大数据入门第二十五天——logstash入门
一、概述
1.logstash是什么
根据官网介绍:
Logstash 是开源的服务器端数据处理管道,能够同时 从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” 中。(我们的存储库当然是 Elasticsearch。)
//属于elasticsearch旗下产品(JRuby开发,开发者曾说如果他知道有scala,就不会用jruby了。。)
也就是说,它是flume的“后浪”,它解决了“前浪”flume的数据丢失等问题!
2.基础结构
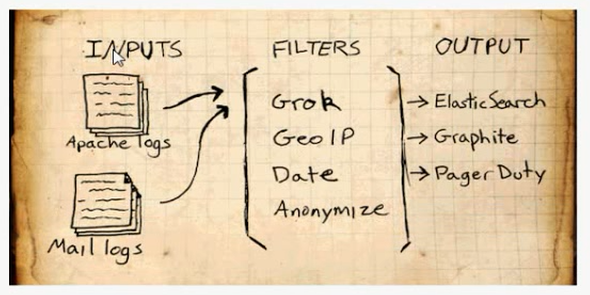
输入:采集各种来源数据
过滤:实时解析转换数据
输出:选择存储库导出数据
补充:Logstash 每读取一次数据的行为叫做事件。
更多详细介绍,包括具体支持的输入输出等,参考:https://www.elastic.co/guide/index.html
用法博文推荐:https://blog.csdn.net/chenleiking/article/details/73563930
二、安装
logstash5.x 6.x需要JDK1.8+,如未安装,请先安装JDK1.8+
1.下载
https://www.elastic.co/downloads/past-releases
选择合适的版本,下载即可
2.解压
[hadoop@mini1 ~]$ tar -zxvf logstash-5.6..tar.gz -C apps/
三、入门使用
1.HelloWorld示例
运行启动命令,并直接给出配置
bin/logstash -e 'input { stdin { } } output { stdout {} }'
常用的启动参数如下:
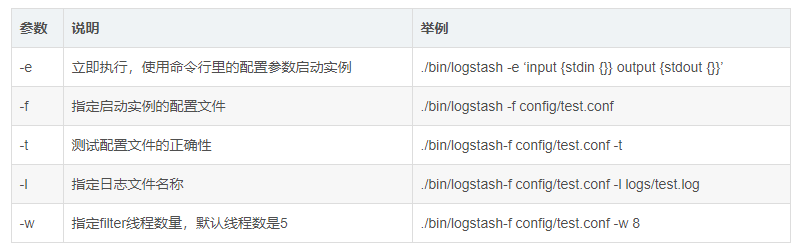
运行结果如下:输入helloworld,给出message消息:
[hadoop@mini1 logstash-5.6.]$ bin/logstash -e 'input { stdin { } } output { stdout {} }'
Sending Logstash's logs to /home/hadoop/apps/logstash-5.6.9/logs which is now configured via log4j2.properties
[--18T16::,][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/home/hadoop/apps/logstash-5.6.9/modules/fb_apache/configuration"}
[--18T16::,][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/home/hadoop/apps/logstash-5.6.9/modules/netflow/configuration"}
[--18T16::,][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.queue", :path=>"/home/hadoop/apps/logstash-5.6.9/data/queue"}
[--18T16::,][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.dead_letter_queue", :path=>"/home/hadoop/apps/logstash-5.6.9/data/dead_letter_queue"}
[--18T16::,][INFO ][logstash.agent ] No persistent UUID file found. Generating new UUID {:uuid=>"893c481c-85d1-4746-8562-48a74dcbad08", :path=>"/home/hadoop/apps/logstash-5.6.9/data/uuid"}
[--18T16::,][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>, "pipeline.batch.size"=>, "pipeline.batch.delay"=>, "pipeline.max_inflight"=>}
[--18T16::,][INFO ][logstash.pipeline ] Pipeline main started
The stdin plugin is now waiting for input:
[--18T16::,][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>}
HelloWorld
{
"@version" => "",
"host" => "mini1",
"@timestamp" => --18T08::.798Z,
"message" => "HelloWorld"
}
2.使用配置文件
实际中的 -e 后的配置一般相对更复杂,所以一般会通过 -f 使用配置文件来启动
bin/logstash -f logstash.conf
配置文件大概长这样:
# 输入
input {
...
} # 过滤器
filter {
...
} # 输出
output {
...
