python数据分析之数据分布
转自链接:https://blog.csdn.net/YEPAO01/article/details/99197487
一、查看数据分布趋势
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- %matplotlib inline
- #读取源数据
- df = pd.read_csv('http://jse.amstat.org/datasets/normtemp.dat.txt', header=None, sep='\s+', names = ['体温','性别','心率'])
- df.head()
#下载到本地
re = requests.get("http://jse.amstat.org/datasets/normtemp.dat.txt")
re.encoding = "utf-8"
with open("normtemp.dat.txt","w") as f:
f.write(re.text)
df = pd.read_csv("normtemp.dat.txt", header=None, sep="\s+")
df.columns = ['体温','性别','心率']
df.head()
#2 不下载
columns = ['体温','性别','心率']
df = pd.read_csv("http://jse.amstat.org/datasets/normtemp.dat.txt", header=None, sep="\s+")
df.columns = ['体温','性别','心率']
- #查看数据基本特征
- df.describe()
绘制散点图
- # 散点图
- fig = plt.figure(figsize=(16,5))
- df1 = df[df["性别"]==1]
- df1.shape
- plt.scatter(df1.index, df1["体温"], c="r", label="male")
- plt.legend()
- df2 = df[df["性别"]==2]
- df2.shape
- plt.scatter(df2.index, df2["体温"], c="b", label="female")
- plt.legend()
- plt.ylabel("tw")
- plt.xlabel("x")
- plt.grid()

柱形图
- # 柱形图
- x = np.arange(0,130,1)
- y = df_tw.values
- plt.bar(x,y)
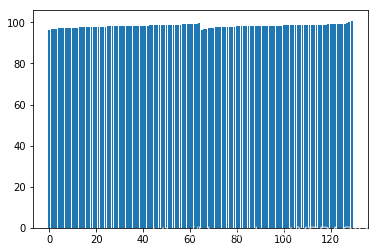
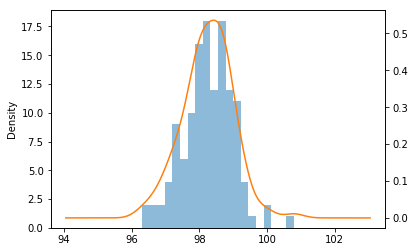
绘制直方图查看体温分布趋势
df_tw.hist(bins=20,alpha = 0.5) df_tw.plot(kind = 'kde', secondary_y=True)
计算温度个数
- # 针对温度数据, 计算温度的个数
- df_tm01 = df_tm.value_counts() # 计数
- df_tm01.sort_index(inplace=True) # 按照温度排序
- print(df_tm01.head())
- 96.3 1
- 96.4 1
- 96.7 2
- 96.8 1
- 96.9 1
- Name: 体温, dtype: int64
- plt.scatter(df_tm01.index,df_tm01.values)
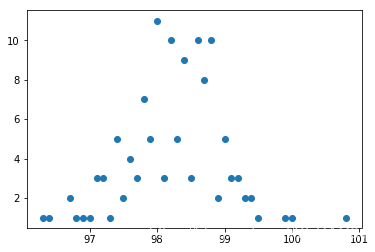
检验是否符合正太
方法1 :scipy.stats.normaltest (a, axis=0)
参数:a - 待检验数据;axis - 可设置为整数或置空,如果设置为 none,则待检验数据被当作单独的数据集来进行检验。该值默认为 0,即从 0 轴开始逐行进行检验。
返回:k2 - s^2 + k^2,s 为 skewtest 返回的 z-score,k 为 kurtosistest 返回的 z-score,即标准化值;p-value - p值
- import scipy.stats
- scipy.stats.normaltest(df_tm)
- NormaltestResult(statistic=2.703801433319236, pvalue=0.2587479863488212)
得到的p值>0.05
方法2 Shapiro-Wilk test
方法:scipy.stats.shapiro(x)
官方文档:SciPy v1.1.0 Reference Guide
参数:x - 待检验数据
返回:W - 统计数;p-value - p值
- scipy.stats.shapiro(df_tm.values)
- (0.9865770936012268, 0.233174666762352)
得到的p值 0.23 > 0.05, 符合正态分布
方法3: scipy.stats.kstest
方法:scipy.stats.kstest (rvs, cdf, args = ( ), N = 20, alternative =‘two-sided’, mode =‘approx’)
官方文档:SciPy v0.14.0 Reference Guide
参数:rvs - 待检验数据,可以是字符串、数组;
cdf - 需要设置的检验,这里设置为 norm,也就是正态性检验;
alternative - 设置单双尾检验,默认为 two-sided
返回:W - 统计数;p-value - p值
- u = df_tm.mean()
- std = df_tm.std()
- scipy.stats.kstest(df_tm.values,'norm',args=(u,std))
- KstestResult(statistic=0.06472685044046644, pvalue=0.6450307317439967)
方法4: Anderson-Darling test
方法:scipy.stats.anderson (x, dist =‘norm’ )
该方法是由 scipy.stats.kstest 改进而来的,可以做正态分布、指数分布、Logistic 分布、Gumbel 分布等多种分布检验。默认参数为 norm,即正态性检验。
官方文档:SciPy v1.1.0 Reference Guide
参数:x - 待检验数据;dist - 设置需要检验的分布类型
返回:statistic - 统计数;critical_values - 评判值;significance_level - 显著性水平
- scipy.stats.anderson(df_tm.values,dist="norm")
- AndersonResult(statistic=0.5201038826714353, critical_values=array([0.56 , 0.637, 0.765, 0.892, 1.061]), significance_level=array([15. , 10. , 5. , 2.5, 1. ]))
结论:三种检验的pvalue值均大于5%,因此体温值服从正态分布。第四种方法返回的不是pvalue值.
