模型标准化——预测模型标记语言(PMML)
https://www.cnblogs.com/pinard/p/9220199.html
在机器学习用于产品的时候,我们经常会遇到跨平台的问题。比如我们用Python基于一系列的机器学习库训练了一个模型,但是有时候其他的产品和项目想把这个模型集成进去,但是这些产品很多只支持某些特定的生产环境比如Java,为了上一个机器学习模型去大动干戈修改环境配置很不划算,此时我们就可以考虑用预测模型标记语言(Predictive Model Markup Language,以下简称PMML)来实现跨平台的机器学习模型部署了。
1. PMML概述
PMML是数据挖掘的一种通用的规范,它用统一的XML格式来描述我们生成的机器学习模型。这样无论你的模型是sklearn,R还是Spark MLlib生成的,我们都可以将其转化为标准的XML格式来存储。当我们需要将这个PMML的模型用于部署的时候,可以使用目标环境的解析PMML模型的库来加载模型,并做预测。
可以看出,要使用PMML,需要两步的工作,第一块是将离线训练得到的模型转化为PMML模型文件,第二块是将PMML模型文件载入在线预测环境,进行预测。这两块都需要相关的库支持。
2. PMML模型的生成和加载相关类库
PMML模型的生成相关的库需要看我们使用的离线训练库。如果我们使用的是sklearn,那么可以使用sklearn2pmml这个python库来做模型文件的生成,这个库安装很简单,使用"pip install sklearn2pmml"即可,相关的使用我们后面会有一个demo。如果使用的是Spark MLlib, 这个库有一些模型已经自带了保存PMML模型的方法,可惜并不全。如果是R,则需要安装包"XML"和“PMML”。此外,JAVA库JPMML可以用来生成R,SparkMLlib,xgBoost,Sklearn的模型对应的PMML文件。github地址是:https://github.com/jpmml/jpmml。
加载PMML模型需要目标环境支持PMML加载的库,如果是JAVA,则可以用JPMML来加载PMML模型文件。相关的使用我们后面会有一个demo。
3. PMML模型生成和加载示例
下面我们给一个示例,使用sklearn生成一个决策树模型,用sklearn2pmml生成模型文件,用JPMML加载模型文件,并做预测。
完整代码参见我的github:https://github.com/ljpzzz/machinelearning/blob/master/model-in-product/sklearn-jpmml
首先是用用sklearn生成一个决策树模型,由于我们是需要保存PMML文件,所以最好把模型先放到一个Pipeline数组里面。这个数组里面除了我们的决策树模型以外,还可以有归一化,降维等预处理操作,这里作为一个示例,我们Pipeline数组里面只有决策树模型。代码如下:

- import numpy as np
- import matplotlib.pyplot as plt
- %matplotlib inline
- import pandas as pd
- from sklearn import tree
- from sklearn2pmml.pipeline import PMMLPipeline
- from sklearn2pmml import sklearn2pmml
- import os
- os.environ["PATH"] += os.pathsep + 'C:/Program Files/Java/jdk1.8.0_171/bin'
- X=[[1,2,3,1],[2,4,1,5],[7,8,3,6],[4,8,4,7],[2,5,6,9]]
- y=[0,1,0,2,1]
- pipeline = PMMLPipeline([("classifier", tree.DecisionTreeClassifier(random_state=9))]);
- pipeline.fit(X,y)
- sklearn2pmml(pipeline, ".\demo.pmml", with_repr = True)
上面这段代码做了一个非常简单的决策树分类模型,只有5个训练样本,特征有4个,输出类别有3个。实际应用时,我们需要将模型调参完毕后才将其放入PMMLPipeline进行保存。运行代码后,我们在当前目录会得到一个PMML的XML文件,可以直接打开看,内容大概如下:
- <?xml version="1.0" encoding="UTF-8" standalone="yes"?>
- <PMML xmlns="http://www.dmg.org/PMML-4_3" version="4.3">
- <Header>
- <Application name="JPMML-SkLearn" version="1.5.3"/>
- <Timestamp>2018-06-24T05:47:17Z</Timestamp>
- </Header>
- <MiningBuildTask>
- <Extension>PMMLPipeline(steps=[('classifier', DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
- max_features=None, max_leaf_nodes=None,
- min_impurity_decrease=0.0, min_impurity_split=None,
- min_samples_leaf=1, min_samples_split=2,
- min_weight_fraction_leaf=0.0, presort=False, random_state=9,
- splitter='best'))])</Extension>
- </MiningBuildTask>
- <DataDictionary>
- <DataField name="y" optype="categorical" dataType="integer">
- <Value value="0"/>
- <Value value="1"/>
- <Value value="2"/>
- </DataField>
- <DataField name="x3" optype="continuous" dataType="float"/>
- <DataField name="x4" optype="continuous" dataType="float"/>
- </DataDictionary>
