【机器学习】Apriori算法——原理及代码实现(Python版)
Apriopri算法
Apriori算法在数据挖掘中应用较为广泛,常用来挖掘属性与结果之间的相关程度。对于这种寻找数据内部关联关系的做法,我们称之为:关联分析或者关联规则学习。而Apriori算法就是其中非常著名的算法之一。关联分析,主要是通过算法在大规模数据集中寻找频繁项集和关联规则。
- 频繁项集:经常出现在一起的物品或者属性的集合
- 关联规则:物品或者属性之间存在的内在关系(统计学上的关系)
所以,我们常见的Apriori算法中的主要包含两大模块内容,一块是寻找频繁项集的函数模块,一块是探索关联规则的函数模块。
支持度与置信度
支持度与置信度是实现Apriori算法无法回避的两个概念,支持度用来寻找频繁项集,而置信度用来确定关联规则。具体用处,在后续原理章节,进行介绍。
- 支持度:频繁项集在全体数据样本中所占的比例
support(X, Y) = P(X, Y) = \frac{number(X, Y)}{number(all\ sample)}support(X,Y)=P(X,Y)=number(all sample)number(X,Y) - 置信度:体现为一个数据出现后,另一个数据出现的概率,或者说数据的条件概率
confidence(X \Rightarrow Y) = P(Y | X) = \frac{P(X,Y)}{P(X)} =\frac{number(X,Y)}{number(X)}confidence(X⇒Y)=P(Y∣X)=P(X)P(X,Y)=number(X)number(X,Y)
Apriori算法原理
以商品购买为例,假设一家商店,出售四种商品,分别为商品0,商品1,商品2,商品3。我们希望通过挖掘买家购买商品的订单数据,来进行商品之间的组合促销或者说是摆放位置。那么商品之间可能的组合如下图所示: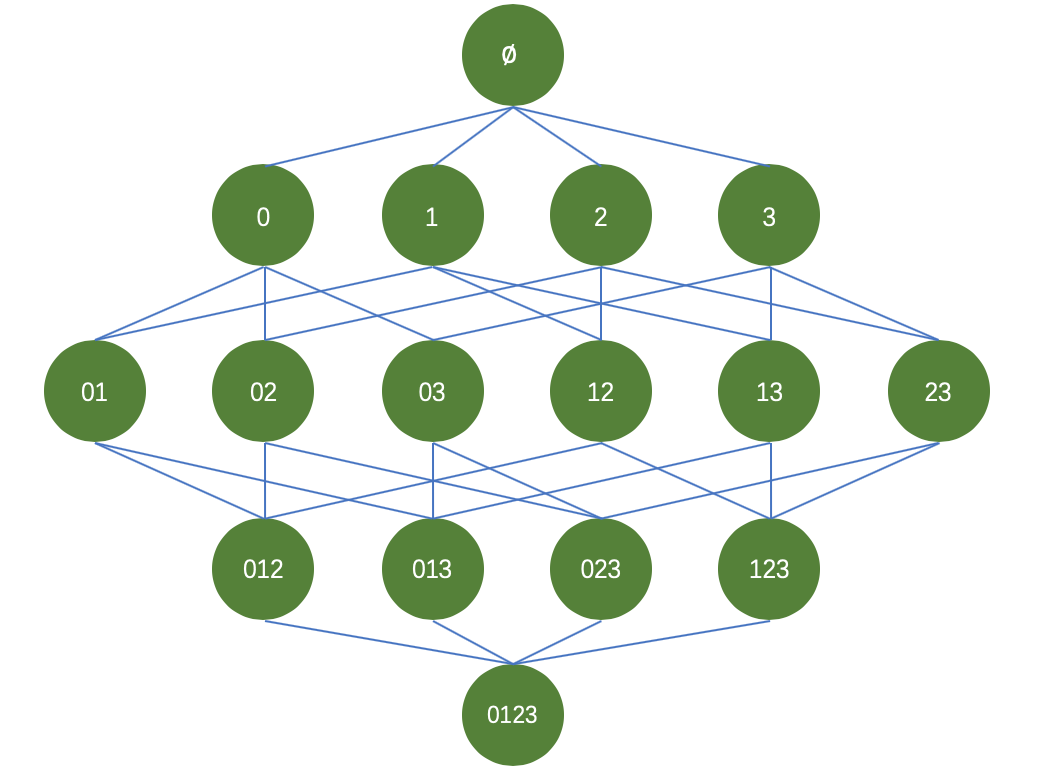
针对这些商品,我们的目标是:从大量购买数据中找到经常一起被购买的商品。在寻找频繁项集(即经常出现的商品组合)的过程中,我们采用支持度(support)来过滤商品组合,即频繁项集。针对四中商品,我们要在整体数据集上进行15次轮询,才可以统计出每个频繁项集的支持度。试想,如果数据量较大,且商品种类不止四中的情况下,难道依旧采用逐个轮询的方式进行统计吗?那么带来的运算量也是巨大的,并且随着商品种类的增加,频繁项集的组合种类也将变为2^N-12N−1种,随着种类的增加,那么带来的运算代价呈现指数型增加。为了解决这个问题,研究人员便在Apriori原理的基础上设计了Apriori算法。
Apriori原理如下:如果某个项集是频繁的,那么它的所有子集也是频繁的。反过来,如果一个项集是非频繁集,那么它的所有超集(包含该非频繁集的父集)也是非频繁的。
于是,可以将上图进行适当的优化,如下所示: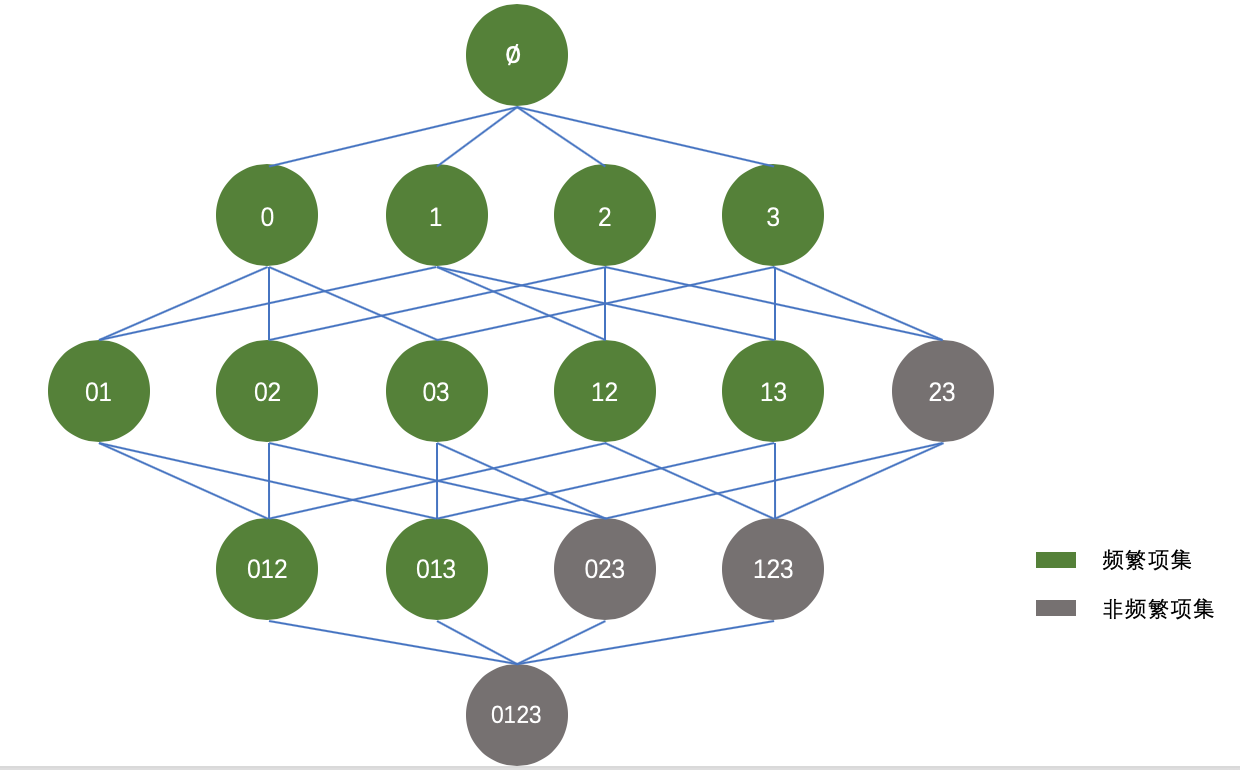
根据Apriori原理,我们知道阴影项集{2,3}是非频繁的,那么它的所有超集,也都是非频繁的,如上图灰色所示。在实际计算过程中,一旦计算出{2,3}的支持度不满足最小支持度,那么就不需要再计算{0,2,3}、{1,2,3}和{0,1,2,3}的支持度,因为它们也都是非频繁集。
Apriori算法实现
上面的部分也已经说了,Apriori算法主要有两部分组成:
- 发现频繁项集
- 找出关联规则
本部分将从两个方面来实现代码,具体如下所示:
发现频繁项集
def createC1(dataSet):
C1=[]
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
return list(map(frozenset,C1))
def scanD(D,CK,minSupport):
ssCnt = {}
for tid in D:
for can in CK:
if can.issubset(tid):
if not can in ssCnt:ssCnt[can]=1
else:ssCnt[can]+=1
numItems = float(len(D))
retList = []
supportData={}
for key in ssCnt:
support = ssCnt[key]/numItems
if support>=minSupport:
retList.insert(0,key)
supportData[key]=support
return retList,supportData
电动叉车
#频繁项集两两组合
def aprioriGen(Lk,k):
retList=[]
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1,lenLk):
L1=list(Lk[i])[:k-2];L2=list(Lk[j])[:k-2]
L1.sort();L2.sort()
if L1==L2:
retList.append(Lk[i]|Lk[j])
return retList
def apriori(dataSet,minSupport=0.5):
C1=createC1(dataSet)
D=list(map(set,dataSet))
L1,supportData =scanD(D,C1,minSupport)
L=[L1]
k=2
while(len(L[k-2])>0):
CK = aprioriGen(L[k-2],k)
Lk,supK = scanD(D,CK,minSupport)
supportData.update(supK)
L.append(Lk)
k+=1
return L,supportData
找出关联规则
#规则计算的主函数
def generateRules(L,supportData,minConf=0.7):
bigRuleList = []
for i in range(1,len(L)):
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if(i>1):
rulesFromConseq(freqSet,H1,supportData,bigRuleList,minConf)
else:
calcConf(freqSet,H1,supportData,bigRuleList,minConf)
return bigRuleList
def calcConf(freqSet,H,supportData,brl,minConf=0.7):
prunedH=[]
for conseq in H:
conf = supportData[freqSet]/supportData[freqSet-conseq]
if conf>=minConf:
print (freqSet-conseq,'--->',conseq,'conf:',conf)
brl.append((freqSet-conseq,conseq,conf))
prunedH.append(conseq)
return prunedH
def rulesFromConseq(freqSet,H,supportData,brl,minConf=0.7):
m = len(H[0])
if (len(freqSet)>(m+1)):
Hmp1 = aprioriGen(H,m+1)
Hmp1 = calcConf(freqSet,Hmp1,supportData,brl,minConf)
if(len(Hmp1)>1):
rulesFromConseq(freqSet,Hmp1,supportData,brl,minConf)
整合整个代码如下所示:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 30 16:38:01 2018
@author: lxh
"""
def loadDataSet():
return [[1,3,4],[2,3,5],[1,2,3,5],[2,5]]
def createC1(dataSet):
C1=[]
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
return list(map(frozenset,C1))
def scanD(D,CK,minSupport):
ssCnt = {}
for tid in D:
for can in CK:
if can.issubset(tid):
if not can in ssCnt:ssCnt[can]=1
