top k问题
1.top k问题
在海量数据处理中,经常会遇到的一类问题:在海量数据中找出出现频率最高的前k个数,或者从海量数据中找出最大的前k个数,这类问题通常被称为top K问题。例如,在搜索引擎中,统计搜索最热门的10个查询词;在歌曲库中统计下载最高的前10首歌等
2.实例
2.1从N个无序数中寻找Top-k个最小数
问题分析
针对海量数据的top k问题,这里实现了一种时间复杂度为O(Nlogk)的有效算法:初始时一次性从文件中读取k个数据,并建立一个有k个数的最大堆,代表目前选出的最小的k个数。然后从文件中一个一个的读取剩余数据,如果读取的数据比堆顶元素小,则把堆顶元素替换成当前的数,然后从堆顶向下重新进行堆调整;否则不进行任何操作,继续读取下一个数据。直到文件中的所有数据读取完毕,堆中的k个数就是海量数据中最小的k个数(如果是找最大的k个数,则使用最小堆)
对于从海量数据(N)中找出TOP K,这种算法仅需一次性将k个数装入内存,其余数据从文件一个一个读即可,不用将海量数据全都一次性读进内存,所以它是针对海量数据TOP K问题最为有效的算法
代码实现
#define N 1000000000 //10亿
#define K 10000 //1万 void adjustHeap(vector<int>& nums, int node, int last)//调整完全二叉树,使得以node节点为根的树成为大顶堆
{
int temp = nums[node];
for (int i = * node + ; i <= last; i = * i + )//沿较大的儿子向下进行调整
{
if (i <= last - && nums[i] < nums[i + ])//比较左儿子和右儿子的大小,让i指向更大的那个儿子
++i;
if (temp < nums[i])//此处仅仅是赋值,不是交换
{
nums[node] = nums[i];
node = i;
}
}
nums[node] = temp;
} int main()
{
vector<int> nums;
fstream in("file");
char buf[] = {};
if (!in.is_open())
{
cout << "Open file failed!\n";
exit();
}
for (int i = ; i < K; ++i)
{
if (!in.eof())
{
in.getline(buf, );
nums.push_back(atoi(buf));
}
}
for (int i = nums.size() / - ; i >= ; --i)//构建一个大顶堆:遍历所有的分支节点,从最后一个分支节点开始往前遍历
adjustHeap(nums, i, nums.size() - );
while (!in.eof())//读取剩下的数据
{
in.getline(buf, );
int temp = atoi(buf);
if (temp < nums[])//读取的数据比最大堆堆顶元素小
{
nums[] = temp;
adjustHeap(nums, , nums.size() - );
}
}
in.close(); return ;
}
非海量数据
对于非海量数据的情况,还有一种时间复杂度仅为O(N)的经典算法 ——BFPRT算法,受到快速排序的启发,通过修改快速排序中主元的选取方法可以降低快速排序在最坏情况下的时间复杂度,BFPRT算法解决了这样一个问题:在时间复杂度O(N)内,从无序的数组中找到第k小的数。显而易见的是,如果我们找到了第k小的数,那么Top-k个最小数,就在这个数的左边还有它自己
BFPRT算法步骤
1)选取主元:
1.1)将n个元素划分为⌊n/5⌋(向下取整)个组,每组5个元素,若最后一组不够5个元素,则将最后剩下的元素归为一组
1.2)使用直接插入排序找到每一组的中位数,如果最后一组元素个数为偶数,规定找下中位数
1.3)对于(1.2)中找到的所有中位数,再求出它们的中位数,作为主元
2)以1.3种选取的主元为分界点,把小于主元的放在左边,大于主元的放在右边
3)判断主元的位置index与k的大小,有选择的对左边或右边递归:
- 如果 index+1=k,则主元就是第k小的数
- 如果 index+1>k,则去左边递归找第k小的数
- 如果 index+1<k,则去右边递归找第 k-(index+1) 小的数
2.2有一千万条查询串,不重复的不超过三百万,统计最热门的10条查询串(内存1G. 字符串长 0-255)
不重复的三百万条字符串的所占最大空间为:256x300x104/1024/1024/1024=0.715G,建立一个map一个一个读取一千万条查询串,统计出现次数,最后将存下三百万条不重复的串和对应的出现次数,此时再从map里取10条查询串以出现次数建立一个大小为10的最小堆,再遍历map中剩下的查询串,依次与最小堆堆顶元素的出现次数作比较,若次数大于堆顶元素,则把堆顶元素替换成当前的串,然后从堆顶向下重新进行堆调整;否则不进行任何操作,继续读取下一个查询串,直到文件中的所有数据读取完毕,堆中的10条串就是最热门的10条查询串,时间复杂度 O(Nlog10)
2.3给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
方案1:
可以估计每个文件的大小约为50x108x64/1000/1000/1000=320G(1G约等于10亿字节),远远大于内存限制的4G。所以不可能将其完全加载到内存中处理,考虑采取分治法。
遍历文件a,对每个url求取哈希值再对1000取余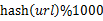 ,然后根据所取得的值(0~999)将url分别存储到1000个小文件(记为
