Python自动化开发 - 字符编码、文件和集合
本节内容
| 一、字符编码 |
1、编码
计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。解决思路:数字与符号建立一对一映射,用不同数字表示不同符号。
ASCII(American Standard Code for Information Interchange, 美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
每个bit 有两种状态 0和1,ASCII码使用指定的8位二进制数组合来表示256种可能的字符
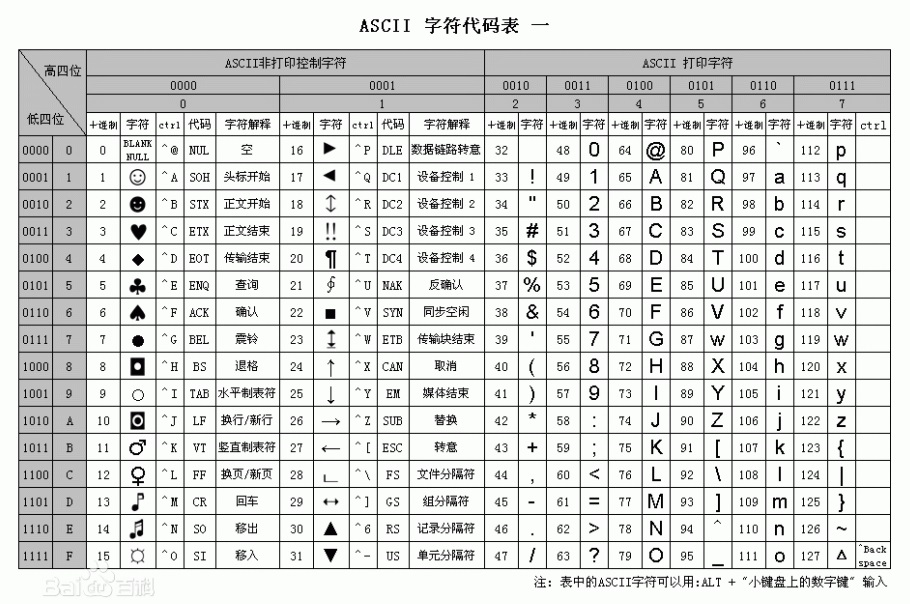
大小规则
1) 数字0-9比字母要小, 如"7" < "F";
2) 数字0比数字9要小,并按0到9顺序递增, 如"3" <"8";
3) 字母A比字母Z要小,并按A到Z顺序递增, 如"A" < "Z";
4) 同个字母的大写字母比小写字母要小,如 "A" <" a";
常用ASCII 十进制 "0" = 48、"A"= 65、"a"= 97
中文编码
8为的ASCII能表示的最大整数255,也就是大小写英文字母、数字和一些符号。如果要表示更大的整数,就必须用更多的字节,如两个字节。
为了处理汉字,中国设计了用于简体中文的GB2312和用于繁体中文的big5
发展过程 GB2312(7445个字符) -- GBK(21886个字符) -- GB18030(27484个字符),属于双字节字符集
Windows缺省内码GBK
万国码
Unicode(统一码、万国码、单一码)为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定最少由16位(2个字节)。Python3支持Unicode编码
UTF-8
如果文本全是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
Unicode编码优化压缩为UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,
ASCII码中的内容用1个字节保存
欧洲的字符用2个字节保存
东亚的字符用3个字节保存
| 字符 | ASCII | Unicode | UTF-8 |
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | -- | 01001110 00101101 | 11100100 10111000 10101101 |
在UTF-8编码中,ASCII编码实际上可以被看成是UTF-8编码的一部分。所以大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现)
2、Python2.x编码
Python2.x 默认编码为ASSIC, 1989年,先于1991年出现的unicode编码
# -*- coding:utf-8-*- 告诉py的解释器,后面的代码请用utf-8来来解释,对Python2.x非常重要
Python2.x中 UTF-8与GBK相互转换如下图所示

Python2.x 示例
|
msg = "中国" print msg gbk_str = msg.decode(encoding="utf-8").encode(encoding="gbk") print gbk_str print gbk_str.decode(encoding="gbk").encode("gb2312") print gbk_str.decode(encoding="gbk").encode("utf-8") pirnt gbk_str.decode(encoding="gbk") |
Python2 在windows解码是必须的,编码成gbk这个动作不是必须的
Python2 在linux(默认是utf8)上,如果是gbk-> utf8,解码是必须得,编码成utf-8这个动作不是必须的
所有的程序在内存里默认都是unicode
3、Pyhthon3.x编码
unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节),utf-16就是现在最常用的unicode版本, 传输或存储时用utf-8
Python 3.x 默认文件时 utf-8
Python3 也有两种数据类型:str和bytes,其中str类型存unicode数据,bytse类型存bytes数据
Python3 renamed the unicode type to str ,the old str type has been replaced by bytes.
