Flink 之 写入数据到 ElasticSearch
前面 FLink 的文章中我们已经介绍了说 Flink 已经有很多自带的 Connector。
1、《从0到1学习Flink》—— Data Source 介绍
2、《从0到1学习Flink》—— Data Sink 介绍
其中包括了 Source 和 Sink 的,后面我也讲了下如何自定义自己的 Source 和 Sink。
那么今天要做的事情是啥呢?就是介绍一下 Flink 自带的 ElasticSearch Connector,我们今天就用他来做 Sink,将 Kafka 中的数据经过 Flink 处理后然后存储到 ElasticSearch。
准备
安装 ElasticSearch,这里就忽略,自己找我以前的文章,建议安装 ElasticSearch 6.0 版本以上的,毕竟要跟上时代的节奏。
下面就讲解一下生产环境中如何使用 Elasticsearch Sink 以及一些注意点,及其内部实现机制。
Elasticsearch Sink
添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch6_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
上面这依赖版本号请自己根据使用的版本对应改变下。
下面所有的代码都没有把 import 引入到这里来,如果需要查看更详细的代码,请查看我的 GitHub 仓库地址:
这个 module 含有本文的所有代码实现,当然越写到后面自己可能会做一些抽象,所以如果有代码改变很正常,请直接查看全部项目代码。
ElasticSearchSinkUtil 工具类
这个工具类是自己封装的,getEsAddresses 方法将传入的配置文件 es 地址解析出来,可以是域名方式,也可以是 ip + port 形式。
addSink 方法是利用了 Flink 自带的 ElasticsearchSink 来封装了一层,传入了一些必要的调优参数和 es 配置参数,下面文章还会再讲些其他的配置。
ElasticSearchSinkUtil.java
public class ElasticSearchSinkUtil {
/**
* es sink
*
* @param hosts es hosts
* @param bulkFlushMaxActions bulk flush size
* @param parallelism 并行数
* @param data 数据
* @param func
* @param <T>
*/
public static <T> void addSink(List<HttpHost> hosts, int bulkFlushMaxActions, int parallelism,
SingleOutputStreamOperator<T> data, ElasticsearchSinkFunction<T> func) {
ElasticsearchSink.Builder<T> esSinkBuilder = new ElasticsearchSink.Builder<>(hosts, func);
esSinkBuilder.setBulkFlushMaxActions(bulkFlushMaxActions);
data.addSink(esSinkBuilder.build()).setParallelism(parallelism);
}
/**
* 解析配置文件的 es hosts
*
* @param hosts
* @return
* @throws MalformedURLException
*/
public static List<HttpHost> getEsAddresses(String hosts) throws MalformedURLException {
String[] hostList = hosts.split(",");
List<HttpHost> addresses = new ArrayList<>();
for (String host : hostList) {
if (host.startsWith("http")) {
URL url = new URL(host);
addresses.add(new HttpHost(url.getHost(), url.getPort()));
} else {
String[] parts = host.split(":", 2);
if (parts.length > 1) {
addresses.add(new HttpHost(parts[0], Integer.parseInt(parts[1])));
} else {
throw new MalformedURLException("invalid elasticsearch hosts format");
}
}
}
return addresses;
}
}
Main 启动类
Main.java
public class Main {
public static void main(String[] args) throws Exception {
//获取所有参数
final ParameterTool parameterTool = ExecutionEnvUtil.createParameterTool(args);
//准备好环境
StreamExecutionEnvironment env = ExecutionEnvUtil.prepare(parameterTool);
//从kafka读取数据
DataStreamSource<Metrics> data = KafkaConfigUtil.buildSource(env);
//从配置文件中读取 es 的地址
List<HttpHost> esAddresses = ElasticSearchSinkUtil.getEsAddresses(parameterTool.get(ELASTICSEARCH_HOSTS));
//从配置文件中读取 bulk flush size,代表一次批处理的数量,这个可是性能调优参数,特别提醒
int bulkSize = parameterTool.getInt(ELASTICSEARCH_BULK_FLUSH_MAX_ACTIONS, 40);
//从配置文件中读取并行 sink 数,这个也是性能调优参数,特别提醒,这样才能够更快的消费,防止 kafka 数据堆积
int sinkParallelism = parameterTool.getInt(STREAM_SINK_PARALLELISM, 5);
//自己再自带的 es sink 上一层封装了下
ElasticSearchSinkUtil.addSink(esAddresses, bulkSize, sinkParallelism, data,
(Metrics metric, RuntimeContext runtimeContext, RequestIndexer requestIndexer) -> {
requestIndexer.add(Requests.indexRequest()
.index(ZHISHENG + "_" + metric.getName()) //es 索引名
.type(ZHISHENG) //es type
.source(GsonUtil.toJSONBytes(metric), XContentType.JSON));
});
env.execute("flink learning connectors es6");
}
}
配置文件
配置都支持集群模式填写,注意用 , 分隔!
