HBase原理和架构
HBase是什么

HBase在生态体系中的位置
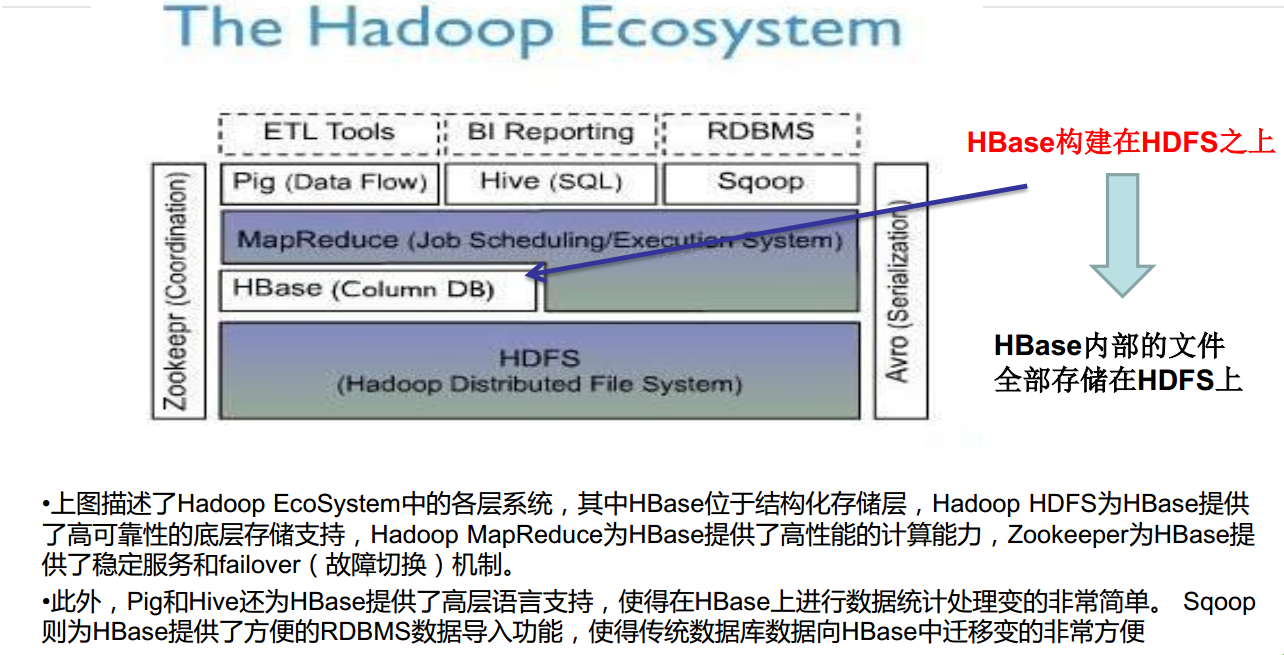
HBase vs HDFS

HBase表的特点

HBase是真正的分布式存储,存储级别达到TB级别,而才传统数据库就不是真正的分布式了,传统数据库在底层,虽然的存储能力很强,一旦达到上亿条数据。读取性能下降得很快。
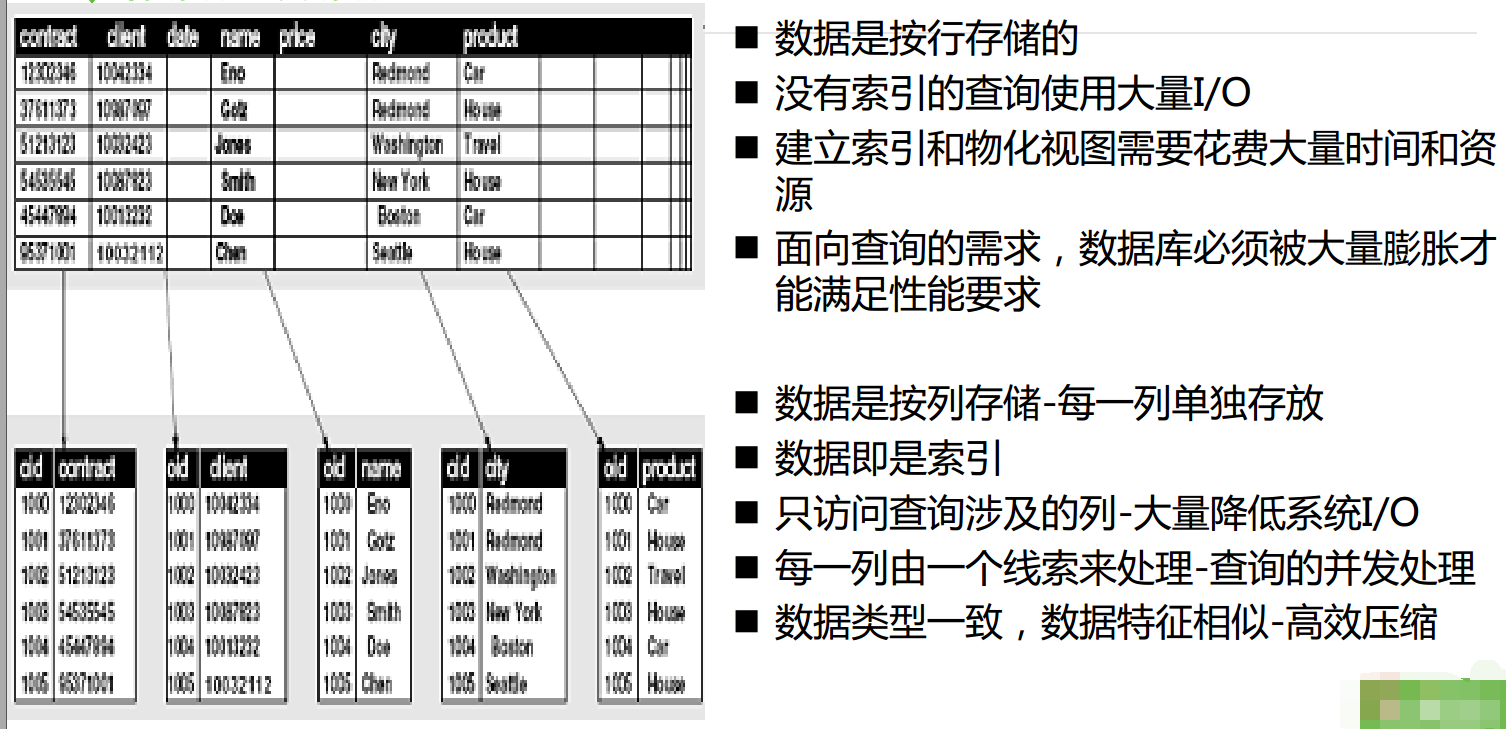
传统数据库按行存储,如果列过多的话,一行数据会非常大,HBase按列簇存储,每个列簇都存储一个文件,如果只读取某一些字段的话,只需读取对应的文件就可以了,其他的不用扫描,节省了IO。
HBase的存储每一行的内容可以不同,空出来的列不占用空间。
多版本,怎么理解呢,就比如说相同id的行重新插入数据不会覆盖掉,而是按照插入的时间戳分类。
行存储和列存储
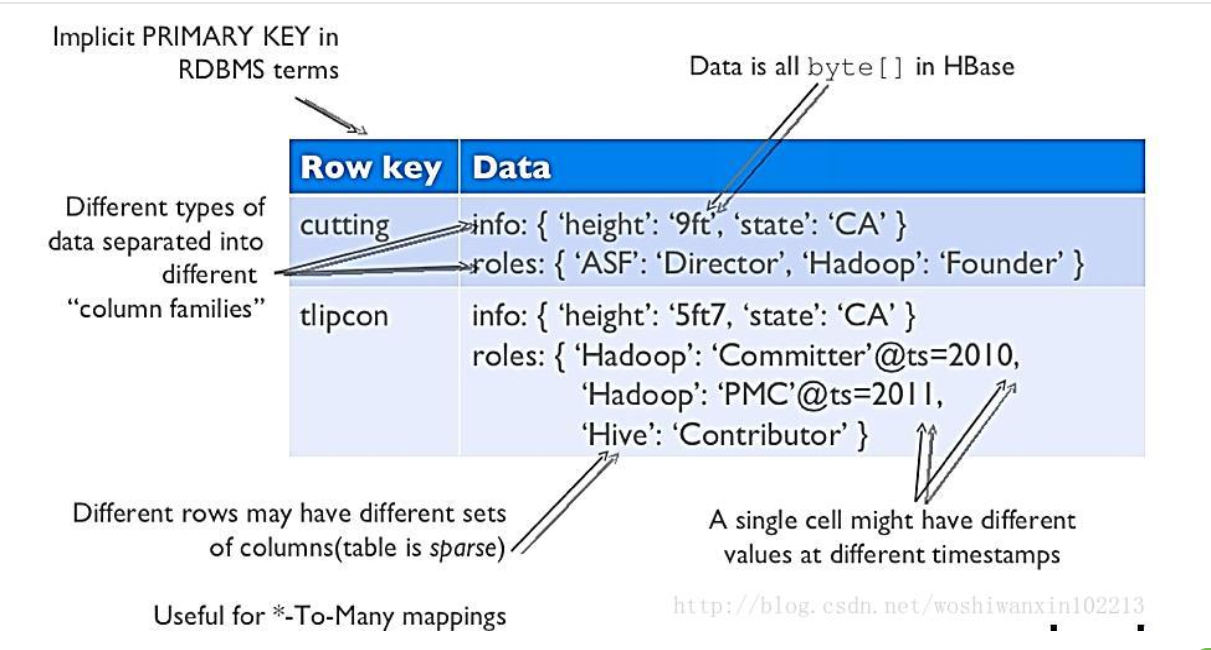
02 HBase数据模型
HBase逻辑视图
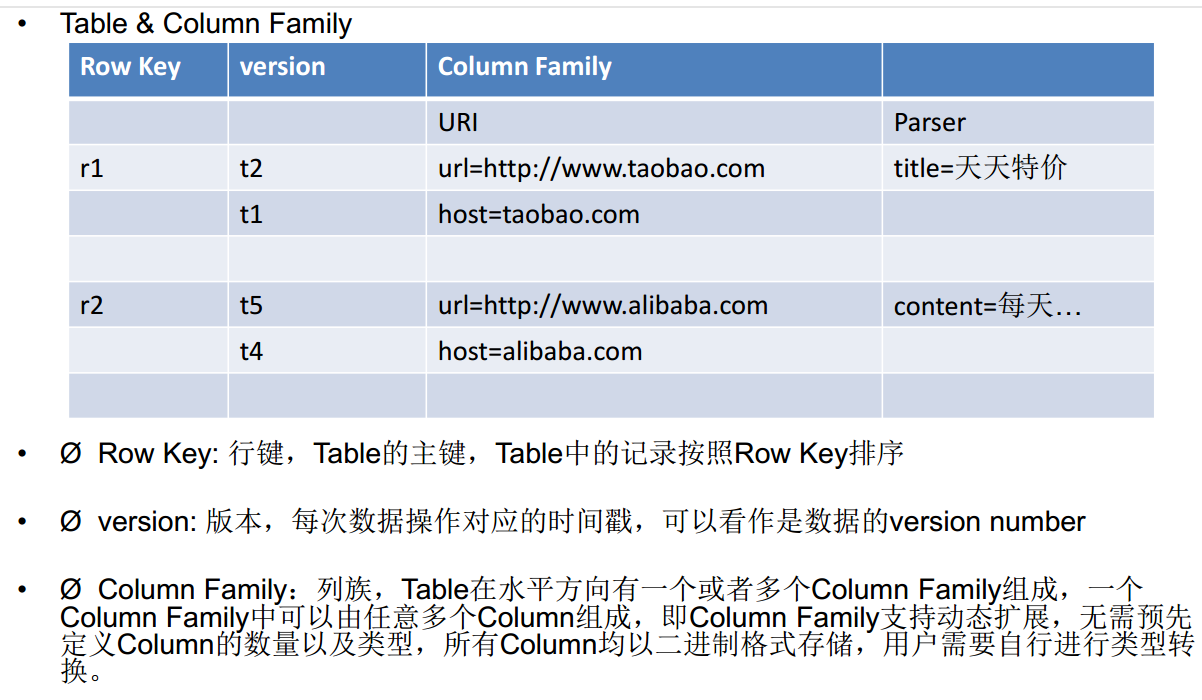
Rowkey和Column Family
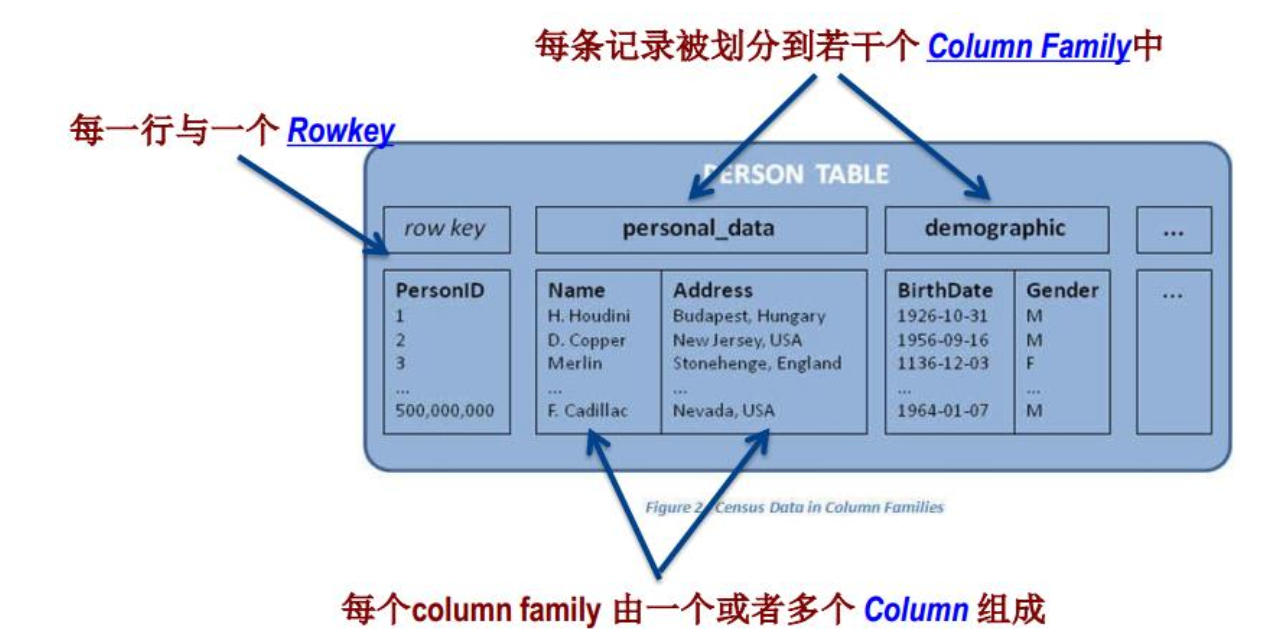
HBase数据模型