- <TransformationDictionary>
- <DerivedField name="double(x3)" optype="continuous" dataType="double">
- <FieldRef field="x3"/>
- </DerivedField>
- <DerivedField name="double(x4)" optype="continuous" dataType="double">
- <FieldRef field="x4"/>
- </DerivedField>
- </TransformationDictionary>
- <TreeModel functionName="classification" missingValueStrategy="nullPrediction" splitCharacteristic="multiSplit">
- <MiningSchema>
- <MiningField name="y" usageType="target"/>
- <MiningField name="x3"/>
- <MiningField name="x4"/>
- </MiningSchema>
- <Output>
- <OutputField name="probability(0)" optype="continuous" dataType="double" feature="probability" value="0"/>
- <OutputField name="probability(1)" optype="continuous" dataType="double" feature="probability" value="1"/>
- <OutputField name="probability(2)" optype="continuous" dataType="double" feature="probability" value="2"/>
- </Output>
- <Node>
- <True/>
- <Node>
- <SimplePredicate field="double(x3)" operator="lessOrEqual" value="3.5"/>
- <Node score="1" recordCount="1.0">
- <SimplePredicate field="double(x3)" operator="lessOrEqual" value="2.0"/>
- <ScoreDistribution value="0" recordCount="0.0"/>
- <ScoreDistribution value="1" recordCount="1.0"/>
- <ScoreDistribution value="2" recordCount="0.0"/>
- </Node>
- <Node score="0" recordCount="2.0">
- <True/>
- <ScoreDistribution value="0" recordCount="2.0"/>
- <ScoreDistribution value="1" recordCount="0.0"/>
- <ScoreDistribution value="2" recordCount="0.0"/>
- </Node>
- </Node>
- <Node score="2" recordCount="1.0">
- <SimplePredicate field="double(x4)" operator="lessOrEqual" value="8.0"/>
- <ScoreDistribution value="0" recordCount="0.0"/>
- <ScoreDistribution value="1" recordCount="0.0"/>
- <ScoreDistribution value="2" recordCount="1.0"/>
- </Node>
- <Node score="1" recordCount="1.0">
- <True/>
- <ScoreDistribution value="0" recordCount="0.0"/>
- <ScoreDistribution value="1" recordCount="1.0"/>
- <ScoreDistribution value="2" recordCount="0.0"/>
- </Node>
- </Node>
- </TreeModel>
- </PMML>
可以看到里面就是决策树模型的树结构节点的各个参数,以及输入值。我们的输入被定义为x1-x4,输出定义为y。
有了PMML模型文件,我们就可以写JAVA代码来读取加载这个模型并做预测了。
我们创建一个Maven或者gradle工程,加入JPMML的依赖,这里给出maven在pom.xml的依赖,gradle的结构是类似的。
- <dependency>
- <groupId>org.jpmml</groupId>
- <artifactId>pmml-evaluator</artifactId>
- <version>1.4.1</version>
- </dependency>
- <dependency>
- <groupId>org.jpmml</groupId>
- <artifactId>pmml-evaluator-extension</artifactId>
- <version>1.4.1</version>
- </dependency>
接着就是读取模型文件并预测的代码了,具体代码如下:
- import org.dmg.pmml.FieldName;
- import org.dmg.pmml.PMML;
- import org.jpmml.evaluator.*;
- import org.xml.sax.SAXException;
- import javax.xml.bind.JAXBException;
- import java.io.FileInputStream;
- import java.io.IOException;
- import java.io.InputStream;
- import java.util.HashMap;
- import java.util.LinkedHashMap;
- import java.util.List;
- import java.util.Map;
- /**
- * Created by 刘建平Pinard on 2018/6/24.