解释器编码是 unicode,加载到内存后自动解码成unicode,同时,把字符转换成bytes格式
bytes = 8bit
Python2 str == python3 bytes
Python3 str == unicode
Python3 多出来的bytes格式是一个单独的类型
4、文件从磁盘到内存的编码
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
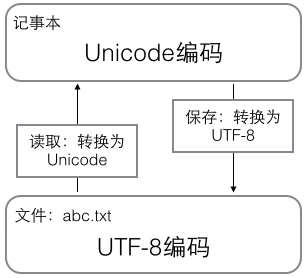
在文本编辑器编辑文字的时候,不管是中文还是英文,计算机都不认识,所以在内存中以unicode数据存在。无论中文、英文、日文、拉丁文,
世界上任何字符它都有唯一编码对应,所以兼容性是最好的。
在磁盘上存储数据的时候,是通过某种编码方式的bytes字节串,比如utf8,可变长编码,节省空间,还有gbk等等。文本编辑器软件都有默认的
保存文件的编码方式,比如utf8、gbk等等。当我们点击保存的时候,这些编辑软件已经“默默地”帮我们做了编码工作。
当我们再打开这个软件时,软件又默默地给我们做了解码工作,将数据再解码成unicode,然后就可以呈现明文给用户了。
unicode是离用户更近的数据,bytes是离计算机更近的数据。
那编码和程序执行有什么关系呢?
先明确一个概念:Python解释器本身就是一个软件,一个类似于文本编辑器一样的软件!
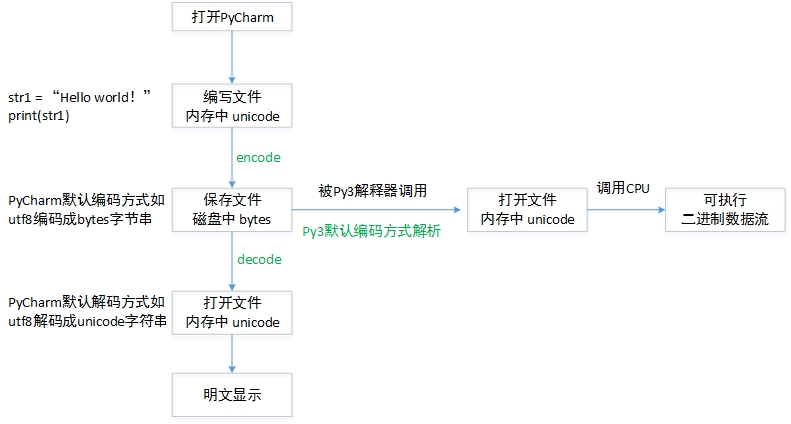
文本编辑器有自己默认的编码解码方式,解释器也有
|
import sys print sys.getdefaultencoding() # Python2 默认ascii print (sys.getdefaultencoding()) # Python3 默认utf-8 |
是否还记得开头这个声明
|
# -*- coding:utf-8 -*- |
如何Python2解释器去执行一个utf8编码的文件,就会默认地以ascii去解析utf8,一旦程序中有中文,自然就解码错了。
开头位置声明 # -*- coding:utf-8 -*-,其实就是告诉解释器,不要以默认的编码方式去解码这个文件,而是以utf8解析。
而Python3解释器默认utf8编码,就方便很多了。

| 二、文件操作 |
open() # encoding不声明,默认使用操作系统的编码来解释文件,如中文Windows的GBK
打开文件模式
r,只读模式(默认),不可写
w,只写模式(不可读;不存在则创建;存在则删除内容,更新为最新内容)
a,追加模式(可读;不存在则创建;存在则只追加内容)
"+"表示可同时读写某个文件
r+,追加 + 读,会覆盖光标后内容,除非定长修改,而 a模式只追加
w+ ,清空原文件,再写入新内容,可读
a+,追加读,从文件末尾
# 实际运用 r w a 较多
基本操作
|
f = open("text", encoding="utf-8", mode="r") # 读模式打开文件 first_line = f.readline() # 读第一行 second_line = f.readline() # 读第二行 lines = f.) # 读三行,返回值为列表 data = f.read() # 读剩下所有内容,文件大时不要用;read(n)有值时,读取相应字符 f.close() # 关闭文件 number = f.tell() # 返回光标所在第几个字节 f.seek() # 往后移动相应字节,如10字节 f.write("xxxxx\n") # 写数据到文件 f.flush # 内存数据更新到硬盘 f.fileno() # 操作系统维护的文件列表,文件描述符 |