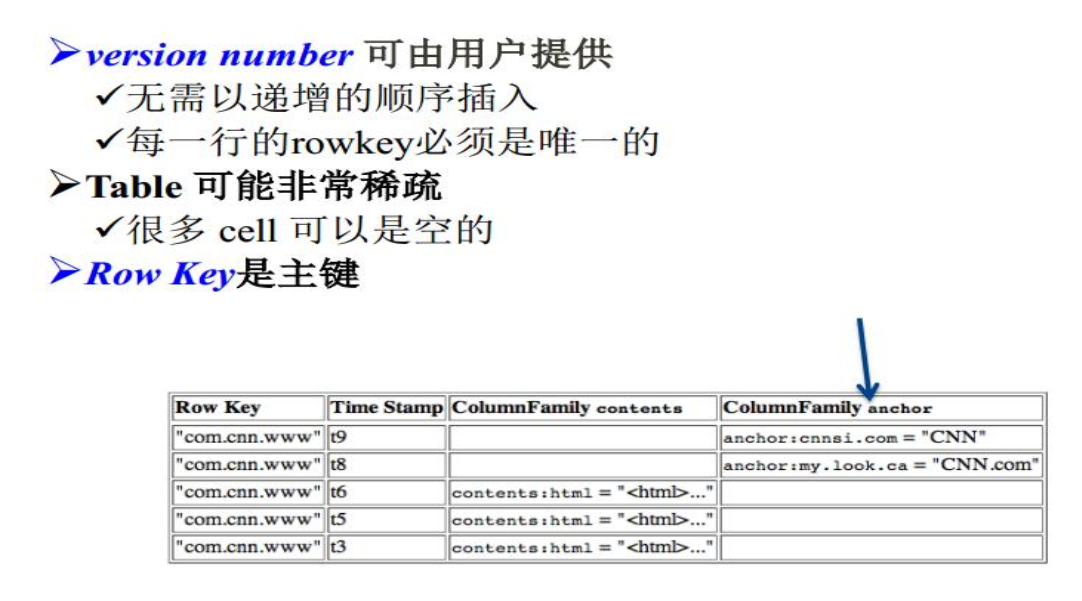
HBase支持的操作

03 HBase物理模型

传统数据库和HBase的存储的不同


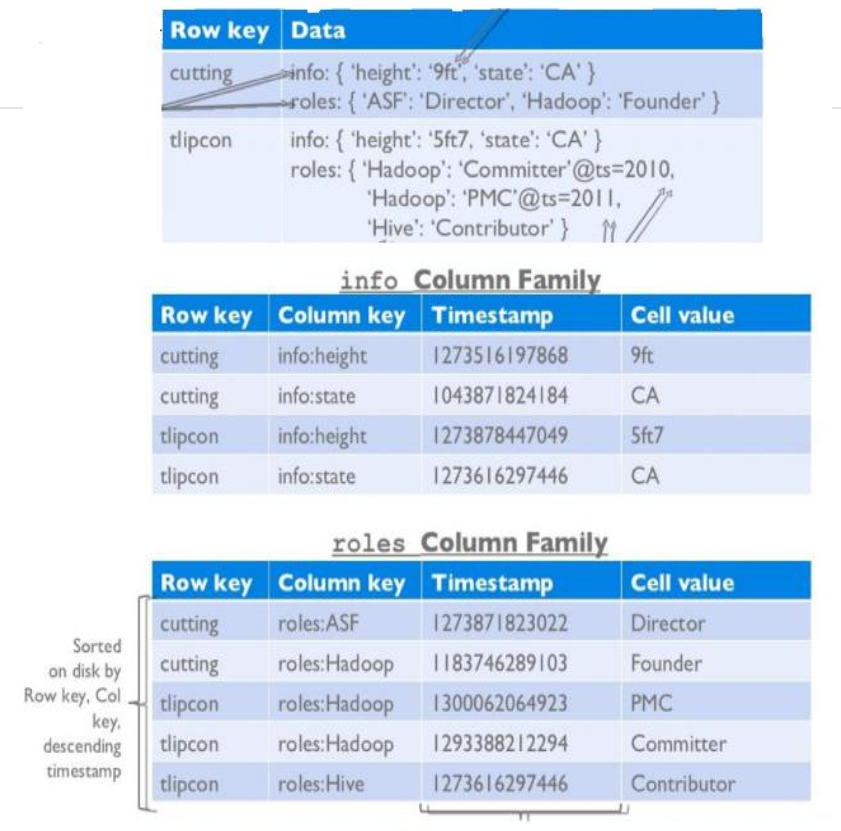
物理存储
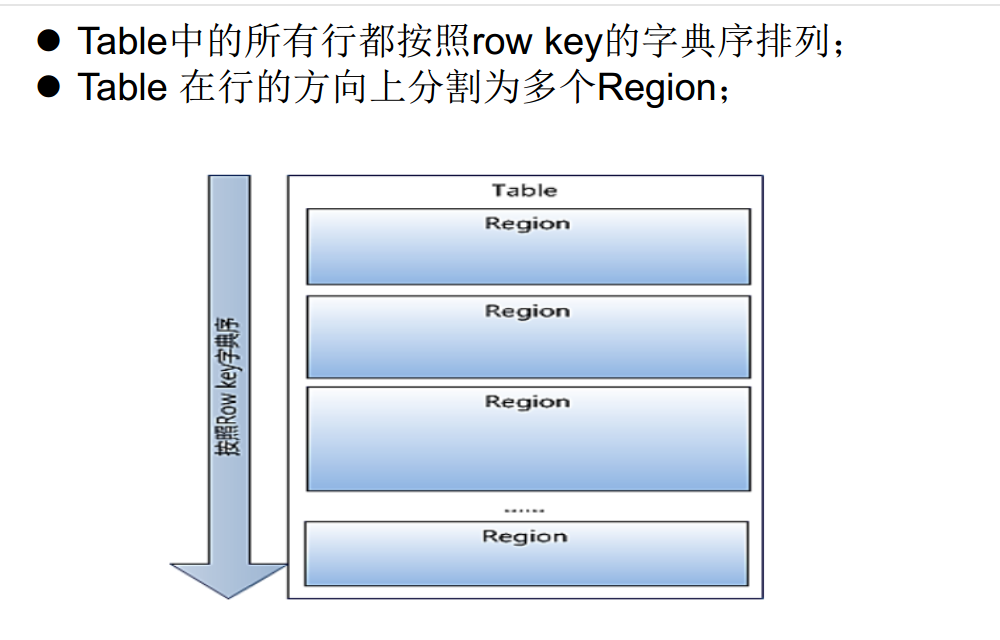
