从0开始学爬虫2之json的介绍和使用
从0开始学爬虫2之json的介绍和使用
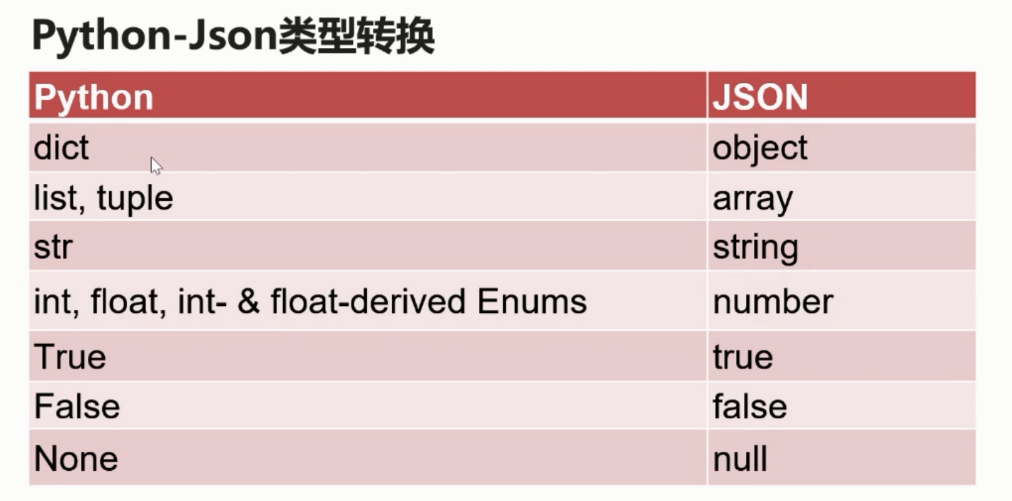
Json
- 一种轻量级的数据交换格式,通用,跨平台
- 键值对的集合,值的有序列表
- 类似于python中的dict
Json中的键值如果是字符串一定要用双引号
json文件static/book.json
{
"name": "Python书籍",
"origin_price": ,
"pub_date": "2018-4-14 17:00:00",
"store": ["京东","淘宝"],
"author": ["张三","李四","Jhone"],
"is_valid":true,
"is_sale": false,
"meta":{
"isbn":"abc-123",
"pages":
},
"desc":null
}
Json的常用方法练习use_json.py
#coding=utf-8 import json def python_to_json():
"""将python对象转换成json"""
d = {
'name': 'python书籍',
'price':62.3,
'is_valid': True
}
# intend是加入缩进效果
rest = json.dumps(d, indent=4)
print(rest) def json_to_python():
""" 将json转换成python """
data = '''
{
"name": "Python书籍",
"origin_price": 66,
"pub_date": "2018-4-14 17:00:00",
"store": ["京东","淘宝"],
"author": ["张三","李四","Jhone"],
"is_valid":true,
"is_sale": false,
"meta":{
"isbn":"abc-123",
"pages":300
},
"desc":null
}
'''
rest = json.loads(data)
print(rest) def json_to_python_from_file():
"""从文件读取内容并转换为python对象"""
f = open('./static/book.json', 'r', encoding='utf-8') s = f.read()
print(s)
rest = json.loads(s)
print(rest["name"]) f.close() if __name__ == '__main__':
python_to_json()
# json_to_python()
# json_to_python_from_file()
从0开始学爬虫2之json的介绍和使用的更多相关文章
- 从0开始学爬虫3之xpath的介绍和使用
从0开始学爬虫3之xpath的介绍和使用 Xpath:一种HTML和XML的查询语言,它能在XML和HTML的树状结构中寻找节点 安装xpath: pip install lxml HTML 超文本标 ...
- 从0开始学爬虫4之requests基础知识
从0开始学爬虫4之requests基础知识 安装requestspip install requests get请求:可以用浏览器直接访问请求可以携带参数,但是又长度限制请求参数直接放在URL后面 P ...