kafka.brokers=localhost:9092
kafka.group.id=zhisheng-metrics-group-test
kafka.zookeeper.connect=localhost:2181
metrics.topic=zhisheng-metrics
stream.parallelism=5
stream.checkpoint.interval=1000
stream.checkpoint.enable=false
elasticsearch.hosts=localhost:9200
elasticsearch.bulk.flush.max.actions=40
stream.sink.parallelism=5
运行结果
执行 Main 类的 main 方法,我们的程序是只打印 flink 的日志,没有打印存入的日志(因为我们这里没有打日志):
所以看起来不知道我们的 sink 是否有用,数据是否从 kafka 读取出来后存入到 es 了。
你可以查看下本地起的 es 终端或者服务器的 es 日志就可以看到效果了。
es 日志如下:

上图是我本地 Mac 电脑终端的 es 日志,可以看到我们的索引了。
如果还不放心,你也可以在你的电脑装个 kibana,然后更加的直观查看下 es 的索引情况(或者直接敲 es 的命令)
我们用 kibana 查看存入 es 的索引如下:
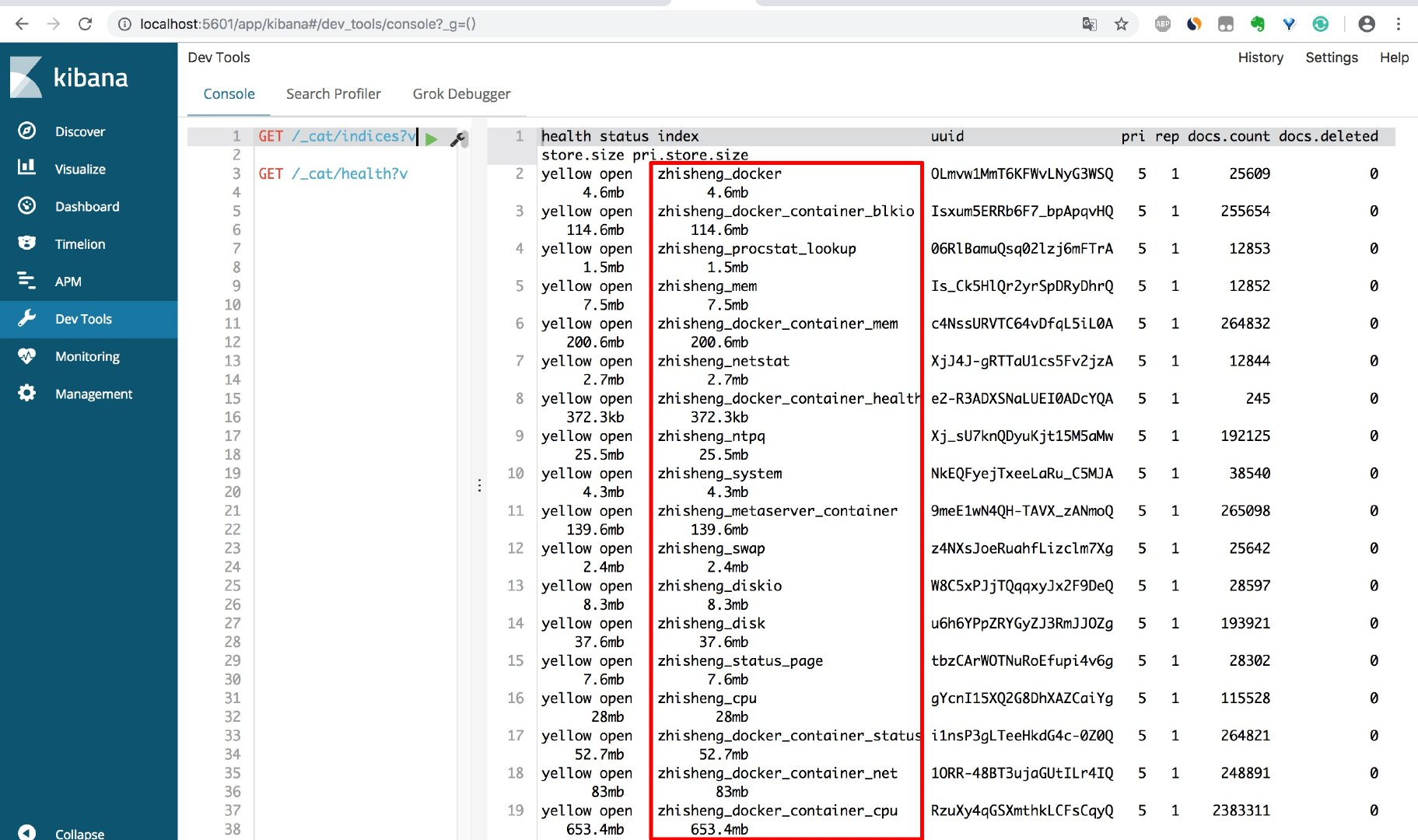
程序执行了一会,存入 es 的数据量就很大了。
扩展配置