- */
- public class PMMLDemo {
- private Evaluator loadPmml(){
- PMML pmml = new PMML();
- InputStream inputStream = null;
- try {
- inputStream = new FileInputStream("D:/demo.pmml");
- } catch (IOException e) {
- e.printStackTrace();
- }
- if(inputStream == null){
- return null;
- }
- InputStream is = inputStream;
- try {
- pmml = org.jpmml.model.PMMLUtil.unmarshal(is);
- } catch (SAXException e1) {
- e1.printStackTrace();
- } catch (JAXBException e1) {
- e1.printStackTrace();
- }finally {
- //关闭输入流
- try {
- is.close();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- ModelEvaluatorFactory modelEvaluatorFactory = ModelEvaluatorFactory.newInstance();
- Evaluator evaluator = modelEvaluatorFactory.newModelEvaluator(pmml);
- pmml = null;
- return evaluator;
- }
- private int predict(Evaluator evaluator,int a, int b, int c, int d) {
- Map<String, Integer> data = new HashMap<String, Integer>();
- data.put("x1", a);
- data.put("x2", b);
- data.put("x3", c);
- data.put("x4", d);
- List<InputField> inputFields = evaluator.getInputFields();
- //过模型的原始特征,从画像中获取数据,作为模型输入
- Map<FieldName, FieldValue> arguments = new LinkedHashMap<FieldName, FieldValue>();
- for (InputField inputField : inputFields) {
- FieldName inputFieldName = inputField.getName();
- Object rawValue = data.get(inputFieldName.getValue());
- FieldValue inputFieldValue = inputField.prepare(rawValue);
- arguments.put(inputFieldName, inputFieldValue);
- }
- Map<FieldName, ?> results = evaluator.evaluate(arguments);
- List<TargetField> targetFields = evaluator.getTargetFields();
- TargetField targetField = targetFields.get(0);
- FieldName targetFieldName = targetField.getName();
- Object targetFieldValue = results.get(targetFieldName);
- System.out.println("target: " + targetFieldName.getValue() + " value: " + targetFieldValue);
- int primitiveValue = -1;
- if (targetFieldValue instanceof Computable) {
- Computable computable = (Computable) targetFieldValue;
- primitiveValue = (Integer)computable.getResult();
- }
- System.out.println(a + " " + b + " " + c + " " + d + ":" + primitiveValue);
- return primitiveValue;
- }
- public static void main(String args[]){
- PMMLDemo demo = new PMMLDemo();
- Evaluator model = demo.loadPmml();
- demo.predict(model,1,8,99,1);
- demo.predict(model,111,89,9,11);
- }
- }
代码里有两个函数,第一个loadPmml是加载模型的,第二个predict是读取预测样本并返回预测值的。我的代码运行结果如下:
target: y value: {result=2, probability_entries=[0=0.0, 1=0.0, 2=1.0], entityId=5, confidence_entries=[]}
1 8 99 1:2
target: y value: {result=1, probability_entries=[0=0.0, 1=1.0, 2=0.0], entityId=6, confidence_entries=[]}
111 89 9 11:1
也就是样本(1,8,99,1)被预测为类别2,而(111,89,9,11)被预测为类别1。
以上就是PMML生成和加载的一个示例,使用起来其实门槛并不高,也很简单。
4. PMML总结与思考
PMML的确是跨平台的利器,但是是不是就没有缺点呢?肯定是有的!
第一个就是PMML为了满足跨平台,牺牲了很多平台独有的优化,所以很多时候我们用算法库自己的保存模型的API得到的模型文件,要比生成的PMML模型文件小很多。同时PMML文件加载速度也比算法库自己独有格式的模型文件加载慢很多。
第二个就是PMML加载得到的模型和算法库自己独有的模型相比,预测会有一点点的偏差,当然这个偏差并不大。比如某一个样本,用sklearn的决策树模型预测为类别1,但是如果我们把这个决策树落盘为一个PMML文件,并用JAVA加载后,继续预测刚才这个样本,有较小的概率出现预测的结果不为类别1.
第三个就是对于超大模型,比如大规模的集成学习模型,比如xgboost, 随机森林,或者tensorflow,生成的PMML文件很容易得到几个G,甚至上T,这时使用PMML文件加载预测速度会非常慢,此时推荐为模型建立一个专有的环境,就没有必要去考虑跨平台了。
此外,对于TensorFlow,不推荐使用PMML的方式来跨平台。可能的方法一是TensorFlow serving,自己搭建预测服务,但是会稍有些复杂。另一个方法就是将模型保存为TensorFlow的模型文件,并用TensorFlow独有的JAVA库加载来做预测。
我们在下一篇会讨论用python+tensorflow训练保存模型,并用tensorflow的JAVA库加载做预测的方法和实例。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
PMML, Predictive Model Markup Language.
1.简述
PMML 用于描述算法模型, 允许您在不同的应用程序之间轻松共享预测分析模型.
