不是很好,今天仔细研究了一下Batch Normalization的原理,以下为参考网上几篇文章总结得出. Batch Normaliz ...
随机推荐
- 文本排序的王者:玩透sort命令
本文目录: 1.1 选项说明 1.2 sort示例 1.3 深入研究sort sort是排序工具,它完美贯彻了Unix哲学:"只做一件事,并做到完美".它的排序功能极强.极完整,只 ...
- React渲染问题研究以及Immutable的应用
写在前面 这里主要介绍自己在React开发中的一些总结,关于react的渲染问题的一点研究. 另外本人一直希望在React项目中尝试使用,因此在之前已经介绍过immutable的API,可以参看这里I ...
- 新的表格展示利器 Bootstrap Table Ⅱ
上一篇文章介绍了Bootstrap Table的基本知识点和应用,本文针对上一篇文章中未解决的文件导出问题进行分析,同时介绍BootStrap Table的扩展功能,当行表格数据修改. 1.B ...
- linux下操作mysql
有关mysql数据库方面的操作,必须首先登录到mysql中. 开启MySQL服务后,使用MySQL命令可以登录.一般使用mysql -uroot -p即可.如果数据库不是本机,则需要加参数,常用参数如 ...
- Java环境的搭建
一.JDK的下载 JDK又称Java SE,可以从Oracle公司的官网上https://www.oracle.com/index.html下载. 1.打开Oracle官网.将光标移到[Menu]-[ ...
- Windows noinstall zip 安装MySQL。
听完数据库老师的课,想在Windows下通过命令行的方法安装MySQL5.7,于是开了这个坑,终于把这个坑填上了. 第一步:下载MySQL 的noinstall zip ,点击该链接下载,或者复制链接 ...
- linq 起源
在说LINQ之前必须先说说几个重要的C#语言特性 一:与LINQ有关的语言特性 1.隐式类型 (1)源起 在隐式类型出现之前, 我们在声明一个变量的时候, 总是要为一个变量指定他的类型 甚至在fore ...
- 猎八哥FLY——将数据库中的某一表中的某一列或者多列添加到另一张表的某一列中
成绩表的字段:xueshenghao,yu,shu,yy均为int类型.新标与成绩表字段相同,不同的是成绩表中拥有数据,而新表中没有(是一张空表,一条数据都没有).需求:将成绩表中每一个人的yu,sh ...
- MySQLzip archive版本(5.7.19)安装教程
1. 从官网下载zip archive版本http://dev.mysql.com/downloads/mysql/ 2. 解压缩至相应目录,并配置环境变量(将*\bin添加进path中): 3. ...
- go golang 笔试题 面试题 笔试 面试
go golang 笔试题 面试题 笔试 面试 发现go的笔试题目和面试题目还都是比较少的,于是乎就打算最近总结一下.虽然都不难,但是如果没有准备猛地遇到了还是挺容易踩坑的. 就是几个简单的笔试题目, ...