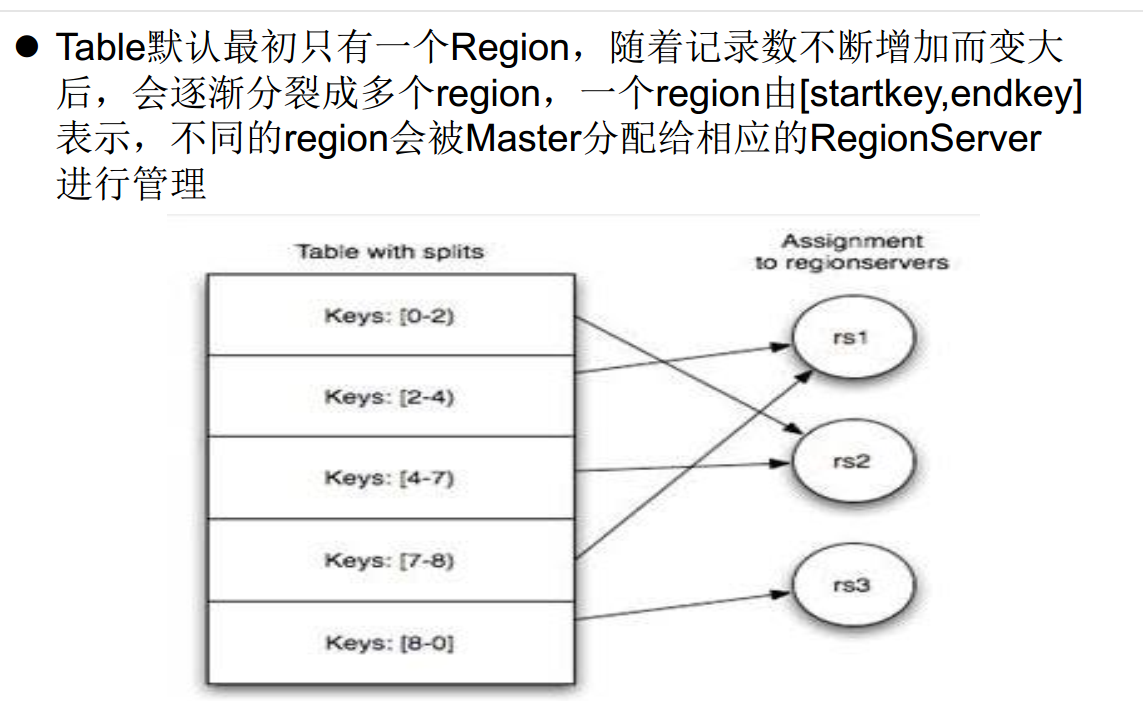
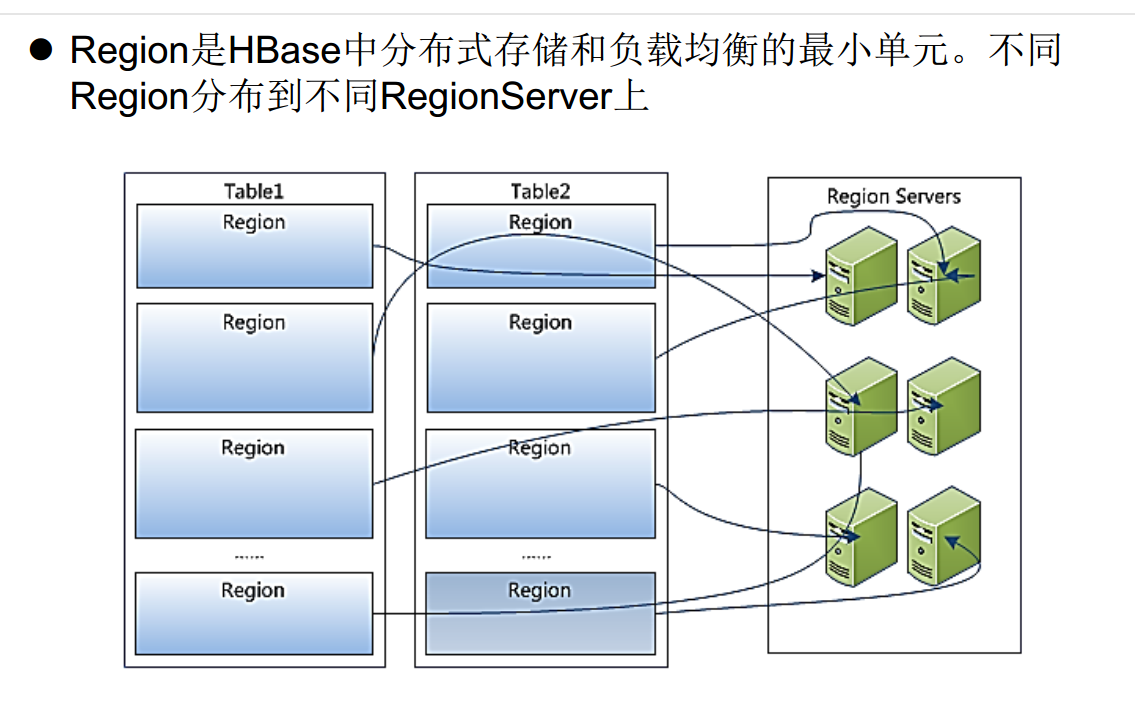
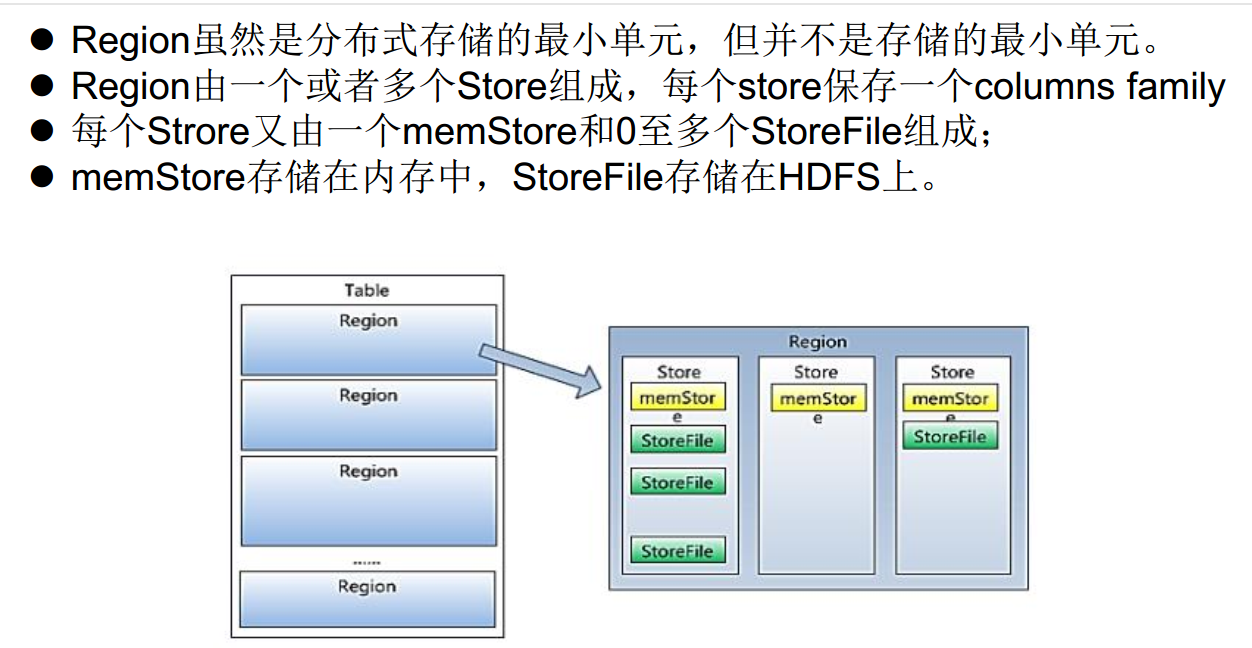
Table vs Region
04 HBase系统架构
架构图
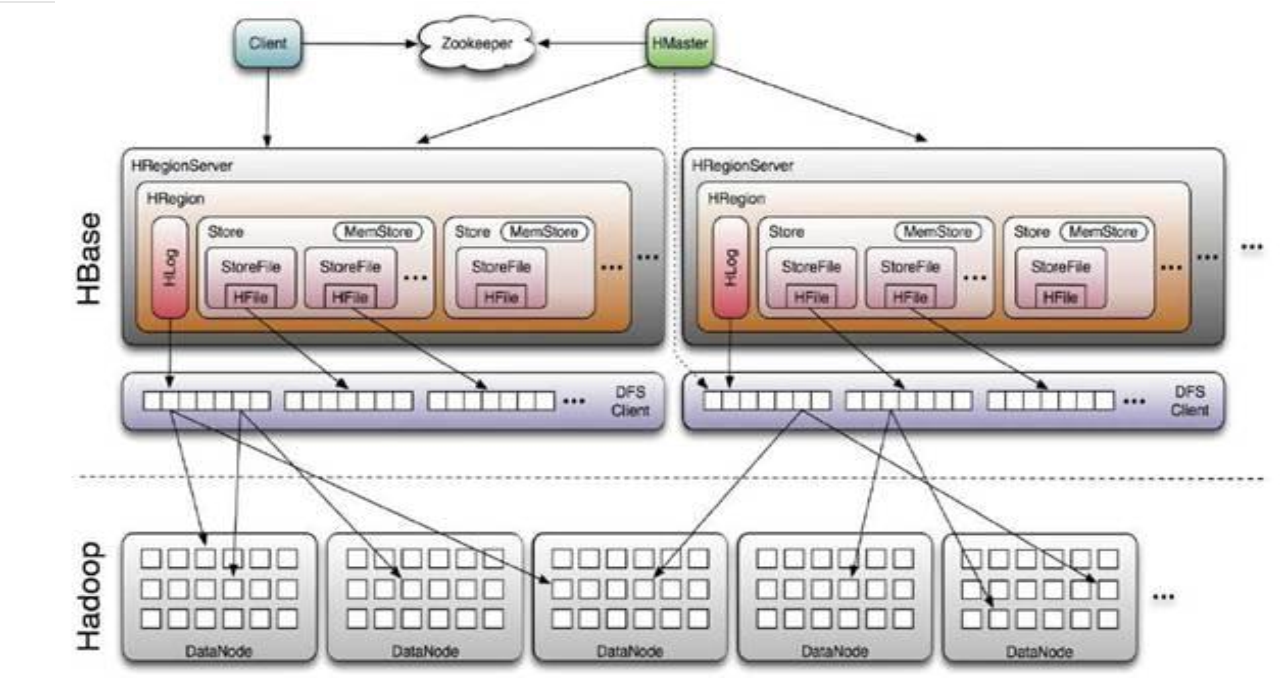
HBase基本组件