- 从0开始学爬虫12之使用requests库基本认证
从0开始学爬虫12之使用requests库基本认证 此处我们使用github的token进行简单测试验证 # coding=utf-8 import requests BASE_URL = " ...
- 从0开始学爬虫11之使用requests库下载图片
从0开始学爬虫11之使用requests库下载图片 # coding=utf-8 import requests def download_imgage(): ''' demo: 下载图片 ''' h ...
- 从0开始学爬虫9之requests库的学习之环境搭建
从0开始学爬虫9之requests库的学习之环境搭建 Requests库的环境搭建 环境:python2.7.9版本 参考文档:http://2.python-requests.org/zh_CN/l ...
- 从0开始学爬虫8使用requests/pymysql和beautifulsoup4爬取维基百科词条链接并存入数据库
从0开始学爬虫8使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 Python使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 参考 ...
- 从0开始学爬虫10之urllib和requests库与github/api的交互
urllib库的使用 # coding=utf-8 import urllib2 import urllib # htpbin模拟的环境 URL_IP="http://10.11.0.215 ...
- 从0开始学爬虫7之BeautifulSoup模块的简单介绍
参考文档: https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ # 安装 beautifulsoup4 (pytools) D:\pyt ...
- 一起学爬虫——使用selenium和pyquery爬取京东商品列表
layout: article title: 一起学爬虫--使用selenium和pyquery爬取京东商品列表 mathjax: true --- 今天一起学起使用selenium和pyquery爬 ...
随机推荐
- IBM MQ V6.0 for Windows7
https://blog.csdn.net/guolf521/article/details/87913141 websphere 商用中间件MQ 轨道交通使用
- destoon二次开发-签到时间函数扩展
在api/extend.func.php文件下增加以下代码: //签到时间函数 function timetoday($time = 0, $type = 6) { if(!$time) $time ...
- NOIP 2017 PJ
T1:水 T2:水 T3:水 T4:水,二分+DP检测+单调队列优化,然而优化写炸了,还没暴力分高 所以爆炸 (民间)100 + 100 + 100 + 10 = 310 GAME OVER
- HiveQL 数据装在与导出
一.向管理表中装载数据 1.向表中装载数据load 1)load语法 2)LOCAL 指的是操作系统的文件路径,否则默认为HDFS的文件路径 3)overwrite关键字 如果用户指定了overwr ...
- Base64原理解析与使用
一.Base64编码由来 为什么会有Base64编码呢?因为有些网络传送渠道并不支持所有的字节,例如传统的邮件只支持可见字符的传送,像ASCII码的控制字符就 不能通过邮件传送.这样用途就受到了很大的 ...
- C#实现上传/下载Excel文档
要求 环境信息:WIN2008SERVER 开发工具:VS2015 开发语言:C# 要求: 1.点击同步数据后接口获取数据展示页面同时过滤无效数据并写入数据库,数据可导出Excel并支持分类导出 2 ...
- 【一起来烧脑】读懂Promise知识体系
知识体系 Promise基础语法,如何处理错误,简单介绍异步函数 内容 错误处理的两种方式: reject('错误信息').then(null, message => {}) throw new ...
- UOJ226. 【UR #15】奥林匹克环城马拉松 [组合数学,图论]
UOJ 思路 我们知道关于有向图欧拉回路计数有一个结论:在每个点入度等于出度的时候,答案就是 \[ t_w(G)\prod (deg_i-1)! \] 其中\(t_w(G)\)是以某个点为根的树形图个 ...
- Pytest权威教程06-使用Marks标记测试用例
目录 使用Marks标记测试用例 在未知标记上引发异常: -strict 标记改造和迭代 返回: Pytest权威教程 使用Marks标记测试用例 通过使用pytest.mark你可以轻松地在测试用例 ...
- Linux 之数组
数组 和其他编程语言一样,Shell 也支持数组.数组(Array)是若干数据的集合,其中的每一份数据都称为元素(Element). Shell 并且没有限制数组的大小,理论上可以存放无限量的数据.和 ...