,然后根据所取得的值(0~999)将url分别存储到1000个小文件(记为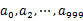 )中。这样每个小文件的大约为320M。遍历文件b,采取和a相同的哈希算法将url分别存储到1000各小文件(记为
)中。这样每个小文件的大约为320M。遍历文件b,采取和a相同的哈希算法将url分别存储到1000各小文件(记为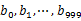 )。这样处理后,所有可能相同的url都在对应的小文件(
)。这样处理后,所有可能相同的url都在对应的小文件(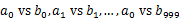 )中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
求每对小文件中相同的url时,可以把其中一个小文件的url存储到set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的set中,如果是,那么就是共同的url,存到文件里面,上述过程重复1000遍即可。
方案2:
如果允许有一定的错误率,可以使用Bloom Filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。
2.4. 有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序
方案1:
若内存不够存储所有不重复的query,则按顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为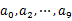 )中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的),相同query进入了同一个小文件。
)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的),相同query进入了同一个小文件。
找一台内存在2G左右的机器,依次对 用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件(记为
用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件(记为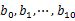 )。
)。
 这10个文件进行
这10个文件进行方案2:
一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query出现的次数,然后按出现次数做快速/堆/归并排序就可以了。
方案3:
与方案1类似,但在做完hash,分成多个文件后,可以交给多个文件来处理,采用分布式的架构来处理(比如MapReduce),最后再进行合并。
2.3有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词
方案1:
顺序读文件中,对于每个词x,取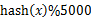 ,然后按照该值存到5000个小文件(记为
,然后按照该值存到5000个小文件(记为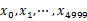 )中,相同的词进入同一个文件。这样每个文件大概是200k左右。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,知道分解得到的小文件的大小都不超过1M。对每个小文件,采用trie树或hash_map统计每个文件中出现的词以及相应的频率,再用容量为100的最小堆并取出出现频率最大的100个词,并把100词及相应的频率存入文件,这样又得到了5000个文件。最后用容量为100的最小堆,依次遍历每个文件,获得最终频数最高的100个词。
)中,相同的词进入同一个文件。这样每个文件大概是200k左右。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,知道分解得到的小文件的大小都不超过1M。对每个小文件,采用trie树或hash_map统计每个文件中出现的词以及相应的频率,再用容量为100的最小堆并取出出现频率最大的100个词,并把100词及相应的频率存入文件,这样又得到了5000个文件。最后用容量为100的最小堆,依次遍历每个文件,获得最终频数最高的100个词。
2.4. 海量日志数据,提取出某日访问百度次数最多的那个IP
方案1:
首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有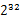 个IP。同样可以采用先哈希再取模的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。
个IP。同样可以采用先哈希再取模的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。
2.5海量数据分布在100台电脑中,想个办法统计出这批数据的TOP10
方案1:
在每台电脑上求出TOP10,可以采用包含10个元素的堆完成(TOP10小,用最大堆,TOP10大,用最小堆)。比如求TOP10大,我们首先取前10个元素调整成最小堆,如果发现,然后扫描后面的数据,并与堆顶元素比较,如果比堆顶元素大,那么用该元素替换堆顶,然后再调整为最小堆。最后堆中的元素就是TOP10大。
求出每台电脑上的TOP10后,然后把这100台电脑上的TOP10组合起来,共1000个数据,再利用上面类似的方法求出TOP10就可以了。
2.6怎么在海量数据中找出重复次数最多的一个?
