基于docker的spark-hadoop分布式集群之二: 环境测试
在上一章《环境搭建》基础上,本章对各个模块做个测试
Mysql 测试
1、Mysql节点准备
为方便测试,在mysql节点中,增加点数据
进入主节点
docker exec -it hadoop-maste /bin/bash
进入数据库节点
ssh hadoop-mysql
创建数据库
create database zeppelin_test;
创建数据表
create table user_info(id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,name VARCHAR(16),age INT);
增加几条数据,主键让其自增:
insert into user_info(name,age) values("aaa",10);
insert into user_info(name,age) values("bbb",20);
insert into user_info(name,age) values("ccc",30);
2、Zeppelin配置
配置驱动及URL地址:
default.driver ====> com.mysql.jdbc.Driver
default.url ====> jdbc:mysql://hadoop-mysql:3306/zeppelin_test
使zeppelin导入mysql-connector-java库(maven仓库中获取)
mysql:mysql-connector-java:8.0.12
3、测试mysql查询
%jdbc
select * from user_info;
应能打印出先前插入的几条数据。
Hive测试
本次使用JDBC测试连接Hive,注意上一节中,hive-site.xml的一个关键配置,若要使用JDBC连接(即TCP模式),hive.server2.transport.mode应设置为binary。
1、Zeppelin配置
(1)增加hive解释器,在JDBC模式修改如下配置
default.driver ====> org.apache.hive.jdbc.HiveDriver
default.url ====> jdbc:hive2://hadoop-hive:10000
(2)添加依赖
org.apache.hive:hive-jdbc:0.14.0
org.apache.hadoop:hadoop-common:2.6.0
2、测试
Zeppelin增加一个note
增加一个DB:
%hive
CREATE SCHEMA user_hive
%hive
use user_hive
创建一张表:
%hive
create table if not exists user_hive.employee(id int ,name string ,age int)
插入数据:
%hive
insert into user_hive.employee(id,name,age) values(1,"aaa",10)
再打印一下:
%hive
select * from user_hive.employee
所有的操作,都是OK的。
另外,可以从mydql中的hive.DBS表中,查看到刚刚创建的数据库的元信息:
%jdbc
select * frmo hive.DBS;
如下:
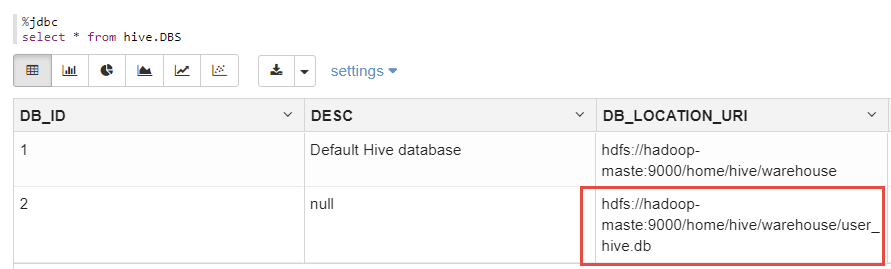
上图显示了刚刚创建的DB的元数据。
登录Hadoop管理后台,应也能看到该文件信息(容器环境将Hadoop的50070端口映射为宿主机的51070)
http://localhost:51070/explorer.html#/home/hive/warehouse/user_hive.db
可以看到,user_hive.db/employee下,有刚刚创建的数据文件,如下:
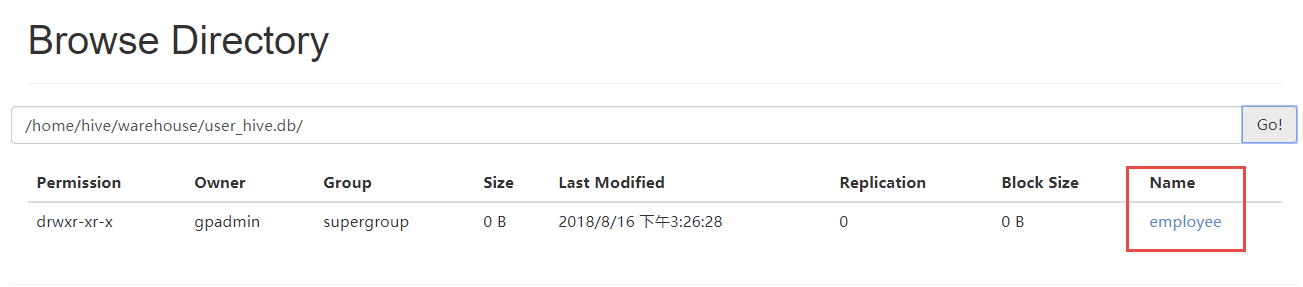
分布式测试
在上一节基础上,进入主从节点,可以看到,在相同的目录下,都存在有相同的数据内容,可见上一节对于hive的操作,在主从节点是都是生效的。操作如下:
主节点:
root@hadoop-maste:~# hdfs dfs -ls /home/hive/warehouse/user_hive.db/employee
Found 1 items
-rwxr-xr-x 2 gpadmin supergroup 9 2018-08-15 11:36 /home/hive/warehouse/user_hive.db/employee/000000_0
从节点:
root@hadoop-node1:~# hdfs dfs -ls /home/hive/warehouse/user_hive.db/employee
Found 1 items
-rwxr-xr-x 2 gpadmin supergroup 9 2018-08-15 11:36 /home/hive/warehouse/user_hive.db/employee/000000_0
测试 Spark 操作 hive
通过spark向刚才创建的user_hive.db中写入两条数据,如下:
import org.apache.spark.sql.{SQLContext, Row}
import org.apache.spark.sql.types.{StringType, IntegerType, StructField, StructType}
import org.apache.spark.sql.hive.HiveContext
//import hiveContext.implicits._
val hiveCtx = new HiveContext(sc)
val employeeRDD = sc.parallelize(Array("6 rc 26","7 gh 27")).map(_.split(" "))
val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("age", IntegerType, true)))
val rowRDD = employeeRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).toInt))
val employeeDataFrame = hiveCtx.createDataFrame(rowRDD, schema)
employeeDataFrame.registerTempTable("tempTable")
hiveCtx.sql("insert into user_hive.employee select * from tempTable")
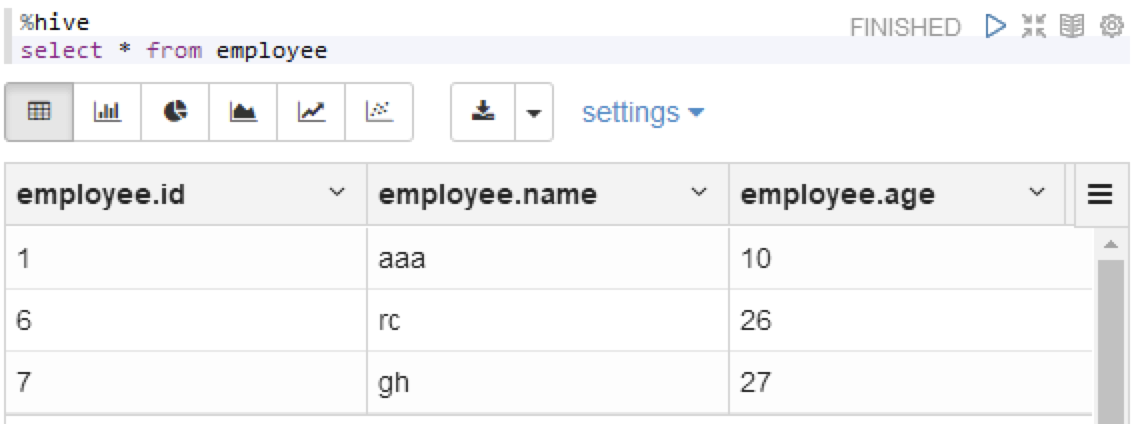
运行之后,查一下hive
%hive
select * from employee
可以看到,数据已经写进文件中了
基于docker的spark-hadoop分布式集群之二: 环境测试的更多相关文章
- 在 Ubuntu 上搭建 Hadoop 分布式集群 Eclipse 开发环境
一直在忙Android FrameWork,终于闲了一点,利用空余时间研究了一下Hadoop,并且在自己和同事的电脑上搭建了分布式集群,现在更新一下blog,分享自己的成果. 一 .环境 1.操作系统 ...
- 使用docker搭建hadoop分布式集群
使用docker搭建部署hadoop分布式集群 在网上找了非常长时间都没有找到使用docker搭建hadoop分布式集群的文档,没办法,仅仅能自己写一个了. 一:环境准备: 1:首先要有一个Cento ...