通俗地讲, 我有一个决策树模型, 使用效果也不错, 那么就可以把树的结构(节点间的父子关系, 节点内的丰富信息 等)序列化为PMML文件, 共享给其他人使用.
2. 主要结构
PMML 文件的结构遵从了用于构建预测解决方案的常用步骤,包括:
- 数据词典
这是一种数据分析阶段的产品,可以识别和定义哪些输入数据字段对于解决眼前的问题是最有用的。这可以包括数值、顺序和分类字段。 - 挖掘架构
定义了处理缺少值和离群值的策略。这非常有用,因为通常情况,当将模型应用于实践时,所需的输入数据字段可能为空或者被误呈现。 - 数据转换
定义了将原始输入数据预处理至派生字段所需的计算。派生字段(有时也称为特征检测器)对输入字段进行合并或修改,以获取更多相关信息。例如,为了预测停车所需的制动压力,一个预测模型可能将室外温度和水的存在(是否在下雨?)作为原始数据。派生字段可能会将这两个字段结合起来,以探测路上是否结冰。然后结冰字段被作为模型的直接输入来预测停车所需的制动压力。 - 模型定义
定义了用于构建模型的结构和参数。PMML 涵盖了多种统计技术。例如,为了呈现一个神经网络,它定义了所有的神经层和神经元之间的连接权重。对于一个决策树来说,它定义了所有树节点及简单和复合谓语。 - 输出
定义了预期模型输出。对于一个分类任务来说,输出可以包括预测类及与所有可能类相关的概率。 - 目标
定义了应用于模型输出的后处理步骤。对于一个回归任务来说,此步骤支持将输出转变为人们很容易就可以理解的分数(预测结果)。 - 模型解释
定义了将测试数据传递至模型时获得的性能度量标准(与训练数据相对)。这些度量标准包括字段相关性、混淆矩阵、增益图及接收者操作特征(ROC)曲线图。 - 模型验证
定义了一个包含输入数据记录和预期模型输出的示例集。这是非常重要的一个步骤,因为在应用程序之间移动模型时,该模型需要通过匹配测试。这样就可以确保,在呈现相同的输入时,新系统可以生成与旧系统同样的输出。 如果实际情况是这样的话,一个模型将被认为经过了验证,且随时可用于实践。
3. GBDT例子
图3-1 一个GBDT决策树的回归模型
可以看出模型是由若干棵树组成的, 通过加和来使用.
每棵树的编号从0开始, 是根节点. 因为是完全二叉树, 所以若当前节点为x, 则左子树为2x+1, 右子树为2x+2.
具有父子关系的节点, 子节点会在父节点内部且有缩进.
简化一下图3-1中的 模型, 得到下列xml片段. 它的可视化见图3-2 .
- <!--代码片3 , 回归决策树的表达-->
- <!--section_num表示文章中段落个数, picitem_num表示商品图个数等, 根据这些特征来预测文章的等级.-->
- <Node id="0">
- <Node id="1">
- <SimplePredicate field="section_num" operator="lessOrEqual" value="6.5"/>
- <Node id="3" score="2">
- <SimplePredicate field="picitem_num" operator="lessOrEqual" value="15.5"/>
- </Node>
- <Node id="4" score="3">
- <SimplePredicate field="picitem_num" operator="greaterThan" value="15.5"/>
- </Node>
- </Node>
- <Node id="2">
- <SimplePredicate field="section_num" operator="greaterThan" value="6.5"/>
- <Node id="5" score="4">
- <SimplePredicate field="text_len" operator="lessOrEqual" value="895.5"/>
- </Node>
- <Node id="6" score="5">
- <SimplePredicate field="text_len" operator="greaterThan" value="895.5"/>
- </Node>
- </Node>
- </Node>
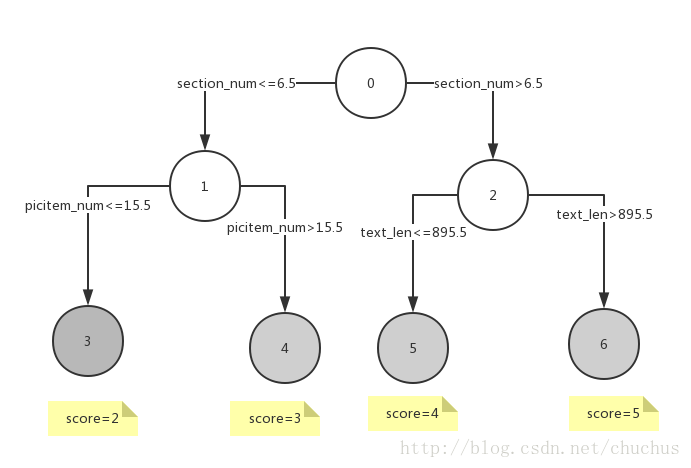
图3-2 代码片3的可视化表示
4.参考资料
参考资料:
IBM 知识库:何为 PMML?
