使用python爬取整本《盗墓笔记》
一、前言
《盗墓笔记》是一本经典的盗墓题材小说,故事情节引人入胜。本文将使用python2.7通过小说网站http://www.daomubiji.com/来爬取整本盗墓笔记并保存,在这一过程中演示了使用python网络库requests实现简单的python爬虫以及使用html文档分析库BeautifulSoup分析网页。
二、准备
在进行下一步之前先要安装两个库:requests以及BeautifulSoup。
pip install requests
pip install beautifulsoup4
# BeautifulSoup的解析器
pip install lxml
pip install html5lib
我们通常都是使用浏览器来访问网页,浏览器发送请求给服务器,服务器根据请求将请求的数据返回给浏览器,浏览器再将这些数据显示出来。而使用爬虫则不再使用浏览器发送请求,而是使用程序发送,并且使用爬虫程序接受服务器返回的数据,requests就是一个能帮助我们发送请求给服务器并得到返回数据的库。得到返回数据后(如HTML),可以使用另一个库BeautifulSoup来对HTML进行解析,提取出我们想要的标签的内容。
requests文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
BeautifulSoup文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
三、网页分析
爬虫的基本思想是从网页中找到我们感兴趣的标签或链接,然后使用相关工具(如request和BeautifulSoup)来得到网页和标签的内容。下面对该网站的网页进行分析。
首先打开网站的主页http://www.daomubiji.com/来分析一下网页。我们知道盗墓笔记有很多部,打开后可以看到主页上列出了每一部的入口。
点进去其中的一部:《盗墓笔记1:七星鲁王宫》,我们可以看到该页显示了《盗墓笔记1》的每个章节。