方案1:
先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并记录重复次数。然后找出上一步求出的数据中重复次数最多的一个就是所求(具体参考前面的题)。
2.7一万字符串,其中有些是重复的,需要把重复的全部去掉,保留没有重复的字符串。请怎么设计和实现?
方案1:
这题用trie树比较合适,hash_map也应该能行。
10. 一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
方案1:这题是考虑时间效率。用trie树统计每个词出现的次数,时间复杂度是O(n*le)(le表示单词的平准长度)。然后是找出出现最频繁的前10个词,可以用堆来实现,前面的题中已经讲到了,时间复杂度是O(n*lg10)。所以总的时间复杂度,是O(n*le)与O(n*lg10)中较大的哪一个。
11. 一个文本文件,找出前10个经常出现的词,但这次文件比较长,说是上亿行或十亿行,总之无法一次读入内存,问最优解。
方案1:首先根据用hash并求模,将文件分解为多个小文件,对于单个文件利用上题的方法求出每个文件件中10个最常出现的词。然后再进行归并处理,找出最终的10个最常出现的词。
12. 100w个数中找出最大的100个数。
方案1:在前面的题中,我们已经提到了,用一个含100个元素的最小堆完成。复杂度为O(100w*lg100)。
方案2:采用快速排序的思想,每次分割之后只考虑比轴大的一部分,知道比轴大的一部分在比100多的时候,采用传统排序算法排序,取前100个。复杂度为O(100w*100)。
方案3:采用局部淘汰法。选取前100个元素,并排序,记为序列L。然后一次扫描剩余的元素x,与排好序的100个元素中最小的元素比,如果比这个最小的要大,那么把这个最小的元素删除,并把x利用插入排序的思想,插入到序列L中。依次循环,知道扫描了所有的元素。复杂度为O(100w*100)。
14. 一共有N个机器,每个机器上有N个数。每个机器最多存O(N)个数并对它们操作。如何找到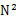 个数中的中数?
个数中的中数?
方案1:先大体估计一下这些数的范围,比如这里假设这些数都是32位无符号整数(共有 个)。我们把0到
个)。我们把0到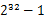 的整数划分为N个范围段,每个段包含
的整数划分为N个范围段,每个段包含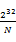 个整数。比如,第一个段位0到
个整数。比如,第一个段位0到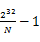 ,第二段为
,第二段为 到
到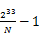 ,…,第N个段为
,…,第N个段为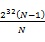 到
到 。然后,扫描每个机器上的N个数,把属于第一个区段的数放到第一个机器上,属于第二个区段的数放到第二个机器上,…,属于第N个区段的数放到第N个机器上。注意这个过程每个机器上存储的数应该是O(N)的。下面我们依次统计每个机器上数的个数,一次累加,直到找到第k个机器,在该机器上累加的数大于或等于
。然后,扫描每个机器上的N个数,把属于第一个区段的数放到第一个机器上,属于第二个区段的数放到第二个机器上,…,属于第N个区段的数放到第N个机器上。注意这个过程每个机器上存储的数应该是O(N)的。下面我们依次统计每个机器上数的个数,一次累加,直到找到第k个机器,在该机器上累加的数大于或等于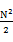 ,而在第k-1个机器上的累加数小于
,而在第k-1个机器上的累加数小于 ,并把这个数记为x。那么我们要找的中位数在第k个机器中,排在第
,并把这个数记为x。那么我们要找的中位数在第k个机器中,排在第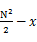 位。然后我们对第k个机器的数排序,并找出第
位。然后我们对第k个机器的数排序,并找出第 个数,即为所求的中位数。复杂度是
个数,即为所求的中位数。复杂度是 的。
的。
方案2:先对每台机器上的数进行排序。排好序后,我们采用归并排序的思想,将这N个机器上的数归并起来得到最终的排序。找到第 个便是所求。复杂度是
个便是所求。复杂度是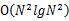 的。
的。
15. 最大间隙问题
给定n个实数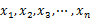 ,求着n个实数在实轴上向量2个数之间的最大差值,要求线性的时间算法。
,求着n个实数在实轴上向量2个数之间的最大差值,要求线性的时间算法。
方案1:最先想到的方法就是先对这n个数据进行排序,然后一遍扫描即可确定相邻的最大间隙。但该方法不能满足线性时间的要求。故采取如下方法:
s 找到n个数据中最大和最小数据max和min。
s 用n-2个点等分区间[min, max],即将[min, max]等分为n-1个区间(前闭后开区间),将这些区间看作桶,编号为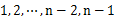 ,且桶
,且桶 的上界和桶i+1的下届相同,即每个桶的大小相同。每个桶的大小为:
的上界和桶i+1的下届相同,即每个桶的大小相同。每个桶的大小为: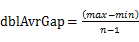 。实际上,这些桶的边界构成了一个等差数列(首项为min,公差为
。实际上,这些桶的边界构成了一个等差数列(首项为min,公差为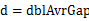 ),且认为将min放入第一个桶,将max放入第n-1个桶。
),且认为将min放入第一个桶,将max放入第n-1个桶。
s 将n个数放入n-1个桶中:将每个元素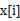 分配到某个桶(编号为index),其中
分配到某个桶(编号为index),其中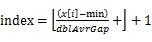 ,并求出分到每个桶的最大最小数据。
,并求出分到每个桶的最大最小数据。
s 最大间隙:除最大最小数据max和min以外的n-2个数据放入n-1个桶中,由抽屉原理可知至少有一个桶是空的,又因为每个桶的大小相同,所以最大间隙不会在同一桶中出现,一定是某个桶的上界和气候某个桶的下界之间隙,且该量筒之间的桶(即便好在该连个便好之间的桶)一定是空桶。也就是说,最大间隙在桶i的上界和桶j的下界之间产生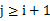 。一遍扫描即可完成。
。一遍扫描即可完成。
16. 将多个集合合并成没有交集的集合:给定一个字符串的集合,格式如: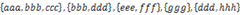 。要求将其中交集不为空的集合合并,要求合并完成的集合之间无交集,例如上例应输出
。要求将其中交集不为空的集合合并,要求合并完成的集合之间无交集,例如上例应输出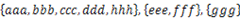 。
。
(1) 请描述你解决这个问题的思路;
(2) 给出主要的处理流程,算法,以及算法的复杂度;
(3) 请描述可能的改进。
方案1:采用并查集。首先所有的字符串都在单独的并查集中。然后依扫描每个集合,顺序合并将两个相邻元素合并。例如,对于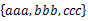 ,首先查看aaa和bbb是否在同一个并查集中,如果不在,那么把它们所在的并查集合并,然后再看bbb和ccc是否在同一个并查集中,如果不在,那么也把它们所在的并查集合并。接下来再扫描其他的集合,当所有的集合都扫描完了,并查集代表的集合便是所求。复杂度应该是O(NlgN)的。改进的话,首先可以记录每个节点的根结点,改进查询。合并的时候,可以把大的和小的进行合,这样也减少复杂度。
,首先查看aaa和bbb是否在同一个并查集中,如果不在,那么把它们所在的并查集合并,然后再看bbb和ccc是否在同一个并查集中,如果不在,那么也把它们所在的并查集合并。接下来再扫描其他的集合,当所有的集合都扫描完了,并查集代表的集合便是所求。复杂度应该是O(NlgN)的。改进的话,首先可以记录每个节点的根结点,改进查询。合并的时候,可以把大的和小的进行合,这样也减少复杂度。
17. 最大子序列与最大子矩阵问题
数组的最大子序列问题:给定一个数组,其中元素有正,也有负,找出其中一个连续子序列,使和最大。
方案1:这个问题可以动态规划的思想解决。设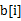 表示以第i个元素
表示以第i个元素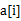 结尾的最大子序列,那么显然
结尾的最大子序列,那么显然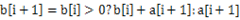 。基于这一点可以很快用代码实现。
。基于这一点可以很快用代码实现。
最大子矩阵问题:给定一个矩阵(二维数组),其中数据有大有小,请找一个子矩阵,使得子矩阵的和最大,并输出这个和。
方案1:可以采用与最大子序列类似的思想来解决。如果我们确定了选择第i列和第j列之间的元素,那么在这个范围内,其实就是一个最大子序列问题。如何确定第i列和第j列可以词用暴搜的方法进行。代码详见我的博客。
top k问题的更多相关文章
- [LeetCode] Top K Frequent Elements 前K个高频元素
Given a non-empty array of integers, return the k most frequent elements. For example,Given [1,1,1,2 ...