HBase工作流程

Hbase Write-Ahead-Log(预先写日志)
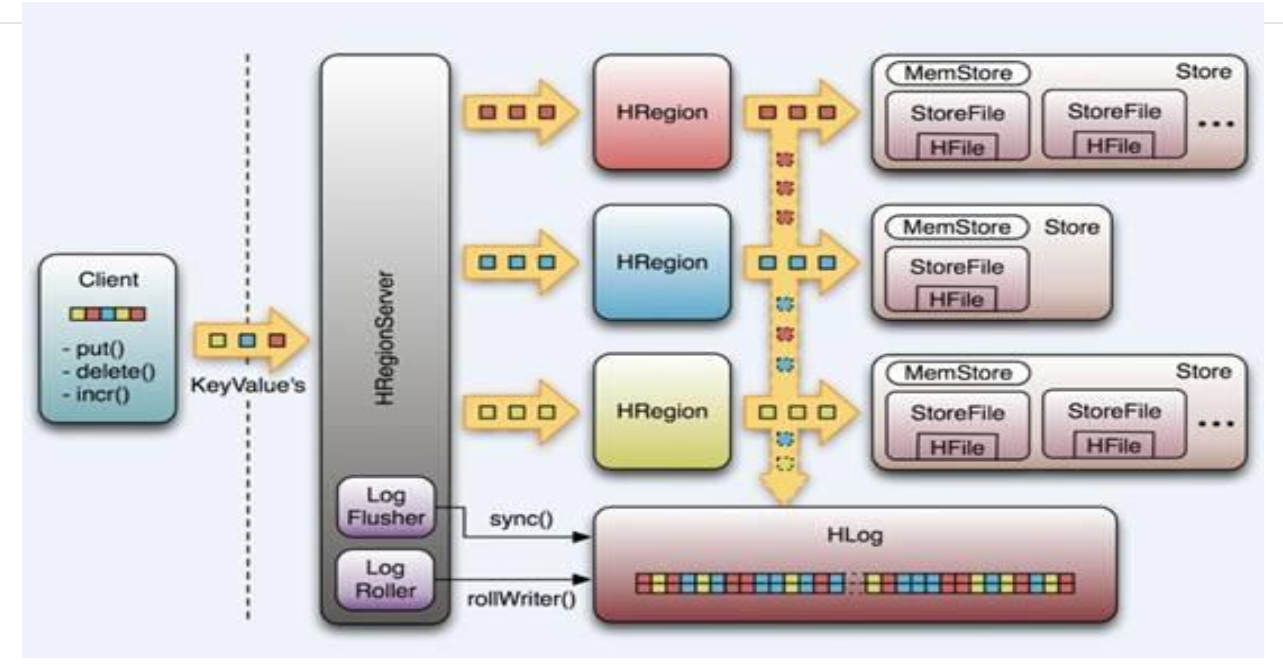
Regionserver结构

