论文阅读:FaceBoxes: A CPU Real-time Face Detector with High Accuracy
文章: 《FaceBoxes: A CPU Real-time Face Detector with High Accuracy》
Introduction
2个挑战:
1)在杂乱背景下人脸视角大的变化需要人脸检测器精准的解决复杂人脸和非人脸的分类问题。
2)较大的搜索空间和人脸尺寸进一步增加了时间效率的需要。
传统方法效率高但在人脸大的视角变化下精度不够,基于CNN的方法精度高但速度很慢。
受到Faster R-CNN的RPN以及SSD中多尺度机制的启发,便有了这篇可以在CPU上实时跑的FaceBoxes。
FaceBoxes
(1)RDCL:Rapidly Digested Convolutional Layers,加速计算
- 缩小输入的空间大小:为了快速减小输入的空间尺度大小,在卷积核池化上使用了一系列的大的stride,在Conv1,Pool1,Conv2,Pool2上stride分别是4,2,2,2,RDCL的stride一共是32,意味着输入的尺度大小被快速减小了32倍。
- 选择合适的kernel size:一个网络开始的一些层的kernel size应该比较小以用来加速,同时也应该足够大用以减轻空间大小减小带来的信息损失。Conv1,Conv2和所有的Pool分别选取7*7,5*5,3*3的kernel size。
- 减少输出通道数:使用C.ReLU来减少输出通道数。
(2)MSCL:Multiple Scale Convolutional Layers,丰富感受野,使不同层的anchor离散化以处理多尺度人脸
将RPN作为一个人脸检测器,不能获取很好的性能有以下两个原因:
- RPN中的anchor只和最后一个卷积层相关,其中的特征和分辨率在处理人脸变化上太弱。
- anchor相应的层使用一系列不同的尺度来检测人脸,但只有单一的感受野,不能匹配不同尺度的人脸。
为解决这个问题,对MSCL从以下两个角度去设计:
- Multi-scale design along the dimension of network depth.如下图,anchor在多尺度的feature map上面取,类似SSD。

- Multi-scale design along the dimension of network width.使用inception模块,内部使用不同大小的卷积核,可以捕获到更多的尺度信息。
- Multi-scale design along the dimension of network depth.如下图,anchor在多尺度的feature map上面取,类似SSD。
(3)Anchor densification strategy:
Inception的anchor尺度为32*32,64*64,128*128,Conv3_2、Conv4_2的尺度分别为256*256和512*512。

anchor的间隔和相应的层的stride相等。比如Conv3_2的stride是64、anchor大小为256*256,表示对应输入图片每64像素大小有一个256*256的anchor。anchor密度为:
Adensity = Ascale/Ainterval
Ascale 表示anchor的尺度,Ainterval 表示anchor间隔。默认间隔分别设置为32,32,32,64.根据公式,对应的密度分别为1,2,4,4,4.显然在不同尺度上anchor的密度不均衡。相比大的anchor(128-512),小的anchor(32和64)过于稀疏,将会导致在小脸检测中低的召回率。
为解决不均衡问题,此处提出新的anchor策略。为了加大一种anchor的密度,在一个感受野的中心均匀的堆叠n2 个anchor(本来是1个)用来预测。
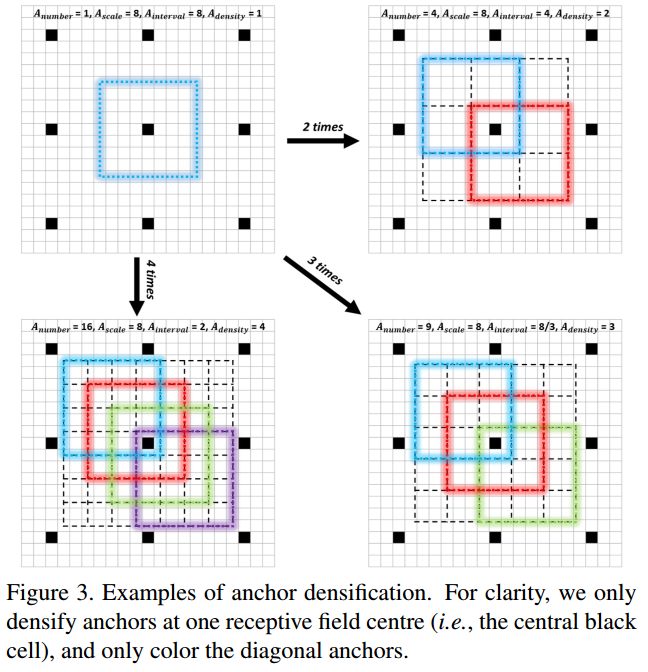
文章里对32*32的anchor做了4倍,对64*64的anchor做了2倍,这样就可以保证不同尺度的anchor有相同的密度。
训练
Training dataset: WIDER FACE的子集,12880个图片。
Data augmentation:
- Color distorition:根据《Some Improvements on Deep Convolutional Neural Network Based Image Classification》
- Random cropping: 从原图中随机裁剪5个方块patch:一个最大方块,其他的分别在范围[0.3,1]之于原图尺寸。
- Scale transformation:将随机裁剪后的方块patch给resize到1024*1024.