- Leetcode 347. Top K Frequent Elements
Given a non-empty array of integers, return the k most frequent elements. For example,Given [1,1,1,2 ...
- 大数据热点问题TOP K
1单节点上的topK (1)批量数据 数据结构:HashMap, PriorityQueue 步骤:(1)数据预处理:遍历整个数据集,hash表记录词频 (2)构建最小堆:最小堆只存k个数据. 时间复 ...
- LeetCode "Top K Frequent Elements"
A typical solution is heap based - "top K". Complexity is O(nlgk). typedef pair<int, un ...
- [IR] Ranking - top k
PageRanking 通过: Input degree of link "Flow" model - 流量判断喜好度 传统的方式又是什么呢? Every term在某个doc中的 ...
- 347. Top K Frequent Elements
Given a non-empty array of integers, return the k most frequent elements. For example,Given [1,1,1,2 ...
- 面试题:m个长度为n的ordered array,求top k 个 数字
package com.sinaWeibo.interview; import java.util.Comparator; import java.util.Iterator; import java ...
- get top k elements of the same key in hive
key points: 1. group by key and sort by using distribute by and sort by. 2. get top k elements by a ...
- Top k问题(线性时间选择算法)
问题描述:给定n个整数,求其中第k小的数. 分析:显然,对所有的数据进行排序,即很容易找到第k小的数.但是排序的时间复杂度较高,很难达到线性时间,哈希排序可以实现,但是需要另外的辅助空间. 这里我提供 ...
- pig询问top k,每个返回hour和ad_network_id最大的两个记录(SUBSTRING,order,COUNT_STAR,limit)
pig里面有一个TOP功能.我不知道为什么用不了.有时间去看看pig源代码. SET job.name 'top_k'; SET job.priority HIGH; --REGISTER piggy ...
随机推荐
- 33 【kebernetes】一个错误的解决方案
在安装或者重新安装kubernetes时,我碰到了这个错误: Unable to update cni config: No networks found in /etc/cni/net.d/ 这个错 ...
- CentOS 6、7 安装 Golang
方法一:使用二进制文件安装 (推荐) 1.下载二进制文件: wget https://storage.googleapis.com/golang/go1.7.3.linux-amd64.tar.gz ...
- 检测Android手机的IP地址
package com.jason.demo.androidip; import android.content.Context; import android.net.DhcpInfo; impor ...
- 产品密钥无法激活成功,最后使用visio2013激活软件激活成功。
装了visio2013,使用网上搜索的产品密钥,没有一个能够激活成功.最后发现了visio的一个激活软件KMSpico,成功激活. 破解工具 KMSpico_setup.exe 下载地址: http: ...
- CentOS 7系统关闭yum自动下载更新
安装CentOS 7后,系统yum自动更新状态默认为开启,若禁止系统自动更新需要手动关闭. 1.进入yum目录 [root@localhost ~]$ cd /etc/yum 2.编辑yum-cron ...
- Java 7.21 游戏:豆机(C++&Java)
PS: 难点在于,随机之后的分隔,理解就很容易了 注意:槽的奇偶情况 C++: #include<iostream> #include<ctime> #include<s ...
- Andriod——手机尺寸相关的概念 +尺寸单位+关于颜色
手机的尺寸: 屏幕对角线的长度,单位为英寸(2.54cm) 手机的分辨率: 屏幕能显示的像素的数量, 一般用在长方向上数量*宽方向上数量来表达 手机的像素密度: pixels per inch,也称P ...
- numpy常见属性、创建数组
1.几种常见numpy的属性 ndim:维度 shape:行数和列数 size:元素个数 >>> import numpy as np #导入numpy模块,np是为了使用方便的 ...
- hisat2+stringtie+ballgown
hisat2+stringtie+ballgown Posted on 2016年11月25日 早在去年九月,我就写个博文说 RNA-seq流程需要进化啦!http://www.bio-info-tr ...
- BZOJ1935或洛谷2163 [SHOI2007]园丁的烦恼
BZOJ原题链接 洛谷原题链接 很容易想到二维前缀和. 设\(S[i][j]\)表示矩阵\((0, 0)(i, j)\)内树木的棵数,则询问的矩形为\((x, y)(xx, yy)\)时,答案为\(S ...