else:ssCnt[can]+=1
numItems = float(len(D))
retList = []
supportData={}
for key in ssCnt:
support = ssCnt[key]/numItems
if support>=minSupport:
retList.insert(0,key)
supportData[key]=support
return retList,supportData
#频繁项集两两组合
def aprioriGen(Lk,k):
retList=[]
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1,lenLk):
L1=list(Lk[i])[:k-2];L2=list(Lk[j])[:k-2]
L1.sort();L2.sort()
if L1==L2:
retList.append(Lk[i]|Lk[j])
return retList
def apriori(dataSet,minSupport=0.5):
C1=createC1(dataSet)
D=list(map(set,dataSet))
L1,supportData =scanD(D,C1,minSupport)
L=[L1]
k=2
while(len(L[k-2])>0):
CK = aprioriGen(L[k-2],k)
Lk,supK = scanD(D,CK,minSupport)
supportData.update(supK)
L.append(Lk)
k+=1
return L,supportData
#规则计算的主函数
def generateRules(L,supportData,minConf=0.7):
bigRuleList = []
for i in range(1,len(L)):
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if(i>1):
rulesFromConseq(freqSet,H1,supportData,bigRuleList,minConf)
else:
calcConf(freqSet,H1,supportData,bigRuleList,minConf)
return bigRuleList
def calcConf(freqSet,H,supportData,brl,minConf=0.7):
prunedH=[]
for conseq in H:
conf = supportData[freqSet]/supportData[freqSet-conseq]
if conf>=minConf:
print (freqSet-conseq,'--->',conseq,'conf:',conf)
brl.append((freqSet-conseq,conseq,conf))
prunedH.append(conseq)
return prunedH
def rulesFromConseq(freqSet,H,supportData,brl,minConf=0.7):
m = len(H[0])
if (len(freqSet)>(m+1)):
Hmp1 = aprioriGen(H,m+1)
Hmp1 = calcConf(freqSet,Hmp1,supportData,brl,minConf)
if(len(Hmp1)>1):
rulesFromConseq(freqSet,Hmp1,supportData,brl,minConf)
if __name__=='__main__':
dataSet=loadDataSet()
L,supportData=apriori(dataSet)
rules = generateRules(L,supportData,minConf=0.7)
输出结果如下所示:
【机器学习】Apriori算法——原理及代码实现(Python版)的更多相关文章
- 【机器学习】算法原理详细推导与实现(六):k-means算法
[机器学习]算法原理详细推导与实现(六):k-means算法 之前几个章节都是介绍有监督学习,这个章解介绍无监督学习,这是一个被称为k-means的聚类算法,也叫做k均值聚类算法. 聚类算法 在讲监督 ...