- Horizontal flipping: 0.5的概率翻转。
- Face-box filter: 如果face box的中心在处理后的图片上,则保持其重叠,然后将高或宽小于20像素的face box过滤出来。
Matching strategy:
在训练时需要判断哪个anchor是和哪个face bounding box相关的。首先使用jaccard overlap将每个脸和anchor对应起来,然后对anchor和任意脸jaccard overlap高于阈值(0.35)的匹配起来。
Loss function:
和Faster R-CNN中的RPN用同样的loss,一个2分类的softmax loss用来做分类,smooth L1用来做回归。
Hard negative mining:
在anchor匹配后,大多数anchor都是负样本,导致正样本和负样本严重不均衡。为了更快更稳定的训练,将他们按照loss值排序并选取最高的几个,保证正样本和负样本的比例最高不超过3:1.
Other implementation details:
Xavier随机初始化。优化器SGD,momentum:0.9,weight decay:5e-4,batch size:32,迭代最大次数:120k,初始80k迭代learning rate:1e-3,80-100k迭代用1e-4,,100-120k迭代用1e-5,使用caffe实现。
Experiments

Model analysis
FDDB相比AFW和PASCAL face较为困难,因此这里在FDDB上作分析。
Ablative Setting:
1)去掉anchor densification strategy.
2)把MSCL替换为三层卷积,其大小都为3*3,输出数都和MSCL中前三个Inception的保持一致.同时,把anchor只和最后一层卷积关联。
3)把RDCL中的C.ReLU替换为ReLU。
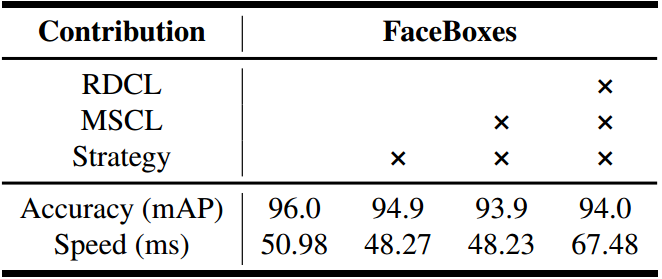
结论:
Anchor densification strategy is crucial.
MSCL is better.
RDCL is efficient and accuracy-preserving.