使用箱型图查看是否存在异常值.
- #箱型图
- df_tm.plot.box(vert=False, grid = True)
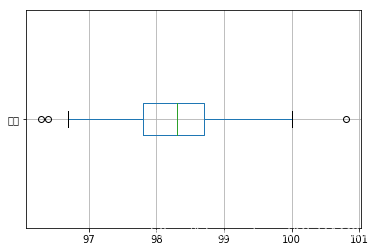
查找具体的异常值数据
- # 上四分位数
- q3 = df_tm.quantile(q=0.75)
- #下四分位数
- q1 = df_tm.quantile(q=0.25)
- # 四分位差
- iqr = q3-q1
- print("上四分位数:{}\n下四分位数:{}\n四分位差{}".format(q3,q1,iqr))
- df_tm_01 = df_tm[(df_tm>q3+1.5*iqr) | (df_tm<q1-1.5*iqr)]
- print("异常值:\n{}".format(df_tm_01))
- 上四分位数:98.7
- 下四分位数:97.8
- 四分位差0.9000000000000057
- 异常值:
- 0 96.3
- 65 96.4
- 129 100.8
- Name: 体温, dtype: float64
利用python计算两者之间的相关性系数
需要了解统计学三大相关系数: 绝对值越大,相关性越强
pearson
kendall
spearman
相关系数 相关强度
0.8-1.0 极强
0.6-0.8 强
0.4-0.6 中等
0.2-0.4 弱
0.0-0.2 极弱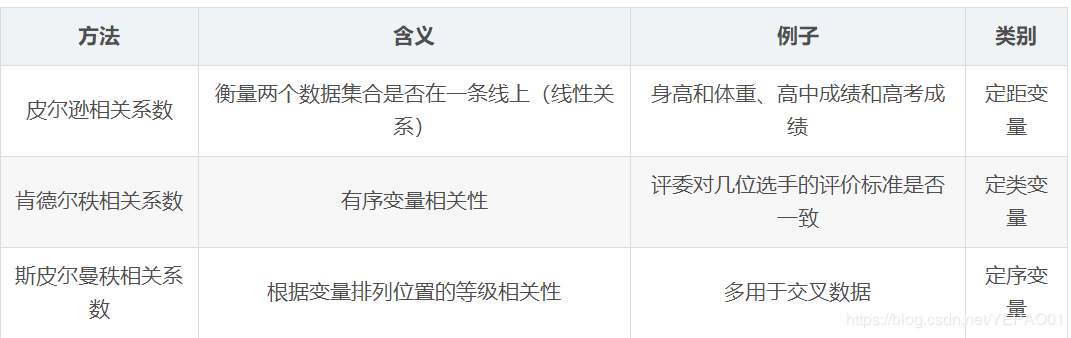
- #相关系数
- df["体温"].corr(df["心率"], method='pearson')
- 0.24328483580230698
- # spearman 相关系数
- df["体温"].corr(df["心率"], method='spearman')
- 0.265460363879611
- # kendall 相关系数
- df["体温"].corr(df["心率"], method='kendall')
- 0.17673221630037853
或
- df = df[["体温","心率"]]
- print(df.corr(method='pearson'),"\n")
- print(df.corr(method='spearman'),"\n")
- print(df.corr(method='kendall'),"\n")
- 体温 心率
- 体温 1.000000 0.243285
- 心率 0.243285 1.000000
- 体温 心率
- 体温 1.00000 0.26546
- 心率 0.26546 1.00000
- 体温 心率
- 体温 1.000000 0.176732
- 心率 0.176732 1.000000
- fig = plt.figure(figsize=(16,5))
- plt.scatter(df.index, df["体温"])
- plt.scatter(df.index, df["心率"])

参考链接https://blog.csdn.net/cyan_soul/article/details/81236124
二、python中实现数据分布的方法
参考链接:https://www.cnblogs.com/pinking/p/7898313.html
- #二项分布
- from scipy.stats import binom
- #几何分布
- from scipy.stats import geom
- #泊松分布
- from scipy.stats import poisson
- #均匀分布
- from scipy.stats import uniform
- #指数分布
- from scipy.stats import expon
- #正太分布
- from scipy.stats import norm
python数据分析之数据分布的更多相关文章
- Python数据分析--Pandas知识点(三)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘. Python数据分析--Pandas知识点(一) Python数据分析--Pandas知识点(二) 下面将是在知识点一, ...