- AC-BM算法原理与代码实现(模式匹配)
AC-BM算法原理与代码实现(模式匹配) AC-BM算法将待匹配的字符串集合转换为一个类似于Aho-Corasick算法的树状有限状态自动机,但构建时不是基于字符串的后缀而是前缀.匹配 时,采取自后向 ...
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- 机器学习之KNN原理与代码实现
KNN原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9670187.html 1. KNN原理 K ...
- 机器学习之AdaBoost原理与代码实现
AdaBoost原理与代码实现 本文系作者原创,转载请注明出处: https://www.cnblogs.com/further-further-further/p/9642899.html 基本思路 ...
- stacking算法原理及代码
stacking算法原理 1:对于Model1,将训练集D分为k份,对于每一份,用剩余数据集训练模型,然后预测出这一份的结果 2:重复上面步骤,直到每一份都预测出来.得到次级模型的训练集 3:得到k份 ...
- 机器学习 KNN算法原理
K近邻(K-nearst neighbors,KNN)是一种基本的机器学习算法,所谓k近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表.比如:判断一个人的人品,只需要观察 ...
- Apriori算法原理总结
Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策.比如在常见的超市购物数据集,或者电商的网购数据集中,如果我们找到了 ...
- [机器学习] Apriori算法
适用场合 Apriori算法包含两部分内容:1,发现频繁项集 2,挖掘关联规则. 通俗地解释一下,就是这个意思:1.发现哪些项目常常同时出现 2.挖掘这些常常出现的项目是否存在“如果A那么B”的关系. ...
随机推荐
- SDN第五次上机作业--基于组表的简单负载均衡
0.作业链接 http://www.cnblogs.com/easteast/p/8125383.html 1.实验目的 1.搭建如下拓扑并连接控制器 2.下发相关流表和组表实现负载均衡 3.抓包分析 ...
- Oracle Database(rdbms) 12.2 安装组件
1. 工具用法 su - oracle $ $(orabasehome)/perl/bin/perl $ORACLE_HOME/rdbms/admin/catcon.pl Usage: catcon ...
- 关于 X509Certificate2 找到文件路径的问题
由于微信退款功能需要用到证书,当调用 X509Certificate2 的时候,会提示找不到文件而报错. X509Certificate2 cert = new X509Certificate2(文件 ...
- OpenCV——LBP(Local Binary Patterns)特征检测
#include <opencv2/opencv.hpp> #include <iostream> #include "math.h" using name ...
- OpenCV——ROI截取、线性混合、通道分离、合并、亮度对比度调整
#include <opencv2/opencv.hpp> #include <iostream> using namespace cv; using namespace st ...
- Const vs. Readonly
Const 被const修饰的变量不能为静态,因为const实际隐式上已经是静态变量. const变量在声明时就必须进行初始化,否则会有编译错误. const变量的赋值是发生在编译期间 Readonl ...
- linux shell中'',""和``的区别
今天学习一个bash脚本,看到有一条:bin=`dirname "$0"` (dirname filename是输出该文件所在的目录,$0是该bash文件的文件名,在bash中一般 ...
- 运放参数的详细解释和分析-part3,输入失调电压Vos及温漂
运放参数的详细解释和分析-part3,输入失调电压Vos及温漂 在运放的应用中,不可避免的会碰到运放的输入失调电压Vos问题,尤其对直流信号进行放大时,由于输入失调电压Vos的存在,放大电路的输出端总 ...
- LIN、CAN、FlexRay、MOST,三分钟搞明白四大汽车总线
LIN.CAN.FlexRay.MOST,三分钟搞明白四大汽车总线 2016-09-21 13:09 汽车中的电子部件越来越多,光是ECU就有几十个,这么多的电子单元都要进行信息交互.传统的点对点通信 ...
- 【小程序】本地资源图片无法通过 WXSS 获取
小程序升级更改: 本地资源图片无法通过 WXSS 获取,可以使用网络图片,或者 base64,或者使用<image/>标签.请参考文档: https://mp.weixin.qq.com/ ...