| 三、集合 |
集合是一个无序不重复元素的序列。基本功能
去重,列表变集合,自动去重
关系测试,测试两组数据交集、并集、差集等关系
集合定义可以使用大括号{}或者set函数来创建集合
注意:创建一个空集合必须用 set() 而不是 {},因为 {} 是用来创建一个空字典
特性:去重、无序
|
# 定义集合 去重、无序 set1 = set({}) set2 = set([, , , ]) set3 = {, , , } set4 = ({, , , }) # 集合基本操作 set2.add() # 集合set2增加元素11 set2.remove() # 集合set2删除元素11 len(set4) # 返回集合set4长度 data in set4 # 判断元素data是否存在于集合set4之中 data not in set4 # 判断元素data是否不存在于集合set4之中 set3.issubset(set4) # 判断集合set3中每个元素是否都在集合set4中,即子集判断 set3.issuperset(set4) # 判断集合set3是否包含集合set4中每个元素,即父集判断 # 关系运算 a = {, , , , } b = {, , , , } # 交集,同时在集合a和集合b中的元素集合 print( a & b) print( a.intersection(b)) a.intersection_update(b) # 集合 a 更新为a与b交集 # 差集运算 a - b,只在集合a中,不在集合b中 print( a- b) print(a.difference(b)) a.difference_update(b) # 集合 a 更新为差集 a -b # 同理 差集 b - a # 并集,集合a和集合b总元素集合 print(a | b) print(a.union(b)) # 对称差集,集合a和集合b不重复元素集合 print(a^b) print(a.symmetirc_differece(b) |
Python自动化开发 - 字符编码、文件和集合的更多相关文章
- python基础_字符编码
字符编码的历史 阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII 阶段二:为了满足中文,中国人定制了GBK 阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的 ...
- python自动化开发学习 I/O多路复用
python自动化开发学习 I/O多路复用 一. 简介 socketserver在内部是由I/O多路复用,多线程和多进程,实现了并发通信.IO多路复用的系统消耗很小. IO多路复用底层就是监听so ...
- python自动化开发学习 进程, 线程, 协程
python自动化开发学习 进程, 线程, 协程 前言 在过去单核CPU也可以执行多任务,操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换任务2,任务2执行0.01秒,在切换到任务3,这 ...