PMML 4.1 GeneralStructure 文档
PMML 4.1 TreeModels 结构文档
PMML简介
PMML全称预言模型标记模型(Predictive Model Markup Language),以XML 为载体呈现数据挖掘模型。PMML 允许您在不同的应用程序之间轻松共享预测分析模型。因此,您可以在一个系统中定型一个模型,在 PMML 中对其进行表达,然后将其移动到另一个系统中,而不需考虑分析和预测过程中的具体实现细节。使得模型的部署摆脱了模型开发和产品整合的束缚。
PMML标准
PMML 标准是数据挖掘过程的一个实例化标准,它按照数据挖掘任务执行过程,有序的定义了数据挖掘不同阶段的相关信息:
头信息(Header)
数据字典(DataDictionary)
挖掘模式(Mining Schema)
数据转换(Transformations)
模型定义 (Model Definition)
评分结果 (Score Result)
头信息(Header)
PMML文件使用头信息作为开始,它主要用于记录产品、版权、模型描述,建模时间等描述性信息。例如:
<Header copyright="Copyright (c) 2017 liaotuo" description="Random Forest Tree Model">
<Extension name="user" value="liaotuo" extender="Rattle/PMML"/>
<Application name="Rattle/PMML" version="1.4"/>
<Timestamp>2017-07-04 16:33:42</Timestamp>
</Header>
其中:
Header 是标识头信息部分的起始标记
copyright 包含了所记录模型的版权信息
description 包含可读的描述性信息
Application 描述了生成本文件所含模型的软件产品。
Timestamp 记录了模型创建的时间。
数据字典(DataDictionary)
数据字典定义了所有变量的信息,包括预测变量和目标变量。这些信息包括变量名,量度和类型等。 对于分类变量,可能包含各种不同类型的分类值, 包括有效值 (valid value),遗漏值 (missing value) 和无效值 (invalid value), 它们由 Value 的“property”属性决定;对于连续变量,可以指定一个或多个有效值范围 (Interval)。
<DataDictionary numberOfFields="7">
<DataField dataType="double" displayName="Age" name="Age" optype="continuous"/>
<Interval leftMargin="0" rightMargin="120" closure="closedClosed" />
<DataField dataType="string" displayName="Sex" name="Sex" optype="categorical">
<Value displayValue="F" property="valid" value="F"/>
<Value displayValue="M" property="valid" value="M"/>
</DataField>
<DataField dataType="string" displayName="BP" name="BP" optype="categorical">
<Value displayValue="HIGH" property="valid" value="HIGH"/>
<Value displayValue="LOW" property="valid" value="LOW"/>
<Value displayValue="NORMAL" property="valid" value="NORMAL"/>
<Value displayValue="ABNORMAL" property="invalid" value="ABNORMAL"/>
<Value displayValue="MISSING" property="missing" value="MISSING"/>
</DataField>
<DataField dataType="string" displayName="Cholesterol" name="Cholesterol"
optype="categorical">
<Value displayValue="HIGH" property="valid" value="HIGH"/>
<Value displayValue="NORMAL" property="valid" value="NORMAL"/>
</DataField>
<DataField dataType="double" displayName="Na" name="Na" optype="continuous"/>
<DataField dataType="double" displayName="K" name="K" optype="continuous"/>
<DataField dataType="string" displayName="Drug" name="Drug" optype="categorical">
<Value displayValue="drugA" property="valid" value="drugA"/>
<Value displayValue="drugB" property="valid" value="drugB"/>
<Value displayValue="drugC" property="valid" value="drugC"/>
<Value displayValue="drugX" property="valid" value="drugX"/>
<Value displayValue="drugY" property="valid" value="drugY"/>
</DataField>
</DataDictionary>
挖掘模式(Mining Schema)
定义预测变量和目标变量
<MiningSchema>
<MiningField importance="0.589759" name="K" usageType="active"/>
<MiningField importance="0.0328595" name="Age" usageType="active"/>
<MiningField importance="0.0249929" name="Na" usageType="active"
outliers=" asExtremeValues" lowValue="0.02" highValue="0.08"/>
<MiningField importance="0.0333406" name="Cholesterol" usageType="active"/>
<MiningField importance="0.307279" name="BP" usageType="active"
missingValueReplacement="HIGH"/>
<MiningField importance="0.0117684" name="Sex" usageType="active"/>
<MiningField name="Drug" usageType="predicted"/>