上面代码已经可以实现你的大部分场景了,但是如果你的业务场景需要保证数据的完整性(不能出现丢数据的情况),那么就需要添加一些重试策略,因为在我们的生产环境中,很有可能会因为某些组件不稳定性导致各种问题,所以这里我们就要在数据存入失败的时候做重试操作,这里 flink 自带的 es sink 就支持了,常用的失败重试配置有:
1、bulk.flush.backoff.enable 用来表示是否开启重试机制 2、bulk.flush.backoff.type 重试策略,有两种:EXPONENTIAL 指数型(表示多次重试之间的时间间隔按照指数方式进行增长)、CONSTANT 常数型(表示多次重试之间的时间间隔为固定常数) 3、bulk.flush.backoff.delay 进行重试的时间间隔 4、bulk.flush.backoff.retries 失败重试的次数 5、bulk.flush.max.actions: 批量写入时的最大写入条数 6、bulk.flush.max.size.mb: 批量写入时的最大数据量 7、bulk.flush.interval.ms: 批量写入的时间间隔,配置后则会按照该时间间隔严格执行,无视上面的两个批量写入配置
看下啦,就是如下这些配置了,如果你需要的话,可以在这个地方配置扩充了。
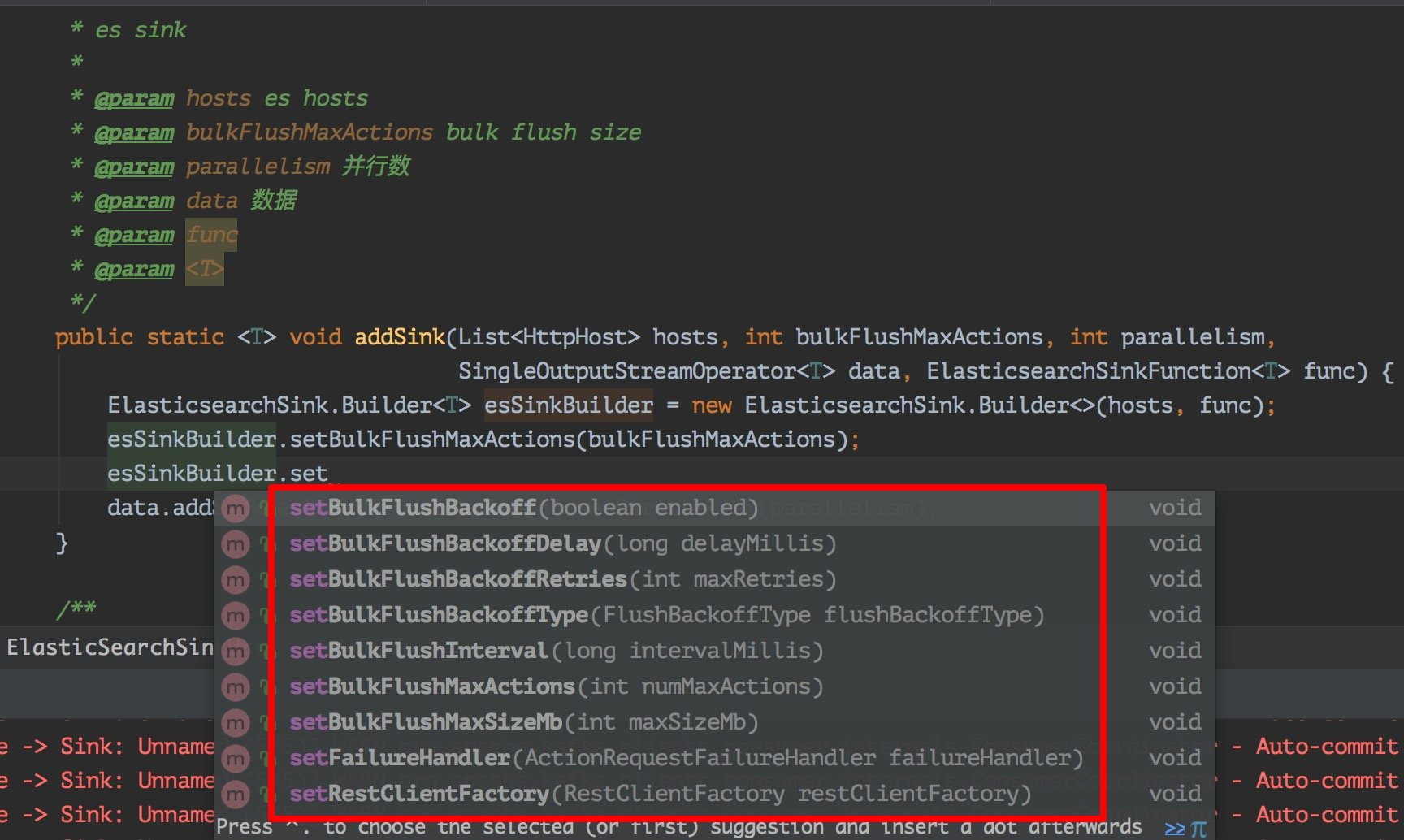
FailureHandler 失败处理器
写入 ES 的时候会有这些情况会导致写入 ES 失败:
1、ES 集群队列满了,报如下错误
12:08:07.326 [I/O dispatcher 13] ERROR o.a.f.s.c.e.ElasticsearchSinkBase - Failed Elasticsearch item request: ElasticsearchException[Elasticsearch exception [type=es_rejected_execution_exception, reason=rejected execution of org.elasticsearch.transport.TransportService$7@566c9379 on EsThreadPoolExecutor[name = node-1/write, queue capacity = 200, org.elasticsearch.common.util.concurrent.EsThreadPoolExecutor@f00b373[Running, pool size = 4, active threads = 4, queued tasks = 200, completed tasks = 6277]]]]
是这样的,我电脑安装的 es 队列容量默认应该是 200,我没有修改过。我这里如果配置的 bulk flush size * 并发 sink 数量 这个值如果大于这个 queue capacity ,那么就很容易导致出现这种因为 es 队列满了而写入失败。
当然这里你也可以通过调大点 es 的队列。参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-threadpool.html
2、ES 集群某个节点挂了
这个就不用说了,肯定写入失败的。跟过源码可以发现 RestClient 类里的 performRequestAsync 方法一开始会随机的从集群中的某个节点进行写入数据,如果这台机器掉线,会进行重试在其他的机器上写入,那么当时写入的这台机器的请求就需要进行失败重试,否则就会把数据丢失!