- Python数据分析初始(一)
基础库 pandas:python的一个数据分析库(pip install pandas) pandas 是基于 NumPy 的一个 python 数据分析包,主要目的是为了 数据分析 .它提供了大量 ...
- 《Python 数据分析》笔记——pandas
Pandas pandas是一个流行的开源Python项目,其名称取panel data(面板数据)与Python data analysis(Python 数据分析)之意. pandas有两个重要的 ...
- Python 数据分析中常用的可视化工具
Python 数据分析中常用的可视化工具 1 Matplotlib 用于创建出版质量图表的绘图工具库,目的是为 Python 构建一个 Matlab 式的绘图接口. 1.1 安装 Anaconada ...
- [Python数据分析]新股破板买入,赚钱几率如何?
这是本人一直比较好奇的问题,网上没搜到,最近在看python数据分析,正好自己动手做一下试试.作者对于python是零基础,需要从头学起. 在写本文时,作者也没有完成这个小分析目标,边学边做吧. == ...
- 【Python数据分析】Python3多线程并发网络爬虫-以豆瓣图书Top250为例
基于上两篇文章的工作 [Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 [Python数据分析]Python3操作Excel(二) 一些问题的解决与优化 已经正确地实现 ...
- 【Python数据分析】Python3操作Excel(二) 一些问题的解决与优化
继上一篇[Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 对豆瓣图书Top250进行爬取以后,鉴于还有一些问题没有解决,所以进行了进一步的交流讨论,这期间得到了一只尼玛 ...
- 【搬砖】【Python数据分析】Pycharm中plot绘图不能显示出来
最近在看<Python数据分析>这本书,而自己写代码一直用的是Pycharm,在练习的时候就碰到了plot()绘图不能显示出来的问题.网上翻了一下找到知乎上一篇回答,试了一下好像不行,而且 ...
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
随机推荐
- ES6新增的一些特性
1.let关键字,用来代替 var的关键字,特点: 1.变量不允许被重复定义 2.不会进行变量声明提升 3.保留块级作用域中i的 2.const定义常量,特点:1.常量值不允许被改变 2.不会进行变量 ...
- [十一集训] Day1 (2018-2019 ACM-ICPC Nordic Collegiate Programming Contest (NCPC 2018))
A Altruistic Amphibians 原题 题目大意: n只青蛙在高度为d的井中,每只有跳跃距离.重量和高度,每只青蛙可以借助跳到别的青蛙的背上而跳出井,每只青蛙能承受的最大重量是自身重量, ...
- scrapy服务化持久运行
如果要将scrapy做成服务持久运行,通常我们会尝试下面的方式,这样是不可行的: class myspider(scrapy.Spider): q = queue() #task qu ...
- 13 IO流(十)——BufferedReader/BufferedWriter 装饰流
Buffered字符包装流 与Buffered字节装饰流一样,只不过是对字符流进行包装. 需要注意的地方 Buffered字符流在Reader与Writer上有两个新的方法:String readLi ...
- CCS中的linked resource
一.关于CCS中的linked resource linkded resources 是eclipse中的一个功能,可以将存放在项目所在位置以外某个路径的文件或者文件夹链接至工程项目中.这个功能最大的 ...
- java 简易日历表
在页面上输出1900年以后任意一年的简易日历表 package text3; import java.util.Scanner; public class MyCalendar { public st ...
- VirtualBox安装文档教程
1找到安装包双击打开 2 3 这里可以更改安装路径 4 5 6 7 等待安装 8
- git 学习笔记 ---撤销修改
自然,你是不会犯错的.不过现在是凌晨两点,你正在赶一份工作报告,你在readme.txt中添加了一行: $ cat readme.txt Git is a distributed version co ...
- springboot 2.1.3.RELEASE添加filter,servlet源码学习
Servlet规范中,通过ServeltContext来注册Filter.Servlet,这里分析Filter,Servlet是相同逻辑 springboot2.0中,我们通过 FilterRegis ...
- OO——JML作业总结
目录 第三单元博客作业 JML语言理论基础 1.注释结构 2.JML表达式 3.方法规格 4.类型规格 应用工具链 JMLUnitNG使用实例 作业架构设计 第一次作业 第二次作业 第三次作业 BUG ...