</MiningSchema>
如下:给出了一个使用 Functions 的示例,通过使用内建函数 if 和 isMissing 将变量“PREVEXP”中的缺失值替换为指定的均值。值得注意的是,替换了缺失值之后将产生一个新的变量“PREVEXP_without_missing”。
<DerivedField dataType="double" name="PREVEXP_without_missing"
optype="continuous">
<Apply function="if">
<Apply function="isMissing">
<FieldRef field="PREVEXP"/>
</Apply>
<Constant>mean</Constant>
<FieldRef field="PREVEXP"/>
</Apply>
</DerivedField>
模型定义 (Model Definition)
具体的模型定义,最新的 PMML 4.0.1 定义了一下十三种模型:
AssociationModel
ClusteringModel
GeneralRegressionModel
MiningModel
NaiveBayesModel
NeuralNetwork
RegressionModel
RuleSetModel
SequenceModel
SupportVectorMachineModel
TextModel
TimeSeriesModel
TreeModel
这些模型都是帮助使用者从历史性的数据中提取出无法直观发现的,具有推广意义的数据模式。比如说 Association model,关联规则模型,常被用来发现大量交易数据中不同产品的购买关系和规则。使用其分析超市的销售单就可以发现,那些购买婴幼儿奶粉和护肤品的客户同时也会以较大的可能性去购买纸尿裤。这样有助于管理人员作出合理的商业决策,有导向的推动购物行为,比如将上述产品放在相邻的购物架上便于客户购买,从而产生更高的销售额。Tree model,树模型,也是很常用的模型,她采用类似树分支的结构将数据逐层划分成节点,而每个叶子节点就表示一个特别的类别。树模型受到应用领域广泛的欢迎,还有一个重要的原因就是她所做出的预测决策易于解释,能够快速推广。为了支持这些模型,PMML 标准提供了大量的语法来有针对性的表示不同的模型。
评分结果(Score Result)
评分结果集可以在输出元素 (Output) 中定义
<Output>
<OutputField name="$R-Drug" displayName="Predicted Value" optype="categorical"
dataType="string" targetField="Drug" feature="predictedValue"/>
<OutputField name="$RC-Drug" displayName="Confidence of Predicted Value"
optype="continuous" dataType="double" targetField="Drug"
feature="standardError"/>
<OutputField name="$RP-drugA" displayName="Probability of drugA"
optype="categorical" dataType="string" targetField="Drug"
feature="probability" value="drugA"/>
<OutputField name="$RP-drugB" displayName="Probability of drugB"
optype="categorical" dataType="string" targetField="Drug"
feature="probability" value="drugB"/>
<OutputField name="$RP-drugC" displayName="Probability of drugC"
optype="categorical" dataType="string" targetField="Drug"
feature="probability" value="drugC"/>
<OutputField name="$RP-drugX" displayName="Probability of drugX"
optype="categorical" dataType="string" targetField="Drug"
feature="probability" value="drugX"/>
<OutputField name="$RP-drugY" displayName="Probability of drugY"
optype="categorical" dataType="string" targetField="Drug"
feature="probability" value="drugY"/>
</Output>
输出元素 : 描述了从模型中获取评分结果值的集合。每一个输出变量指定名称,类型,规则计算和结果特征。 结果特征 (feature): 它是一个结果的标识符 , 它有很多的分类表达,常见统计观念如下:
预测价值(predictedValue):它描述了预测统计的目标值。
概率(probability):它描述预测统计的目标值的概率值。
标准误差(standardError):它描述了标准误差的预测数值。
样例pmml
LR.pmml
<?xml version="1.0"?>
<PMML version="4.3" xmlns="http://www.dmg.org/PMML-4_3" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.dmg.org/PMML-4_3 http://www.dmg.org/pmml/v4-3/pmml-4-3.xsd">
<Header copyright="Copyright (c) 2017 liaotuo" description="Generalized Linear Regression Model">
<Extension name="user" value="liaotuo" extender="Rattle/PMML"/>
<Application name="Rattle/PMML" version="1.4"/>
<Timestamp>2017-07-11 13:18:36</Timestamp>
</Header>
<DataDictionary numberOfFields="4">
<DataField name="am" optype="continuous" dataType="double"/>
<DataField name="cyl" optype="continuous" dataType="double"/>
<DataField name="hp" optype="continuous" dataType="double"/>
<DataField name="wt" optype="continuous" dataType="double"/>
</DataDictionary>
<GeneralRegressionModel modelName="General_Regression_Model" modelType="generalizedLinear" functionName="regression" algorithmName="glm" distribution="binomial" linkFunction="logit">