3、ES 集群某个节点的磁盘满了
这里说的磁盘满了,并不是磁盘真的就没有一点剩余空间的,是 es 会在写入的时候检查磁盘的使用情况,在 85% 的时候会打印日志警告。
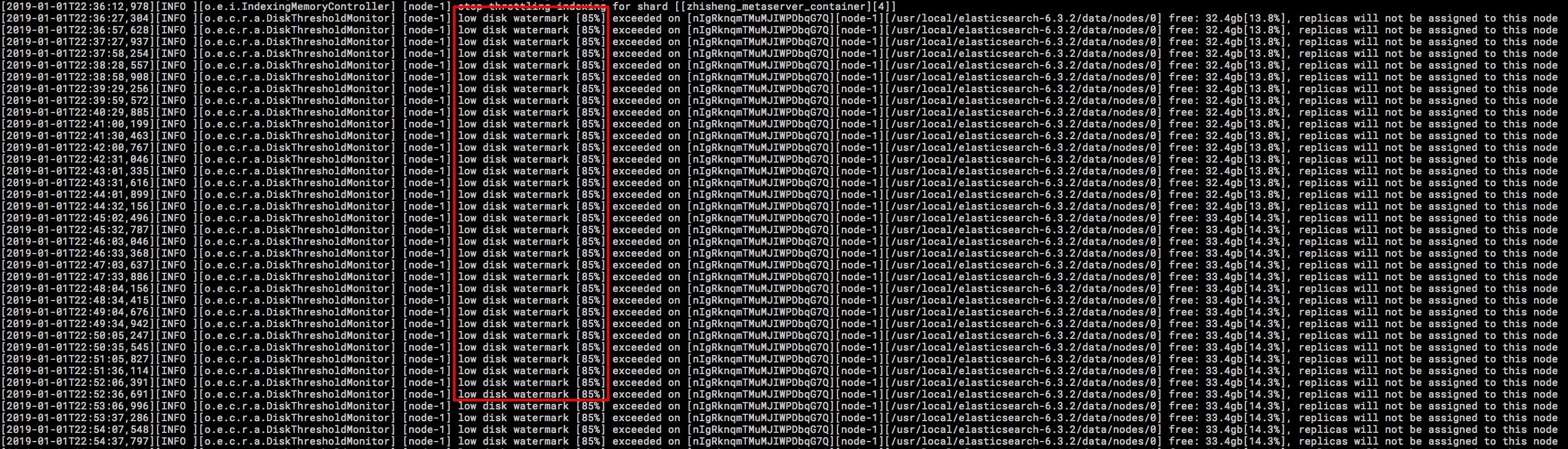
这里我看了下源码如下图:
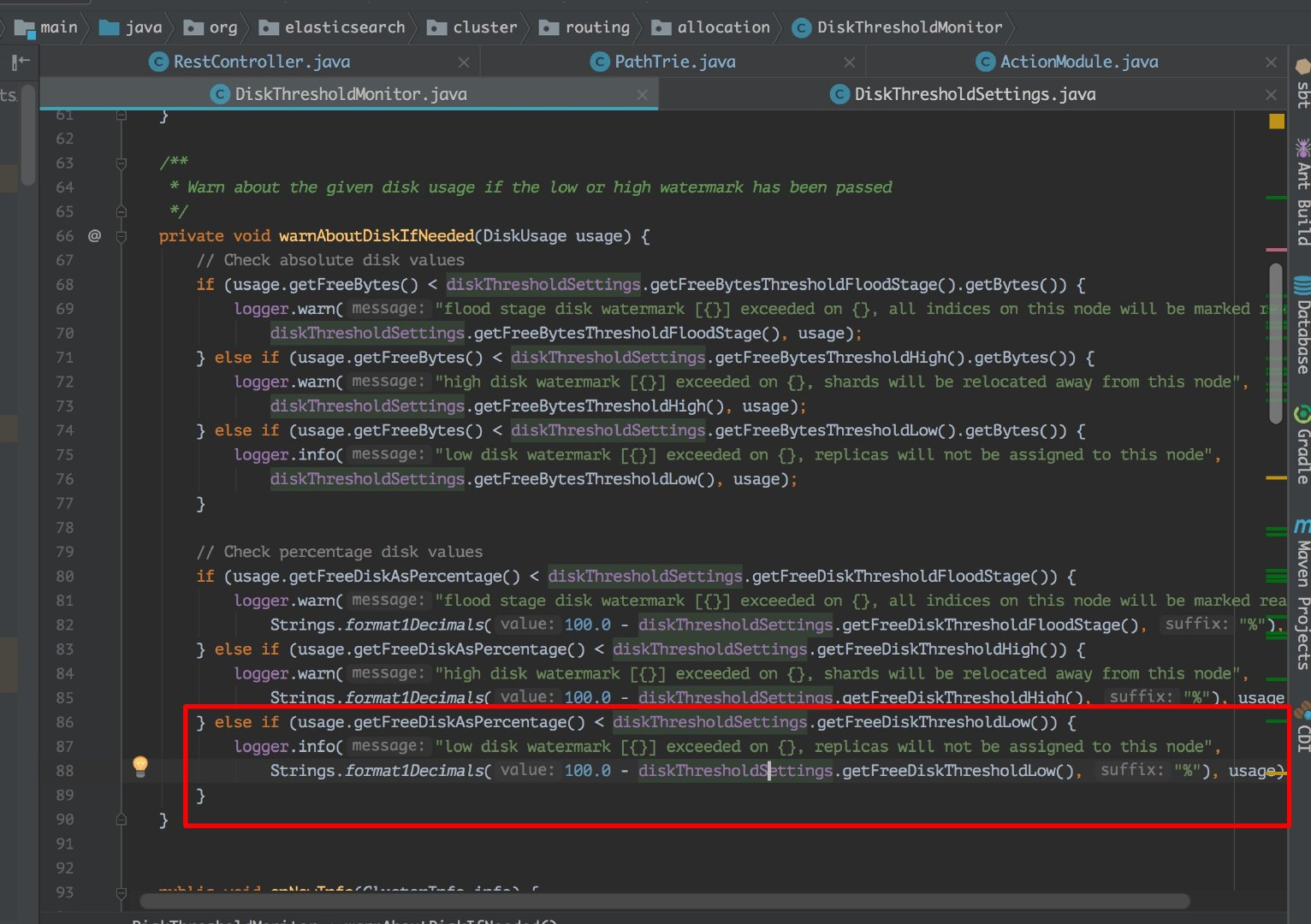
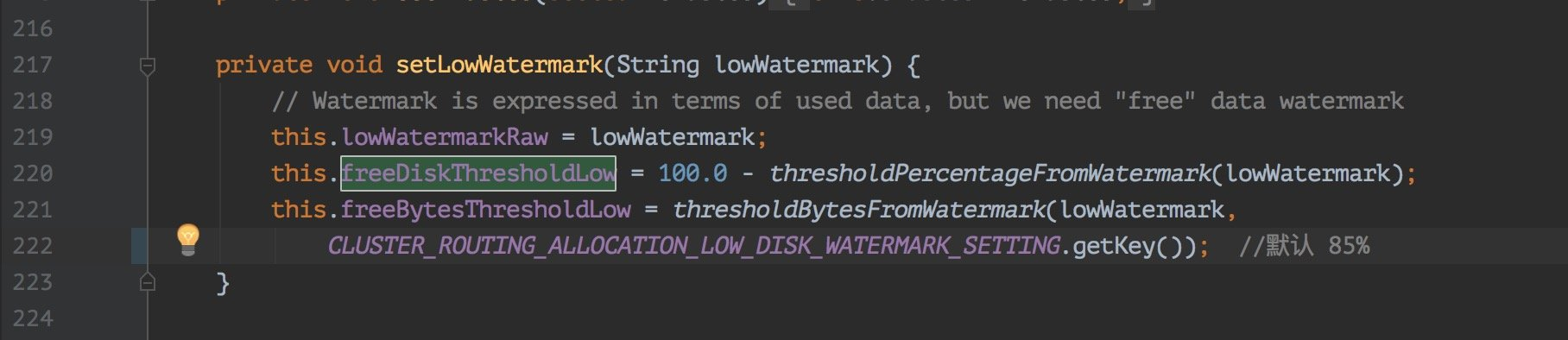
如果你想继续让 es 写入的话就需要去重新配一下 es 让它继续写入,或者你也可以清空些不必要的数据腾出磁盘空间来。
解决方法
DataStream<String> input = ...; input.addSink(new ElasticsearchSink<>(
config, transportAddresses,
new ElasticsearchSinkFunction<String>() {...},
new ActionRequestFailureHandler() {
@Override
void onFailure(ActionRequest action,
Throwable failure,
int restStatusCode,
RequestIndexer indexer) throw Throwable { if (ExceptionUtils.containsThrowable(failure, EsRejectedExecutionException.class)) {