再点进某一章节,就可以看到这一章的内容了。

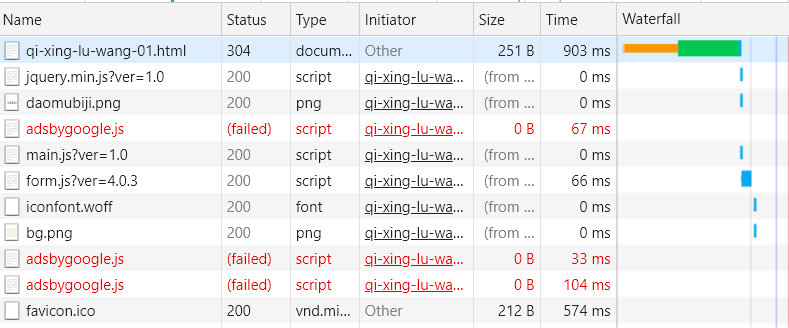
在来分析一下各章的链接,在《盗墓笔记1:七星鲁王宫》中,第一章的链接为http://www.daomubiji.com/qi-xing-lu-wang-01.html,第二章的链接为http://www.daomubiji.com/qi-xing-lu-wang-02.html,以此类推。在浏览器按下F12,选择NetWork后刷新网页,我们可以看到网页请求的文件:
点击第一行,可以看到:
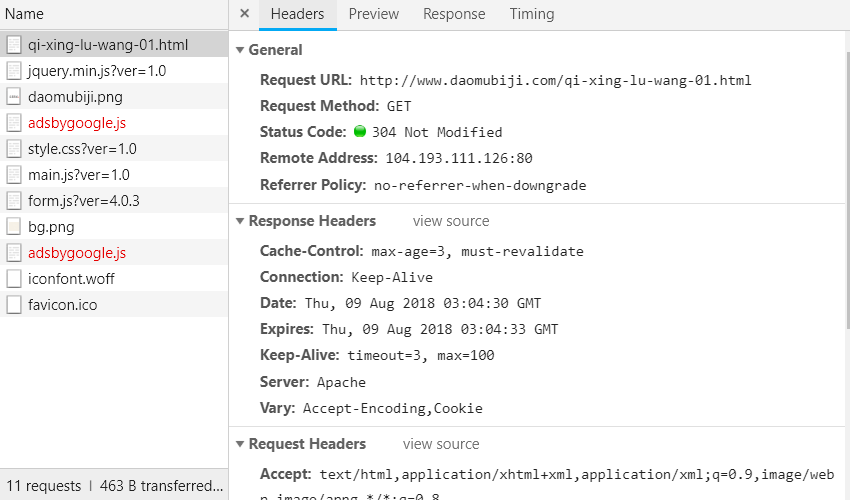
由Headers的内容可以看出该请求为一个简单的GET请求,没有任何参数,翻页是通过链接中的最后一个数字来实现的,比如01代表第一页、02代表第二页,所以只要我们得到所有章节的链接,然后从各章节对应的HTML文档中使用BeautifulSoup提取文章内容即可。总的步骤如下:
- 通过主页获取每本盗墓笔记的链接;
- 通过每本的链接获取每章的链接;
- 通过每章的链接获取每章标题与内容;
- 汇总每章的内容,保存进文件。
以下为各步骤的实现。
四、通过主页获取每本盗墓笔记的链接
打开主页http://www.daomubiji.com/并按下F12,点击左上角的鼠标(或者ctrl+shift+c)来选择元素,然后选择标题《盗墓笔记1:七星鲁王宫》,可以看到下图:
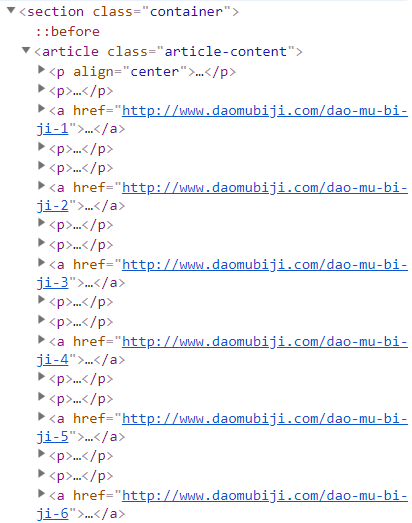
我们发现,每部书的链接都在一个名为article的标签下,由标签a中的href属性指定,所以我们可以使用BeautifulSoup提取出标签a的href属性。我们发现主页还包含两部其他小说:《沙海》和《藏海花》的链接:
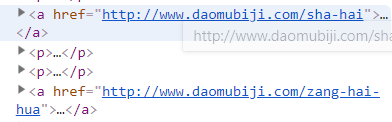
而我们只想获得小说《盗墓笔记》,解决方法是使用BeautifulSoup来将这两个链接排除在外,该小节的代码如下:
from bs4 import BeautifulSoup
import requests
import re
def get_book_urls(url):
book_urls = []
#获取主页
index = requests.get(url)
soup = BeautifulSoup(index.content.decode("utf8"), 'lxml')
#从主页中找到所有的article标签
articles = soup.find_all("article", class_='article-content')
for article in articles:
#找到各本盗墓笔记的链接,并排除沙海和藏海花的链接
links = article.find_all('a', href=re.compile("dao-mu-bi-ji"))
for link in links:
book_urls.append(link["href"])
return book_urls
book_urls = get_book_urls("http://www.daomubiji.com")
print book_urls
输出:

这样我们就得到了每本的链接。
五、通过每本的链接获取每章的链接
点进第一本《七星鲁王宫》http://www.daomubiji.com/dao-mu-bi-ji-1后按F12并选择元素,选择每章的标题:
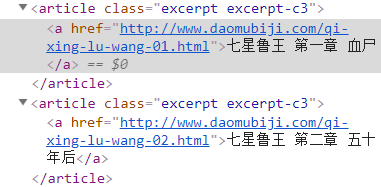
可以看到,每章的链接在article标签(该标签的class为"excerpt excerpt-c3")下,由标签a的href属性指定,使用以下代码获取各章的链接:
def get_chapter_urls(url):
chapter_urls = []
#获取每本书对应的页面
page = requests.get(url)
soup = BeautifulSoup(page.content.decode("utf8"), "lxml")
#找到所有类为excerpt excerpt-c3的article标签
articles = soup.find_all("article", class_="excerpt excerpt-c3")
#提取article标签下a标签的href属性
for article in articles:
chapter_urls.append(article.a["href"])
return chapter_urls
chapter_urls = get_chapter_urls("http://www.daomubiji.com/dao-mu-bi-ji-1")
print chapter_urls
输出(一部分):

六、通过每章的链接获取每章标题与内容
和前面一样,通过对文章内容进行“选择元素”,可以发现标题的标签如下:

内容的标签如下:

使用BeautifulSoup提取标签内容:
def get_content(url):
content = ""
page = requests.get(url)
soup = BeautifulSoup(page.content.decode("utf8"), "lxml")
#提取标题
title = soup.find_all("h1", class_="article-title")[0].string
content += ("\n"+title+"\n\n")
#找到包含文章内容的article标签
articles = soup.find_all("article", class_="article-content")
for article in articles:
ps = article.find_all('p') #找到包含文章每一段的标签p
for p in ps:
#print p.string
for string in p.strings:
content = content + unicode(string) + "\n" #获取标签p中的所有内容
return content
content = get_content("http://www.daomubiji.com/qi-xing-lu-wang-01.html")
print content
输出(一部分):

这样我们对每一章的链接都执行以上操作就可以获得每一章的内容,再把每一章的内容汇总保存即可。
七、完整代码
完整代码如下:
from bs4 import BeautifulSoup
import requests
import re
# 获取每本书的链接
def get_book_urls(url):
book_urls = []
index = requests.get("http://www.daomubiji.com/")
soup = BeautifulSoup(index.content.decode("utf8"), 'lxml')
articles = soup.find_all("article", class_='article-content')
for article in articles:
links = article.find_all('a', href=re.compile("dao-mu-bi-ji"))
for link in links:
book_urls.append(link["href"])
return book_urls
# 获取每章的链接
def get_chapter_urls(url):
chapter_urls = []
page = requests.get(url)
soup = BeautifulSoup(page.content.decode("utf8"), "lxml")
articles = soup.find_all("article", class_="excerpt excerpt-c3")
for article in articles:
chapter_urls.append(article.a["href"])
return chapter_urls
# 获取每章的内容
def get_content(url):
content = ""
page = requests.get(url)
soup = BeautifulSoup(page.content.decode("utf8"), "lxml")
title = soup.find_all("h1", class_="article-title")[0].string
content += ("\n"+title+"\n\n")
articles = soup.find_all("article", class_="article-content")
for article in articles:
ps = article.find_all('p')
for p in ps:
for string in p.strings:
content = content + unicode(string) + "\n"
return content
# 获取全本《盗墓笔记》并保存到文件
def get_article(url):
book_urls = get_book_urls(url)
chapter_urls = []
for url in book_urls:
#url = "http://www.daomubiji.com/dao-mu-bi-ji-2"
chapter_urls.extend(get_chapter_urls(url))
print chapter_urls
result = ""
for chapter_url in chapter_urls:
content = get_content(chapter_url)
result += content
print content
with open("I:\daomubiji\daomubiji.txt", "a") as f:
f.write(result.encode("utf8"))
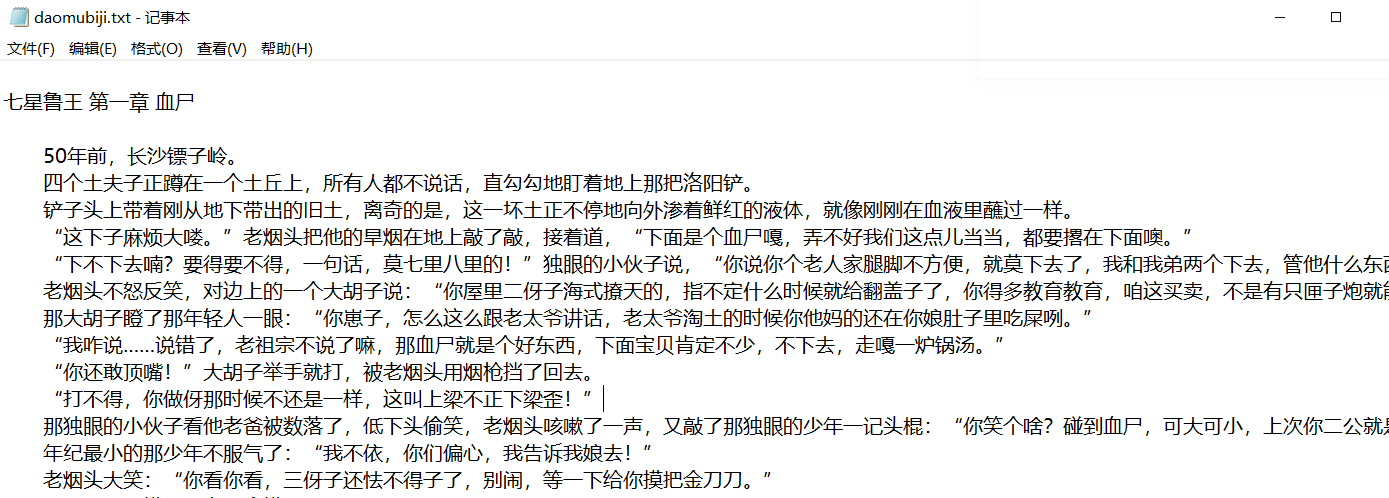
get_article("http://www.daomubiji.com/")
结果:
使用python爬取整本《盗墓笔记》的更多相关文章
- python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口 具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地 刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就o ...
- 用Python爬取B站、腾讯视频、爱奇艺和芒果TV视频弹幕!
众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕.不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一个组织良好的评论序列.通过分析弹幕,我们可以快速洞察广大观众对于视频 ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- Python:爬取乌云厂商列表,使用BeautifulSoup解析
在SSS论坛看到有人写的Python爬取乌云厂商,想练一下手,就照着重新写了一遍 原帖:http://bbs.sssie.com/thread-965-1-1.html #coding:utf- im ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- python爬取网页的通用代码框架
python爬取网页的通用代码框架: def getHTMLText(url):#参数code缺省值为‘utf-8’(编码方式) try: r=requests.get(url,timeout=30) ...
随机推荐
- IntelliJ IDEA远程调试运行中的JAVA程序/项目
一.IntelliJ IDEA配置 1.添加一个运行配置(remote项) 2.打开remote项配置对话框 3.远程jvm参数配置提示 4.远程调试的ip地址和端口号,ip就是java项目所在机器i ...
- java基础知识学习--------之枚举类型(1)
枚举类型的概念: /** * 目的:枚举类型 * @author chenyanlong * 日期:2017/10/22 * 网址:http://blog.csdn.net/sup_heaven/ar ...
- arcgis计算邻接矩阵
求邻接矩阵 教程链接 http://m.blog.csdn.net/wan_yanyan528/article/details/49175673 (1) 将目标shp文件导出一份副本备用(以省级为 ...
- MySQL的DML常用语法格式
MySQL的DML常用语法格式 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道MySQL的查询大致分为单表查询,多表查询以及联合查询.多表查询,顾名思义,就是查询的结果可能 ...
- IIS发布MVC出错
一个MVC网站在发布到IIS上时,出现了这个问题: 然后解决办法: 然后应用程序池那里,自己点右键添加一个 新建完应用池之后选中点高级设置 最后,添加网站,添加网站的时候应用程序池选择自己刚刚新建的那 ...
- 快速了解yuv4:4:4 yuv4:2:2 yuv 4:1:1 yuv 4:2:0四种YUV格式区别
四种YUV格式区别如下: 1.YUV 4:4:4抽样方式: Y: Y0 Y1 Y2 Y3 U: U0 U1 U2 U3 V: V0 V1 V2 V3 2.YUV 4:2:2抽样方式: Y : ...
- bzoj千题计划213:bzoj2660: [Beijing wc2012]最多的方案
http://www.lydsy.com/JudgeOnline/problem.php?id=2660 很容易想到是先把n表示成最大的两个斐波那契数相加,然后再拆分这两个斐波那契数 把数表示成斐波那 ...
- css 基础2
1.内部样式表: 2.行内样式表:在标签内写style,适合style 比较少的情况 3.外部样式表(外联式): 4.html标签可以分为:块级标签,h1~h6,div ,p,ul,ol,li,div ...
- XHR工厂的实现
ajax这种常见的开发模式已经遍布我们日常的开发之中了,ajax本质还是采用一种轮询的模式,就是隔一段时间去发送一次http请求,获取数据,然后显示在页面之上,当然,ajax比起新兴的WebScoke ...
- 如何让你的.vue在sublime text 3 中变成彩色?
作者:青鲤链接:https://www.zhihu.com/question/52215834/answer/129495890来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明 ...