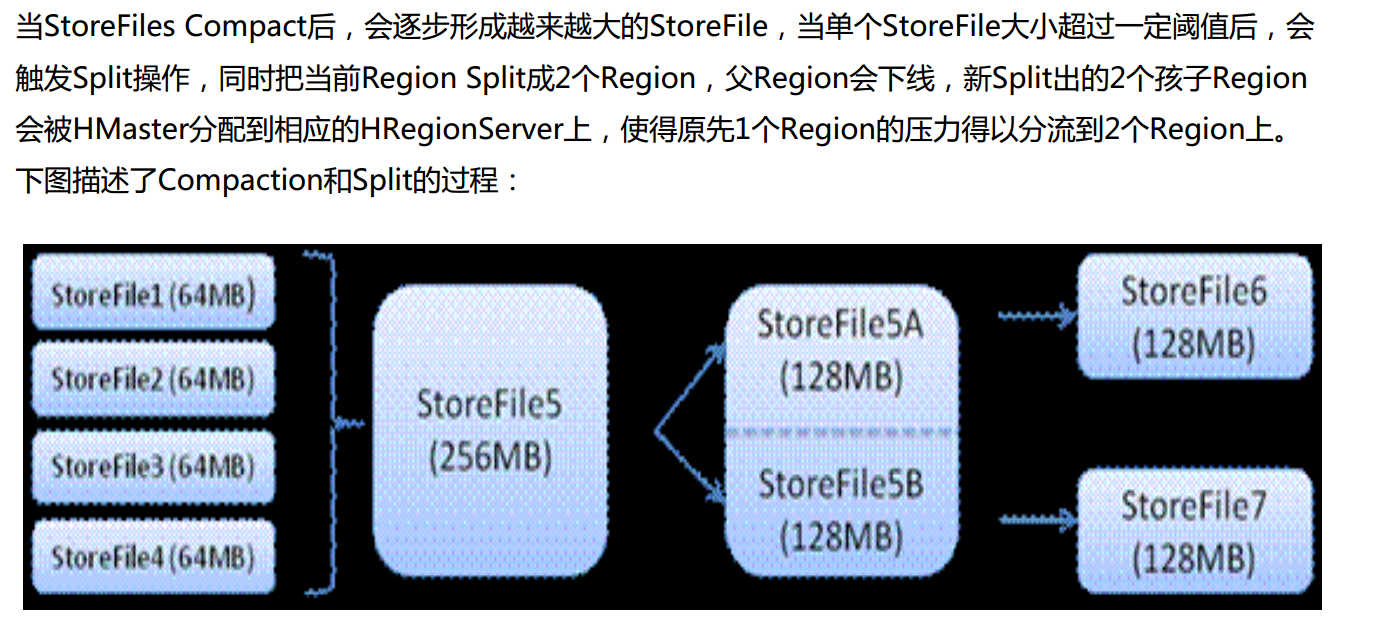
HBase Compact && Split
HLog Replay

Hfile存储格式
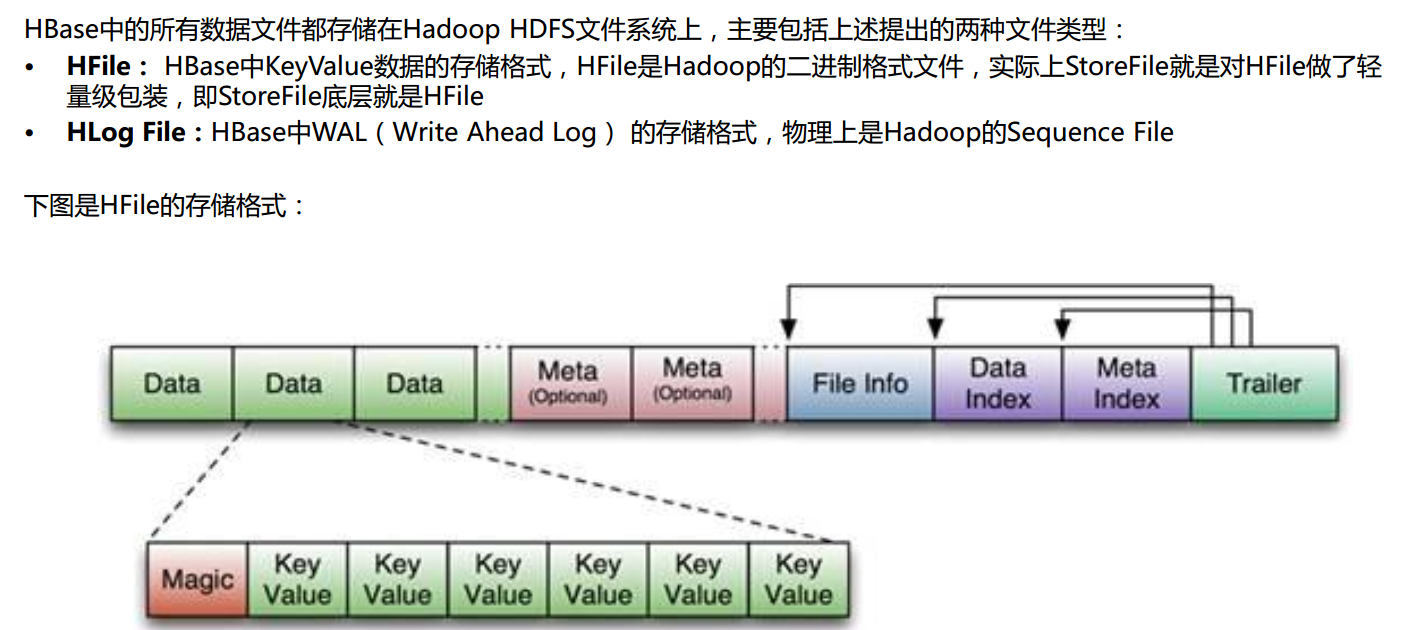
Hfile存储格式(续)

Keyvalue格式

Hlog存储格式
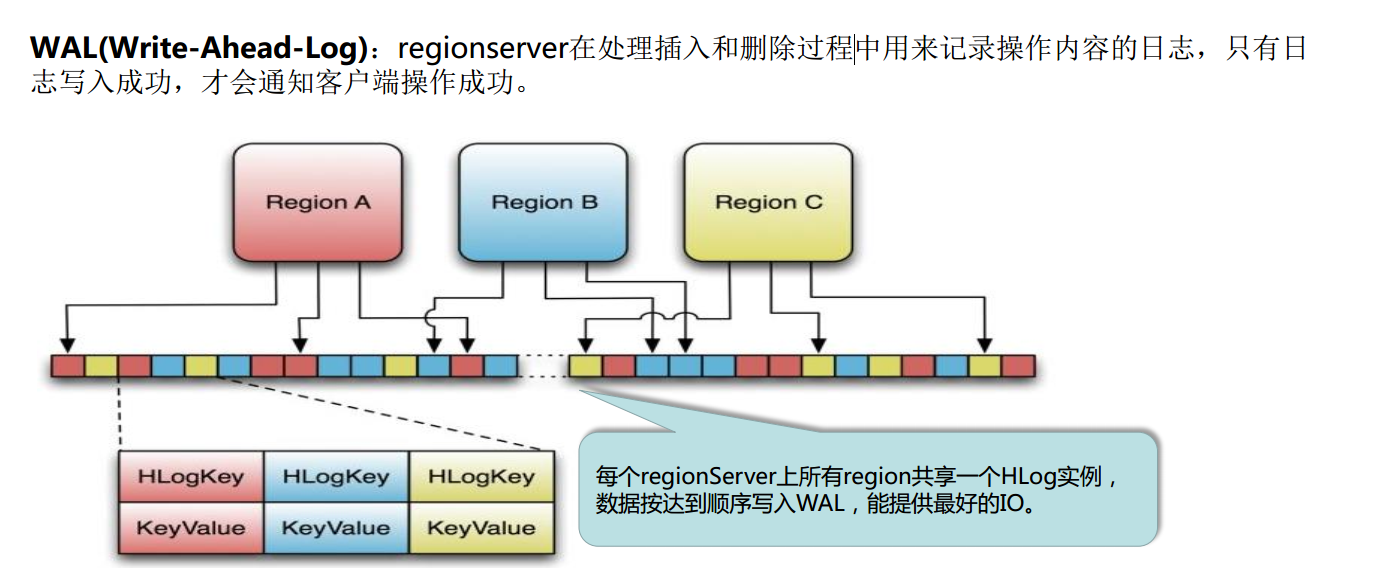
HLog存储格式(续)