// full queue; re-add document for indexing
indexer.add(action);
} else if (ExceptionUtils.containsThrowable(failure, ElasticsearchParseException.class)) {
// malformed document; simply drop request without failing sink
} else {
// for all other failures, fail the sink
// here the failure is simply rethrown, but users can also choose to throw custom exceptions
throw failure;
}
}
}));
如果仅仅只是想做失败重试,也可以直接使用官方提供的默认的 RetryRejectedExecutionFailureHandler ,该处理器会对 EsRejectedExecutionException 导致到失败写入做重试处理。如果你没有设置失败处理器(failure handler),那么就会使用默认的 NoOpFailureHandler 来简单处理所有的异常。
总结
本文写了 Flink connector es,将 Kafka 中的数据读取并存储到 ElasticSearch 中,文中讲了如何封装自带的 sink,然后一些扩展配置以及 FailureHandler 情况下要怎么处理。(这个问题可是线上很容易遇到的)
原创地址为:http://www.54tianzhisheng.cn/2018/12/30/Flink-ElasticSearch-Sink/
Flink 之 写入数据到 ElasticSearch的更多相关文章
- 《从0到1学习Flink》—— Flink 写入数据到 ElasticSearch
前言 前面 FLink 的文章中我们已经介绍了说 Flink 已经有很多自带的 Connector. 1.<从0到1学习Flink>-- Data Source 介绍 2.<从0到1 ...
- 使用Flink实现索引数据到Elasticsearch
使用Flink实现索引数据到Elasticsearch 2018-07-28 23:16:36 Yanjun 使用Flink处理数据时,可以基于Flink提供的批式处理(Batch Proce ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 四十六 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
前面我们讲到的elasticsearch(搜索引擎)操作,如:增.删.改.查等操作都是用的elasticsearch的语言命令,就像sql命令一样,当然elasticsearch官方也提供了一个pyt ...