- Python全栈开发之路 【第三篇】:Python基础之字符编码和文件操作
本节内容 一.三元运算 三元运算又称三目运算,是对简单的条件语句的简写,如: 简单条件语句: if 条件成立: val = 1 else: val = 2 改成三元运算: val = 1 if 条件成 ...
- python自动化开发-[第三天]-编码,函数,文件操作
今日概要 - 编码详解 - 文件操作 - 初识函数 一.字符编码 1.代码执行过程 代码-->解释器翻译-->机器码-->执行 2.ASCII ASCII:一个Bytes代表一个字符 ...
- python数据类型、字符编码、文件处理
介绍: 1.什么是数据? 例:x=10,10是我们要存储的数据 2.为何数据要分不同的类型? 数据是用来表示状态的,不同的状态用不同的类型的数据去表示 1.数据类型 1.数字(整形,长整形,浮点型,复 ...
- Python 字符编码-文件处理
.read #读取所有内容,光标移动到文件末尾.readable #判断文件是否可读.readline #读取一行内容,光标移动到第二行首部.readlines #读取每一行内容,存放于列表中.wri ...
- python字符编码-文件操作
字符编码 字符编码历史及发展 为什么有字符编码 ''' 原因:人们想要将数据存入计算机 计算机的能存储的信息都是二进制的数据 内存是基于电工作的,而电信号只有高低频两种,就用01来表示高低电频,所以计 ...
- python 基础之字符编码和文件处理
一.字符编码 (1)计算机基础知识 (2)python 解释器执行py文件的原理 <1>python 解释器启动 <2>python解释器相当于一个文本编辑器,打开txt.py ...
随机推荐
- UI设计:C4D作品案例分享
中文名4D电影,外文名CINEMA 4D,研发公司为德国Maxon Computer,特点为极高的运算速度和强大的渲染插件,使用在电影<毁灭战士>.<阿凡达>中,获得贸易展中最 ...
- Spring 是如何解析泛型 - ResolvalbeType
Spring 是如何解析泛型 - ResolvalbeType Spring 系列目录(https://www.cnblogs.com/binarylei/p/10198698.html) Java ...
- jmeter脚本录制的两种方式
完成一次完整的性能测试: 1.创建用户: 2.选择协议(HTTP) 3.使用工具去模拟协议操作(1.手工编写(抓包工具):2.工具自带录制) 4.运行工具进行压力测试
- java 泛型: 通配符? 和 指定类型 T
1. T通常用于类后面和 方法修饰符(返回值前面)后面 ,所以在使用之前必须确定类型,即新建实例时要制定具体类型, 而?通配符通常用于变量 ,在使用时给定即可 ? extends A : 通配符上 ...
- Sophus链接错误
错误指示如下: CMakeFiles/run_vo.dir/run_vo.cpp.o: In function `main': run_vo.cpp:(.text.startup+0x1086): u ...
- applicationContext-common.xml]; nested exception is java.lang.NoClassDefFoundError: org/w3c/dom/ElementTraversal
14:59:16,747 ERROR ContextLoader:350 - Context initialization failedorg.springframework.beans.factor ...
- python上下文管理协议
所谓上下文管理协议,就是咱们打开文件时常用的一种方法:with __enter__(self):当with开始运行的时候触发此方法的运行 __exit__(self, exc_type, exc_va ...
- Windows 平台 (UWP)应用设计
Make Your Apps Cooperate with Cross-App Communication : https://rewards.msdn.microsoft.com/Challeng ...
- 过河卒(NOIP2002)
题目链接:过河卒 直接模拟?会T掉60分. 所以我们可以采用递推,怎么想到的? 因为卒子只能向下或向右走,所以走到一个点的方法数,等于走到它上面点的方法数加上走到它左边点的方法数,这样就可以地推了. ...
- MyBatis中实现多表查询
如果查询的数据量大,推荐使用N+1次查询.数据量少使用联合查询... 一. 1.Mybatis是实现多表查询方式 1.1 业务装配:对两个表编写单表查询语句,在业务(Service)把查询的两表结果 ...