HBase高可用
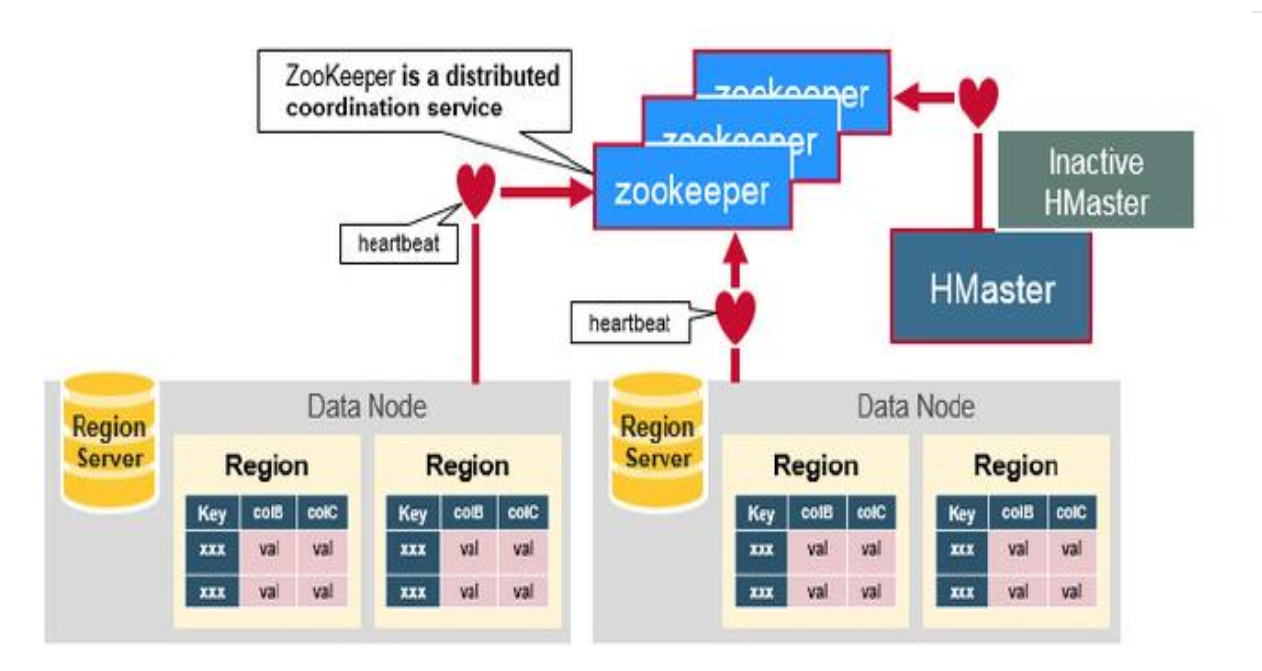
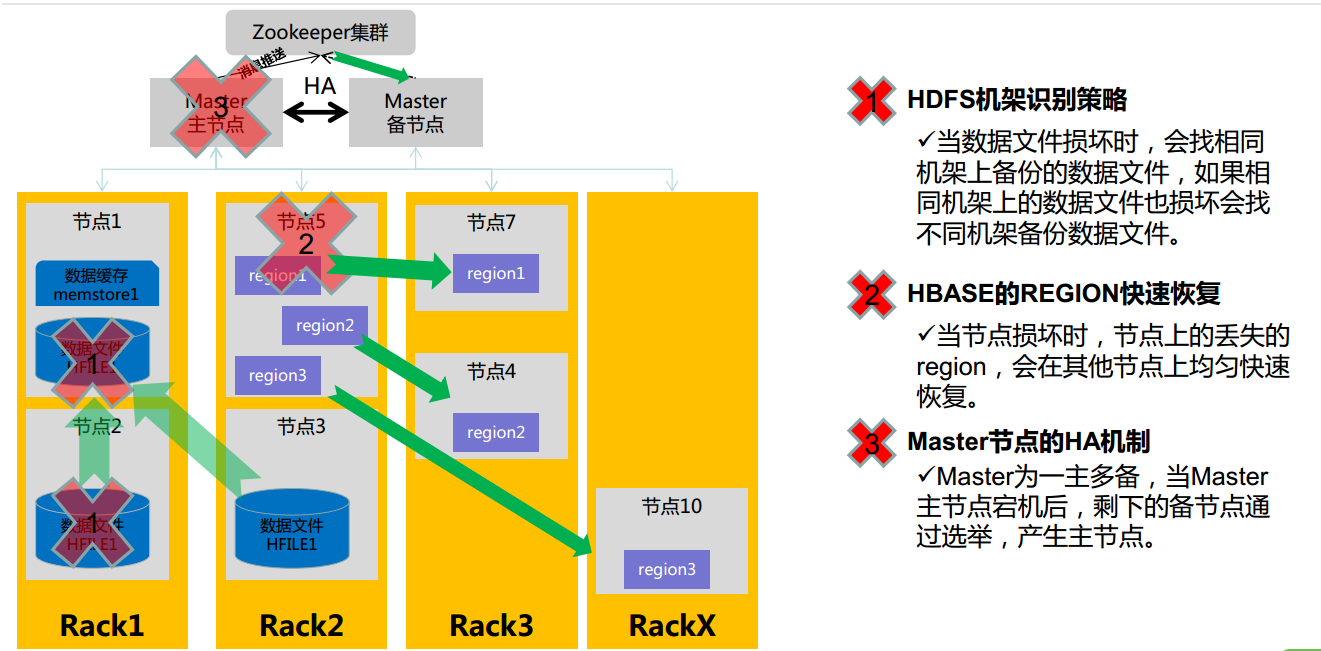
HBase容错性

Region定位

先访问zookeeper,找到root表的位置,root表记录了meta表的位置,在meta表里面查找对应的rowkey查找所在的region,并获取用户region的位置
-ROOT-和.META.表结构