- logstash 写入数据到elasticsearch 索引相差8小时解决办法
问题说明 Logstash用的UTC时间, logstash在按每天输出到elasticsearch时,因为时区使用utc,造成每天8:00才创建当天索引,而8:00以前数据则输出到昨天的索引 # 使 ...
- 《从0到1学习Flink》—— Flink 写入数据到 Kafka
前言 之前文章 <从0到1学习Flink>-- Flink 写入数据到 ElasticSearch 写了如何将 Kafka 中的数据存储到 ElasticSearch 中,里面其实就已经用 ...
- ElasticSearch写入数据的工作原理是什么?
面试题 es 写入数据的工作原理是什么啊?es 查询数据的工作原理是什么啊?底层的 lucene 介绍一下呗?倒排索引了解吗? 面试官心理分析 问这个,其实面试官就是要看看你了解不了解 es 的一些基 ...
- flink clickhouse-jdbc和flink-connector 写入数据到clickhouse因为jar包冲突导致的60 seconds.Please check if the requested resources are available in the YARN cluster和Could not resolve ResourceManager address akka报错血案
一.问题现象,使用flink on yarn 模式,写入数据到clickhouse,但是在yarn 集群充足的情况下一直报:Deployment took more than 60 seconds. ...
- Elasticsearch写入数据的过程是什么样的?以及是如何快速更新索引数据的?
前言 最近面试过程中遇到问Elasticsearch的问题不少,这次总结一下,然后顺便也了解一下Elasticsearch内部是一个什么样的结构,毕竟总不能就只了解个倒排索引吧.本文标题就是我遇到过的 ...
随机推荐
- Spring Boot 笔记 (8) - H2 数据库
Maven 依赖 <dependency> <groupId>com.h2database</groupId> <artifactId>h2</a ...
- 数据库PDO简介
php简介,php历史,php后端工程师职业前景,php技术方向,php后端工程师职业体系介绍. php是世界上使用最广泛的web开发语言,是超文本预处理器,是一种通用的开源脚本语言,语法吸收了c语言 ...
- sql的匹配和正则表达式
1. 匹配:like 关键字 #假设存在表 my_test_copy select * from my_test_copy; 则使用like关键词匹配:注意下划线 '_'和百分号 '%' # 下划线' ...
- js对样式的操作
本文有:对某个事件的来回操作实现对css样式的来回修改 .比如实现hover效果 <!DOCTYPE html> <html> <head> <meta ch ...
- (Linux基础学习)第一章:科普和Linux系统安装
第一章:科普和Linux系统安装 第1节:操作系统介绍OS:Operating System,通用目的的软件程序硬件驱动进程管理内存管理网络管理安全管理文件管理OS分类:服务器OS:RHEL,Cent ...
- 加速 Unity 不同平台打包的一种思路
Unity打包总的来说还不是一件特别复杂的事情, 但是我们知道任何关于跨平台(多线程等)这类问题, 总是会把事情搞得复杂起来. 以前项目的打包是通过Jenkins对一个工程下对不同平台多次打包, 不可 ...
- webpack loader和插件的编写原理
webpack自定义loader和插件的api网址:https://www.webpackjs.com/api/loaders/ 点击顶部API,看左侧api: 1. 如何编写一个loader 实现的 ...
- python实现Bencode解码方法
近期搞项目中遇到Bencode解码的问题,就用Py写了个Bencode解码的代码.作为笔记保存参考. BEncoding是BitTorrent用在传输数据结构的编码方式,这种编码方式支持四种类型的数据 ...
- Redis 缓存失效机制
Redis缓存失效的故事要从EXPIRE这个命令说起,EXPIRE允许用户为某个key指定超时时间,当超过这个时间之后key对应的值会被清除,这篇文章主要在分析Redis源码的基础上站在Redis设计 ...
- dosbox+masm5.0编译汇编文件
在去年写过如何bc3.1编译ucos,不过现在很少去用到,但是那是用dosbox也是懵懵懂懂的,参见https://blog.csdn.net/liming0931/article/details/8 ...