<MiningSchema>
<MiningField name="am" usageType="predicted"/>
<MiningField name="cyl" usageType="active"/>
<MiningField name="hp" usageType="active"/>
<MiningField name="wt" usageType="active"/>
</MiningSchema>
<Output>
<OutputField name="Predicted_am" feature="predictedValue"/>
</Output>
<ParameterList>
<Parameter name="p0" label="(Intercept)"/>
<Parameter name="p1" label="cyl"/>
<Parameter name="p2" label="hp"/>
<Parameter name="p3" label="wt"/>
</ParameterList>
<FactorList/>
<CovariateList>
<Predictor name="cyl"/>
<Predictor name="hp"/>
<Predictor name="wt"/>
</CovariateList>
<PPMatrix>
<PPCell value="1" predictorName="cyl" parameterName="p1"/>
<PPCell value="1" predictorName="hp" parameterName="p2"/>
<PPCell value="1" predictorName="wt" parameterName="p3"/>
</PPMatrix>
<ParamMatrix>
<PCell parameterName="p0" df="1" beta="19.7028827927103"/>
<PCell parameterName="p1" df="1" beta="0.487597975045672"/>
<PCell parameterName="p2" df="1" beta="0.0325916758086386"/>
<PCell parameterName="p3" df="1" beta="-9.14947126999654"/>
</ParamMatrix>
</GeneralRegressionModel>
</PMML>
rule.pmml
<RuleSetModel modelName="RiskEval" functionName="classification" algorithmName="RuleSet">
<MiningSchema>
<MiningField name="var973" usageType="active" invalidValueTreatment="asMissing" missingValueReplacement="0"/>
<MiningField name="var969" usageType="active" invalidValueTreatment="asMissing" missingValueReplacement="0"/>
<MiningField name="var20" usageType="active" invalidValueTreatment="asMissing" missingValueReplacement="0"/>
<MiningField name="var393" usageType="active" invalidValueTreatment="asMissing" missingValueReplacement="0"/>
<MiningField name="var868" usageType="active" invalidValueTreatment="asMissing" missingValueReplacement="0"/>
<MiningField name="var543" usageType="active" invalidValueTreatment="asMissing" missingValueReplacement="0"/>
<MiningField name="var1213" usageType="active" invalidValueTreatment="asMissing" missingValueReplacement="0.0"/>
<MiningField name="flg" usageType="target"/>
</MiningSchema>
<RuleSet defaultScore="0">
<RuleSelectionMethod criterion="firstHit"/>
<SimpleRule id="RULE1" score="1" confidence="1">
<CompoundPredicate booleanOperator="or">
<SimplePredicate field="var973" operator="greaterOrEqual" value="1"/>
<SimplePredicate field="var969" operator="greaterOrEqual" value="1"/>
<SimplePredicate field="var20" operator="greaterOrEqual" value="7"/>
<CompoundPredicate booleanOperator="and">
<SimplePredicate field="var393" operator="greaterOrEqual" value="2"/>
<SimplePredicate field="var543" operator="notEqual" value="1"/>
</CompoundPredicate>
<CompoundPredicate booleanOperator="and">
<SimplePredicate field="var868" operator="greaterOrEqual" value="1"/>
<SimplePredicate field="var1213" operator="lessThan" value="0.8"/>
</CompoundPredicate>
</CompoundPredicate>
</SimpleRule>
</RuleSet>
</RuleSetModel>
相关链接
PMML 官网:http://dmg.org/pmml/v4-1/GeneralStructure.html
---------------------
作者:Clannad_汐
来源:CSDN
原文:https://blog.csdn.net/c1481118216/article/details/78411200
版权声明:本文为博主原创文章,转载请附上博文链接!
模型标准化——预测模型标记语言(PMML)的更多相关文章
- CoffeeScript及相关文本标记语言
粗步看了下CoffeeScript(简称cs),发现cs这玩意还是有些问题,当然最大的问题之一是缺乏称手的工具.要是能放VS里编译调试当然好.但是转来转去的,真不如直接多敲几个JS字符串. 问题之二就 ...