- 暑假第二弹:基于docker的hadoop分布式集群系统的搭建和测试
早在四月份的时候,就已经开了这篇文章.当时是参加数据挖掘的比赛,在计科院大佬的建议下用TensorFlow搞深度学习,而且要在自己的hadoop分布式集群系统下搞. 当时可把我们牛逼坏了,在没有基础的 ...
- 超快速使用docker在本地搭建hadoop分布式集群
超快速使用docker在本地搭建hadoop分布式集群 超快速使用docker在本地搭建hadoop分布式集群 学习hadoop集群环境搭建是hadoop入门的必经之路.搭建分布式集群通常有两个办法: ...
- 基于Hadoop分布式集群YARN模式下的TensorFlowOnSpark平台搭建
1. 介绍 在过去几年中,神经网络已经有了很壮观的进展,现在他们几乎已经是图像识别和自动翻译领域中最强者[1].为了从海量数据中获得洞察力,需要部署分布式深度学习.现有的DL框架通常需要为深度学习设置 ...
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
- CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 分布式计算(一)Ubuntu搭建Hadoop分布式集群
最近准备接触分布式计算,学习分布式计算的技术栈和架构知识.目前的分布式计算方式大致分为两种:离线计算和实时计算.在大数据全家桶中,离线计算的优秀工具当属Hadoop和Spark,而实时计算的杰出代表非 ...
- 大数据系列之Hadoop分布式集群部署
本节目的:搭建Hadoop分布式集群环境 环境准备 LZ用OS X系统 ,安装两台Linux虚拟机,Linux系统用的是CentOS6.5:Master Ip:10.211.55.3 ,Slave ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
随机推荐
- 全面掌握IO(输入/输出流)
File类: 程序中操作文件和目录都可以使用File类来完成即不管是文件还是目录都是使用File类来操作的,File能新建,删除,重命名文件和目录,但File不能访问文件内容本身,如果需要访问文件本身 ...
- Hadoop框架
1.Hadoop的整体框架 Hadoop由HDFS.MapReduce.HBase.Hive和ZooKeeper等成员组成,其中最基础最重要元素为底层用于存储集群中所有存储节点文件的文件系统HDFS( ...
- PAT甲题题解-1015. Reversible Primes (20)-素数
先判断n是否为素数然后把n转化成d进制下再反转,转化为十进制的num判断num是否为素数 注意n为0和1时,不是素数!!!注意反转后的num也有可能为1,不是素数!!! #include <io ...
- djbc
jdbc:mysql://localhost:3306:test这句里面分如下解析:jdbc:mysql:// 是指JDBC连接方式:localhost: 是指你的本机地址:3306 SQL数据库的端 ...
- 【Beta阶段】第五次Scrum Meeting!
每日任务内容: 本次会议为第五次Scrum Meeting会议~ 由于本次会议项目经理召开时间依旧较晚,在公寓7层召开,女生参与了线上会议. 队员 昨日完成任务 明日要完成任务 刘乾 #167(未完成 ...
- 《Linux内核设计与实现》第四周读书笔记——第五章
<Linux内核设计与实现>第四周读书笔记--第五章 20135301张忻 估算学习时间:共1.5小时 读书:1.0 代码:0 作业:0 博客:0.5 实际学习时间:共2.0小时 读书:1 ...
- Java实现模拟登录新浪微博
毕设题目要使用到新浪微博数据,所以要爬取新浪微博的数据.一般而言,新浪微博的爬虫有两种模式:新浪官方API和模拟登录新浪微博.两种方法的异同点和适用情况就无须赘述了.前辈的文章已经非常多了.写这篇文章 ...
- java之JDBC学习总结
以前一直以为jdbc是很高大上的东西,没想到今天学了jdbc,惊喜来了,just a tool!当然工具是用来帮助人们学习和提供方便的,所以总结了一下,也就是简单的三板斧: first :加载驱动 t ...
- css实现table中td单元格鼠标悬浮时显示更多内容
table中,td单元格无法显示下全部内容,需要在鼠标hover时显示全部内容. 正常显示样式: 鼠标hover时: html: <td>displayAddress<span cl ...
- Docker(九)-Docker创建Selenium容器
SeleniumHQ官方项目:https://github.com/seleniumHQ/docker-selenium 项目目前快速迭代中. Selenium 这里主要针对的是 Selenium G ...