如果是root表,表名就是.meta。如果是meta表,表名就是用户的id 订单等等。
-ROOT-表和.META


Hbase 读流程
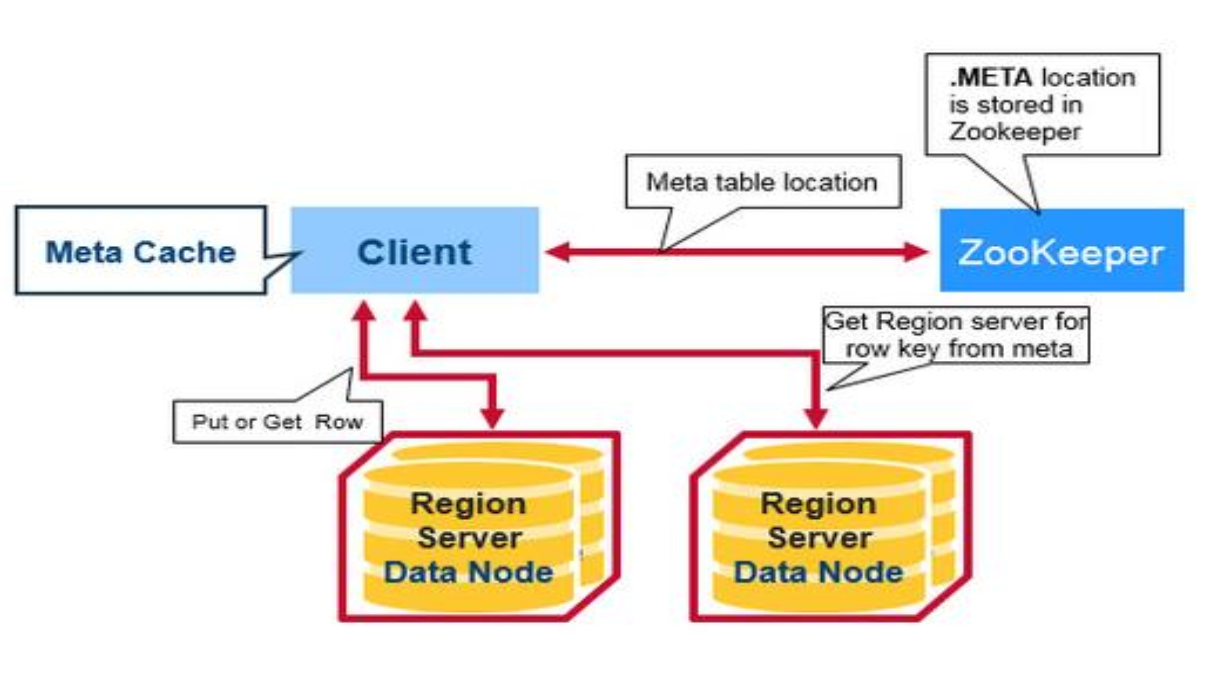
Client客户端先找到zookeeper拿到meta表,meta表根据rowkey拿到相应的region信息,找到对应的regionsever
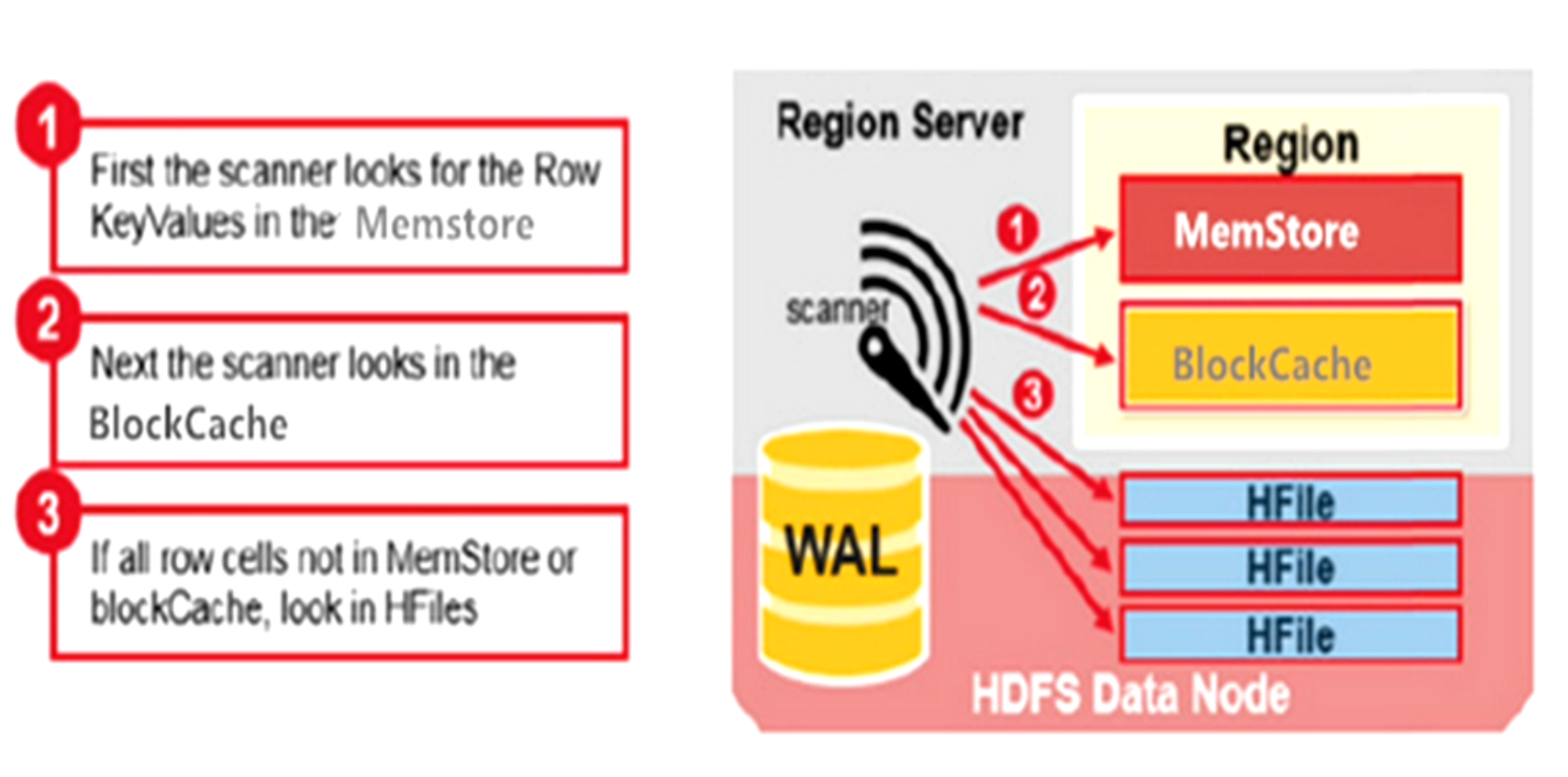
1.memstore是写缓存,blockcache是读缓存。
2.读数据的时候先到写缓存memstore去读,这样能提高读的效率,当memstore没有了,才到读缓存blockcache读数据。如果上面两个缓存(属于内存)都没有的情况下,就到磁盘去读。
3.在读到磁盘的时候去查找相应的数据,在没找到之前把前面的hfile放到blockcache读缓存里面,因为blockcache的空间也是有限的,如果blockcache读满了还没有找到需要查询的数据,blockcache就会淘汰一部分数据。
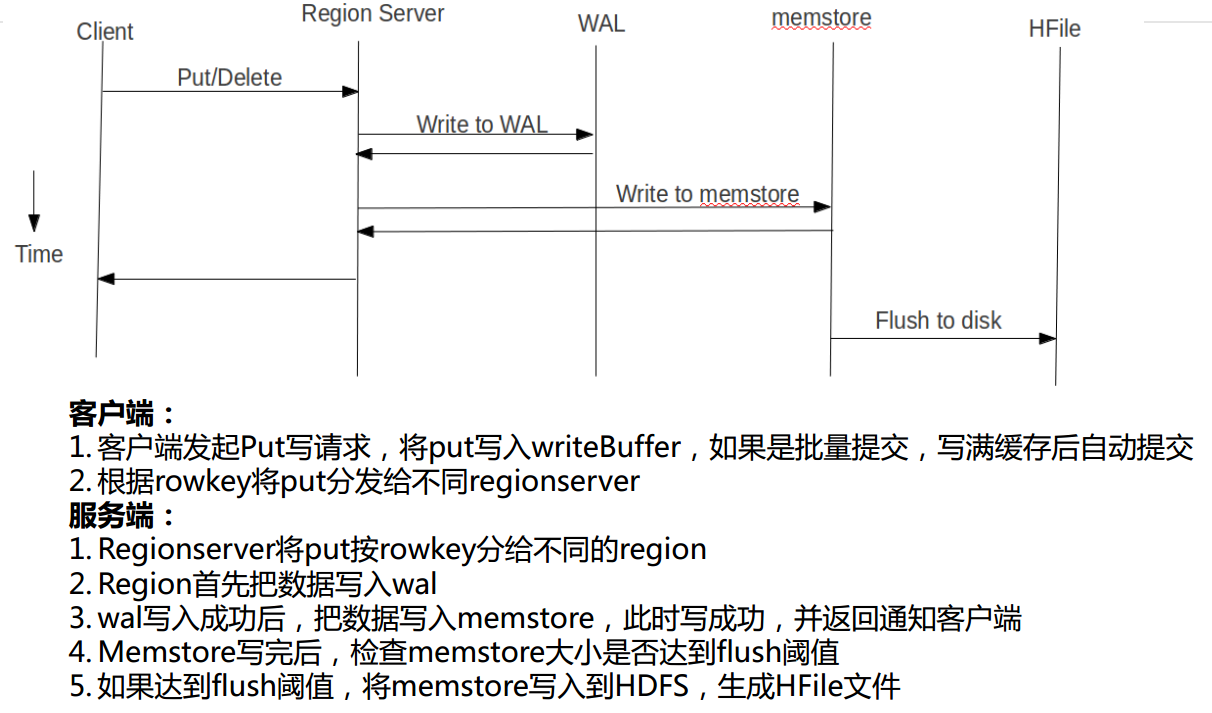
HBase put写流程
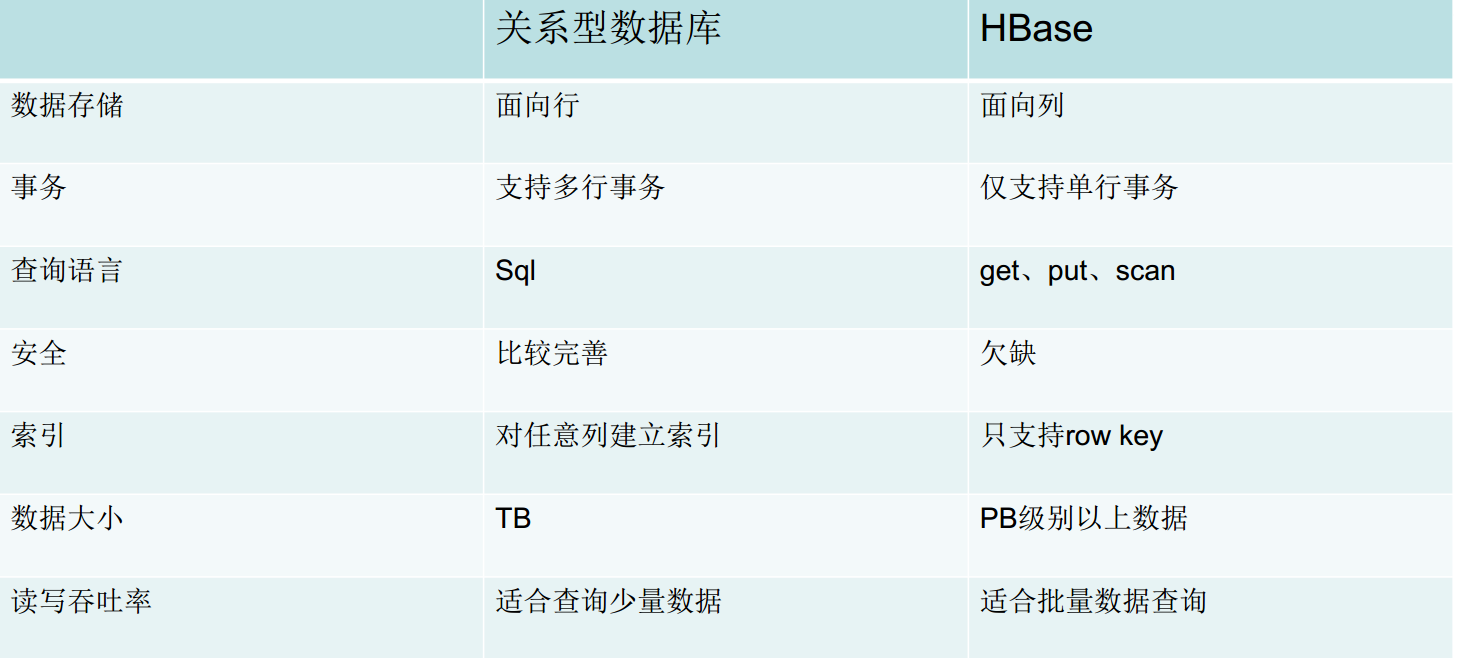
Hbase VS 关系型数据库
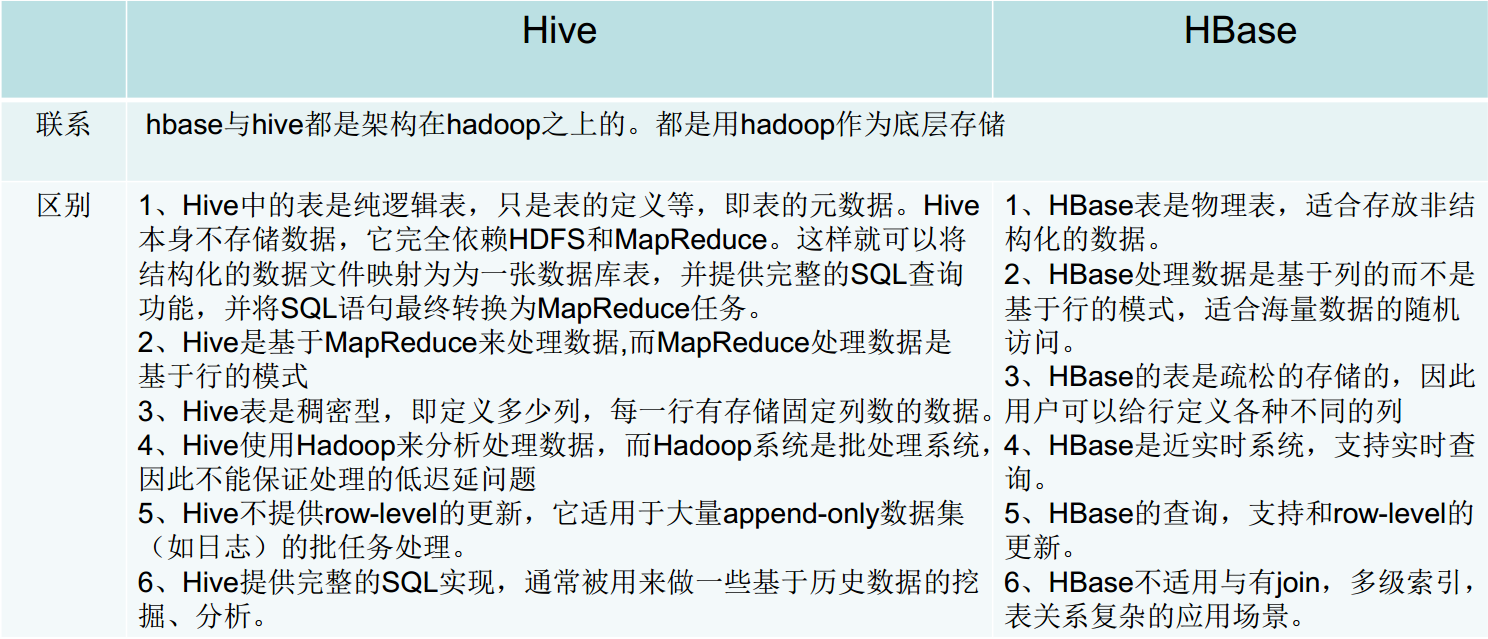
Hbase VS Hive