- Markdown轻量级标记语言
1. Markdown是什么? Markdown是一种轻量级标记语言,它以纯文本形式(易读.易写.易更改)编写文档,并最终以HTML格式发布.Markdown也可以理解为将以MARKDOWN语言编写的 ...
- java XML(可扩展标记语言)
XML 是EXtensible Markup Language的缩写,它是一种类似于HTML的标记语言,称为可扩展标记语言,传输数据而不是显示数据,可以自定义标签,具有自我描述性是一种通用的数据交换格 ...
- Markdown与标记语言
Markdown 是一种轻量级的「标记语言」,它的优点很多,目前也被越来越多的写作爱好者,撰稿者广泛使用.看到这里请不要被「标记」.「语言」所迷惑,Markdown 的语法十分简单.常用的标记符号也不 ...
- 面向内容的标记语言--markdonw
引言: 我们习惯用html来展示数据,尤其是结合了js以及css之后,更是让html变得非常的绚丽,可是有些时候在感受绚丽的同时,我们往往对我们本身想要了解的内容变得漠不关心了,其实并不是所有的知识都 ...
- html 超文本标记语言
1.html超文本标记语言 2.在html中存在着大量的标签,我们用html中存在的标签将要显示在网页的内容包含起来. 3.css 控制网页显示内容的效果. 4.html+css 只能是静态网页. 5 ...
- XML 概述 (可扩展标记语言)
XML:eXtensible Markup Language 可扩展标记语言 概念:可扩展:xml中所有的标签都是自定义的.没有预定义的. 功能: 存储数据 ...
- HTML标记语言篇--学习笔记01
HTML标记语言篇 第1章 HTML基础 1.1 基本概念 WWW 是"World Wide Web"(全球广域网)的缩写,简称为Web,中文又称为"万维网" ...
- Razor标记语言介绍
什么是Razor? Razor的中文意思是"剃刀",它不是编程语言,只是一种服务器段的标记语言,与PHP和ASP类似 Razor允许你向网页中嵌入基于服务器的代码(Visu ...
随机推荐
- 【LOJ】#2548. 「JSOI2018」绝地反击
题解 卡常卡不动,我自闭了,特判交上去过了 事实上90pts= = 我们考虑二分长度,每个点能覆盖圆的是一段圆弧 然后问能不能匹配出一个正多边形来 考虑抖动多边形,多边形的一个端点一定和圆弧重合 如果 ...
- flask 封装
#!/bin/env python# _*_coding:utf-8_*_#!!!!!!!!!!!!describe:this script shoud install python-devel an ...
- University Entrace Examination zoj1023
学校招收学生 优先级按照: 分数 是否本地 志愿先后 相当于 女的开后宫 对gs进行略微修改 结束的条件为每个男的表白完所有女的 第二部分比较时 找出女的后宫里的吸引力最弱的男的比较 ...
- Mysql介绍,与将脚本导入新数据库
一:介绍 1.介绍 Mysql是最流行的关系型数据库管理系统,在WEB应用方面MySQL是最好的RDBMS(Relational Database Management System:关系数据库管理系 ...
- s3fs挂s3作为本地盘制作ftp使用
一. 安装s3fs 安装s3fs-fuserhttps://github.com/s3fs-fuse/s3fs-fuse 二. 安装vsftpd #查看当前系统版本cat /etc/redhat-re ...
- Odoo访问权限(一)
Odoo访问权限(一) 四个ODOO权限管理层次 一. Odoo 菜单级别: 即,不属于指定菜单所包含组的用户看不到该菜单.不安全,只是隐藏菜单,若用户知道菜单ID,仍然可以通过指定URL访问 二. ...
- 链表用途&&数组效率&&链表效率&&链表优缺点
三大数据结构的实现方式 数据结构 实现方式 栈 数组/单链表 队列 数组/双端链表 优先级队列 数组/堆/有序链表 双端队列 双向链表 数组与链表实现方式的比较 数组与链表都很快 如果能精确预测栈 ...
- MD Test
欢迎使用 MWeb XXX ``` ZFCollectionViewListController.m <script src="https://blog-static.cnblogs. ...
- android listView 点两下才监听到
因为 对应的控件设置了 android:focusableInTouchMode="true" 意思是 触摸模式下 点击第一次 是 获得焦点.===
- Maven入门指南② :Maven 常用命令,手动创建第一个 Maven 项目
1.根据 Maven 的约定,我们在D盘根目录手动创建如下目录及文件结构: 2.打开pom.xml文件,添加如下内容: <project xmlns="http://maven.apa ...