}
编写一个示例的配置文件:logstash.conf:
input {
# 从文件读取日志信息
file {
path => "/home/hadoop/apps/logstash-5.6.9/logs/1.log"
type => "system"
start_position => "beginning"
}
}
# filter {
#
# }
output {
# 标准输出
stdout { codec => rubydebug }
}
输出结果如下:
[hadoop@mini1 logstash-5.6.]$ bin/logstash -f logstash.conf
Sending Logstash's logs to /home/hadoop/apps/logstash-5.6.9/logs which is now configured via log4j2.properties
[--18T16::,][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/home/hadoop/apps/logstash-5.6.9/modules/fb_apache/configuration"}
[--18T16::,][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/home/hadoop/apps/logstash-5.6.9/modules/netflow/configuration"}
[--18T16::,][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>, "pipeline.batch.size"=>, "pipeline.batch.delay"=>, "pipeline.max_inflight"=>}
[--18T16::,][INFO ][logstash.pipeline ] Pipeline main started
{
"@version" => "",
"host" => "mini1",
"path" => "/home/hadoop/apps/logstash-5.6.9/logs/1.log",
"@timestamp" => --18T08::.451Z,
"message" => "Apr 16 17:01:01 mini1 systemd: Started Session 5 of user root.",
"type" => "system"
}
四、插件的使用
logstash主要有3个主插件:输入input,输出output,过滤filter,其他还包括编码解码插件等
1.输入插件input
定义的数据源,支持从文件、stdin、kafka、twitter等来源,甚至可以自己写一个input plugin。
输入的file path等是支持通配的,例如:
path => "/data/web/logstash/logFile/*/*.log"
常用输入插件
1.file
file插件的必选参数只有path一项:部分选项如下:

// 原版的完整参数解释参见官网,中文参见上文博文参考处链接
配置示例:
input
file {
path => ["/var/log/*.log", "/var/log/message"]
type => "system"
start_position => "beginning"
}
}
2.过滤插件、输出插件
同输入插件类似,可以参考官网详细配置与参考博文
大数据入门第二十五天——logstash入门的更多相关文章
- 大数据入门第二十五天——elasticsearch入门
一.概述 推荐路神的ES权威指南翻译:https://es.xiaoleilu.com/010_Intro/00_README.html 官网:https://www.elastic.co/cn/pr ...
- 大数据入门第十五天——HBase整合:云笔记项目
一.功能简述 1.笔记本管理(增删改) 2.笔记管理 3.共享笔记查询功能 4.回收站 效果预览: 二.库表设计 1.设计理念 将云笔记信息分别存储在redis和hbase中. redis(缓存):存 ...
- 大数据笔记(十五)——Hive的体系结构与安装配置、数据模型
一.常见的数据分析引擎 Hive:Hive是一个翻译器,一个基于Hadoop之上的数据仓库,把SQL语句翻译成一个 MapReduce程序.可以看成是Hive到MapReduce的映射器. Hive ...
- Spring入门第二十五课
使用具名参数 直接看代码: db.properties jdbc.user=root jdbc.password=logan123 jdbc.driverClass=com.mysql.jdbc.Dr ...
- 孤荷凌寒自学python第二十五天初识python的time模块
孤荷凌寒自学python第二十五天python的time模块 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 通过对time模块添加引用,就可以使用python的time模块来进行相关的时间操 ...
- 无废话ExtJs 入门教程十五[员工信息表Demo:AddUser]
无废话ExtJs 入门教程十五[员工信息表Demo:AddUser] extjs技术交流,欢迎加群(201926085) 前面我们共介绍过10种表单组件,这些组件是我们在开发过程中最经常用到的,所以一 ...
- NeHe OpenGL教程 第二十五课:变形
转自[翻译]NeHe OpenGL 教程 前言 声明,此 NeHe OpenGL教程系列文章由51博客yarin翻译(2010-08-19),本博客为转载并稍加整理与修改.对NeHe的OpenGL管线 ...
- javaSE第二十五天
第二十五天 399 1:如何让Netbeans的东西Eclipse能访问. 399 2:GUI(了解) 399 (1)用户图形界面 399 (2)两个包: 399 (3) ...
- Bootstrap入门(十五)组件9:面板组件
Bootstrap入门(十五)组件9:面板组件 虽然不总是必须,但是某些时候你可能需要将某些 DOM 内容放到一个盒子里.对于这种情况,可以试试面板组件. 1.基本实例 2.带标题的面板 3.情景效果 ...
随机推荐
- php添加购物车
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 排错-SP2-1503:无法初始化Oracle调用界面解决
SP2-1503:无法初始化Oracle调用界面解决 by:授客 QQ:1033553122 SP2-1503:无法初始化Oracle调用界面解决 问题描述: win7下,cmd运行输入sqlplus ...
- 学习MVC之租房网站(十二)-缓存和静态页面
在上一篇<学习MVC之租房网站(十一)-定时任务和云存储>学习了Quartz的使用.发邮件,并将通过UEditor上传的图片保存到云存储.在项目的最后,再学习优化网站性能的一些技术:缓存和 ...
- 大数据【三】YARN集群部署
一 概述 YARN是一个资源管理.任务调度的框架,采用master/slave架构,主要包含三大模块:ResourceManager(RM).NodeManager(NM).ApplicationMa ...
- idea总是编译启动报错
使用多环境配置时候,总是会出现莫名其妙的启动报错.主要是没有多环境配置的参数,挺奇怪的,因为这个问题时现时不现.又没有什么具体规律,一直找不到原因.今天一个偶然的机会,发现会不会是这个原因?
- D3、EChart、HighChart绘图demol
1.echarts: <!DOCTYPE html> <html> <head> <meta charset="utf-8" ...
- Apache2启动错误Could not reliably determine the server's fully qualified domain name
错误情况: AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using ...
- Spark job 部署模式
Spark job 的部署有两种模式,Client && Cluster spark-submit .. --deploy-mode client | cluster [上传 Jar ...
- 使用环信开发项目遇到错误提示 configure your build for VectorDrawableCompat
问题描述:在使用AndroidStudio开发项目时,使用环信重写了聊天界面后,运行时app就崩掉了,查看日志报告,提示报错如下: java.lang.RuntimeException: Unable ...
- 用apiDoc简化接口开发
身为程序员最讨厌看到的代码没有注释,自己的代码却讨厌写注释,觉得麻烦,接口也是这样. 比如公司要做一个H5活动的页面,开发文档已经发到后端开发.设计.与前端的邮箱了,其实这个时候就可以开始开发了.开发 ...