HBase原理和架构的更多相关文章
- HBase的基本架构及其原理介绍
1.概述:最近,有一些工程师问我有关HBase的基本架构的问题,其实这个问题仅仅说架构是非常简单,但是需要理解.在这里,我觉得可以用HDFS的架构作为借鉴.(其实像Hadoop生态系统中的大部分组建的 ...
- Zookeeper概论(对zookeeper的概论、原理、架构等的理解)
Zookeeper概论(对zookeeper的概论.原理.架构等的理解) 一.概论 Zookeeper是一个分布式的.开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是h ...
- 【转】HBase原理和设计
简介 HBase —— Hadoop Database的简称,Google BigTable的另一种开源实现方式,从问世之初,就为了解决用大量廉价的机器高速存取海量数据.实现数据分布式存储提供可靠的方 ...
- Hbase原理
Hbase原理 概述 HBase是一个构建在HDFS上的分布式列存储系统:HBase是基于Google BigTable模型开发的,典型的key/value系统:HBase是Apache Hadoop ...
- HBase原理和设计
转载 2016年1月10日:http://www.sysdb.cn/index.php/2016/01/10/hbase_principle/ 简介 架构 数据组织 原理 RS定位 region写入 ...
- HBase原理、设计与优化实践
转自:http://www.open-open.com/lib/view/open1449891885004.html 1.HBase 简介 HBase —— Hadoop Database的简称,G ...
- 大数据技术之_11_HBase学习_01_HBase 简介+HBase 安装+HBase Shell 操作+HBase 数据结构+HBase 原理
第1章 HBase 简介1.1 什么是 HBase1.2 HBase 特点1.3 HBase 架构1.3 HBase 中的角色1.3.1 HMaster1.3.2 RegionServer1.3.3 ...
- HBase之一:HBase原理和设计
一.简介 HBase —— Hadoop Database的简称,Google BigTable的另一种开源实现方式,从问世之初,就为了解决用大量廉价的机器高速存取海量数据.实现数据分布式存储提供可靠 ...
- 1、Hbase原理分析
一.Hbase介绍 1.1.对Hbase的认识 HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随机读写操作,HBase正是为此而出现. HBase参考 Google 的 Bigtable ...
随机推荐
- sql查询:存在A表而不在B表中的数据
A.B两表,找出ID字段中,存在A表,但是不存在B表的数据. 方法一:使用 not inselect distinct A.ID from A where A.ID not in (select ID ...
- java-常用注解
JDK自带注解 @Override 重写, 标识覆盖它的父类的方法 @Deprecated 已过期,表示方法是不被建议使用的 @Suppvisewarnings 压制警告,抑制警告 元注解 @Ta ...
- 运用MQTT-JMeter插件测试MQTT服务器性能
今天我们介绍XMeter团队带来的新版MQTT-JMeter插件,您可以更为方便地添加MQTT连接.发布.订阅取样器,构造组合的应用场景,例如背景连接.多发少收.少发多收,计算消息转发时延等.利用该插 ...
- Jmeter使用流程及简单分析监控
本文摘自:一颗糖果 https://www.cnblogs.com/linglingyuese/archive/2013/03/04/linglingyuese-one.html 1.下载Jmet ...
- 让邮件服务器发出的Email不被认为是垃圾邮件
配置一个Email服务器很简单,用Postfix等软件稍微配置一下就可以了,几分钟搞定. 但Email服务器发出去的Email很可能经常被人当成垃圾邮件,怎么配置Email服务器才能让Email服务器 ...
- mysql_test
------------------ #/bin/sh binlogfile=$1 if [ ! -n $binlogfile ]thenecho "pls input your mysql ...
- 开IE时 暴卡
待打开IE后,在“工具”-“管理加载项”中禁用所有加载项.
- mysqlli 的基本用法
Mysqli是php5之后才有的功能 需要修改php.ini的配置文件 查找下面的语句: ;extension=php_mysqli.dll 将其修改为:extension=php_mysqli.dl ...
- leedcode_贪心算法系列
861. 翻转矩阵后的得分 思路: 行首的权值最大,故首先将其置1; 每列由于权值相同,故只需要将0多于1的情况反转即可 763. 划分字母区间 思路: 1.计算每个字母的最右边界下标,并记录到新数组 ...
- Mongo查询分组
db.test.aggregate( {'$match':{"url":/http:\/\/www.baidu.cn\/member\/T107581\//}}, {'$group ...