实验结果:
AFW:
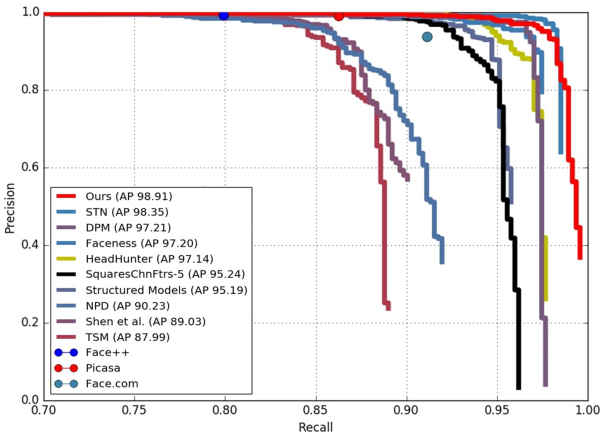
PASCAL face:

FDDB:
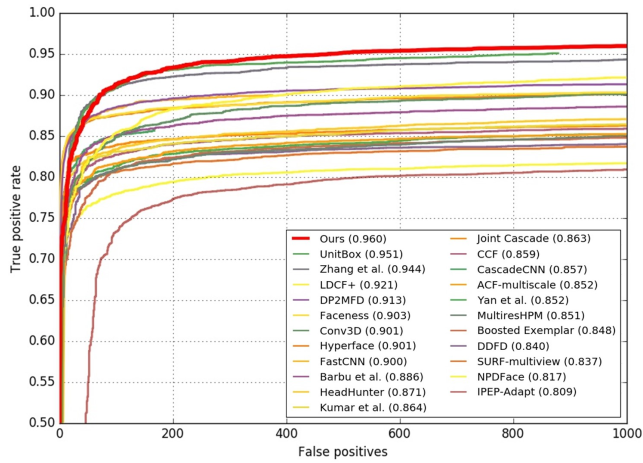
论文阅读:FaceBoxes: A CPU Real-time Face Detector with High Accuracy的更多相关文章
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读:《Bag of Tricks for Efficient Text Classification》
论文阅读:<Bag of Tricks for Efficient Text Classification> 2018-04-25 11:22:29 卓寿杰_SoulJoy 阅读数 954 ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
随机推荐
- beta版本——第四次冲刺
第四次冲刺 (1)SCRUM部分☁️成员描述: 姓名 李星晨 完成了哪个任务 进行注册的时候若不输入手机号,提醒用户的是未输入登录名,进行更改 花了多少时间 1.2h 还剩余多少时间 1.8h 遇到什 ...
- solr和ElasticSearch(ES)的区别?
Solr2004年诞生 ElasticSearch 2010年诞生 ES更新 ElasticSearch简介: ElasticSearch是一个实时的分布式的搜索引擎和分析引擎.它可以帮助你用前所未有 ...
- python 根据字符串语句进行操作再造函数(evec和eval方法)
例: #coding:utf-8 ''' Created on 2017年9月9日 @author: Bss ''' test_list=['def','a',''] test_list1=['pri ...
- dimensionality reduction动机---visualization(将数据可视化帮助我们更好地理解数据)
如果我们能更好地理解我们的数据,这样会对我们开发高效的机器学习算法有作用,将数据可视化(将数据画出来能更好地理解数据)出来将会对我们理解我们的数据起到很大的帮助. 高维数据如何进行显示 GDP: gr ...
- Linux下TCP连接断开后不释放的解决办法
问题:在开发测试时发现断开与服务器端口后再次连接时拒绝连接. 分析:服务器上查看端口占用情况,假设端口为8888. netstat -anp |grep 8888 发现端口8888端口显示被占用(ip ...
- Python的私有变量与装饰器@property的用法
Python的私有变量是在变量前面加上双横杠(例如:__test)来标识, Python私有变量只能在类内部使用,不被外部调用,且当变量被标记为私有后,调用时需再变量的前端插入类名,在类名前添加一个下 ...
- learning java FileOutputStream
import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStrea ...
- hibernate之一对多关系
1. 什么是关联(association) 1.1 关联指的是类之间的引用关系.如果类A与类B关联,那么被引用的类B将被定义为类A的属性.例如: public class A{ private B b ...
- lyft amundsen简单试用
昨天有说过amundsen 官方为我们提供了dockerc-compose 运行的参考配置,以下是一个来自官方的 quick start clone amundsen 代码 amundsen 使用了g ...
- Lightning Web Components 来自salesforce 的web 组件化解决方案
Lightning Web Components 是一个轻量,快速,企业级别的web 组件化解决方案,官方网站也提供了很全的文档 对于我们学习使用还是很方便的,同时我们也可以方便的学习了解salesf ...